基于跨语言知识迁移和经验驱动的电力行业模型训练方法与流程
本发明属于电力行业自然语言处理,具体涉及一种基于跨语言知识迁移和经验驱动的电力行业模型训练方法。
背景技术:
1、近年来生成式人工智能技术不断进步,以chatgpt为代表的通用预训练语言模型由于其强大的语义理解、逻辑推理和文本生成能力受到广泛关注,在诸多通用领域如聊天机器人、新闻写作、智能办公和智能搜索等得到实际应用,显示出巨大价值。作为一种实现自然语言与计算机系统之间高效智能交互的技术,大语言模型在垂直行业领域也具有广阔的应用前景。
2、通用大模型利用广泛的通用知识训练,但没有接受专业领域的知识训练,难以直接应用于垂直行业。最近一些研究通过领域知识训练或微调探索了将语言模型应用到部分垂直行业的途径。典型的行业大模型如chatdoctor、medalpaca、bianque、chatlaw、chathome等。这些研究主要集中在医药、法律和金融等行业,电力行业专用大模型的研究尚不多见。电力行业在国家经济和社会发展中具有举足轻重的地位。因此,探索大模型技术在电力行业的应用具有重要价值。将海量的电力专业知识通过增量训练的方式注入到电力行业大模型,并将大模型应用于电网企业。可实现营销领域的电费查询、用电政策咨询和调度领域的安全案例分析、电网故障处置方案生成等功能,有助于电力行业的数字化转型。但由于电力行业知识的专业性很强,一些业务的理解和处理也具有较大困难,这些给大模型的应用带来极大挑战。亟需研究面向电力行业的大语言模型训练技术。
3、另一方面,从技术路线来看,这些行业大模型大多在llama-7b,chatglm-6b等小型开源预训练语言模型基础上,通过专业语料的增量预训练或指令微调的方式赋予模型行业知识技能。然而,这些模型只用到了中文语料训练,知识范围和掌握程度有待提升。指令微调样本通常通过蒸馏chatgpt等更大规模的教师模型生成,并未利用行业专家的业务经验,影响实际效果。
技术实现思路
1、为了克服现有技术中的问题,本发明提出了一种基于跨语言知识迁移和经验驱动的电力行业模型训练方法、装置及储存介质。
2、本发明解决上述技术问题的技术方案如下:
3、第一方面,本发明提供了一种基于跨语言知识迁移和经验驱动的电力行业模型训练方法,包括以下步骤:
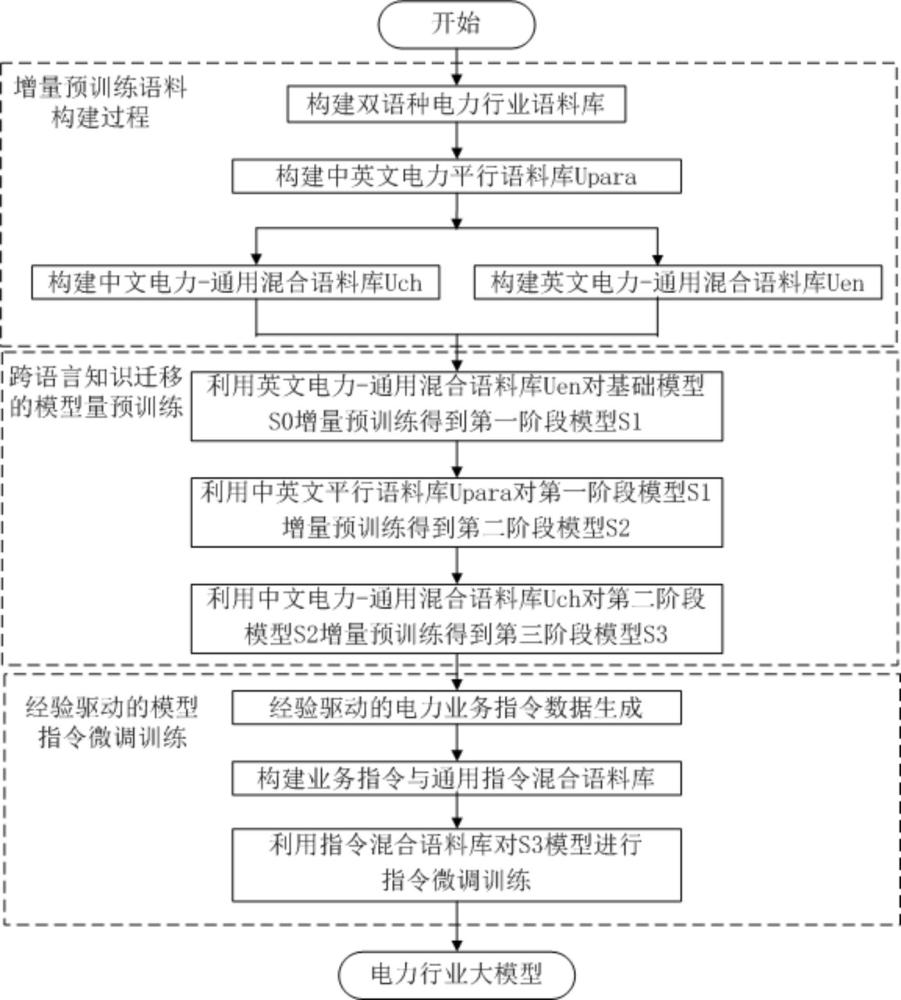
4、步骤100.构建增量预训练语料库,其包括:构建双语种电力行业语料库;基于双语种电力行业语料库,构建中英文电力平行语料库;将双语种电力行业语料与通用语料混合,分别构建中文电力-通用混合语料库及英文电力-通用混合语料库;
5、步骤200.跨语言知识迁移增量预训练,其包括:利用英文电力-通用混合语料库对基础模型增量预训练得到第一阶段模型;利用中英文电力平行语料库对第一阶段模型增量预训练得到第二阶段模型;利用中文电力-通用混合语料库对第二阶段模型增量预训练得到第三阶段模型;
6、步骤300.对模型指令微调:生成经验驱动的电力业务指令数据;构建业务指令与通用指令混合语料库;利用所述电力业务指令与通用指令混合语料库对第三阶段模型进行指令调整训练,得到电力行业大模型。
7、进一步地,步骤100中构建双语种电力行业语料库具体包括:获取不同来源的中文电力文档和英文电力文档,并进行预处理,所述预处理包括:文件名筛选、文件转换、合并段落、启发式文本清洗、小文件过滤及文本去重。
8、进一步地,所述步骤200中利用英文电力-通用混合语料库对基础模型增量预训练得到第一阶段模型,具体包括:
9、利用英文电力-通用混合语料库采用无监督自回归方式,按照公式(1)的第一阶段的损失函数,对基础模型s0进行增量预训练,从而获得第一阶段模型s1:
10、(1);
