一种基于自适应加权平均数据融合的路网MFD估测方法与流程
本发明涉及神经网络技术方法领域,更具体地,涉及一种基于自适应加权平均数据融合的路网mfd估测方法。
背景技术:
城市交通拥堵给城市交通带来了巨大的挑战。如何缓解城市交通拥堵问题已成为了众多学者的重点研究方向,学者们提出了各种交通控制策略,在一定程度上有效缓解了城市交通拥堵,但随着车流的不断增大,交通拥堵愈演愈烈,各种交通控制策略将不适用。近期,daganzo和geroliminis两位学者[iiiiiiivv~vi]揭示了宏观基本图(macroscopicfundamentaldiagrams,mfd)的客观存在性,他们认为mfd不仅可以对城市路网从宏观层面进行描述,而且可以监视和预测路网交通运行状态,为从宏观层面对过饱和路网实施交通控制策略提供了新思路,然而如何得到城市路网的mfd又成为一大难点。目前路网mfd可通过固定检测器(如环形感应线圈、微波、视频检测器等)或gps浮动车采集的交通数据来估测。固定检测器数据估测方法(loopdetectordata,ldd估测法)是通过安装在路段的固定检测器实时采集交通数据,然后利用mfd相关理论,估测路网mfd。浮动车数据估测法(floatingcardata,fcd估测法)是通过安装有gps车载终端的车辆(如出租车、公交),实时采集路网浮动车交通数据,采用edie(1963)[vii]提出的行车轨迹估测法,得到路网加权交通流量和加权交通密度,从而估测路网mfd。部分学者对两种估测方法进行了研究,如(courbon等人,2011)[viii]对理论分析法、ldd估测法、fcd估测法等三种路网mfd估测方法进行比较分析,研究固定检测器位置和浮动车覆盖均衡性对mfd估测的影响。(nagle等人,2013)[ix]提出浮动车覆盖率至少15%时,采用fcd估测法,可获得较为准确的路网mfd,但采用这种方法的前提是必须知道浮动车覆盖率,且浮动车在路网的分布是均匀的。(lu等人,2013)[x]利用实际交叉口视频检测数据和出租车浮动数据,估测路网mfd,并发现数据处理时间间隔会影响路网mfd的估测结果.(leclercq等人,2014)[xi]利用实际路网获取的交通数据,比较了ldd估测法和fcd估测法等两种路网mfd估测方法差异,并探讨了两种方法的适用范围。(du等人,2016)[xii]针对浮动车覆盖率在路网中不均匀的实际情况,假定某个特定起点到终点中的浮动车比例是已知的,估测路网交通流量所需的等价浮动车比例,并利用少数浮动车数据估算路网交通流量和交通密度,从而估测路网mfd。但实际上固定检测器只能采集到部分路段的交通数据,未安装固定检测器的路段则无法获取交通数据,而gps浮动车的覆盖率低,交通数据量不足,所估测的路网mfd存在较大的误差。(ambühll等人,2016)[xiii]针对大多数文献都仅采用上述其中一种方法估测路网mfd,很少将两者结合起来的情况,提出了将上述两种方法进行数据融合,从而估测更加准确的路网mfd,但其数据融合算法是经过大量经验实验得到的,并不具有普遍适用性。(金盛等人,2018)[xiv]提出对微波检测器和车牌识别的数据进行融合,构建mfd估测方法,但其数据融合模型以检测器所在路段长度占路网总长度的比例为权重,未考虑交通流离散性和检测器性能对交通参数精度的影响。