一种基于驾驶风格的智能网联混合动力汽车编队控制方法与流程
本发明涉及智能网联混合动力汽车技术领域,尤其涉及一种基于驾驶风格的智能网联混合动力汽车编队控制方法。
背景技术:
随着全球能源与环境问题的日益凸显,新能源汽车逐渐成为汽车工业未来发展的方向,而混合动力汽车凭借其油耗低、续航里程长等优势成为目前汽车市场重要的一部分。另一方面,随着移动互联网、人工智能、大数据等新技术的发展,汽车工业也正经历着新的革命,互联网与汽车工业融合是大势所趋。在此背景下,各大汽车企业也加快了这方面的布局,上汽集团就提出了“新四化”:电动化、网联化、智能化、共享化。
一直以来,人、车、路是一个密不可分的整体,而智能交通、车联网、信息交互等技术的发展也促进了智能网联汽车和智能驾驶辅助系统的发展,实现人、车、路三者协同工作,对提升道路交通环境的安全性和高效性有重要意义。另外,能够进一步完善混合动力汽车实时能量管理策略,而能量管理策略又是混合动力汽车节能减排效果的关键。
智能网联汽车能够获取道路交通信息和周围车辆信息也能发送自己的车辆信息进行信息交互,通过对智能网联混合动力汽车编队控制,能够避免碰撞和不必要的加减速,以及在路口长时间等红灯的情况发生,对提高道路通行能力、交通安全性、车辆燃油经济性有重要作用。
目前结合车联网和混合动力汽车的研究大多针对单辆车,或者只考虑安全性,没有在规划车速时将燃油经济性也考虑进去。对队列控制方面的研究比较少,而且并没有考虑驾驶员的驾驶误差对车速的影响。
技术实现要素:
为解决上述存在的问题,本发明提出一种基于驾驶风格的智能网联混合动力汽车编队控制方法,该方法达到提升道路通行能力和提高车辆燃油经济性的目的,同时为混合动力汽车结合智能交通环境与智能辅助驾驶提供了新的方向。
本发明采用如下技术方案:一种基于驾驶风格的智能网联混合动力汽车编队控制方法,包括如下步骤:
智能交通信息:基于车联网环境,采集实时路况和交通信号灯信息,以及自车和前后车位置、车速、加速度信息;
最优车速规划:根据交通信号灯信息求解目标车速范围,目标车速范围的上限为初始目标车速;建立整车纵向动力学模型和油耗模型,并利用粒子群滚动优化算法求解多目标问题得到最优车速;
误差补偿计算:基于不同驾驶员跟踪目标车速所得到的误差样本数据,利用bp神经网络进行误差预测并结合补偿算法求解出指令车速,并将求解出的指令车速传递给驾驶员;
能量管理:驾驶员根据指令车速进行加速或者制动,能量管理控制器根据加速或制动信息求解发动机和电机的最优转矩并进行指令传送和控制执行。
进一步的,所述最优车速规划中,根据交通信号灯信息求解目标车速范围,如下式:
其中
进一步的,所述最优车速规划中的整车纵向动力学模型如下式:
其中xm=[sm,vm],为第m辆车的状态变量,sm和vm分别该辆车的所处位置和速度,
油耗模型如下式:
其中mmfuel为等效燃油消耗率,ηmeff为油箱到传动系统的效率,h为汽油的低热值,pmw(t)=0.5ρacdamvm(t)3+μmmgvm(t)+mmgθvm(t)+mmvm(t)dvm(t)/dt,为需求功率;vm(t)在t时刻,第m辆车的车速。
进一步的,所述最优车速规划中的多目标问题如下:
其中t为预测时域;
进一步的,所述最优车速规划中的粒子群滚动优化算法包括以下步骤:
最优控制序列预测:在采样时刻,根据纵向动力学模型和目标函数,利用粒子群算法进行预测时域内的最优控制序列预测;将得到的最优控制序列中的第一个控制量作为实际控制量;
滚动优化:在下一采样时刻将预测时域向前推进一步,再次进行最优控制序列预测,如此不断重复实现滚动优化。
进一步的,误差补偿计算中,利用bp神经网络进行误差预测及补偿算法主要包括以下步骤:
基于不同的驾驶员跟踪目标车速的所得到的误差样本数据,进行bp神经网络训练,当前以及邻近的前三个时刻的车速和加速度作为神经网络的输入,输出下一时刻的车速误差;
把误差补偿计算中得到的最优车速输入训练好的神经网络得到驾驶员驾驶可能产生的误差;
通过补偿算法对误差进行补偿得到指令车速并通过驾驶辅助系统传达给驾驶员。
进一步的,所述能量管理中,指令传送和控制执行主要包括以下步骤:
微处理器将信息处理成执行指令发送给发动机、电机、电池的通信模块;将通信模块将指令通过can总线发送给各控制模块实现能量分配。
本发明具有如下有益效果:
1.将智能网联技术与混合动力汽车能量管理相结合,为优化能量管理提供了新的思路和技术支持。
2.考虑路口交通信号灯、道路限速、前后车运行信息的同时,将燃油消耗也作为一项考虑因素来求解最优车速,最后通过能量管理再一次减少燃油消耗,有效提高了车辆燃油经济性。
3.考虑不同驾驶风格对汽车速度的影响,对最优车速进行处理后通过智能驾驶辅助系统传达给驾驶员,使车辆最终的速度更接近于最优车速。
