一种基于近端策略优化的交通信号控制方法
1.本发明属于智能交通信号控制技术领域,具体的说是一种基于近端策略优化的交通信号控制方法。
背景技术:
2.在城市机动车水平快速提升的今天,交通拥堵已经成为世界各大城市面临的严重问题。城市道路有限增长与汽车保有量无限增长之间的矛盾导致交通问题日益严重,特别是以小汽车为主导的大中城市正在面临严峻的交通拥堵问题。而交通信号控制,在道路资源有限、不易扩容的情况下,可以通过调动交通系统的时空资源,平衡交通压力,保证交通系统运行的安全和稳定,成为城市交通系统管控的重要手段之一。
3.然而,居民出行方式以及城市交通网络复杂度的快速变化,经典的信号控制方式逐渐显露出了一些问题,控制效果也渐渐达到了瓶颈阶段。首先,固定信号配时方案是基于交通流的短期时不变假设,根据历史的平均流量数据计算得到的,虽然计算简单便于实际使用,但是由于缺少交通流的实时监测数据,因此该方案并不能根据交通流的实时变化而做出调整。其次,感应控制方案仅对车辆的到达状态进行检测,虽然能一定程度响应交通流的变化,但是并没有对交通流的变化趋势进行判断,因此无法从整体上分析各方向的交通需求,很难保证车均延误的降低,并且当面对稀疏交通流状态时,控制效果往往较差。最后,自适应控制方式需要预设较多系统参数,如车辆启动延误,车辆安全距离等,这些参数不仅需要大量的现场测试和人工调整,耗时费力且普适性低。同时,对于非均质交通流的控制效果并不理想。因为交通信号控制的最优解没有固定的范式,在交通状态不断变化的条件下最优策略也随之改变,所以按照人类的经验很难定义最优控制策略。因此,以深度强化学习的方式完成信号控制自动调整成为研究的热点。然而现有基于强化学习的信号控制方法存在交通流动态时序特征难以有效抽取和利用,样本的差异度难以有效辐射到参数梯度变化因而模型收敛速度慢、实时性差等问题。
技术实现要素:
4.本发明是为了解决上述现有技术存在的不足之处,提出一种基于近端策略优化的交通信号控制方法,以期能够根据不同的交叉口交通运行状态,主动抽取交通流时序特征,实现信号控制策略的自适应调整以及系统的自学习、自迭代,从而能解决交叉口信号控制难以动态调整的问题,并提高交叉口运行效率。
5.本发明为达到上述发明目的,采用如下技术方案:
6.本发明一种基于近端策略优化的交通信号控制方法的特点是按如下步骤进行:
7.步骤1:建立交叉口仿真环境模型;
8.步骤2:收集真实场景中的交叉口信号相位数据和交通流状态数据作为原始数据,所述信号相位数据为信号控制机输出的信号相位、相序及相位持续时间数据,所述交通流状态数据为交叉口各进口道的交通状态数据;
9.步骤3:定义当前的回合数为n,定义信号相位集δ={δ0,δ1,...,δm},δm表示第m个信号相位,定义第n回合下t时刻的信号相位概率分布集p
n,t
={p
n,t,0
,p
n,t,1
,...,p
n,t,m
},p
n,t,m
表示第n回合下t时刻的第m个信号相位δm的概率输出值,定义第n回合下信号相位策略集an={a
n,0
,a
n,1
,...,a
n,t
,...,a
n,t
},a
n,0
表示第n回合下初始时刻的信号相位,a
n,t
表示第n回合下t时刻的信号相位,a
n,t
∈δ,t表示所设置信号控制的终止时刻,t=0,1,
…
,t;
10.定义第n回合交通状态集sn={s
n,0
,s
n,1
,...,s
n,t
,...,s
n,t
},s
n,0
表示第n回合下交叉口初始时刻的交通状态,s
n,t
表示第n回合下交叉口t时刻执行t-1时刻的信号控制相位a
n,t-1
后的交通状态,并有后的交通状态,并有表示第n回合下t时刻第k个交通指标值;
11.定义第n回合下t时刻的状态输入集s
n,t
={s
n,t
,s
n,t-1
,...,s
n,t-l
},0≤l≤t;
12.定义第n回合下奖励集rn={r
n,0
,r
n,1
,
…
,r
n,t
,
…rn,t
},r
n,t
表示第n回合下t时刻的奖励;
