一种基于层次聚类法的高速公路拥堵判断方法及装置
1.本发明涉及到交通数据分析及处理领域,具体涉及一种基于层次聚类法的高速公路拥堵判断方法及装置,可适用于高速公路的拥堵判断,并能判别常发性拥堵与偶发性拥堵。
背景技术:
2.近年来,人均拥有车辆数爆发增长,车辆增长的速率远超与高速公路路网的延伸建设速度,路面超饱和度的现象持续增大,也大大增长了高速公路出现异常事件的几率。
3.高速公路的拥堵检测是交通控制与诱导的重要基础。高速公路发生拥堵的情况一般分为两种,分别分为常发性拥堵与偶发性拥堵,常发性拥堵表现为该路段在某时段车流量急剧上升致使超过道路运行负荷所引起的拥堵,如早高峰、晚高峰情形。偶发性拥堵是异常事件的发生所导致的,异常事件发生时将会产生一个道路瓶颈,若此时该路段车流量较大时,会对事件发生的路段的车辆行驶状况产生较大的影响,而我们可以根据这些影响并结合该路段的检测设备对异常事件进行检测。
4.现阶段事件检测算法最常用的便是加州算法及其改进变形的算法,如加州7#算法和及加州8#算法,为双截面异常事件检测算法,根据路段中发生交通事件会造上游检测断面占有率增高,下游检测断面占有率下降这一事实,通过三个门限值来进行判别交通是否拥堵。mcmaster算法根据突变理论,建立流量
‑
占有率图,通过门限曲线的划分来判断交通状态,其不仅可以判别出拥堵和非拥堵,而且还可判断偶发性拥堵和常发性拥堵。
5.上述研究主要依据经典的交通流理论,并结合模式识别和数据统计技术进行研究,其思想主要为对数据中的异常数据进行识别从而实现对交通事件的检测,其共性的缺点算法参数标定困难,且各路段适用性不强。
6.近年来,随着人工智能技术的发展与进步,随着数据的数量变多、质量变好,部分交通学者们开始引入人工智能技术解决交通问题,一部分学者认为仅是单纯的使用交通三参数,即流量、速度、密度无法有效的区分出常发性拥堵与偶发性拥堵,所以需要设计新的特征参数来对拥堵性质进行判别。2010年清华大学蒲世林等人,通过设计新的特征来对数据集进行分类,可直接区分出正常、常发性拥堵、偶发性拥堵。2014年秦韬根据提取出的特征参数结合bp神经网络算法对城市局部偶发性拥堵和常发性拥堵进行了判别,效果较好。
7.人工智能算法由于对数据充分的挖掘利用,能够达到模式识别、历史对比法等无法达到的效果,但也有缺陷:一是算法特征选取也尤为关键,否则将会对拥堵性质判别造成较大的影响;二是为了更好的区分常发性拥堵与偶发性拥堵,通常会选取多个特征,但是特征数量的增加会导致“维数灾难”,使运算量骤增。
技术实现要素:
8.有鉴于此,本发明提出一种基于层次聚类法的高速公路拥堵判断方法及装置,用于解决现有技术中的至少一个缺陷。
9.本发明的目的是通过以下技术方案来实现的:一种基于层次聚类法的高速公路拥堵判断方法,该方法包括:
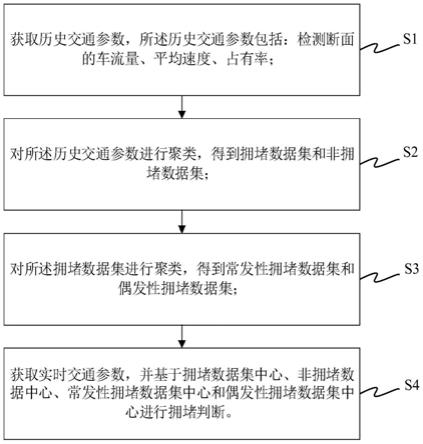
10.获取历史交通参数,所述历史交通参数包括:检测断面的车流量、平均速度、占有率;
11.对所述历史交通参数进行聚类,得到拥堵数据集和非拥堵数据集;
12.对所述拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集;
13.获取实时交通参数,并基于拥堵数据集中心、非拥堵数据中心、常发性拥堵数据集中心和偶发性拥堵数据集中心进行拥堵判断。
14.可选地,通过模糊均值聚类算法对所述历史交通参数进行聚类,得到拥堵数据集和非拥堵数据集。
15.可选地,通过模糊均值聚类算法对所拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集。
16.可选地,所述通过模糊均值聚类算法对所述历史交通参数进行聚类,包括:
17.基于所述平均速度和所述占有率,使用模糊均值聚类算法对所述历史交通参数进行聚类,确定fcm的目标函数:
[0018][0019]
d
ij
=||c
i
‑
x
i
||
[0020][0021]
其中:c
i
代表模糊类第i类的中心;c代表共有c类;n代表共有n个数据对象;m为加权指数,满足m∈[1,∞);d
ij
为第j个数据对象到第i个聚类中心的欧几里德距离;u
ij
代表第j个数据对象属于i类的隶属度大小;
