基于Flink架构的多数据源实时交通事件处理方法与流程
基于flink架构的多数据源实时交通事件处理方法
技术领域
[0001]
本发明涉及一种基于flink架构的多数据源实时交通事件处理方法。
背景技术:
[0002]
近年来,随着车辆的大幅增加,城市道路上发生的事件也越来越多,交通事故,车辆故障,拥堵,大雾,交通管制等等,情况也越来越多。交通出行所需要考虑的也越来越多,但目前的交通事件信息广播依然有较大延迟。随着自动驾驶技术的发展,周围区域的实时交通路况信息,就显得极为重要。
技术实现要素:
[0003]
本发明旨在克服现有技术的缺陷,提供一种基于flink架构的多数据源实时交通事件处理方法,flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件,本方法将不同kafka队列中的数据源(拥堵数据,交通意外,恶劣天气等)的数据统一到flink平台,kafka是一个分布式的流处理平台,进行数据预处理,过滤已过时的数据,将不用的数据源的数据转换成统一的格式,然后根据事件发生所在的位置区域,进行分组,然后进行统一处理,包括但不限于去重,融合,处理过期数据等,将数据发送到kafka消息队列以供下游消费。下游可以通过消费kafka的消息,反馈给车载系统,车载系统根据车机自身的所在的区域,取出相邻区域的所有交通事件,报告给车机的自动驾驶系统,以供决策道路的复杂度是否能开启自动驾驶;同时将数据进行存储,以便读取历史数据以及可视化某个区域中正发生的所有事件。
[0004]
为了解决上述技术问题,本发明是这样实现的:
[0005]
一种基于flink架构的多数据源实时交通事件处理方法,包括如下步骤:
[0006]
步骤一、消费消息队列kafka中的数据源,将不同的数据源的交通事件数据使用不同的转换器统一格式:包含事件id,事件状态(new(新事件)、changed(更新事件)、expired(过期事件)),事件类型(天气,意外事件,拥堵,施工等等),创建时间,有效期,道路(linkid(道路id),可多条),道路区间(事件的起点和终点在对应所在道路上的的偏移量),区域(长度为7的geohash(一种地址编码,它能把二维的经纬度编码成一维的字符串)值,可多个区域),使用flink平台的“union”算子将多个数据流合并到一个流中;
[0007]
步骤二、将统一的数据进行预处理:
[0008]
步骤2.1使用flink平台的“filter”算子过滤掉非指定区域的事件,比如去掉非上海区域内的事件;
[0009]
步骤2.2、根据事件所在的道路等级,使用flink平台的“filter”算子,过滤掉道路等级低于某个阈值的事件,比如去掉非高速路的事件;
[0010]
步骤2.3、使用flink平台的“keyby”算子,将这些事件id进行分区,将事件分发到事件所在每一个区域;
[0011]
步骤2.4、使用flink平台的“process”算子,对不同分区的数据进行分发;
[0012]
步骤三、使用flink平台的“keyby”算子,将事件按照geohash(一种地址编码,它能把二维的经纬度编码成一维的字符串)进行分区,使用flink平台的”map”算子,将新事件和区域内已经存在的事件进行聚合处理,包括新增事件,更新事件(同一个事件的更新,比如拥堵变长),过滤过期事件等操作;
[0013]
步骤四、使用flink平台的“addsink”算子,将数据下发到下游消息队列kafka以供消费。
[0014]
