基于Kaplan‑Meier法的驾驶者发生交通事故间隔时间的计算方法与流程
本发明涉及一种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法。
背景技术:
统计表明,90%的交通事故是由人为因素引起的。在人为因素中,除了少量无意识的危险驾驶行为,82%的属于驾驶者侥幸心理造成的有意识的危险驾驶行为,而这类行为更多的记录在驾驶者历史交通违法中。目前,许多国家已采取在驾照上扣分的政策以规范人们的驾驶行为。既有研究表明:事故发生地交通违法和交通事故间呈正比例的数量关系,且比例不断升高。因此交通违法数据是研究驾驶者危险驾驶行为和交通事故间联系的重要手段。
生存分析是对生存时间进行分析的统计技术总称,其主要特点是可以处理删失数据,删失是指准确生存时间未被观察到的情况。删失又分为左删失、右删失、区间删失。此次研究数据中皆为右删失,即由于统计时段结束而某些驾驶者未发生第二次交通事故的情况。因此在统计分析时必须考虑删失数据,否则将会导致结果偏倚。因为理论上生存时间越长,越容易发生删失。此外,驾驶者交通事故时间间隔具有非负且其右偏分布的特征,因此通常基于正态分布的统计分析方法不适用。而生存分析中的kaplan-meier法可以实现利用生存函数对生存时间分布进行展示,其适用于每个观察样本的事件发生时间点或删失发生时间点能够被准确记录下来的生存时间数据。
文章《theimpactoftrafficviolationsontheestimatedcostoftrafficaccidentswithvictims》中,mercedesayuso等人将西班牙2003至2005年发生的交通事故的严重程度及违法类型对交通事故的影响折合成经济损失,使用多项式逻辑回归模型量化各个违法类型对不同严重程度交通事故的影响。接着,使用不同交通违法类型的组合预测事故的严重程度,再通过预测出的各种事故严重程度的可能性计算事故损失。由此得出了以下结论:1.随着事故中违法次数的增加,事故发生的严重程度也在提升;2.不同类型的交通违法组合会造成不同严重程度的交通事故。特殊的,相比于未发生违法的严重交通事故,某些交通违法组合会降低发生严重交通事故的概率。
现有研究大多利用多元逻辑回归、对数线性等模型,从违法对交通事故造成的严重程度讨论了交通违法与交通事故间的关系。这种方法将交通违法作为影响变量之一,得出了不同违法类型对事故严重程度的影响,但是忽略了违法和事故在时间上的联系,即发生不同频次违法数量的驾驶者,其发生交通事故的间隔时间即频率有无关系。
技术实现要素:
针对这一问题,本发明的目的是提供一种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法,以驾驶人违法次数为协变量、事故发生间隔为因变量,使用医学中统计学中常用的生存分析方法,在考虑删失数据的前提下,得出对应驾驶者的生存函数和风险函数,以描述具有不同违法次数的驾驶者其生存时间即事故发生间隔时间的分布特征,解决现有技术中存在的忽略了违法和事故在时间上的联系的问题。
本发明中名称解释如下:
生存分析:一种将生存时间和生存结果综合起来对数据进行分析的一种统计分析方法。
生存函数:个体生存时间t大于等于某一特定时间t的概率。
半数生存时间:50%的个体存活且有50%的个体死亡的时间,又称为中位生存时间。
风险函数:在生存过程中,t时刻存活的个体在t时刻的瞬时死亡率。
kaplan-meier法:即乘积极限法,生存分析的一种非参数法,利用条件概率及概率乘法原理来计算生存率,可利用删失数据,适用于生存时间数据的原始资料(或未分组资料),可用于小、中或大样本;删失数据:研究分析过程中由于某些原因,未能得到所研究个体的准确时间。
本发明的技术解决方案是:
一种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法,包括以下步骤,
s1、选取观测样本,即选择在事故统计时段内发生交通事故1-2次的驾驶者;
s2、计算违法统计时段内步骤s1所选取样本的违法次数并进行分类;
s3、定义事件发生并分类样本数据,包括完全数据和删失数据;
s4、根据步骤s3分类的样本数据,对样本数据计算事故时间间隔,具体为:对完全数据计算两次事件发生时间间隔,对于删失数据计算事件开始到统计时段结束时间间隔;
