基于深度强化学习与扩展卡尔曼滤波相结合的交通信号灯配时方法
1.本发明涉及一种交通信号灯配时方法,尤其是一种基于深度强化学习与扩展卡尔曼滤波相结合的交通信号灯配时方法。
背景技术:
2.随着社会的快速发展和人们物质生活水平的提高,日益增长的汽车数量会造成交通拥堵问题。交通拥堵会带来很多不必要的资源损失和环境污染,并且会增加交通事故发生的概率。现有的交通信号灯配时方法有两种,即定时算法和最长队列优先配时算法。定时算法在高度动态的交通环境下,对于缓解交通拥堵的效率低下;最长队列优先配时算法根据车辆队列长度调整交通信号灯的配时方案,仍然不能解决交叉口的拥堵问题。人工指挥交通有时是有效的,但它浪费人力和时间。因此,发明人需要交通信号灯能够学会与环境互动得到合理的配时方案。
技术实现要素:
3.本发明的一个目的是通过提出一种基于深度强化学习与扩展卡尔曼滤波相结合的交通信号灯配时方法,以解决上述背景技术中提出的缺陷。
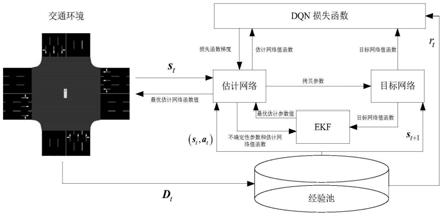
4.本发明采用的技术方案如下:包括将交通信号灯配时系统抽象为智能体,十字路口的交通环境抽象为被控对象,交通信号灯的配时方案抽象为动作,车辆的累计等待时间的变化抽象为奖励,智能体根据被控对象提供的状态信息选择动作;执行动作后,被控对象将当前状态和奖励反馈给智能体,并且不断重复此过程,智能体以获取最大奖励值为目标不断更新参数直至得到最优动作;经验池用来存储训练样本,并用于dqn网络训练。
5.作为本发明的一种优选技术方案:所述dqn网络训练与ekf不断交互。
6.作为本发明的一种优选技术方案:所述十字路口的交通环境采用离散交通状态编码将整个十字路口网格化,并构建交通状态信息矩阵。
7.作为本发明的一种优选技术方案:所述智能体通过奖励函数进行优化用于提高十字路口的车辆通行效率,所述奖励函数将奖励定义为相邻两个周期之间累计等待时间之差,具体公式如下:
8.r
t
=w
t-w
t+1
9.其中,r
t
表示当前状态下的奖励值,w
t
表示十字路口所有车辆在当前状态下等待时间的累计值;w
t+1
表示执行动作后十字路口所有车辆等待时间的累计值。
10.作为本发明的一种优选技术方案:所述dqn网络训练的损失函数如下所示:
[0011][0012]
其中,为目标网络函数值,为目标网络的固定权重,q
(s
t
,a
t
|θ
t
)为t时刻估计网络包含不确定性参数的值函数,θ
t
为t时刻估计网络不确定性参数。
[0013]
作为本发明的一种优选技术方案:所述dqn网络训练中采用q-learning算法进行强化,具体公式为:
[0014][0015]
其中,α∈(0,1)为系统的学习率;γ∈(0,1)为衰减因子,用于计算状态s
t+1
到最后的累计奖励。
[0016]
作为本发明的一种优选技术方案:所述dqn网络训练与ekf不断交互具体为:
[0017]
明确ekf的状态方程和观测方程,具体公式如下:
[0018]
xi=f(x
i-1
)+w
i-1
[0019]
zi=h(xi)+vi[0020]
其中,xi为状态变量,zi为观测变量;f(
·
)和h(
·
)分别为非线性系统的状态函数和观测函数;wi是过程噪声,vi是观测噪声,它们的协方差分别为qi和ri;
[0021]
令e[wi]=0、e[vi]=0、以及将t时刻的不确定性参数θ
t
代入ekf状态方程,z
t
与q(s
t
,a
t
|θ
t
)带入ekf观测方程。具体公式如下:
[0022]
θi=θ
i-1
+w
i-1
[0023]
zi=q(s
t
,a
t
|θi)+vi[0024]
其中,状态变量θi表示迭代i次时的不确定性参数,观测变量zi表示迭代i次时的目标网络值函数;非线性状态函数f(θi)=θi,非线性观测函数h(θi)=q(st,a
t
|θi);
[0025]
分别将f(θi)在处泰勒一阶展开,h(θi)在处泰勒一阶展开,具体公式如下:
[0026][0027][0028]
其中,为迭代i次时的真实参数估计值,为迭代i次时的真实参数预测值;状态转移矩阵观测转移矩阵观测转移矩阵和为高阶项并可忽略;则状态方程和观测方程为:
[0029][0030][0031]
迭代i次时真实参数预测值由迭代i-1次时真实参数估计值代替;具体推
导公式如下:
[0032][0033]
由状态变量θi与真实参数预测值的差计算得到状态预测误差协方差
