一种基于近端策略优化的小型路网交通信号优化方法与流程
本发明涉及智能交通、人工智能应用领域,具体涉及近端策略优化(proximalpolicyoptimization)算法和小型路网交通信号优化方法。
背景技术:
随着大众生活水平的普遍提高,汽车已成为人们出行最常用的交通工具,但由于道路资源的有限,交通管理协调机制的不科学以及交通决策存在的失误性等因素,城市路网,特别是交叉口处会造成严重的交通拥堵问题。对于某一个具体的交叉口,宽敞的道路和智能交通设备的存在使得该路口不会产生严重的拥堵;而对于多个交叉口连接而成的小型路网,拥堵问题仍然存在,并且是影响区域通行效率的最大因素。
技术实现要素:
为了优化小型路网的交通信号配时方案,改善区域路网的交通拥堵现象,基于实时获取的交通数据,本发明提出一种基于近端策略优化的小型路网交通信号控制方法,对于小型路网提出的基于近端策略优化的交通信号优化配时方案可以有效提高交通通行效率,而且可以增加区域内不同交叉口之间的协作,应对交通的动态性变化。
本发明解决其技术问题所采用的技术方案是:
一种基于近端策略优化的小型路网交通信号控制方法,包括以下步骤:
1)利用路网交叉口处的交通数据信号传感器,实时获取小型路网中(井字型四交叉口)的交通数据,为车辆的相对坐标信息和信号灯在对应时刻所处的相位信息,确定处于排队状态的车辆,保存在原始数据集中;
2)原始数据预处理,删去离谱的数据并用前一时刻的数据填补缺失的数据,获取具体交叉口处的排队长度-相位编号集合{qi,j,pi},其中,qi,j表示当前时刻第i交叉口第j车道处的车辆排队长度,pi代表当前时刻第i交叉口处的信号灯灯态,在该发明中,i=1,2,3,4,j=1,2,...,7,8;按照路网中交叉口的排列顺序,将集合{qi,j,pi}整合得到整个路网在当前时刻的排队长度-相位编号数据集st,t为当前的时刻;
3)利用路网的排队长度-相位编号集st,初始化神经网络权重,利用近端策略优化方法ppo更新网络参数,寻找当前交通环境下的最优信号灯配时方案;
4)保存最终收敛的神经网络训练参数,得到该路网下基于近端策略优化的交通信号优化配时方案,在不同交通状态st下,该路网需切换至的交通相位由以下状态-动作对所决定:
pnext=argmax(q(snow,anow,θ))
其中pnext表示路网需切换至的相位,snow为当前路网交通状态,anow为当前路网可执行的相位,θ表示神经网络的参数,q(snow,anow,θ)表示由当前路网状态,当前路网可执行相位,神经网络参数决定的q值函数,argmax(q(snow,anow,θ))表示使得q(snow,anow,θ)最大的受控参数anow。
进一步,所述步骤3)的过程如下:
3.1)首先,定义训练超参数,折扣因子γ=0.9,actor网络学习率a_lr=0.0001,critic网络学习率c_lr=0.0002,batch=256,ac网络的更新步长step=10,裁剪因子ε=0.2,当前时刻ppo方法的奖励定义如下:
3.2)根据排队长度-相位编号数据集st,缓冲区buffer中存储的小批量训练数据以及critic网络的返回值adv更新actor神经网络q(st,at,θt),其中θt为策略参数,更新当前时刻选取各个动作的概率,并按照预设的step将更新参数传入old_policy网络,ppo中policy的更新公式如下所示:
lclip(θ)=et[min(rt(θ)at,clip(rt(θ),1-ε,1+ε)at)];
其中,rt(θ)是t时刻newpolicy和oldpolicy的比例,以此限制newpolicy的更新幅度;
