基于分布式深度循环Q网络的交通灯控制方法与流程
本发明属于交通控制领域,特别涉及一种交通灯控制方法,可用于城市交通管理,减少城市交通拥堵。
背景技术:
利用强化学习解决城市交通灯控制已经在20世纪出现,suttonr.rs等人成功将sarsa应用于交通灯控制,这也是世界学术上第一次在交通灯控制算法中应用强化学习。balajipg利用分布式多路口s模型解决交通灯控制问题,每个路口都有独立的q表学习并判断执行相位,实验证明了q学习在交通灯控制算法中的有效性。wieringma使用车辆交通状态建模的强化学习模型,通过计算路口在红绿灯的最大收益确定最优动作相位。
jinj等人在ei上发表的论文中提出一种分层架构建立交通灯控制模型,模型主要分为三层,最底层为城市路口,利用knn算法计算邻居未访问状态的q值,并通过时间差异函数与合格迹线函数计算单路口的q值,选择执行最优策略即max策略值,然后通过层次之间的通信完成区域间路口通信,利用欧几里得公式计算各路口间的权重,最后形成城市路网的通信,但其计算复杂度高,易出现状态空间爆炸的问题。
chut在ieee上发表的论文中提出一种最小通信进行分布式强化学习的模型,解决多路口交通灯控制,其主要是将分布式系统划分为小系统,通过计算每个小系统的q通信消耗,然后选择最小值q,总体系统q值表示为众多小系统最小q的和,虽然该方法中提到了协作图的原理,但没有实现多路口之间的协作,各路口的执行相位仅跟该路口自身的状态有关,并没有利用到邻居路口的状态、动作对值。
中国城市人口数的增长已经严重影响到城市交通的发展,如何高效的解决城市交通的拥堵问题及发展智慧城市交通已成为我国急需解决的问题,最近几年我国研究学者也在城市交通灯控制邻域取得了优异的成绩。
伦立宝在2013年发表的论文中利用启发式强化学习计算路口红绿灯收益来获取下一时刻单路口执行相位,并利用协作图和多路口s协作的概念,考虑多路口之间交通灯的协作调配,实验表明利用强化学习的多路口s协作算法虽然优于定时系统和max-plus等算法,但是依旧存在状态空间爆炸的问题。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种基于分布式深度循环q网络ddrqn的交通灯控制方法,以实现各路口之间的协作,避免出现状态空间爆炸的问题。
为实现上述目的,本发明的技术方案包括如下步骤:
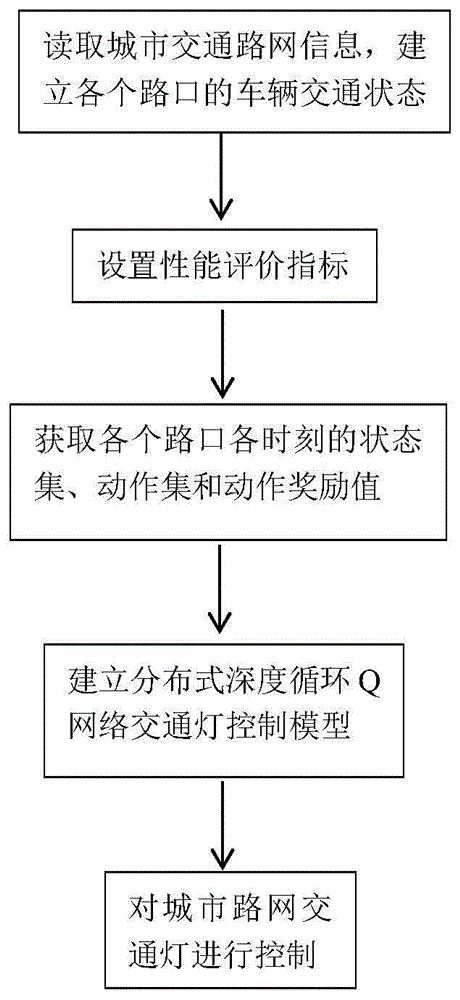
(1)读取城市交通路网信息,建立各个路口的车辆交通状态集合,并采用协作图的方法将读取的城市交通路网信息转换为邻接矩阵进行存储;
(2)根据实际路网中的车辆等待时间和车辆到达目的地数量,设置通用的性能评价指标;
(3)从(1)建立的各个路口车辆交通状态集合中获取各个路口各时刻的状态集、动作集和动作奖励值;
(4)根据(3)获取的信息和(1)中的邻接矩阵,建立分布式深度循环q网络交通灯控制模型:
4a)将路口的历史状态值
将每一个历史时刻的数据都按照上述的公式计算,直到当前时刻t的前一时刻t-1,将t-1时刻的隐藏层状态
4b)从邻接矩阵获取路口m的四个邻接路口me、mw、ms、mn的状态值
第一个邻接路口的隐藏层状态为
第二个邻接路口的隐藏层状态为
第三个邻接路口的隐藏层状态为
第四个邻接路口的隐藏层状态为
将第四个邻接路口的隐藏层状态
4c)将路口m自身历史数据训练得到的输出
(5)根据(4)构建的模型对城市路网交通灯进行控制:
5a)初始化路网中路口的邻接矩阵及分布式深度循环q网络中的学习率α=0.25、折扣因子γ=0.9、ε-贪心策略中的ε=0.01、网络参数θ=0、迭代上限t=1000、迭代次数t=1、隐藏层状态h=0;
5b)根据ε-贪心策略选择路口的执行动作;
5c)对每一个路口执行所选择的动作,并计算获取分布式深度循环q网络的即时奖励;