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于自适应加权平均数据融合的路网mfd估测方法,将ldd估测法和fcd估测法所得的交通数据结合起来考虑,以车联网下100%联网车数据(networkcardata,ncd)估测的交通参数为检验数据,引入动态误差,分别建立路网加权交通流量和路网加权交通密度的自适应加权平均数据融合模型,以便可获得更加准确的路网加权交通流量和路网加权交通密度,从而更加准确地估测路网mfd。在有固定检测器的路段,对固定检测器和浮动车所采集的交通数据进行自适应加权平均数据融合,得到路段加权交通流量和加权交通密度;在没有固定检测器的路段,用浮动车采集的交通数据提取路段加权交通流量和加权交通密度。最后依据数据融合的路网加权交通流量和加权交通密度,估测路网mfd。
为解决上述技术问题,本发明采用的技术方案是:
提供一种基于自适应加权平均数据融合的路网mfd估测方法,具体步骤如下:
(1)将ldd估测法和fcd估测法所得的交通数据结合,对车联网下100%联网车数据估测的交通参数为检验数据,
(2)在步骤(1)之后,引入动态误差,在设有固定检测器的路段,对固定检测器和浮动车所采集的交通数据进行自适应加权平均数据融合,获得路段加权交通流量和加权交通密度;在没有固定检测器的路段,用浮动车采集的交通数据提取路段加权交通流量和加权交通密度;
(3)在步骤(2)之后,分别建立路网加权交通流量和路网加权交通密度的自适应加权平均数据融合模型,获得准确的路网加权交通流量和路网加权交通密度;
(4)在步骤(3)之后,依据数据融合的路网加权交通流量和加权交通密度,估测路网mfd。
优选地,在步骤(1)中,ldd估测法的具体步骤如下:
(1)首先在路网中各路段均安装有固定检测器(如环形线圈检测器、视频采集检测器等),则可直接通过固定检测器采集的路段交通流量和交通密度估测路网mfd,
(2)在步骤(1)之后,依据(geroliminisanddaganzo,2008)所提出的mfd相关理论,可知:
式中:n——路网移动车辆数(veh);
qw、kw、ow——路网加权交通流量(veh/h)、路网加权交通密度(veh/km)、路网加权时间占有率;
i、li——路段i和该路段的长度(km);
qi、ki、oi——路段i的流量(veh/h)、密度(vehk/km)和时间占有率;
s——车辆的平均车长。
优选地,在步骤(1)中,fcd估测法的具体步骤如下:
当路网所有车的轨迹可知时,根据车轨迹可计算出路网的交通流量和交通密度,公式如下:
式中:k——路网交通密度,veh/km;
q——路网交通流量,veh/h;
m——采集周期t内记录的车辆数;
n——路网中路段总数;
tj——采集周期t内第j辆车的行驶时间,s;
li——第i路段的长度,m;
t——采集周期,s;
dj——采集周期t内第j辆车的行驶距离,m;
tm——采集周期t内路网所有车的行驶时间之和,s。
dm——采集周期t内路网所有车的行驶距离之和,s。
若实际很难获取所有车辆的行驶状态(行驶距离和行驶时间),就获取部分浮动车的行驶状态;nagle(2014)提出假定浮动车在路网中的比例ρ已知的,且在路网各区域均匀分布,那么依据上述公式,可估算路网的交通流量和交通密度,公式如下:
式中:
m′——采集周期t内记录的浮动车数;
n——路网中路段总数
tj′——采集周期t内第j’浮动车的行驶时间,s;
li——第i路段的长度,m;
t——采集周期,s;
dj′——采集周期t内第j’辆车的行驶距离,m;。
优选地,在步骤(2)中,加权平均法中,确定加权因子是最关键的步骤,基于加权平均法的多源数据融合值的计算公式为:
其中,yi(t)——在t时刻第i种检测方式获得的交通参数;
wi(t)——在t时刻第i中检测方式的加权因子。