4.运用本方法能够提高道路通行效率、交通安全性、车辆燃油经济性和排放性能。
5.本发明结合智能交通系统和驾驶员驾驶风格,求解驾驶辅助系统的指令速度,并对混合动力汽车进行实时能量管理控制,达到了提升道路通行能力和提高车辆燃油经济性的目的,为混合动力汽车结合智能交通环境与智能辅助驾驶提供了新的方向。
附图说明
图1为本发明基于驾驶风格的智能网联混合动力汽车编队控制的原理图;
图2为本发明技术路线图;
图3为本发明的粒子群滚动优化算法示意图;
图4为本发明bp神经网络结构图;
图5为交通信号灯时空分布示意图。
具体实施方式
为对本发明做进一步的了解,现下面结合技术方案和附图详细叙述:
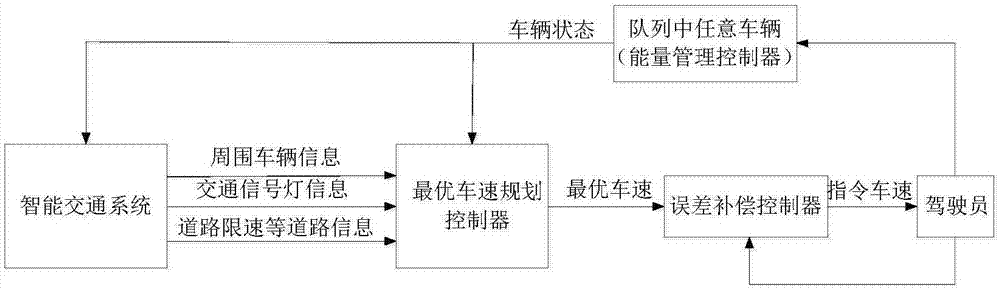
结合附图1,在智能交通系统中,车辆可以获得周围车辆信息、交通信号灯信息等其他道路信息,根据这些信息,最优车速规划控制器可以求解出最优车速。误差补偿控制器根据最优车速以及预测的误差,求得指令车速,并将其传达给驾驶员。能量管理控制器根据驾驶员的加速或制动信息,对车辆的发动机和电机进行转矩并分配。
结合附图2,技术路线可分为上层控制和下层控制。上层控制包括:信号灯信息模型建模并利用信号灯信息求解初始目标车速,在此基础上建立多目标函数并设计预测控制算法求解最优车速。再利用bp神经网络预测误差,结合最优车速进行误差补偿,得到指令车速。下层控制包括:建立驾驶员以及整车和能量管理控制策略模型。最后对上下层联合仿真得到的结果进行分析。
一种基于驾驶风格的智能网联混合动力汽车编队控制方法,具体包括如下步骤:
步骤一:基于车联网环境,采集实时路况和交通信号灯信息,以及该车和前后车位置、车速、加速度等信息;
步骤二:根据交通信号灯信息求解目标车速范围,如下式:
式中
结合附图5,rij为第i个路口的信号灯的第j个红灯窗口开始的时刻,gij为第i个路口的信号灯的第j个绿灯窗口开始的时刻,vmin和vmax分别为所在道路所允许的车辆最小和最大车速。
该车速范围的上限即为初始目标车速。
步骤三:为求解最优车速,需要建立整车纵向动力学模型和油耗模型,并建立多目标函数,并采用粒子群滚动优化算法进行求解。具体步骤如下:
①建立整车纵向动力学模型:
其中xm=[sm,vm],为第m辆车的状态变量,sm和vm分别该辆车的所处位置和速度,
②建立油耗模型:
其中mmfuel为等效燃油消耗率,ηmeff为油箱到传动系统的效率,h为汽油的低热值,pmw(t)=0.5ρacdamvm(t)3+μmmgvm(t)+mmgθvm(t)+mmvm(t)dvm(t)/dt,为需求功率。
③建立多目标函数如下:
其中t为预测时域;
结合附图3,④利用粒子群滚动优化算法进行求解,具体如下:
a、在每一采样时刻,根据纵向动力学模型和目标函数,利用粒子群算法进行预测时域内的最优控制序列预测。而粒子群算法具体包括种群初始化;计算目标函数值、个体最优值pbest及全局最优值gbest;更新粒子的位置和速度,如下式:
式中
b、控制序列的第一个控制量作为实际控制量作用于系统,在下一采样时刻将预测时域向前推进一步,如此不断重复实现滚动优化;
步骤四:由于驾驶风格会影响最终车速,因此要对最优车速进行处理后传达给驾驶员一个指令车速,从而使车辆实际速度更接近于最优车速。具体如下:
①基于不同驾驶风格的驾驶员跟踪目标车速所得到的误差样本数据,进行bp神经网络训练,bp神经网络结构如图4,当前以及邻近的前3个时刻的车速和加速度作为神经网络的输入,输出下一时刻的车速误差,可表示为:
error(k+1)=f[v(k),v(k-1),v(k-2),v(k-3);u(k),u(k-1),u(k-2),u(k-3)]
②把之前得到的最优车速输入训练好的神经网络得到驾驶员驾驶可能产生的误差;
③通过补偿算法对误差进行补偿得到指令车速,并传达给驾驶员。
步骤五:在simulink中建立驾驶员模型、混合动力整车模型以及能量管理控制策略并进行仿真。即驾驶员根据指令车速进行加速或制动,能量管理控制系统根据加速或制动信息求解发动机和电机的最优转矩并进行指令传送和控制执行,指令传送和控制执行主要包括以下步骤:微处理器将信息处理成执行指令发送给发动机、电机、电池的通信模块;通过通信模块将指令通过can总线发送给各控制模块实现能量分配。
注:bp神经网络为反向传播神经网络(back-propagationneuralnetwork)
所述实施例为本发明的优选的实施方式,但本发明并不限于上述实施方式,在不背离本发明的实质内容的情况下,本领域技术人员能够做出的任何显而易见的改进、替换或变型均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!