5d)计算分布式深度循环q网络的损失函数误差,更新网络参数θ;
5e)设t=t+1,将邻接矩阵中的路口状态st转变为st+1,
5f)判断迭代是否停止,若t小于迭代上限t,转5b),否则,停止。
本发明与现有方法相比有如下优点:
第一,本发明将基于分布式深度循环q网络来实现多路口之间的合作,通过训练学习后各个路口之间会达成一致的协作协议,彼此之间通过满足协作协议来实现多路口之间的合作,使得全局的奖励最大,单位时间内全局通过各个路口的车辆更多,在最大程度上缓解城市交通的压力;
第二,本发明基于分布式深度循环q网络实现各路口之间的协作,各路口之间的协作通过自身历史状态、动作值和所有邻居的上一时刻的路口交通状态、动作值来反应,一方面可以很明确的体现邻居之间是如何合作以及明确了解到邻居路口的交通状态,另一方面解决强化学习中存储q表导致状态空间爆炸问题。
附图说明
图1为本发明的实现流程图;
图2为本发明路网中的一个路口示意图;
图3为本发明中的城市路口协作图;
图4为本发明中的城市路网交通状态图;
图5为本发明中基于分布式深度循环q网络交通灯控制模型图;
图6为本发明中多个路口的交通网络仿真图;
图7为本发明多路口中的任意单路口示意图;
图8为本发明在轻度交通流情况下分布式深度循环q网络与其他控制方法的路口平均等待时间at对比图;
图9为本发明在轻度交通流情况下分布式深度循环q网络与其他控制方法的车辆平均行驶等待时间aj对比图;
图10为本发明在重度交通流情况下分布式深度循环q网络与其他控制方法的路口平均等待时间at对比图;
图11为本发明在重度交通流情况下分布式深度循环q网络与其他控制方法的车辆平均行驶等待时间aj对比图。
具体实施方式
下面结合附图,对本发明实例和效果作进一步的详细描述。
参照图1,本实例的实现步骤如下:
步骤1,读取城市交通路网信息,建立各个路口的车辆交通状态集合t。
1a)通过openstreetmap地图平台导出城市交通路网信息,如图6所示;
根据导出的城市交通路网信息,建立各个路口的车辆交通状态集合
其中:i:表示路网中任意一个路口;
li:表示路网中某个路口的全部入口车道;
tli:表示任意路口的入口车道所对应的交通灯;
ai:表示交通灯tli的动作,交通灯的动作对应于交通灯的状态,一个路口交通灯含有八种相位动作,如图2所示;每个路口的动作与相位动作相匹配的关系如表1所示:
表1路口动作与相位关系
1b)读取城市交通路网信息,获取路网的全局最优解。
1b1)采用协作图的方法将读取的城市交通路网信息转换为邻接矩阵进行存储:
建立城市路网的协作图,如图3所示,其中e(i,j)表示相邻路口之间的依赖性,将openstreetmap地图平台导出的城市交通路网信息转换为邻接矩阵进行存储,在判断某一路口的邻居时可直接查阅邻接矩阵;
1b2)将路网全局的协作问题分割为不同的局部问题,通过计算局部的最优解来获取路网的全局最优解:
根据协作图的连通性,在计算某一路口的最优解时,获取该路口四个邻接路口的交通状态和交通灯的动作,每一个邻接路口在计算最优解时又可获取与之相邻的四个邻接路口的信息,以此类推,通过计算各相邻路口的最优解,累计求和获得路网的全局最优解。
步骤2,根据路网中的车辆等待时间和车辆到达目的地数量,设置通用的性能评价指标。
2a)通过sumo交通仿真软件获取路网中的车辆等待时间和车辆到达目的地数量;
2b)根据获取的车辆等待时间和车辆到达目的地数量,设置性能评价指标:包括路口平均等待时间aj、车辆平均行驶等待时间at和到达目的地的总车辆数v:
2b1)路口平均等待时间aj,用于反应单个车辆在路口的平均等待时间,定义如下:
其中,pt为通过路口的所有车辆总的等待时间,n为通过该路口的车辆总数,aj越小,说明路口拥堵时间越少,反之,路口拥堵时间越长;