[0034]
本发明的有益效果是:
[0035]
针对dqn中存在的参数不确定性问题,提出利用不确定性参数值作为ekf模型的输入,通过ekf模型的不断迭代更新得到真实参数的最优估计值,然后利用真实参数的最优估计值替代不确定性参数值得到准确的值函数并选择最优的配时方案,设置了三种不同交通仿真环境,并分别在正常交通流和高峰交通流的情况下进行了对比试验,充分证明dqn-ekf能够有效的提高交通路口的通行效率,并适用于不同交通环境。
附图说明
[0036]
图1为本发明优选实施例的模型总体框架图;
[0037]
图2为本发明优选实施例中交通状态信息表示图;
[0038]
图3为本发明优选实施例中十字路口相位变化图;
[0039]
图4为本发明优选实施例中丁字路口相位变化图;
[0040]
图5为本发明优选实施例中dqn与ekf相结合的结构图;
[0041]
图6为本发明优选实施例中场景1中正常交通流下的平均等待时间变化图;
[0042]
图7为本发明优选实施例中场景1中正常交通流下的平均队列长度条形图;
[0043]
图8为本发明优选实施例中场景1中高峰交通流下的平均等待时间变化图;
[0044]
图9为本发明优选实施例中场景1中高峰交通流下的平均队列长度条形图;
[0045]
图10为本发明优选实施例中场景2中正常交通流下的平均等待时间变化图;
[0046]
图11为本发明优选实施例中场景2中正常交通流下的平均队列长度条形图;
[0047]
图12为本发明优选实施例中场景2中高峰交通流下的平均等待时间变化图;
[0048]
图13为本发明优选实施例中场景2中场景2中高峰交通流下的平均队列长度条形图;
[0049]
图14为本发明优选实施例中场景3中正常交通流下的平均等待时间变化图;
[0050]
图15为本发明优选实施例中场景3中正常交通流下的平均队列长度条形图;
[0051]
图16为本发明优选实施例中场景3中高峰交通流下的平均等待时间变化图;
[0052]
图17为本发明优选实施例中场景3中高峰交通流下的平均队列长度条形图。
具体实施方式
[0053]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0054]
参照图1-17,本发明优选实施例提供了一种基于深度强化学习与扩展卡尔曼滤波
相结合的交通信号灯配时方法,将交通信号灯配时系统抽象为智能体,十字路口的交通环境抽象为被控对象,交通信号灯的配时方案抽象为动作,车辆的累计等待时间的变化抽象为奖励。首先,智能体根据被控对象提供的状态信息选择动作;执行动作后,被控对象将当前状态和奖励反馈给智能体,并且不断重复此过程;最后,智能体以获取最大奖励值为目标不断更新参数直至得到最优动作;经验池用来存储训练样本,并用于dqn网络训练。其中,dqn网络通过与ekf的不断交互解决了参数不确定性问题。具体的模型框架如图1所示。其中,s
t
为t时刻的状态;a
t
为t时刻的动作;r
t
为t时刻的奖励;d
t
为t时刻的回放记忆单元。
[0055]
为了准确地定义十字路口的交通状态信息,本实施例采用离散交通状态编码(discrete traffic state encoding,dtse)方法将整个十字路口网格化,并构建交通状态信息矩阵。这种方法能够减少数据维度,加快训练速度并有助于智能体做出有效决策。网格的长度应保证不将两辆车放在同一个网格里,并略大于普通车辆的长度,以减少计算量,正常车辆长度为4.5米至5米之间,则设网格大小为5米。在每个网格中,状态值为两个值向量《位置,速度》。位置矩阵表示网格中是否有车辆,如果有车辆,取值为1;否则为0。速度矩阵表示车辆当前速度,单位为m/s。图2为交通状态信息的表示方法。
[0056]
交通信号灯需要根据当前的交通状态选择合适的动作来引导十字路口的车辆。本实施例中交通信号灯的相位变化如图3,4所示。十字路口中相位1表示南北方向直行(同时北向西右转,南向东右转),相位2表示南北方向左转,相位3表示东西方向直行(同时东向北右转,西向南右转),相位4表示东西方向左转;丁字路口中相位1表示东西直行同时南向东右转),相位2表示东向直行且左转(同时西向南右转,南向东右转),相位3表示东向左转(同时西向南右转,南向东右转),相位4表示南向左转(同时西向南右转,南向东右转)。为保证交通系统的稳定性,每个相位都设置了红绿灯的最大持续时间和变化范围,并且在红灯与绿灯之间设置持续时间为3秒的黄色信号灯。