s5、每位驾驶者为一个观测样本,驾驶者违法次数为自变量、步骤s4得到的事故时间间隔为因变量,建立全样本矩阵;
s6、使用kaplan-meier法处理步骤s5得到的全样本矩阵,得到生存函数估计量和累计风险函数,进而由生存函数估计量得到驾驶者的生存时间即发生交通事故的间隔时间。
进一步地,还包括以下步骤:
s7、对组间生存函数进行差异性检验;
s8、根据步骤s6绘制累计生存函数和累计风险函数曲线。
进一步地,步骤s2具体包括以下步骤:
s21、统计全观测样本在违法统计时段内违法次数,并做违法频次分布直方图;
s22、根据违法频次分布直方图,分类违法程度。
进一步地,步骤s3具体包括以下步骤:
s31、确定观测样本进入期te;
s32、确定观测截止日期td;
s33、定义在te内驾驶者发生交通事故为样本观测起始点;
s34、若样本在截止日期td前再次发生交通事故,则定义此类样本为完全数据,记录这类样本事故再次发生日期tam,m为驾驶者编号;
s35、若样本在截止日期td前未发生交通事故,则定义此类样本为删失数据。
进一步地,步骤s4具体包括以下步骤:
s41、对于完全数据,时间间隔τw=ta-te;
s42、对于删失数据,时间间隔τc=td-te。
进一步地,步骤s6具体包括以下步骤:
s61、计算在ti时刻生存函数估计量
s62、在ti时刻生存函数估计的标准误差
s63、累计分布函数
s64、概率密度函数f(ti)=f′(ti),表示f(ti)的变化速率
s65、风险函数
s66、累计风险函数
本发明的有益效果是:与现有技术相比,该种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法,使用统计学方法,从违法对交通事故发生时间间隔的角度,分析交通违法对事故率的影响。该方法能够得到不同违法次数的驾驶者事故发生时间间隔即生存时间,并能够得到观测时段内不同违法次数的驾驶者瞬时发生交通事故的风险率。
附图说明
图1是本发明实施例基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法的流程示意图。
图2是实施例中交通违法次数统计分类结果的示意图。
图3是实施例中分类后的全样本矩阵的示意图。
图4是实施例中累计生存曲线示意图。
图5是实施例中所得累计风险函数的示意图。
具体实施方式
下面结合附图详细说明本发明的优选实施例。
实施例的一种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法,选取统计时段内发生1-2次交通事故的驾驶者作为观测样本,将统计时段内驾驶者发生交通违法次数作为影响变量,将统计时段内驾驶者发生第一次交通事故时间作为观测起始时间,发生第二次交通事故时间作为截止时间。在统计时段内未观测到发生第二次交通事故作为删失事件,其对应的时间作为删失时间。使用生存分析中的kaplan-meier法研究具有不同违章次数的驾驶者,其事故发生间隔的规律。以此得出具有不同违法次数的驾驶者,单位时间内发生交通事故的风险函数及累积生存函数。
实施例通过观察具有不同历史违法次数的驾驶者,发生交通事故的时间间隔,以此分析交通违法对交通事故的影响。实施例方法使用生存分析中的kaplan-meier法,定量分析一年内不同违法次数分组下的驾驶者发生交通事故的时间间隔函数和累计风险函数。
实施例
一种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法,如图1,包括以下步骤,
s1、选取观测样本,选择在事故统计时段内发生交通事故1-2次的驾驶者。
s2、计算违法统计时段内样本违法次数并进行分类。
步骤s2中计算违法统计时段内样本违法次数并进行分类包括以下步骤:
s21、统计全观测样本在违法统计时段内违法次数,并做违法频次分布直方图;
s22、根据违法频次分布直方图,分类违法程度;
s3、定义事件发生并分类样本数据。
步骤s3中定义事件发生并分类样本数据包括以下步骤:
s31、确定观测样本进入期te;
s32、确定观测截止日期td;
s33、定义在te内驾驶者发生交通事故为样本观测起始点;
s34、若样本在截止日期td前再次发生交通事故,则定义此类样本为完全数据,记录这类样本事故再次发生日期tam,m为驾驶者编号;
s35、若样本在截止日期td前未发生交通事故,则定义此类样本为删失数据。