3.3)根据排队长度-相位编号数据集st和平均奖励的偏导数drt更新critic神经网络权重w,输出评价θt好坏的指标adv:
adv=drt-v(st)
3.4)重复更新ppo网络参数直到达到最大迭代次数i=200000或者损失函数达到收敛精度的要求。
本发明的技术构思为:首先实时获取路网内的车辆信息和信号灯相位信息,然后预处理,得到排队长度-相位编号数据集,再基于该数据集和近端策略优化训练策略参数和神经网络。达到最大迭代次数后,可以得到基于近端策略优化和当前路网车辆排队长度的最优信号灯相位切换方案,该发明最终得到的交通信号控制方案可以有效处理小区域路网的交通拥堵问题。
本发明的有益效果为:通过对实时交通数据的获取和处理,挖掘交通数据中隐藏的重要信息,通过训练ppo神经网络,最后将训练结果用于小型路网的交通信号控制,从而可以缓解区域交通的拥堵问题。
附图说明
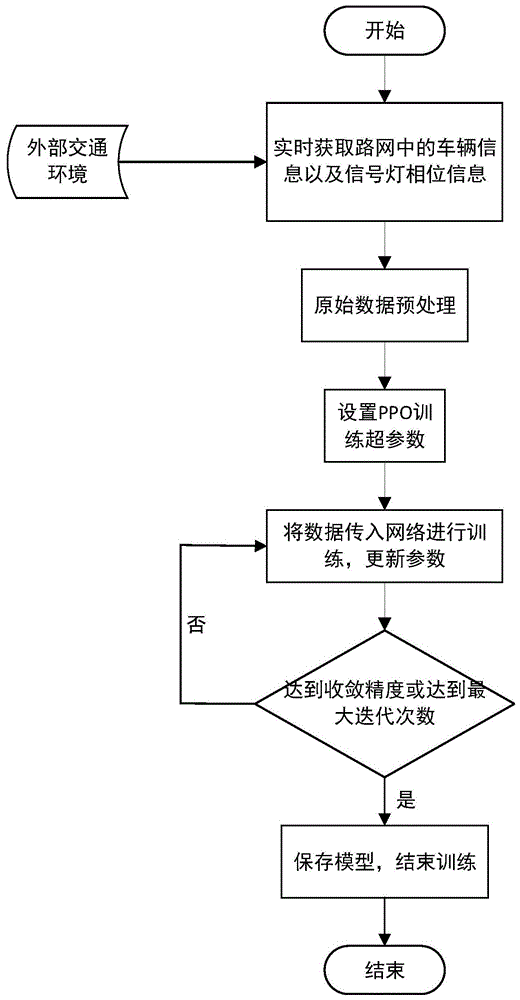
图1显示了基于近端策略优化的小型路网交通信号控制方法流程图;
图2显示了基于sumo仿真软件搭建的小型路网示意图,用于下文的实例分析;
图3显示了路网内交叉口的相位示意图,每个交叉口处的相位具有一致性。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种基于近端策略优化的小型路网交通信号控制方法,包括以下步骤:
1)参照图2,图3的路网信息,利用路网交叉口处的交通数据信号传感器,实时获取小型路网中(井字型四交叉口)的交通数据,主要为车辆的相对坐标信息和信号灯在对应时刻所处的相位信息,确定处于排队状态的车辆,保存在原始数据集中;
2)原始数据预处理,删去离谱的数据并用前一时刻的数据填补缺失的数据,获取具体交叉口处的排队长度-相位编号集合{qi,j,pi},其中,qi,j表示当前时刻第i交叉口第j车道处的车辆排队长度,pi代表当前时刻第i交叉口处的信号灯灯态,在该发明中,i=1,2,3,4,j=1,2,...,7,8;按照路网中交叉口的排列顺序,将集合{qi,j,pi}整合得到整个路网在当前时刻的排队长度-相位编号数据集st,t为当前的时刻;
3)根据图1,利用路网的排队长度-相位编号集st,初始化神经网络权重,利用近端策略优化方法(ppo)更新网络参数,寻找当前交通环境下的最优信号灯配时方案,过程如下:
3.1)首先,定义训练超参数,折扣因子γ=0.9,actor网络学习率a_lr=0.0001,critic网络学习率c_lr=0.0002,batch=256,ac网络的更新步长step=10,裁剪因子ε=0.2,当前时刻ppo方法的奖励定义如下:
3.2)根据排队长度-相位编号数据集st,缓冲区buffer中存储的小批量训练数据以及critic网络的返回值adv更新actor神经网络q(st,at,θt),其中θt为策略参数,更新当前时刻选取各个动作的概率,并按照预设的step将更新参数传入old_policy网络,ppo中policy的更新公式如下所示:
lclip(θ)=et[min(rt(θ)at,clip(rt(θ),1-ε,1+ε)at)];
其中,rt(θ)是t时刻newpolicy和oldpolicy的比例,以此限制newpolicy的更新幅度;
3.3)根据排队长度-相位编号数据集st和平均奖励的偏导数drt更新critic神经网络权重w,输出评价θt好坏的指标adv:
adv=drt-v(st)
3.4)重复更新ppo网络参数直到达到最大迭代次数i=200000或者损失函数达到收敛精度的要求;