13.步骤4:构建基于lstm神经网络的信号策略网络actor和信号价值网络critic,其中,所述lstm神经网络的结构包括:输入层,卷积层,lstm层,全连接层,输出层;其中,所述卷积层包括:归一化层、卷积操作层、relu激活函数层;
14.所述信号策略网络actor包含两个结构一致,但参数不同的actor-new信号策略网络和actor-old信号策略网络;定义actor-new信号策略网络的参数为π
θ
,actor-old信号策略网络的参数为π
θ'
,critic信号价值网络的参数为πv;
15.步骤5:定义网络参数更新频率为α,最大回合数为n,初始化n=0;
16.建立经验存储集合d并初始化为空集;
17.步骤6:定义时刻t并初始化t=0;
18.步骤7:所述actor-new信号策略网络基于第n回合下t时刻的状态输入集s
n,t
计算得到第n回合下t时刻的信号相位概率分布p
n,t
,并采用ε-greedy算法对信号相位概率分布p
n,t
进行采样后得到第n回合下t时刻的信号相位a
n,t
;
19.步骤8:所述交叉口仿真环境模型执行第n回合下t时刻的信号相位a
n,t
并得到第n回合下t+1时刻的交通状态s
n,t+1
以及t时刻的奖励r
n,t
;从而由第n回合下t+1时刻的交通状态s
n,t+1
得到第n回合下t+1时刻的状态输入集s
n,t+1
;
20.将所述第n回合下t时刻的状态输入集s
n,t
、信号相位a
n,t
和奖励r
n,t
作为第n回合下t时刻的样本{s
n,t
,a
n,t
,r
n,t
,s
n,t+1
}放入至经验存储集合d中;
21.步骤9:判断t=t是否成立,若成立,则执行步骤10;否则,t+1赋值给t,并返回步骤步骤7顺序执行;
22.步骤10:所述critic信号价值网络基于第n回合下t时刻输入的状态输入集s
n,t
计算得到第n回合下t时刻的奖励估计值然后设置未来折现因子γ,并利用式(1)将奖励值按照时间维度倒序折减后,得到第n回合下t时刻的折扣奖励r
n,t
:
[0023][0024]
式(1)中,r
n,t
′
为第n回合下t
′
时刻得到的奖励值,当t
′
=t时,令0<γ≤1;
[0025]
步骤11:将经验存储集合d中第n回合下所有时刻的状态输入集合输入到critic信
号价值网络中,得到第n回合下所有状态的奖励估计值,然后利用式(2)计算actor-new信号策略网络在第n回合下t时刻的优势函数a
θ
(s
n,t
,a
n,t
),并作为状态输入集s
n,t
下选择信号相位a
n,t
的最终的奖励值:
[0026][0027]
步骤12:利用式(3)计算critic信号价值网络的损失函数c_loss,然后利用误差反向传播法更新critic信号价值网络的参数πv;
[0028][0029]
步骤13:将经验存储集合d中第n回合下所有时刻的状态输入集分别输入actor-old信号策略网络和actor-new信号策略网络,得到第n回合下每个信号相位在两个网络中对应的动作概率,并相应构成第n回合下动作概率集合prob
n,old
和prob
n,new
,从而利用式(4)得到第n回合下重要性采样权重ration:
[0030][0031]
步骤14:利用式(5)计算actor_new信号策略网络的损失函数a_loss,然后利用误差反向传播法更新actor_new信号策略网络的参数π
θ
:
[0032][0033]
式(5)中,e表示期望,clip(
·
)表示裁剪操作,ε表示裁剪系数,a
θ
′
(s
n,t
,a
n,t
)表示actor-old信号策略网络在第n回合下t时刻的优势函数,β表示范围控制的动态调整参数,并由式(6)得到,σ
β
表示控制阈值,且σ
β
>0;
[0034][0035]
步骤15:判断n=n是否成立,若成立,则将π
θ
赋值给π
θ'
,并保存模型参数π
θ
,从而完成actor信号策略网络和critic信号价值网络的训练;在实际信号控制中,基于参数π
θ
的actor信号策略网络根据交叉口交通状态输入,计算得到输出相应的信号相位;否则,n+1赋值给n,并返回步骤6顺序执行。