[0022]
计算更新聚类中心,通过两个聚类中心分别代表拥堵发生和拥堵未发生,判断是否满足迭代终止条件,直到满足迭代终止条件,即可确定拥堵发生和拥堵未发生对应的两个聚类中心;
[0023]
迭代终止条件为:||j
(t+1)
‑
j
(t)
||≤ε或t=t
max
[0024]
其中:j
(t+1)
为第t+1次目标函数值;j
(t)
为第t次目标函数值;ε为迭代终止条件阈值;t
max
为迭代最大次数;
[0025]
根据模糊聚类所得到的聚类中心,采用欧几里德距离判断数据集d中数据的类别,拥堵或非拥堵,若输入的数据序列到拥堵聚类中心欧几里德距离小于到非拥堵聚类中心的距离,则判断为拥堵,否则,判断为非拥堵;欧几里德距离d(x,y)判断公式为:
[0026][0027]
其中:x和y分别代表两个数据对象;x
k
和y
k
为两个数据对象的第k个特征向量;p为数据对象的特征向量总和。
[0028]
可选地,获取常发性拥堵与偶发性拥堵判别特征参数,包括:t时刻上下游占有率差δo(t,i,i
‑
1)、i检测点t时刻与t
‑
1时刻占有率差δo(i,t,t
‑
1)、表示i检测点t时刻与t
‑
1时刻速度差δv(i,t,t
‑
1);
[0029]
通过模糊均值聚类算法基于所述常发性拥堵与偶发性拥堵判别特征参数对所拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集。
[0030]
可选地,所述通过模糊均值聚类算法对所拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集,包括:
[0031]
基于拥堵数据集中心、非拥堵数据中心、常发性拥堵数据集中心和偶发性拥堵数据集中心,使用欧几里德距离公式确定实时交通参数所属的拥堵类别;若输入的数据序列到拥堵聚类中心欧几里德距离小于到非拥堵聚类中心的距离,则判断为拥堵,否则,判断为非拥堵;若输入的数据序列到偶发性拥堵聚类中心欧几里德距离小于到常发性拥堵聚类中心的距离,则判断为偶发性拥堵,否则,判断为常发性拥堵。
[0032]
可选地,还包括:对所述历史交通参数进行归一化。
[0033]
本发明的目的是通过以下技术方案来实现的:一种基于层次聚类法的高速公路拥堵判断装置,该装置包括:
[0034]
数据获取模块,用于获取历史交通参数,所述历史交通参数包括:检测断面的车流量、平均速度、占有率;
[0035]
第一聚类模块,用于对所述历史交通参数进行聚类,得到拥堵数据集和非拥堵数据集;
[0036]
第二聚类模块,用于对所述拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集;
[0037]
拥堵判断模块,用于获取实时交通参数,并基于拥堵数据集中心、非拥堵数据中心、常发性拥堵数据集中心和偶发性拥堵数据集中心进行拥堵判断。
[0038]
由于采用了上述技术方案,本发明具有如下的优点:
[0039]
本发明充分考虑上下游检测断面交通参数相似性、差异性、突变性的高速公路拥堵判别技术,不仅能够较好的判别拥堵发生,并能进一步判别拥堵为常发性或偶发性,可适用于对高速路上的拥堵的判别。
[0040]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0041]
本发明的附图说明如下。
[0042]
图1为本发明一实施例一种基于层次聚类法的高速公路拥堵判断方法的流程图;
[0043]
图2为本发明一实施例一种基于层次聚类法的高速公路拥堵判断装置的示意图。
具体实施方式
[0044]
下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本技术,而不能理解为对本技术的限制。相反,本
申请的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。
[0045]
如图1所示,本技术实施例提供一种基于层次聚类法的高速公路拥堵判断方法,包括以下步骤:
[0046]
s1获取历史交通参数,所述历史交通参数包括:检测断面的车流量、平均速度、占有率;
[0047]
s2对所述历史交通参数进行聚类,得到拥堵数据集和非拥堵数据集;