其中步骤一中,昨晚一种具备消费消息功能的组件kafka,它有三种消费模式,其中最多一次(at most once)消费消息可能会消失也可能会被处理但是最多只处理一次,至少一次(at least once)消费消息不会丢失但是可能会重复被处理多次,这当然不是我们期望的,精确消费(exactly once)消息被处理一次不丢失不重复就一次,因此采用精确消费。
[0015]
目前处理实时流数据基于flink框架去实现。flink作为下一代数据引擎,其核心是一个流式数据执行引擎,其典型的分布式框架,最大的特征是流处理、可靠性、可扩展、高吞吐、低延迟、支持水平扩展能力,提供了很多高级抽象的应用程序接口,方便用户根据实际场景编写分布式任务。
[0016]
本发明的有益效果是:1)数据实时性处理很强,不会产生数据的延迟,保证数据的一致性;
[0017]
2)数据的吞吐量很强,即数据可以频繁的写入到flink当中且不会丢失。
附图说明
[0018]
下面结合附图和实施方式对本发明作进一步的详细说明:
[0019]
图1为道路和区域的关系图。
[0020]
图2为本发明的实时处理引擎flink的架构示意图。
[0021]
图3为本发明用于消费上游数据源和生产到下游的消息队列kafka的架构示意图。
[0022]
图4为本发明的工作流程架构示意图。
具体实施方式
[0023]
如图4所示,本发明基于flink架构的多数据源实时交通事件处理方式包括如下步骤:
[0024]
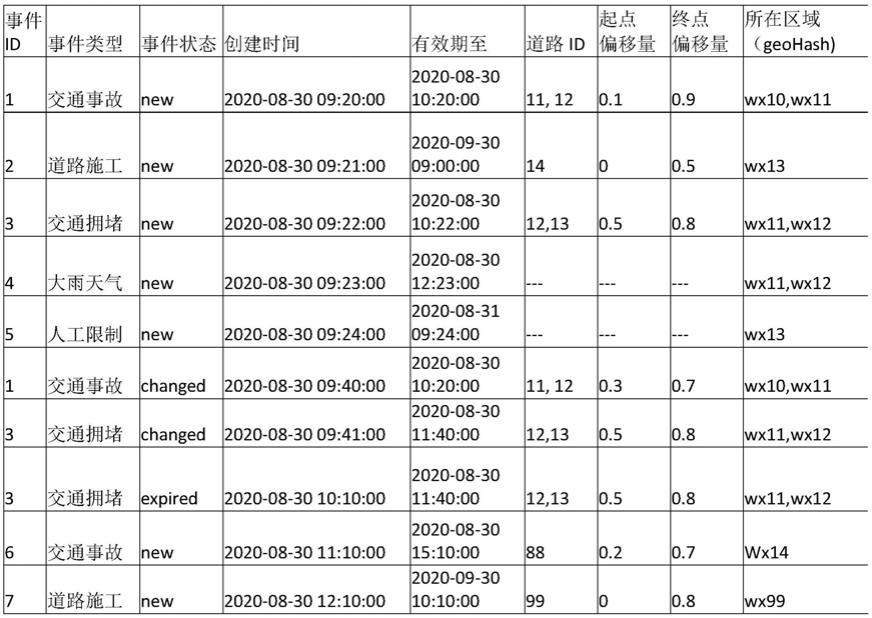
步骤一、读取消息队列kafka中的数据源,将不同的数据源的交通事件数据使用不同的转换器统一格式:表一为数据源的原始数据,图1为道路(id:11,12,13,14,88,99)和区域(geohash:wx10,wx11,wx12,wx13,wx88,wx99)的关系。其中天气事件和人工事件可以覆盖一个或多个区域。将原始数据转换为统一格式的动态数据,将对于区域里的所有道路取出,并设置为全路段覆盖,偏移量设置为对应的偏移量,如表二。
[0025]
步骤二、将统一的数据进行预处理:
[0026]
步骤2.1使用flink平台的“filter”算子过滤掉非指定区域的事件,过滤掉事件7的事件;
[0027]
步骤2.2、根据事件所在的道路等级,使用flink平台的“filter”算子,过滤掉道路等级低于某个阈值的事件,本例中去掉发生在道路id为10的事件,即事件6;
[0028]
步骤2.3、使用flink平台的“keyby”算子,将这些事件id进行分区,对每一个事件进行单独处理;
[0029]
步骤2.4、使用flink平台的“process”算子,确定每一个事件所在的区域(可能为多个区域),将跨区域的道路进行切分,然后对不同区域的数据进行分发,如表3所示;
[0030]
步骤三、使用flink平台的“keyby”算子,将事件按照geohash进行分区,使用flink平台的“map”算子,将新事件和区域内已经存在的事件进行聚合处理,包括新增事件,更新事件(同一个事件的更新,比如拥堵道路变长,拥堵时间延长等),过滤过期事件等操作;
[0031]
步骤四、使用flink平台的“addsink”算子,将输出结果如表4所示发送到kafka消息队列以供下游使用。
[0032]
表1
[0033][0034]
表2
[0035][0036]
表3
[0037][0038]
表4
[0039]
[0040][0041]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1