用于人防指挥的事件监测方法与流程
本发明涉及数据处理,具体是指用于人防指挥的事件监测方法。
背景技术:
1、人防指挥的事件监测方法可以利用多种技术进行实现,包括但不限于自然语言处理、文本挖掘、数据分析和机器学习等技术,通过搭建一个有效的人防指挥事件监测系统,从而帮助管理人员及时了解事件动态,做出及时的决策和应对措施。但是一般事件监测方法存在输入数据的质量差,适应性低,不同频繁模式间关联程度衡量不当从而导致数据挖掘效果差的问题;一般事件监测方法存在术语特异性解释不当,导致无法识别频繁模式的重要性,对事件的重要性评估准确性差的问题。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了用于人防指挥的事件监测方法,针对一般事件监测方法存在输入数据的质量差,适应性低,不同频繁模式间关联程度衡量不当从而导致数据挖掘效果差的问题,本方案基于预先相似度对频繁模式间距离进行改进,可以更好地理解数据集中的模式;基于检查树的单一路径实现不同状态下频繁模式的合并和存储;提高数据挖掘结果的质量和可解释性;针对一般事件监测方法存在术语特异性解释不当,导致无法识别频繁模式的重要性,对事件的重要性评估准确性差的问题,本方案通过改进tf-idf计算术语重要性和特异性从而得到频繁模式权重,基于评估相似矩阵中元素的分散程度实现对事件划分,从而完成事件监测任务。
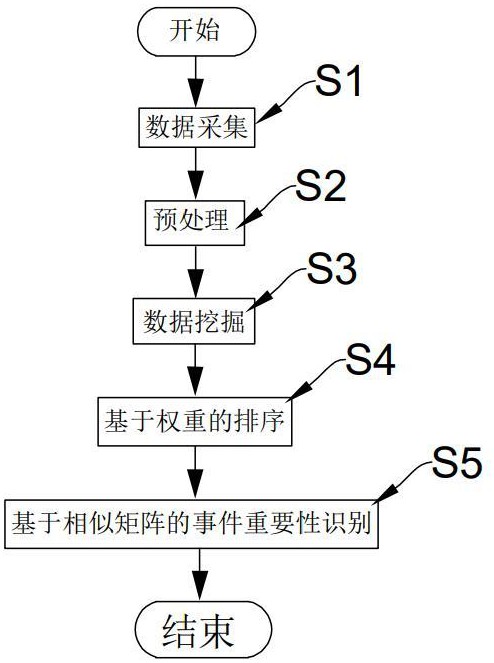
2、本发明采取的技术方案如下:本发明提供的用于人防指挥的事件监测方法,该方法包括以下步骤:
3、步骤s1:数据采集;
4、步骤s2:预处理;
5、步骤s3:数据挖掘;
6、步骤s4:基于权重的排序;
7、步骤s5:基于相似矩阵的事件重要性识别。
8、进一步地,在步骤s1中,所述数据采集是采集人防指挥的事件监测数据,包括社交媒体文本数据、新闻媒体文本数据和论坛博客文本数据。
9、进一步地,在步骤s2中,所述预处理具体包括以下步骤:
10、步骤s21:数据预处理,包括数据清洗、数据转换和建立增量频繁模式树;所述数据清洗是处理缺失值、异常值和重复值;所述数据转换是将清洗后的数据转化为向量形式;所述建立增量频繁模式树是基于fp-growth算法得到增量频繁模式树,并在增量频繁模式树节点数据结构中添加节点结构,最终的增量频繁模式树节点结构包括:节点的唯一标识符名称,用于标识每个节点的唯一性、子节点列表,存储当前节点的所有子节点、指向当前节点的父节点、指向同一层级中当前节点的下一个节点、记录当前节点对应的频繁模式出现的次数和案例标识集合;案例标识集合用caseidset表示,用于标识每个事件的唯一标识符;
11、步骤s22:定义频繁模式间距离,频繁模式指文本关键词的组合,所用公式如下:
12、;
13、;
14、;
15、式中,wmd(·)是频繁模式间距离;tij表示一个从术语i到术语j的术语权重参数;c(i,j)表示从术语i到术语j的距离;fi表示第i个术语在频繁模式f中出现的次数;表示第i个术语在频繁模式中出现的次数;n是术语总数;术语指组成频繁模式的文本关键词;t是术语间权重;
16、步骤s23:定义频繁模式间相似度,所用公式如下:
17、;
18、式中,sim(·)是频繁模式间相似度,f1和f2是两个频繁模式;是l2范数。
19、进一步地,在步骤s3中,所述数据挖掘具体包括以下步骤:
20、步骤s31:检查树是否包含单一路径p:定义α是增量频繁模式树的后缀模式,初始为空;θs是最小支持度阈值;θn是频繁项集的项数阈值;θw是频繁模式间相似度阈值;
21、步骤s32:如果树包含单一路径p,则对路径p中节点的所有组合,并将组合定义为β,执行以下步骤:
22、步骤s321:生成模式β∪α;支持度等于β中节点的最小支持度,支持度是指在数据集中模式出现的频率;
23、步骤s322:检查模式的长度是否等于θn且支持度大于θs:
24、步骤s3221:如果是,则生成频繁模式候选集;