2b2)车辆平均行驶等待时间at,用于反应单个车辆行车全程所需的平均等待时间,定义如下:
其中,dt为所有到达目的车辆总的等待时间,n为车辆总数,at越小,说明路口拥堵时间越少,反之,路口拥堵时间越长;
2b3)到达目的地的总车辆数v,是通过sumo交通仿真软件统计得到,v值越大,说明路口拥堵时间越少,反之,路口拥堵时间越长。
步骤3,从建立的各个路口车辆交通状态集合中获取各个路口各时刻的状态集、动作集和动作奖励值。
3a)获取各个路口各时刻的状态集:
先将任意路口从停车线开始至长度为180m的车道划分成若干个单元格,每个单元格长度为6m,使得满足每个单元格仅可占据一辆车;
再用布尔变量来表示单元格内车辆存在与否,1表示存在车辆、0表示不存在车辆,路口的交通状态如图4所示,将该路口的状态转化为矩阵表示为:
3b)获取各个路口各时刻的动作集:
基于城市交通灯的动作集获取各个路口各时刻的动作集a={a0,a1,…,a7},如表1所示,再按如下规则修改交通灯动作的执行时长:
3b1)为避免交通灯的频繁切换导致交通混乱及成本代价的提升,设置交通灯任意相位执行时长最大时长为70s,最小为10s;
3b2)当选定路口某一相位动作时首先执行10s的时长,若下一执行相位不同,则10s后更换执行相位,若超过10s后仍为该执行相位,则在该相位时长上累加4s,直至执行相位更换;
3b3)当执行某一相位时长达到70s时,则不再执行改相位,直接将该路口动作替换为下一相位执行。
3c)计算各个路口各时刻的动作奖励值,其由车辆排队长度决定:
车辆排队长度是通过sumo交通仿真软件得到,若车辆排队长度在减少,则动作奖励值为:
否则,动作奖励值为:
其中,c1和c2为比例系数,其取值均为0.5;ni为在两个时间片之间通过的车辆数;ti为动作执行时间;n0为单位时间内经过的车辆数量的一半;r0表示额外奖励;
步骤4,建立基于分布式深度循环q网络的交通灯控制模型,如图5所示。
4a)将路口的历史状态值
4b)按照4a)中的公式计算每一个历史时刻的隐藏层状态,直到当前时刻t的前一时刻t-1时刻,并将t-1时刻的隐藏层状态
4c)从邻接矩阵获取路口m的四个邻接路口me、mw、ms、mn在t-1时刻的状态值
第一个邻接路口的隐藏层状态为:
第二个邻接路口的隐藏层状态为:
第三个邻接路口的隐藏层状态为:
第四个邻接路口的隐藏层状态为:
将第四个邻接路口的隐藏层状态
4d)将路口m自身历史数据训练得到的输出
步骤5,根据步骤4建立的分布式深度循环q网络交通灯控制模型,对城市路网交通灯进行控制。
5a)初始化路网中路口的邻接矩阵及分布式深度循环q网络中的学习率α=0.25、折扣因子γ=0.9、ε-贪心策略中的ε=0.01、网络参数θ=0、迭代上限t=1000、迭代次数t=1、隐藏层状态h=0;
5b)根据ε-贪心策略,由随机数rand选择路口的执行动作
若rand<ε,则从动作集a={a0,a1,…,a7}中随机选择动作
否则,执行动作
5c)对每一个路口执行所选择的动作,并根据步骤3计算获取分布式深度循环q网络的即时奖励r;
5d)计算分布式深度循环q网络的损失函数误差▽θ,更新网络参数θi和θi-:
5d1)计算损失函数误差:
5d2)利用损失函数误差▽θ更新网络参数θi和θi-,得到更新后的网络参数:
θi+1=θi+α▽θ
其中,θi为权重共享参数,θi-为目标网络参数,α是θi的学习率,α—是θi-的学习率。
5e)设t=t+1,将路口状态st转变为st+1,
5f)判断迭代是否停止:若t小于迭代上限t,返回5b),否则,停止迭代,完成对城市路网交通灯的控制。
本发明的效果可通过以下实验做进一步说明。
一.仿真条件