优选地,在步骤(2)中,自适应加权平均数据融模型中,
首先要对自适应加权因子的确定,具体如下:
在自适应加权平均法中,引入了动态误差ed,i(t-1),其表达式为:
式中,ed,i(t-1)——在t-1时段第i种检测方法的动态误差;
k——t时段之前的k个时段;
ear,i(t-k)——在t-k时段第i中检测方式的绝对相对误差,其表达式为:
其中,y(t-1)——为t-1时段的实际数据;
yi(t-1)——为t-1时段第i种检测方法的估计数据;
各种检测方式的加权因子随着动态误差的变小而变大,因此,用反比例法确定各检测方式的初始加权因子,表达式为:
为了保证所有检测方式的加权因子之和为1,进行归一化处理,得到最终的加权因子为:
优选地,在步骤(2)中,自适应加权平均数据融模型中,路网mfd估测的两个关键参数为路网加权交通流量和路网加权交通密度,因此需要路网加权交通流量融合模型和路网加权交通密度融合模型,具体的方法步骤如下:
a)输入t-1时刻以前固定检测器估测法和浮动车数据估测法所得的路网mfd参数;
b)以100%联网车获得的mfd参数为实际数据,利用公式(9),计算绝对相对误差;
c)利用公式(8),计算动态误差;
d)利用公式(10),确定初始加权因子;
e)利用公式(11),归一化加权因子;
f)输入t时刻固定检测器估测法和浮动车采集估测法所得的mfd参数;
g)将t时刻估测的mfd参数和归一化加权因子输入自适应加权平均融合模型;
8)输出结果,得到t时刻数据融合后的mfd参数。
另外,为了验证ldd估测法、fcd估测法、自适应加权平均数据融合模型与ncd估测法所得的路网mfd差异性,采用状态比(trafficstateratio,r)来评估各种估测方法的路网mfd差异性,其公式如下:
式中,run——非拥堵状态下的路网mfd参数状态比;
rco——拥堵状态下的路网mfd参数状态比;
kt,qt——t时刻的路网加权交通密度和路网加权交通流量;
kc,qc——路网临界加权交通密度和路网临界加权交通流量;
kj——路网阻塞交通密度,即加权交通流量为0时的路网加权交通密度。
因此,路网mfd差异性可以理解为状态比的差异,定义δ为不同估测法所得的路网mfd差异,δ越大说明路网mfd差异越大,反之差异越小,其表达式为:
式中,
与现有技术相比,本发明的有益效果是:
本发明提供一种基于自适应加权平均数据融合的路网mfd估测方法,将ldd估测法和fcd估测法所得的交通数据结合起来考虑,以车联网下100%联网车数据(networkcardata,ncd)估测的交通参数为检验数据,引入动态误差,分别建立路网加权交通流量和路网加权交通密度的自适应加权平均数据融合模型,以便可获得更加准确的路网加权交通流量和路网加权交通密度,从而更加准确地估测路网mfd。在有固定检测器的路段,对固定检测器和浮动车所采集的交通数据进行自适应加权平均数据融合,得到路段加权交通流量和加权交通密度;在没有固定检测器的路段,用浮动车采集的交通数据提取路段加权交通流量和加权交通密度。最后依据数据融合的路网加权交通流量和加权交通密度,估测路网mfd。。
附图说明
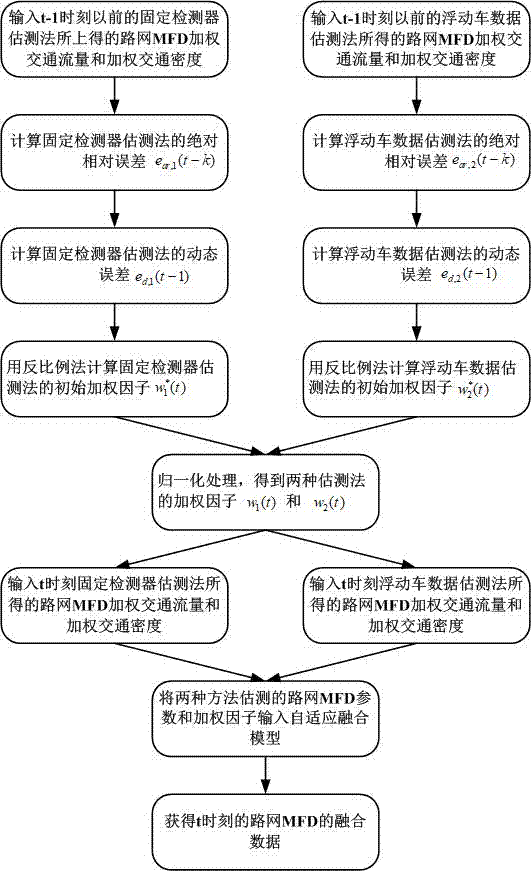
图1为实施例路网加权交通流量融合模型的自适应加权平均数据融合流程图。
图2为天河区核心路网布局图。
图3为各种估测方法的路网加权交通流量对比的示意图。
图4为各种估测方法的路网加权交通密度对比的示意图。
图5为各种估测方法所得的路网mfd的示意图。
图6为各种估测方法所得的路网mfd的示意图。
图7为各估测法所得的路网mfd状态对比的示意图。