25、步骤s3222:取路径中所有节点的caseidset节点的交集,其中,caseidset是数据挖掘中频繁模式树的一种节点类型;
26、步骤s323:对于每个在f中,其中f是存储所有发现的频繁模式的集合;是f中的频繁模式:
27、步骤s3231:如果和中的每个频繁模式的相似度都低于θw,则将合并到f中;
28、步骤s3232:否则,选择中具有最大频繁模式相似度的,将的术语与caseidset合并,并将其存储在f中,术语指组成频繁模式的关键词;
29、步骤s33:如果树不包含单一路径p:对于树顶部的每个频繁模式ai,执行以下步骤:
30、步骤s331:生成模式β=ai∪α:其中生成模式的支持度等于ai的支持度;
31、步骤s332:检查模式的长度是否等于θn且支持度大于θs:
32、步骤s3321:如果是,则生成频繁模式候选集;
33、步骤s3322:取路径中所有节点的caseidset节点的交集;
34、步骤s333:对于每个中的f;
35、步骤s3331:如果与之间的每个频繁模式相似度都低于θw,则将合并到f中;
36、步骤s3332:否则,选择具有最大的频繁模式相似度的,将的术语和caseidset合并,并存储在f中;
37、步骤s34:输出包含频繁模式的集合f。
38、进一步地,在步骤s4中,所述基于权重的排序具体包括以下步骤:
39、步骤s41:计算术语重要性,所用公式如下:
40、;
41、式中,是第i个术语在第j个文本中的重要性;ni,j是第i个术语在第j个文本中的词频;p是第i个术语所在的文本;k是文本中术语的索引,nk,j是第k个术语在第j个文本中的词频;
42、步骤s42:计算术语特异性,所用公式如下:
43、;
44、式中,ipfi是第i个术语的特异性;是总文档数量;是包含术语gi的文档数量,预先设有词阈值,当术语在文档中出现的次数大于词阈值,则被认为是包含术语的文档,否则被认为不包含术语的文档;
45、步骤s43:计算频繁模式的权重,计算候补权重weight(·),归一化处理后作为频繁模式的权重;所用公式如下:
46、;
47、式中,weight(f)是第频繁模式f的候补权重;
48、步骤s44:排序,基于频繁模式的权重对步骤s3输出的集合f中的频繁模式进行排序。
49、进一步地,在步骤s5中,所述基于相似矩阵的事件重要性识别具体包括以下步骤:
50、步骤s51:构建频繁模式的特征向量,基于排序后的频繁模式集合f中的每个频繁模式,构建特征向量;每个特征向量的维度对应频繁模式集合中的术语数,且特征向量中的每个值为术语的权重;
51、步骤s52:计算余弦相似度,计算任意两个频繁模式特征向量的余弦相似度;
52、步骤s53:构建相似度矩阵,基于计算得到的频繁模式间的相似度,构建相似度矩阵;
53、步骤s54:评估相似矩阵中元素的分散程度,所用公式如下:
54、;
55、式中,γ是相似矩阵元素的离散程度;std(s)是矩阵元素的标准差;是矩阵的范数;
56、步骤s55:事件划分,预先设有评估阈值;当γ大于评估阈值时,步骤s3得到的频繁模式的集合f被视为重要事件的文本集合,对文本涉及事件进行事件监测,及时采取应对措施;否则f被视为非重要事件的文本集合。
57、采用上述方案本发明取得的有益效果如下:
58、(1)针对一般事件监测方法存在输入数据的质量差,适应性低,不同频繁模式间关联程度衡量不当从而导致数据挖掘效果差的问题,本方案基于预先相似度对频繁模式间距离进行改进,可以更好地理解数据集中的模式;基于检查树的单一路径实现不同状态下频繁模式的合并和存储;提高数据挖掘结果的质量和可解释性。
59、(2)针对一般事件监测方法存在术语特异性解释不当,导致无法识别频繁模式的重要性,对事件的重要性评估准确性差的问题,本方案通过改进tf-idf计算术语重要性和特异性从而得到频繁模式权重,基于评估相似矩阵中元素的分散程度实现对事件划分,从而完成事件监测任务。
- 还没有人留言评论。精彩留言会获得点赞!