4)保存最终收敛的神经网络训练参数,得到该路网下基于近端策略优化的交通信号优化配时方案。在不同交通状态st下,该路网需切换至的交通相位由以下状态-动作对所决定:
pnext=argmax(q(snow,anow,θ))
其中pnext表示路网需切换至的相位,snow为当前路网交通状态,anow为当前路网可执行的相位,θ表示神经网络的参数,q(snow,anow,θ)表示由当前路网状态,当前路网可执行相位,神经网络参数决定的q值函数,argmax(q(snow,anow,θ))表示使得q(snow,anow,θ)最大的受控参数anow。
本实施例以使用微观交通仿真软件sumo搭建的四交叉口井字型路网的实时交通数据为实施例,一种基于近端策略优化的小型路网交通信号控制方法,包括以下步骤:
1)通过sumo构建仿真路网,并利用python与sumo的接口,实时获取小型路网中(井字型四交叉口)的交通数据,主要为车辆的相对坐标信息和信号灯在对应时刻所处的相位信息,确定处于排队状态的车辆,保存在原始数据集中;
2)原始数据预处理,删去离谱的数据并用前一时刻的数据填补缺失的数据,获取具体交叉口处的排队长度-相位编号集合{qi,j,pi},其中,qi,j表示当前时刻第i交叉口第j车道处的车辆排队长度,pi代表当前时刻第i交叉口处的信号灯灯态,在该发明中,i=1,2,3,4,j=1,2,...,7,8;按照路网中交叉口的排列顺序,将集合{qi,j,pi}整合得到整个路网在当前时刻的排队长度-相位编号数据集st,t为当前的时刻;
3)利用路网的排队长度-相位编号集st,初始化神经网络权重,利用近端策略优化方法(ppo)更新网络参数,寻找当前交通环境下的最优信号灯配时方案,过程如下:
3.1)首先,定义训练超参数,折扣因子γ=0.9,actor网络学习率a_lr=0.0001,critic网络学习率c_lr=0.0002,batch=256,ac网络的更新步长step=10,裁剪因子ε=0.2,当前时刻ppo方法的奖励定义如下:
3.2)根据排队长度-相位编号数据集st,缓冲区buffer中存储的小批量训练数据以及critic网络的返回值adv更新actor神经网络q(st,at,θt),其中θt为策略参数,更新当前时刻选取各个动作的概率,并按照预设的step将更新参数传入old_policy网络,ppo中policy的更新公式如下所示:
lclip(θ)=et[min(rt(θ)at,clip(rt(θ),1-ε,1+ε)at)];
其中,rt(θ)是t时刻newpolicy和oldpolicy的比例,以此限制newpolicy的更新幅度;
3.3)根据排队长度-相位编号数据集st和平均奖励的偏导数drt更新critic神经网络权重w,输出评价θt好坏的指标adv:
adv=drt-v(st)
3.4)重复更新ppo网络参数直到达到最大迭代次数i=200000或者损失函数达到收敛精度的要求。
4)保存最终收敛的神经网络训练参数,得到该路网下基于近端策略优化的交通信号优化配时方案。在不同交通状态st下,该路网需切换至的交通相位由以下状态-动作对所决定:
pnext=argmax(q(snow,anow,θ))。
以微观交通仿真软件sumo搭建的井字型四交叉口路网为实施例,运用以上方法得到基于近端策略优化的小型路网交通信号优化配时方案,结果显示,相比定时控制方式,该方法的车辆平均旅行时间减少了22.8%。
以上阐述的是本发明给出的一个实施例表现出来的优良效果,显然本发明不仅适合上述实施例,在不偏离本发明基本精神及不超出本发明实质内容所涉及内容的前提下可对其做种种变化加以实施。
- 还没有人留言评论。精彩留言会获得点赞!