图8为各估测法与ncd法所得的路网mfd差异值的示意图。
具体实施方式
下面结合具体实施方式对本发明作进一步的说明。其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本专利的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
实施例
如图1至7所示为本发明一种基于自适应加权平均数据融合的路网mfd估测方法的实施例,具体步骤如下:
(1)将ldd估测法和fcd估测法所得的交通数据结合,对车联网下100%联网车数据估测的交通参数为检验数据,
(2)在步骤(1)之后,引入动态误差,在设有固定检测器的路段,对固定检测器和浮动车所采集的交通数据进行自适应加权平均数据融合,获得路段加权交通流量和加权交通密度;在没有固定检测器的路段,用浮动车采集的交通数据提取路段加权交通流量和加权交通密度;
(3)在步骤(2)之后,分别建立路网加权交通流量和路网加权交通密度的自适应加权平均数据融合模型,获得准确的路网加权交通流量和路网加权交通密度;
(4)在步骤(3)之后,依据数据融合的路网加权交通流量和加权交通密度,估测路网mfd。
其中,在步骤(1)中,ldd估测法的具体步骤如下:
(1)首先在路网中各路段均安装有固定检测器(如环形线圈检测器、视频采集检测器等),则可直接通过固定检测器采集的路段交通流量和交通密度估测路网mfd,
(2)在步骤(1)之后,依据(geroliminisanddaganzo,2008)所提出的mfd相关理论[1~6],可知:
式中:n——路网移动车辆数(veh);
qw、kw、ow——路网加权交通流量(veh/h)、路网加权交通密度(veh/km)、路网加权时间占有率;
i、li——路段i和该路段的长度(km);
qi、ki、oi——路段i的流量(veh/h)、密度(vehk/km)和时间占有率;
s——车辆的平均车长。
另外,在步骤(1)中,fcd估测法的具体步骤如下:
当路网所有车的轨迹可知时,根据车轨迹可计算出路网的交通流量和交通密度,公式如下:
式中:k——路网交通密度,veh/km;
q——路网交通流量,veh/h;
m——采集周期t内记录的车辆数;
n——路网中路段总数;
tj——采集周期t内第j辆车的行驶时间,s;
li——第i路段的长度,m;
t——采集周期,s;
dj——采集周期t内第j辆车的行驶距离,m;
tm——采集周期t内路网所有车的行驶时间之和,s。
dm——采集周期t内路网所有车的行驶距离之和,s。
若实际很难获取所有车辆的行驶状态(行驶距离和行驶时间),就获取部分浮动车的行驶状态;nagle(2014)提出假定浮动车在路网中的比例ρ已知的,且在路网各区域均匀分布,那么依据上述公式,可估算路网的交通流量和交通密度,公式如下:
式中:
m'——采集周期t内记录的浮动车数;
n——路网中路段总数
tj'——采集周期t内第j’浮动车的行驶时间,s;
li——第i路段的长度,m;
t——采集周期,s;
dj'——采集周期t内第j’辆车的行驶距离,m;。
其中,在步骤(2)中,加权平均法中,确定加权因子是最关键的步骤,基于加权平均法的多源数据融合值的计算公式为:
其中,yi(t)——在t时刻第i种检测方式获得的交通参数;
wi(t)——在t时刻第i中检测方式的加权因子。
另外,在步骤(2)中,自适应加权平均数据融模型中,
首先要对自适应加权因子的确定,具体如下:
在自适应加权平均法中,引入了动态误差ed,i(t-1),其表达式为:
式中,ed,i(t-1)——在t-1时段第i种检测方法的动态误差;
k——t时段之前的k个时段;
ear,i(t-k)——在t-k时段第i中检测方式的绝对相对误差,其表达式为:
其中,y(t-1)——为t-1时段的实际数据;
yi(t-1)——为t-1时段第i种检测方法的估计数据;
各种检测方式的加权因子随着动态误差的变小而变大,因此,用反比例法确定各检测方式的初始加权因子,表达式为:
为了保证所有检测方式的加权因子之和为1,进行归一化处理,得到最终的加权因子为:
其中,在步骤(2)中,自适应加权平均数据融模型中,路网mfd估测的两个关键参数为路网加权交通流量和路网加权交通密度,因此需要路网加权交通流量融合模型和路网加权交通密度融合模型,具体的方法步骤如下:
a)输入t-1时刻以前固定检测器估测法和浮动车数据估测法所得的路网mfd参数;
b)以100%联网车获得的mfd参数为实际数据,利用公式(9),计算绝对相对误差;
c)利用公式(8),计算动态误差;
d)利用公式(10),确定初始加权因子;
e)利用公式(11),归一化加权因子;
f)输入t时刻固定检测器估测法和浮动车采集估测法所得的mfd参数;
g)将t时刻估测的mfd参数和归一化加权因子输入自适应加权平均融合模型;
h)输出结果,得到t时刻数据融合后的mfd参数。
另外,为了验证ldd估测法、fcd估测法、自适应加权平均数据融合模型与ncd估测法所得的路网mfd差异性,采用状态比(trafficstateratio,r)来评估各种估测方法的路网mfd差异性,其公式如下:
式中,run——非拥堵状态下的路网mfd参数状态比;
rco——拥堵状态下的路网mfd参数状态比;
kt,qt——t时刻的路网加权交通密度和路网加权交通流量;
kc,qc——路网临界加权交通密度和路网临界加权交通流量;
kj——路网阻塞交通密度,即加权交通流量为0时的路网加权交通密度。
因此,路网mfd差异性可以理解为状态比的差异,定义δ为不同估测法所得的路网mfd差异,δ越大说明路网mfd差异越大,反之差异越小,其表达式为:
式中,
本实施例选取广州市天河区核心路网交叉口群作为研究对象,该路网由天河路、天河东路、天河北路、体育西路、体育东路等主干路及部分支路组成,包括7余个平面交叉口,20余个出入口,如图2所示。交通流量数据以scats交通信号控制系统在2017年8月6日高峰小时(18:00-19:00)所检测数据为基础。
(1)以广州市天河区核心路网交叉口群为实验区,依据上述基础数据,利用vissim交通仿真软件建立交通仿真模型,将5%车辆设定为浮动车,在各路段中间位置设置检测器,将100%车辆设定为联网车(特殊的浮动车),构建车联网环境交通模型,用于获得自适应加权平均数据融合模型的校验数据。为了模拟路网从低峰-高峰-拥堵的整个过程,在该路网仿真模型中,模拟交通流从低峰开始,路网边界各路段驶入交通量每隔900s增加100pcu/h,直至至高峰的过饱和状态,共仿真30000s,每隔300s采集1次数据,共采集100次数据。
(2)假设浮动车和联网车每隔5秒上传车辆数、行驶时间、行驶距离等数据,依据fcd估测法,计算每隔300秒的浮动车路网加权交通流量qfcd、浮动车路网加权交通密度kfcd、联网车路网加权交通流量qncd、联网车路网加权交通密度kncd;同样每隔300秒采集各路段检测器的路段交通密度、路段交通流量,依据ldd估测法,计算每隔300秒的路网加权交通流量qldd、和路网加权交通密度kldd。