[0057]
奖励函数是区分强化学习和其他学习算法的一个重要因素。奖励的作用是就先前动作的表现向强化学习模型提供反馈。因此,奖励的定义方式对指导强化学习过程非常重要,这有助于智能体采取最优的行动策略。在交通信号灯配时系统中,主要目标是提高十字路口的车辆通行效率。车辆通行效率的一个主要衡量标准是车辆的等待时间,因此将奖励定义为相邻两个周期之间累计等待时间之差,具体公式如下:
[0058]rt
=w
t-w
t+1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0059]
其中,r
t
表示当前状态下的奖励值,w
t
表示十字路口所有车辆在当前状态下等待时间的累计值。w
t+1
表示执行动作后十字路口所有车辆等待时间的累计值。
[0060]
q-learning是基于价值函数的强化学习算法,其主要思想就是用全部状态(s1,s2,
…
,s
t
,
…
)∈s与动作(a1,a2,
…
,a
t
,
…
)∈a构建一张表格来存储期望值,然后根据期望值来选择获得回报最大的动作。q(s
t
,a
t
)即为在某一时刻的状态s
t
下采取动作a
t
的估计网络值函数,环境会根据智能体执行的动作反馈相应的奖励集合(r1,r2,
…
,r
t
,
…
)∈r。q-learning的更新公式如下所示:
[0061][0062]
其中,α∈(0,1)为系统的学习率;γ∈(0,1)为衰减因子,用于计算状态s
t+1
到最后
的累计奖励。
[0063]
dqn是在q-learning的基础上增加神经网络并采用对偶网络结构。其中,一个主网络用来选择动作并更新参数;另一个目标网络只用来计算目标值,在这里目标网络的参数不会进行迭代更新,而是每隔一段时间从主网络中将参数复制过来;因此两个网络的结构相同,但是参数不同。dqn利用这种网络结构最小化损失函数并更新参数。dqn的损失函数如下所示:
[0064][0065]
其中,为目标网络函数值,为目标网络的固定权重。q(st,a
t
|θ
t
)为t时刻估计网络包含不确定性参数的值函数,θ
t
为t时刻估计网络不确定性参数。
[0066]
为了使损失函数最小化,发明人确定了损失函数相对于函数参数θ
t
的梯度:
[0067][0068]
权重更新如下:
[0069][0070]
在本实施例中,将dqn-ekf用于解决深度强化学习模型中的参数不确定性问题,结构图如图5所示。具体的结合过程如下:
[0071]
首先,明确ekf的状态方程和观测方程,具体公式如下:
[0072]
xi=f(x
i-1
)+w
i-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0073]
zi=h(xi)+viꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0074]
其中,xi为状态变量,zi为观测变量;f(
·
)和h(
·
)分别为非线性系统的状态函数和观测函数。wi是过程噪声,vi是观测噪声,它们的协方差分别为qi和ri。由于过程噪声和观测噪声满足高斯分布,所以令e[wi]=0、e[vi]=0、以及
[0075]
然后,将t时刻的不确定性参数θ
t
代入ekf状态方程,z
t
与q(s
t
,a
t
|θ
t
)带入ekf观测方程。具体公式如下:
[0076]
θi=θ
i-1
+w
i-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0077]
zi=q(st,a
t
|θi)+viꢀꢀꢀꢀꢀꢀ
(9)
[0078]
其中,状态变量θi表示迭代i次时的不确定性参数,观测变量zi表示迭代i次时的目标网络值函数。非线性状态函数f(θi)=θi,非线性观测函数h(θi)=q(s
t
,a
t
|θi)。
[0079]
分别将f(θi)在处泰勒一阶展开,h(θi)在处泰勒一阶展开,具体公式如下:
[0080][0081][0082]
其中,为迭代i次时的真实参数估计值,为迭代i次时的真实参数预测值。状态转移矩阵观测转移矩阵观测转移矩阵和为高阶项并可忽略。则状态方程和观测方程为:
[0083][0084][0085]
迭代i次时真实参数预测值由迭代i-1次时真实参数估计值代替。具体推导公式如下:
[0086][0087]
