一种用于空间探索的代理模型的在线数据选择方法与流程
本说明书涉及空间探索、神经网络模型,尤其涉及一种用于空间探索的代理模型的在线数据选择方法。
背景技术:
1、在空间探索和优化领域,代理模型是一种用于模拟、近似或替代复杂、昂贵或不可行的真实系统或过程的模型。代理模型的作用包括:
2、预测性能:代理模型可以用于估计设计空间中各种配置或参数组合的性能,而无需实际进行昂贵的试验或模拟。这可以帮助在设计过程中快速筛选和排除不良设计,从而节省时间和资源。
3、加速优化:代理模型可以用于加速优化算法,如遗传算法、粒子群优化等。通过使用代理模型,可以减少实际系统的评估次数,从而加快优化过程的收敛速度。
4、引导决策:代理模型可以用于指导设计决策或决策制定。例如,在工程设计中,代理模型可以帮助工程师找到最佳设计参数,以满足特定的性能要求。
5、在现有技术中,往往是通过常规的有监督训练方式对代理模型进行训练,以得到用于空间探索的代理模型,这种方法通过监督学习训练出的代理模型只能实现:全空间拟合能力尚可,但是局部或者高排序区域数据的拟合能力不好;或者,仅某一特定数据区域拟合好。而在实际中的“空间探索”过程中更希望:兼顾全空间数据拟合能力和高排序区域的数据拟合能力,因此,本发明提供了一种针对代理模型的训练阶段“在线迭代数据选择”的方式来提高空间探索的准确性和效率。
技术实现思路
1、本说明书提供一种用于空间探索的代理模型的在线数据选择方法,以部分的解决现有技术存在的上述问题。
2、本说明书采用下述技术方案:
3、本说明书提供了一种用于空间探索的代理模型的在线数据选择方法,包括:
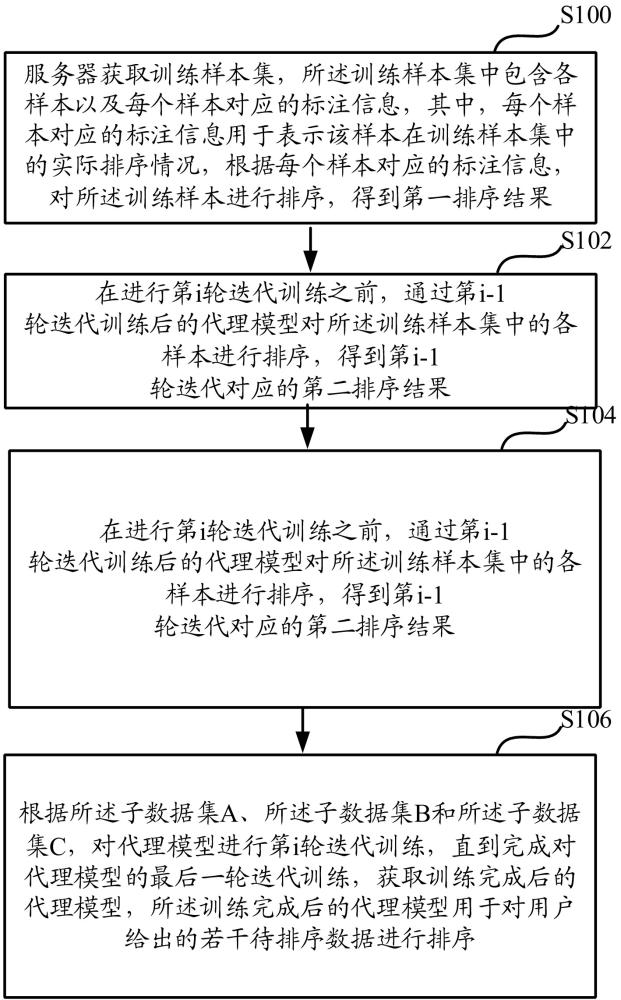
4、服务器获取训练样本集,所述训练样本集中包含各样本以及每个样本对应的标注信息,其中,每个样本对应的标注信息用于表示该样本在训练样本集中的实际排序情况,根据每个样本对应的标注信息,对所述各样本进行排序,得到第一排序结果;
5、在进行第i轮迭代训练之前,通过第i-1轮迭代训练后的代理模型对所述训练样本集中的各样本进行排序,得到第i-1轮迭代对应的第二排序结果;
6、从所述训练样本集中确定出所述第一排序结果中排序高于第一预设排位的子数据集a,以及从所述训练样本集中确定出所述第i-1轮迭代对应的第二排序结果中排序高于第二预设排位的子数据集b,以及根据所述第一排序结果确定出子数据集s,从所述子数据集s中随机采样出第三预设数量的样本以确定出子数据集c;
7、根据所述子数据集a、所述子数据集b和所述子数据集c,对代理模型进行第i轮迭代训练,直到完成对代理模型的最后一轮迭代训练,获取训练完成后的代理模型,所述训练完成后的代理模型用于对用户给出的若干待排序数据进行排序。
8、可选地,通过第i-1轮迭代训练后的代理模型对所述训练样本集中的各样本进行排序,得到第i-1轮迭代对应的第二排序结果,具体包括:
9、从所述训练样本集中确定出各样本对;
10、针对每个样本对,将该样本对输入到所述第i-1轮迭代训练后的代理模型中,得到该样本对对应的排序结果;
11、根据预设的标准排序算法以及各样本对对应的排序结果,确定出第i-1轮迭代对应的第二排序结果。
12、可选地,从所述训练样本集中随机采样出第三预设数量的样本以确定出子数据集c,具体包括:
13、从所述训练样本集中根据所述第一排序结果确定出top的样本,得到子数据集s;
14、从所述子数据集s随机采样出所述第三预设数量的样本,得到所述子数据集c。
15、可选地,所述训练样本集中高于第一预设排位的样本数量为,其中,α为小于1的预设参数,d为所述训练样本集中包含的样本数量,i为总迭代训练次数。