[0048]
s3对所述拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集;
[0049]
s4获取实时交通参数,并基于拥堵数据集中心、非拥堵数据中心、常发性拥堵数据集中心和偶发性拥堵数据集中心进行拥堵判断。
[0050]
在步骤s1中,通过对原始数据进行筛选可以得到历史交通参数,包括:检测断面的车流量、平均速度、占有率;
[0051]
其中,原始数据可以通过车检器得到,车检器数据是以5min为检测周期的单车道数据统计量。
[0052]
以单向两车道为例。
[0053]
将单车道的数据,合并为整个断面的数据。以单向两车道为例。
[0054]
q=q1+q2[0055]
其中,q为检测断面总流量,q1为车道1统计流量,q2为车道2统计流量。
[0056][0057]
其中,v为检测断面平均车速,v1为车道1统计平均车速,v2为车道2统计平均车速。
[0058][0059]
其中,o为检测断面占有率,o1为车道1统计占有率,o2为车道2统计占有率。
[0060]
通过对历史交通参数的筛选形成包含偶发性拥堵样本、常发性拥堵样本、非拥堵样本数据的样本数据集d。
[0061]
在一实施例中,通过模糊均值聚类算法对所述历史交通参数进行聚类,得到拥堵数据集和非拥堵数据集。
[0062]
当某路段发生拥堵时,将会导致检测断面交通参数受到影响,使用平均车速v、占有率o两个特征,对步骤s1建立的数据集进行聚类分析,得到拥堵与非拥堵两类数据集,分别代表拥堵下的数据集d1、非拥堵下的数据集d2。
[0063]
聚类的方法包括:
[0064]
步骤s11:为保证各个特征间数值间距差距大,个别特征对聚类影响大,将步骤1中数据集d中v、o特征进行min
‑
max标准化处理。
[0065][0066]
步骤s12:基于平均车速v、占有率o特征,使用模糊均值聚类算法对这历史交通参数进行聚类,确定fcm的目标函数:
[0067][0068]
d
ij
=||c
i
‑
x
i
||
[0069][0070]
其中:
[0071]
c
i
代表模糊类第i类的中心;
[0072]
c代表共有c类;
[0073]
n代表共有n个数据对象;
[0074]
m是一个加权指数,满足m∈[1,∞);
[0075]
d
ij
为第j个数据对象到第i个聚类中心的欧几里德距离;
[0076]
u
ij
代表第j个数据对象属于i类的隶属度大小;
[0077]
步骤s13:计算更新聚类中心,通过两个聚类中心分别代表拥堵发生和拥堵未发生,判断是否满足迭代终止条件,直到满足迭代终止条件,即可确定拥堵发生和拥堵未发生对应的两个聚类中心;
[0078]
其中,迭代终止条件为:||j
(t+1)
‑
j
(t)
||≤ε或t=t
max
[0079]
其中:
[0080]
j
(t+1)
为第t+1次目标函数值;
[0081]
j
(t)
为第t次目标函数值;
[0082]
ε为迭代终止条件阈值;
[0083]
t
max
为迭代最大次数;
[0084]
步骤s14:根据模糊聚类所得到的聚类中心,采用欧几里德距离判断数据集d中数据的类别,拥堵或非拥堵,若输入的数据序列到拥堵聚类中心欧几里德距离小于到非拥堵聚类中心的距离,则判断为拥堵,否则,判断为非拥堵;欧几里德距离d(x,y)判断公式为:
[0085][0086]
其中:
[0087]
x和y分别代表两个数据对象;
[0088]
x
k
和y
k
为两个数据对象的第k个特征向量;
[0089]
p为数据对象的特征向量总和。
[0090]
步骤s15:将属于拥堵的样本数据提取,生成一个新的数据集,记作d1。
[0091]
基于空间关联关系与突变理论,分析常发性拥堵与偶发性拥堵发生的相似性与差异性,设计并选择上下游占有率差、与前时刻占有率差、与前时刻速度差三个特征参数作为聚类特征,使用上述三特征参数进行聚类分析,得到常发性拥堵与偶发性拥堵的聚类中心,完成对常发性拥堵与偶发性拥堵的判别。具体地,通过模糊均值聚类算法对所拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集,包括以下步骤:
[0092]