由状态变量θi与真实参数预测值的差计算得到状态预测误差协方差结果表明,迭代i次时的与迭代i-1次时的状态估计误差协方差有关,具体推导公式如下:
[0088][0089]
迭代i次时的真实观测变量预测值等于具体推导公式如下:
[0090][0091]
观测变量zi与真实观测变量预测值的误差协方差矩阵为观测预测误差协方差
具体推导公式如下:
[0092][0093]
同理可得,观测预测误差与状态预测误差之间的协方差矩阵表示为状态观测预测误差协方差具体推导公式如下:
[0094][0095]
ekf增益ki表示状态观测预测误差协方差与观测预测误差协方差的比重,具体公式如下:
[0096][0097]
迭代i次时的真实参数估计值通过不断迭代更新得到最优的真实状态值估计值并返回至估计网络中,具体迭代更新公式如下:
[0098][0099]
迭代i次时的状态变量θi与真实参数估计值的误差协方差表示为状态估计误差协方差状态估计误差协方差为计算下一次迭代时的状态预测误差协方差具体推导公式如下:
[0100][0101]
综上所述,dqn与ekf相结合的主要过程为:(1)将dqn模型t时刻的θ
t
、q(s
t
,a
t
|θ
t
)和z
t
作为输入构建ekf的状态方程和观测方程,通过计算误差协方差得到扩展卡尔曼滤波增益;(2)不断迭代更新使扩展卡尔曼增益不断减小真实状态值的估计误差,最终收敛得到最优真实状态值(3)将最优的真实状态值传输到估计网络中得到根据估计
网络值中的最大值选择得到最优的配时方案作用于交通环境,提高交通路口的通行效率。同时,得到t+1时刻的θ
t+1
、z
t+1
和q(s
t+1
,a
t+1
|θ
t+1
),重复上述过程得到t+1时刻的最优配时方案,以此类推直至全局模型收敛。
[0102]
sumo是一个微观交通模拟软件,可以准确的模拟城市交通场景,它还提供了一个可视化的图形界面,支持多种网格格式的输入和各种道路网络设计。利用sumo中提供的traci(traffic control interface)接口模块与仿真平台在线交互,使交通信号灯配时系统能够获取实时的交通状态信息并有效的管理交通路况。发明人在sumo(simulation of urban mobility)平台上模拟三种不同的交通仿真场景,并设置了正常交通流和高峰交通流。场景1为相同路段长度的十字路口,每条路段长度为300米;场景2为多种路段长度的十字路口,路段长度分别为200米、300米、400米和500米;场景3为相同路段长度的丁字路口,每条路段长度为300米。正常交通流中每条道路的车辆到达率为489veh/h,高峰交通流中每条道路的车辆达到率为727veh/h。为保证交通
[0103]
安全,车辆的最大速度为13.89m/s,最大加速度为2m/s2。仿真实验中深度强化学习网络中的超参数如表1所示。
[0104]
表1参数设置
[0105][0106]
由于初始阶段的探索机制和经验不足的问题使智能体不能学习到正确的配时方案,导致dqn、dueling dqn、double dqn和dqn-ekf算法的平均等待时间和平均队列长度较长。随着探索率的降低和经验累积,dqn、dueling dqn、double dqn和dqn-ekf算法的平均等待时间和平均队列长度开始逐渐下降至收敛。在场景1中正常交通流的情况下,由图6,7和表2可知在平均等待时间方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了11.06%、16.39%和23.41%;在平均队列长度方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了2.01%、10.02%和16.30%。
[0107]
表2场景1中正常交通流下的算法性能对比
[0108][0109]
在高峰交通流的情况下,由图8,9和表3可知在平均等待时间方面,dqn-ekf算法比
double dqn、dueling dqn和dqn算法分别降低了13.03%、18.57%和22.22%;在平均队列长度方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了10.81%、15.75%和20.23。
[0110]
表3场景1中高峰交通流下的算法性能对比
[0111][0112]