(3)依据自适应加权平均数据融合流程,在excel中利用宏编程对每个间隔时间的ldd估测法、fcd估测法所得的路网加权交通流量和路网加权交通密度进行自适应加权平均数据融合,最终得到数据融合后的各时段路网mfd路网加权交通流量和路网加权交通密度。
(4)分别生成基于fcd估测的路网mfdf,基于ldd估测的路网mfdl,基于自适应加权平均数据融合估测的mfdawa,基于联网车轨迹的路网标准mfdn,生成拟合函数,计算各拟合函数的临界加权交通密度,临界加权交通流量、阻塞密度,对各种估测法所得的路网mfd进行差异性分析。
对100个周期的qawa、qfcd、qldd、qncd进行数据对比,如图3所示,对100个周期的kawa、kfcd、kldd、kncd进行数据对比,如图4所示。从图3-4可知,fcd估测法所得的路网加权交通流量和路网加权交通密度变化幅度较大,这是因为浮动车数量较少;ldd估测法和车联网估测所得的路网加权交通流量和路网加权交通密度变化较为稳定,且变化趋势较为一致,随着仿真时间的推移,路网加权交通流量和路网加权交通密度逐渐增大,然后在一段时间内维持较稳定的值,接下来又急剧下降,但ldd估测法所得的路网加权交通流量和路网加权交通密度均小于ncd估测的路网加权交通流量和路网加权交通密度,这是因为当到达数据采集间隔时,少部分车辆尚未到达固定检测器。
分析仿真数据,得到qldd、qfcd、qawa与qncd的相对误差绝对值的平均值和kldd、kfcd、kawa与kncd的相对误差绝对值的平均值,如表1、2所示。
表1相对于qncd的相位误差绝对值的平均值
表2相对于kncd的相位误差绝对值的平均值
从表1、表2可知,qfcd和kfcd的相位误差绝对值的平均值最大,分别为11.52%和12.26%;qldd和kldd的相位误差绝对值的平均值次之,分别为8.22%和11.54%;经自适应加权平均数据融合后,qawa和kawa的相位误差绝对值的平均值分别为6.51%和9.56%,最接近标准值qncd和kncd。
利用各种估测数据,生成基于fcd估测法的路网mfdf,基于ldd估测法的路网mfdl,基于自适应加权平均数据融合估测的mfdawa,基于联网车轨迹的路网标准mfdn,如图5所示。
从图5可知,mfdf的散点呈现较大的离散性,mfdl、mfdawa、mfdn的散点较为集中,而且随着仿真时间的推移,路网加权交通流量和路网加权交通密度均逐渐增大,路网加权交通密度从70veh/km开始,路网维持在较高的加权交通流量,随着路网加权交通密度增大,路网加权交通流量急剧下降,路网出现过饱和状态。同时路网mfd还出现了“回滞现象”,符合路网mfd的特性。对各mfd的散点进行数据拟合,得到拟合函数,计算各种拟合函数临界加权交通密度、临界加权交通流量和阻塞密度,如表3所示。
表3各mfd的拟合函数
利用公式12,公式13,计算各种估测方法所得的路网mfd的状态比r和差异值δ,如图6、图7所示。
从图6,图7可知,fcd估测法的路网mfd状态比和差异值变化比较大,lcd估测法和自适应加权平均数融合的状态比和差异值变化比较稳定。计算各估测法的路网mfd差异值绝对值的均值、极大值和极小值,如表4所示:
表4各估测法与ncd估测法所得的路网mfd差异值
从表4可知,fcd估测法所得的路网mfd差异最大,|δ|均值为0.0895,ldd估测法和awa数据融合法所估测的路网mfd差异较小,但awa数据融合法所估测的路网mfd更接近标准路网mfd,其|δ|均值为0.0615。由此可见,自适应加权平均数据融合后的路网mfd更加准确。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!