s4、根据步骤s3分类的样本数据,对完全数据计算两次事件发生间隔时间,对于删失数据计算事件开始到统计时段结束间隔时间。
步骤s4中分类计算间隔时间包括以下步骤:
s41、对于完全数据,时间间隔τw=ta-te;
s42、对于删失数据,时间间隔τc=td-te;
s5、每位驾驶者为一个观测样本,驾驶者违法次数为自变量、事故时间间隔为因变量,建立全样本矩阵。
s6、计算生存函数估计量和累计风险函数,累计风险函数得到的是驾驶者在某一时刻发生交通事故的概率。
步骤s6中计算生存函数估计量和累计风险函数包括以下步骤:
s61、计算在ti时刻生存函数估计量
s62、在ti时刻生存函数估计的标准误差,可以得到s61中生存函数估计量的可信度即误差范围
s63、累计分布函数
s64、概率密度函数f(ti)=f′(ti),表示f(ti)的变化速率
s65、风险函数
s66、累计风险函数
s7、对组间生存函数进行差异性检验。
s8、根据步骤s6绘制累计生存函数和累计风险函数曲线。
实施例的该种基于kaplan-meier法的驾驶者发生交通事故间隔时间的计算方法,使用统计学方法,从不同违法次数的驾驶者发生交通事故间隔的角度,分析交通违法对事故率的影响。该方法使用生存分析中kaplan-meier法,得到不同违法次数的驾驶者,一年356天内发生交通事故的风险函数,并绘制风险曲线。实施例方法估计不同违法次数的驾驶者事故发生时间间隔即生存时间的以及中位生存时间。实施例方法对于含有大量删失数据的交通事故间隔时间,可以将删失数据合理考虑在内。
实例验证
样本数据为某市部分城区发生事故1-2起的驾驶者。样本进入期te为2015年1月1日至2015年3月1日,即以这段时间观测到的驾驶者进行全年跟踪调查。观测截止日期td为2015年12月31日。违法统计时段为2014年1月1日-2014年12月31日。
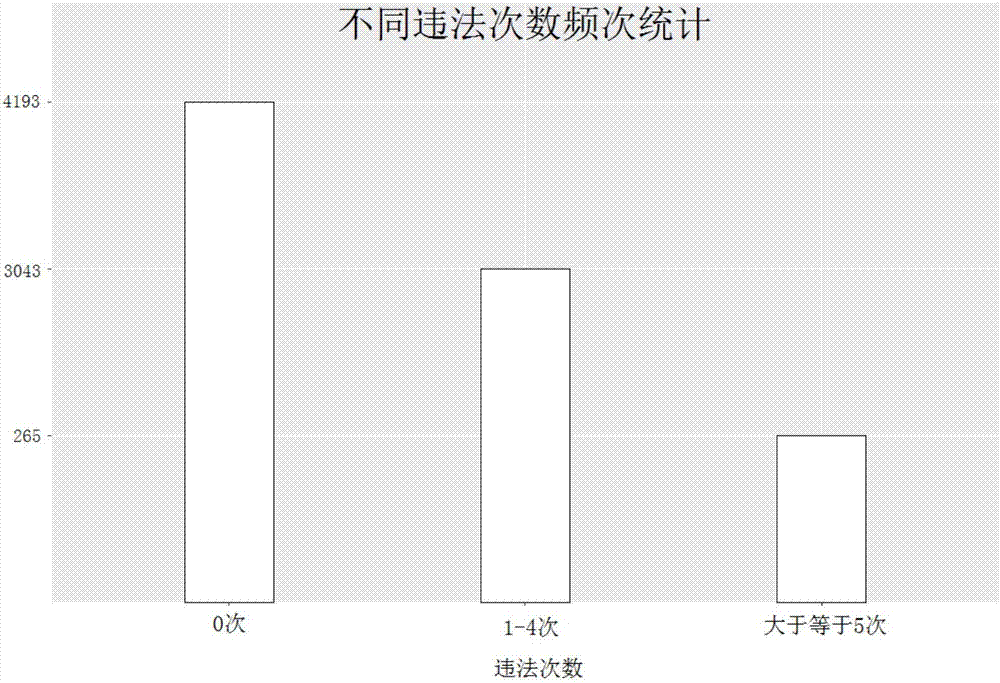
进入观测期的总体样本数量为7501。7501位驾驶者2014年内发生交通违法次数统计分类结果如图2所示:违法0次、1-4次、大于等于5次三组之间频次差异较明显。因此,以上违法次数作为分组变量,将驾驶者分为三组,即违法0次、违法1-4次、违法大于等于5次。定义在2015年3月2日-2015年12月31日期间再次发生交通事故为完全事件,其中对于发生多次交通事故的驾驶者,取第一次发生交通事故时间ta,计算时间间隔τw;定义在2015年3月2日-2015年12月31日期间未发生交通事故为删失事件,计算时间间隔τc。最后得到分类后的全样本矩阵,如图3所示。
利用spss中的生存分析模块的kaplan-meier法,处理图3中的数据,得到包括时刻生存估计量、生存函数估计标准误差、累计分布函数、概率密度函数、风险函数、累计风险函数。
表1为个案处理摘要表。从表1中可得:总体事故数量为7501起,其中删失数据占到60.2%。因此选用生存分析是有必要的。
表1个案处理摘要
表2生存时间的平均值和中值
a.如果已删改估算,那么估算限于最大生存时间。
表2是不同违法次数分组下的驾驶者生存时间的平均值和中位数,中位数即为半数生存时间:50%的个体存活且有50%的个体死亡的时间,又称为中位生存时间。从表2中可以得到:随着违法次数的增加,驾驶员生存时间的平均值、中位数的估算值不断减少。
使用spss-survivalanalysis-comparefactorlevels模块检验不同违法次数分组下的驾驶者生存率曲线的分布是否相同。表3是整体比较检验表,从表3中可以得到:对数值(logrank)检验、breslow检验、tarone-ware检验的显著性水平均低于0.05,因此不同违章类别组间的生存率具有统计学意义。其中logrank检验以各时间点权重一样,检验生存分布是否相同;breslow检验以各时间点的观察例数为权重,检验生存分布是否相同;tarone-ware检验以各时间点的观察例数的平方根为权重,检验生存分布是否相同。
表3整体比较检验结果
绘制累计生存曲线和累计风险曲线如图4、图5所示。图4可以看出线③(违法大于等于5次的驾驶者),其生存时间下降明显快于线②(违法1-4次驾驶者)和线①(无违法)。明显的在第280-290天内高违法次数的人群发生交通事故的概率密度函数最大,对应的这段时间的事故风险率上升最快,瞬时风险率趋向于无穷大,相对观测起始点风险率的三倍。
- 还没有人留言评论。精彩留言会获得点赞!