[0036]
本发明一种电子设备,包括存储器以及处理器,其特点在于,所述存储器用于存储支持处理器执行所述交通信号控制方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
[0037]
本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,其特点在于,所述计算机程序被处理器运行时执行所述交通信号控制方法的步骤。
[0038]
与现有技术相比,本发明的有益效果在于:
[0039]
1、本发明通过采用融合长短时记忆神经网络和近端策略优化算法,解决了交通流时序依赖特征的抽取以及信号相位选择空间与交通特征间的非线性映射问题,通过策略梯度动态范围调整,提高了模型的收敛速度,实现了信号控制算法的自适应迭代训练,大量减少了参数标定和人工调整的过程,从而在实际应用中节约了服务器的算力投入,使得交叉口能够根据交通状态自主动态调整信号相位策略而不需要人工干预,提高了交叉口的交通
运行效率和维护成本。
[0040]
2、本发明采用基于特征的值向量表示方法描述交通状态,克服了以往基于图像的离散流量状态编码方式需进行二次编码所带来的转换耗时以及图像的时序特征丢失等问题,从而保留了交通数据原始特征,且本发明基于现有部署的视频监控设备,实际可操作性强。
[0041]
3、本发明提出一种动态范围调整的自适应近端策略优化算法,通过加入范围控制的动态调整参数,克服了静态范围控制下梯度更新速度较慢的问题,提高了信号策略空间的探索幅度,提升了模型的收敛速度,从而节省了交叉口信号控制系统的分析决策时间,能够对道路交通流变化迅速作出反应,使得交叉口信号控制的实际应变能力增强。
附图说明
[0042]
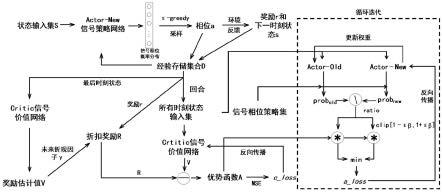
图1为本发明基于近端策略优化的交通信号控制方法的流程图。
具体实施方式
[0043]
本实施例中,一种基于近端策略优化的交通信号控制方法,是结合lstm神经网络以及近端策略优化的强化学习控制法来完成交叉口交通信号的自动控制,如图1所示,具体按如下步骤进行:
[0044]
步骤1:建立交叉口仿真环境模型,本实施例中,采用openstreetmap工具抽取实际道路电子地图,并将地图导入sumo仿真软件搭建信号控制交叉口基础环境;
[0045]
步骤2:收集真实场景中的交叉口信号相位数据和交通流状态数据作为原始数据,信号相位数据为信号控制机输出的信号相位、相序及相位持续时间数据,交通流状态数据为交叉口各进口道的交通状态数据,本实施例中,采用ids-2vs435-f832/t3-海康威视摄像机并结合yolov4算法,采集交叉口各进口道方向各条车道的交通状态数据,包括交通量、车辆平均速度、平均排队长度、平均停车等待时间、车道占有率;
[0046]
步骤3:定义当前的回合数为n,定义信号相位集δ={δ0,δ1,...,δm},δm表示第m个信号相位,定义第n回合下t时刻的信号相位概率分布集p
n,t
={p
n,t,0
,p
n,t,1
,
…
,p
n,t,m
},p
n,t,m
表示第n回合下t时刻的第m个信号相位δm的概率输出值,定义第n回合下信号相位策略集an={a
n,0
,a
n,1
,...,a
n,t
,...,a
n,t
},a
n,0
表示第n回合下初始时刻的信号相位,a
n,t
表示第n回合下t时刻的信号相位,a
n,t
∈δ,t表示所设置信号控制的终止时刻,t=0,1,
…
,t,本实施例中,信号相位集设为8个,分别为南北方向直行、东西方向直行、南北方向左转、东西方向左转、东方向直行和左转、西方向直行和左转、南方向直行和左转、北方向直行和左转;
[0047]
定义第n回合交通状态集sn={s
n,0
,s
n,1
,...,s
n,t
,...,s
n,t
},s
n,0
表示第n回合下交叉口初始时刻的交通状态,s
n,t
表示第n回合下交叉口t时刻执行t-1时刻的信号控制相位a
n,t-1