在场景2中正常交通流的情况下,由图10,11和表4可知在平均等待时间方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了13.51%、19.89%和23.78%;在平均队列长度方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了10.85%、18.45%和27.24%。
[0113]
表4场景2中正常交通流下的算法性能对比
[0114][0115]
在高峰交通流的情况下,由图12,13和表5可知在平均等待时间方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了9.85%、15.23%和20.01%;在平均队列长度方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了8.37%、13.08%和20.26%。
[0116]
表5场景2中高峰交通流下的算法性能对比
[0117][0118]
在场景3中正常交通流的情况下,由图14,15和表6可知在平均等待时间方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了11.29%、18.66%和25.19%;在平均队列长度方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了16.56%、19.93%和29.24%。
[0119]
表6场景3中正常交通流下的算法性能对比
[0120][0121]
在高峰交通流的情况下,由图16,17和表7可知在平均等待时间方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了11.02%、20.87%和27.46%;在平均队列长度方面,dqn-ekf算法比double dqn、dueling dqn和dqn算法分别降低了14.69%、19.28%和27.61%。
[0122]
表7场景3中高峰交通流下的算法性能对比
[0123][0124][0125]
通过上述实验表明,dqn-ekf在不同交通仿真环境下的适用性和高效性。同时,通过对比实验充分证明dqn-ekf解决的dqn中存在的参数不确定性问题能够提高提高最终结果的准确度,并且dqn-ekf实验结果同样优于dueling dqn和double dqn。其中,主要原因为:(1)dueling dqn与dqn的区别在于不直接训练得到估计网络值函数,而是通过训练得到状态函数和优势函数相加得到值函数,以此解决估计网络值函数不准确的问题;(2)double dqn与dqn的区别在于目标网络值函数中的动作是根据估计网络参数计算得到最终结果,以此解决目标网络值函数过估计的问题。由此可见,dueling dqn和double dqn都只是在dqn的值函数结果上作出改进,并没有从根本上解决由参数不确定性导致的值函数不准确的问题,所以在对比实验中没有dqn-ekf的实验效果好。综上所述,由于dueling dqn和double dqn与dqn的网络结构基本相同并且同样存在参数不确定问题,所以double dqn和dueling dqn具有与ekf相结合的可行性。
[0126]
1)针对dqn中存在的参数不确定性问题,提出利用不确定性参数值作为ekf模型的输入,通过ekf模型的不断迭代更新得到真实参数的最优估计值,然后利用真实参数的最优估计值替代不确定性参数值得到准确的值函数并选择最优的配时方案。
[0127]
2)在实验部分设置了三种不同交通仿真环境,并分别在正常交通流和高峰交通流的情况下进行了对比试验,充分证明dqn-ekf能够有效的提高交通路口的通行效率,并适用于不同交通环境。
[0128]
3)分析说明dqn-ekf的实验结果优于dueling dqn、double dqn和dqn的主要原因,并讨论了dueling dqn和double dqn与ekf相结合的可能性。
[0129]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权
利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0130]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1