11、式中,表示第一阶段的损失函数;表示通用语料库训练的模型参数,表示通用语料库中的训练样本,表示通用语料库中的样本数目,表示样本所包含的token词元数目,即;表示模型根据样本的前 t个token,生成第 t+1个token的概率;表示取的对数。
12、进一步地,所述步骤200中利用中英文电力平行语料库对第一阶段模型增量预训练得到第二阶段模型,具体包括:
13、利用中英文电力平行语料库对s1阶段模型按照式(2)的第二阶段的损失函数继续进行增量预训练,得到第二阶段模型s2:
14、(2);
15、式中,表示第二阶段的损失函数;表示先后用通用语料库和中英文电力平行语料库训练的模型参数。
16、进一步地,所述步骤200中利用中文电力-通用混合语料库对第二阶段模型增量预训练得到第三阶段模型,具体包括:
17、在第二阶段模型s2基础上,继续用中文电力-通用混合语料库按照公式(3)的第三阶段的损失函数进行训练,得到第三阶段模型s3:
18、(3);
19、式中,表示第三阶段的损失函数;表示先后用通用语料库、中英文电力平行语料库和中文电力-通用混合语料库训练的模型参数。
20、进一步地,所述步骤300中生成经验驱动的电力业务指令数据,具体包括:
21、获取电力任务真实的样本;
22、基于获取的电力任务真实的样本,分析电力任务真实样本所涉及到的业务知识,并总结为,其中表示具体的每一条业务知识,表示所有涉及到的业务知识点的数量;
23、根据经验从中抽取符合实际的多个知识点的组合,每个组合表示为,;
24、根据电力任务要求设计任务提示词模板;对于每一个知识点组合将其所包含的个知识点依次列入提示词模板的对应位置,并与电力任务真实的样本构成提示词,用于指导电力大模型生成新的任务指令样本;
25、将提示词输入教师模型,并设置温度参数,教师模型针对每个知识点组合的提示词生成多个虚拟的指令样本;
26、对生成的多个虚拟的指令样本进行质量评分后,生成电力业务指令数据。
27、进一步地,所述步骤300中利用所述电力业务指令与通用指令混合语料库对第三阶段模型进行指令调整训练,具体包括:
28、电力业务指令与通用指令混合语料库中一条指令的描述,其相应的回复为,采用有监督方式,按照公式(4)的损失函数进行训练:
29、(4);
30、式中,表示指令微调损失函数,表示电力业务指令与通用指令混合语料库的样本数量,表示用电力业务指令与通用指令混合语料库的模型参数。
31、第二方面,本发明还提供了基于跨语言知识迁移和经验驱动的电力行业模型训练装置,其包括:处理器、存储器以及程序;所述程序存储在所述存储器中,所述处理器调用存储器存储的程序,以执行第一方面中任一实施例所述的方法。
32、第三方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行第一方面中任一实施例所述的方法。
33、与现有技术相比,本发明具有如下技术效果:
34、本发明根据电力行业数字化转型需求,针对现有行业大模型的局限,提出一种两阶段训练方法。第一阶段为跨语言迁移的增量预训练:先后利用英文电力知识语料、中英文平行语料和中文电力知识语料对开源模型进行增量预训练;通过不同语种语料的逐步加训可扩大模型知识范围,强化模型记忆程度;第二阶段为专家经验驱动的指令微调训练:充分利用专家业务经验指导如chatgpt这样的教师模型生成符合实际的任务指令样本,并利用这些指令样本对模型进行微调训练;该方法既用到了专家的经验,又“蒸馏”了教师模型自身的知识能力,可以使模型更好地理解和执行电力领域特定任务,确保产生准确的,符合电力行业要求的输出,有助于提高模型行业应用的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!