s21根据空间关联的先验知识及突变理论,分析常发性拥堵与偶发性拥堵的差异性,获取取常发性拥堵与偶发性拥堵判别特征参数,如下表所示。
[0093][0094]
其中δo(t,i,i
‑
1)表示t时刻上下游占有率差,o(i,t)
‑
o(i
‑
1,t)表示t时刻拥堵上游检测器处占有率减去拥堵下游检测器处占有率;δo(t,i,i
‑
1)表示i检测点,t时刻与t
‑
1时刻占有率差,o(i,t)
‑
o(i
‑
1,t)表示i检测器处t时刻流量减去t
‑
1时刻占有率;δv(i,t,t
‑
1)表示i检测点,t时刻与t
‑
1时刻速度差,v(i,t)
‑
v(i,t
‑
1)表示i检测器处t时刻流量减去t
‑
1时刻速度。
[0095]
步骤s22:使用步骤s21中的特征参数,结合模糊均值聚类算法,再次进行聚类分析,得到常发性拥堵与偶发性拥堵的聚类中心。
[0096]
在对根据实时输入的检测器数据序列,得到平均速度v、占有率o两个拥堵判断参数,并计算出δo(t,i,i
‑
1)、δo(t,i,i
‑
1)、δv(i,t,t
‑
1)三个常发性拥堵与偶发性拥堵判别特征参数。结合步骤s2中拥堵与非拥堵判断聚类中心、步骤s3中常发性拥堵与偶发性拥堵判别聚类中心,使用欧几里德距离公式判断出输入数据序列所属类别,最终完成拥堵判断及常发性拥堵与偶发性拥堵的判别。若输入的数据序列到拥堵聚类中心欧几里德距离小于到非拥堵聚类中心的距离,则判断为拥堵,否则,判断为非拥堵;若输入的数据序列到偶发性拥堵聚类中心欧几里德距离小于到常发性拥堵聚类中心的距离,则判断为偶发性拥堵,否则,判断为常发性拥堵。
[0097]
如图2所示,本技术实施例提供一种基于层次聚类法的高速公路拥堵判断装置,该装置包括:
[0098]
数据获取模块,用于获取历史交通参数,所述历史交通参数包括:检测断面的车流量、平均速度、占有率;
[0099]
第一聚类模块,用于对所述历史交通参数进行聚类,得到拥堵数据集和非拥堵数据集;
[0100]
第二聚类模块,用于对所述拥堵数据集进行聚类,得到常发性拥堵数据集和偶发性拥堵数据集;
[0101]
拥堵判断模块,用于获取实时交通参数,并基于拥堵数据集中心、非拥堵数据中心、常发性拥堵数据集中心和偶发性拥堵数据集中心进行拥堵判断。
[0102]
需要说明的是,前述图1实施例中方法的实施例的解释说明也适用于该实施例提出的装置,其实现原理类似,此处不再赘述。
[0103]
需要说明的是,在本技术的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本技术的描述中,除非另有说明,“多个”的含义是两个或两个以上。
[0104]
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本技术的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本技术
的实施例所属技术领域的技术人员所理解。
[0105]
应当理解,本技术的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
[0106]
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
[0107]
此外,在本技术各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
[0108]
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0109]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本技术的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0110]
尽管上面已经示出和描述了本技术的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本技术的限制,本领域的普通技术人员在本技术的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1