本实验通过sumo软件仿真实现,sumo是开源、时间离散和道路空间连续的交通仿真软件,本实例使用的版本为v0.32.0。sumo主要功能有创建路网、仿真、交通模拟等,图6是通过openstreetmap地图平台导出,利用sumo命令及josm软件获取路口id合成含有车流及红绿灯的实验路网图;
使用traciapi程序接口实现与sumo的交互并获取实时交通状态及按照设计的算法逻辑控制交通灯和仿真数据的采集;为加快神经网络的训练安装gpu版本的tensorflow;安装集成python环境的anaconda,算法逻辑与神经网络利用python实现。
路口:在图6中含有50个路口,其中包含了十字路口、t字路口、直角路口等,如图7所示。图6中红色数字标注了21个有红绿灯的路口,这些路口基本都是主干道上的路口,其交通流相对较大,本实例通过路口2、3、4、11、17五处路口做仿真数据采集,通过josm获取图6中的路口id。
车辆类型:在本实例中只产生公交车bus和小汽车car这两种类型车。car车长为4m,bus车长为8m,其中bus占用两个车道单元格;车间距为最小1.5m,起步速度为5m/s,最大速度为12m/s。
车流量设置:由于当每条道路产生频率值大于等于0.4时都会不可避免产生交通拥堵或堵塞,当小于0.4时则不会造成严重的交通拥堵,因此将每条道路车辆产生频率大于等于0.4定义为重度交通流环境,小于0.4定义为轻度交通流环境。
仿真实验方法:交通信号控制方法tc1、基于交叉口-信号灯的交通信号控制方法tclj、基于消息传递的交通信号控制方法maxpluslj、基于置信传播的交通信号控制方法maxplusjj及本发明方法,共5种方法。
参数设置:初始化参数:设折扣因子γ=0.9,ε-贪心策略中的ε=0.01。
二.仿真实验内容
仿真实验1:用本发明方法和上述现有四种交通控制方法在轻度交通流环境下进行城市路网交通灯控制仿真,仿真得到的平均评价指标值如表2所示,仿真得到的路口的平均等待时间at随时间变化曲线如图8所示,仿真得到的车辆平均行驶等待时间aj随时间变化曲线如图9所示。
表2轻度交通流情况下ddrqn和其他四种控制方法仿真交通性能评价指标平均值
图8、图9和表2表明在多个路口协同控制的情况下,以上五种方法在轻度交通流控制中控制效果的差异不是很大,都能够对交通灯实现有效的控制,避免发生交通拥堵,使得车辆尽快达到目的地。但从表2可以看出,在轻度交通流环境下,分布式深度循环q网络ddrqn方法和其他四种方法相比,在每个指标上都略优于其他四种方法;从图8和图9的曲线图可以看出分布式深度循环q网络ddrqn指标的波动幅度较小,并在一段时间内快速收敛,并维持相对稳定。
仿真实验2:用本发明方法和其他四种交通控制方法在重度交通流环境下进行城市路网交通灯控制仿真,仿真的平均评价指标值如表3所示,仿真的路口的平均等待时间at随时间变化曲线如图10所示,仿真的车辆平均行驶等待时间aj随时间变化曲线图11所示。
表3重度交通流情况下ddrqn和其他四种控制方法仿真交通性能评价指标平均值
从图10、图11和表3可以看出在重度交通流环境下,交通信号控制方法tc1方法发生了交通拥堵,在交通发生拥堵后再无法有效的控制交通灯,使得整个交通网络陷入瘫痪状态;分布式深度循环q网络ddrqn方法能在重度交通流下有效的控制交通灯实现车辆的流通,并且相对于其他四种方法,在重度交通流下路口的平均等待时间at和车辆平均行驶等待时间aj都要小,并且等待时间的波动幅度也明显小于其他方法,能够更加平稳的控制交通灯,从而解决重度交通流环境下路网中车辆的拥堵问题。
综上,本发明相比较于其他四种方法,在轻度交通流和重度交通流环境下都能有效的解决交通拥堵问题,尤其是在重度交通流环境下可以高效控制交通灯,使得在有限相位执行时间内通过更多的车辆,避免了出现较多车辆等待和排队现象,减少了车辆在路口的平均等待时间,同时减少了路网全部车辆的平均行驶等待时间。
- 还没有人留言评论。精彩留言会获得点赞!