16、可选地,所述训练样本集中高于第二预设排位的样本数量为,其中,β为小于1的预设参数,d为所述训练样本集中包含的样本数量,i为总迭代训练次数。
17、可选地,第三预设数量为-g,其中,d为所述训练样本集中包含的样本数量,i为总迭代训练次数, g为子数据集a和子数据集b中的样本总数。
18、本说明书提供了一种用于空间探索的代理模型的在线数据选择装置,包括:
19、获取模块,用于获取训练样本集,所述训练样本集中包含各样本以及每个样本对应的标注信息,其中,每个样本对应的标注信息用于表示该样本在训练样本集中的实际排序情况,根据每个样本对应的标注信息,对所述训练样本进行排序,得到第一排序结果;
20、排序模块,用于在进行第i轮迭代训练之前,通过第i-1轮迭代训练后的代理模型对所述训练样本集中的各样本进行排序,得到第i-1轮迭代对应的第二排序结果;
21、确定模块,用于从所述训练样本集中确定出所述第一排序结果中排序高于第一预设排位的子数据集a,以及从所述训练样本集中确定出所述第i-1轮迭代对应的第二排序结果中排序高于第二预设排位的子数据集b,以及根据所述第一排序结果确定出子数据集s,从所述子数据集s中随机采样出第三预设数量的样本以确定出子数据集c;
22、训练模块,用于根据所述子数据集a、所述子数据集b和所述子数据集c,对代理模型进行第i轮迭代训练,直到完成对代理模型的最后一轮迭代训练,获取训练完成后的代理模型,所述训练完成后的代理模型用于对用户给出的若干待排序数据进行排序。
23、可选地,所述确定模块具体用于,从所述训练样本集中根据所述第一排序结果确定出top的样本,得到子数据集s;从所述子数据集s随机采样出所述第三预设数量的样本,得到所述子数据集c。
24、本说明书提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述用于空间探索的代理模型的在线数据选择方法。
25、本说明书提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述用于空间探索的代理模型的在线数据选择方法。
26、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
27、从上述一种用于空间探索的代理模型的在线数据选择方法中,服务器获取训练样本集,训练样本集中包含各样本以及每个样本对应的标注信息,其中,每个样本对应的标注信息用于表示该样本在训练样本集中的实际排序情况,根据每个样本对应的标注信息,对各样本进行排序,得到第一排序结果,在进行第i轮迭代训练之前,通过第i-1轮迭代训练后的代理模型对训练样本集中的各样本进行排序,得到第i-1轮迭代对应的第二排序结果,从训练样本集中确定出第一排序结果中排序高于第一预设排位的子数据集a,以及从训练样本集中确定出第i-1轮迭代对应的第二排序结果中排序高于第二预设排位的子数据集b,以及根据第一排序结果确定出子数据集s,从子数据集s中随机采样出第三预设数量的样本以确定出子数据集c,根据子数据集a、子数据集b和子数据集c,对代理模型进行第i轮迭代训练,直到完成对代理模型的最后一轮迭代训练,获取训练完成后的代理模型,训练完成后的代理模型用于对用户给出的若干待排序数据进行排序。
28、从上述内容中可以看出,本方法中具备以下优点:
29、本方法在每一轮迭代中选取出了三种数据为代理模型进行训练,包括真实排序高的数据、代理模型预测出的排序高但是不一定实际的排序高的数据,以及从全部样本中的随机采样出的数据(但是在随着迭代训练过程中会不断收缩到排序高的样本点),从而不但训练了代理模型对全部空间上的样本的拟合能力,还加强了代理模型从前期到后期逐渐对排序高的样本点的拟合能力,从而提到的代理模型的排序准确性。
- 还没有人留言评论。精彩留言会获得点赞!