后的交通状态,并有后的交通状态,并有表示第n回合下t时刻第k个交通指标值,本实施例中,采用标准四叉路口,每个进口分为左、直、右三个车道方向,交叉口的交通状态采用交通量、车辆平均速度、平均排队长度、平均停车等待时间、车道占有率5个交通指标作为交通状态的特征表示,即交叉口的交通状态用4
×3×
5的向量进行表示;
[0048]
定义第n回合下t时刻的状态输入集s
n,t
={s
n,t
,s
n,t-1
,...,s
n,t-l
},0≤l≤t,本实
施例中,采用历史5分钟的交通状态组成状态输入集;
[0049]
定义第n回合下奖励集rn={r
n,0
,r
n,1
,
…
,r
n,t
,
…rn,t
},r
n,t
表示第n回合下t时刻的奖励,本实施例中,奖励设定为平均车速;
[0050]
步骤4:构建基于lstm神经网络的信号策略网络actor和信号价值网络critic,其中,lstm神经网络的结构包括:输入层,卷积层,lstm层,全连接层,输出层;其中,卷积层包括:归一化层、卷积操作层、relu激活函数层,本实施例中的卷积层,包括归一化、卷积、relu激活函数,卷积核的个数为64个,lstm层的lstm细胞单元个数为64个,全连接层的单元个数为200个,输出层采用sigmoid激活函数,信号策略网络actor该层的单元个数为8个,信号价值网络critic该层的单元个数为1个;
[0051]
信号策略网络actor包含两个结构一致,但参数不同的actor-new信号策略网络和actor-old信号策略网络,本实施例中的actor-new信号策略网络用于交叉口信号控制并根据奖励反馈不断更新神经网络参数,actor-old信号策略网络用于保存历史信号策略网络参数,并定期更新至最新的actor-new信号策略网络参数,通过对比两个信号策略网络参数,可以观察并控制参数梯度变化幅度;定义actor-new信号策略网络的参数为π
θ
,actor-old信号策略网络的参数为π
θ'
,critic信号价值网络的参数为πv;
[0052]
步骤5:定义网络参数更新频率为α,最大回合数为n,初始化n=0;
[0053]
建立经验存储集合d并初始化为空集;
[0054]
步骤6:定义时刻t并初始化t=0;
[0055]
步骤7:actor-new信号策略网络基于第n回合下t时刻的状态输入集s
n,t
计算得到第n回合下t时刻的信号相位概率分布p
n,t
,并采用ε-greedy算法对信号相位概率分布p
n,t
进行采样后得到第n回合下t时刻的信号相位a
n,t
,本实施例中,ε-greedy的系数设置为0.1,即90%的概率选择概率分布中最大值对应的信号相位;
[0056]
步骤8:交叉口仿真环境模型执行第n回合下t时刻的信号相位a
n,t
并得到第n回合下t+1时刻的交通状态s
n,t+1
以及t时刻的奖励r
n,t
;从而由第n回合下t+1时刻的交通状态s
n,t+1
得到第n回合下t+1时刻的状态输入集s
n,t+1
;
[0057]
将第n回合下t时刻的状态输入集s
n,t
、信号相位a
n,t
和奖励r
n,t
作为第n回合下t时刻的样本{s
n,t
,a
n,t
,r
n,t
,s
n,t+1
}放入至经验存储集合d中;
[0058]
步骤9:判断t=t是否成立,若成立,则执行步骤10;否则,t+1赋值给t,并返回步骤步骤7顺序执行;
[0059]
步骤10:critic信号价值网络基于第n回合下t时刻输入的状态输入集s
n,t
计算得到第n回合下t时刻的奖励估计值然后设置未来折现因子γ,并利用式(1)将奖励值按照时间维度倒序折减后,得到第n回合下t时刻的折扣奖励r
n,t
:
[0060][0061]
式(1)中,r
n,t
′
为第n回合下t
′
时刻得到的奖励值,当t
′
=t时,令0<γ≤1,本实施例中,未来折现因子γ取值为0.9;
[0062]
步骤11:将经验存储集合d中第n回合下所有时刻的状态输入集合输入到critic信号价值网络中,得到第n回合下所有状态的奖励估计值,然后利用式(2)计算actor-new信号
策略网络在第n回合下t时刻的优势函数a
θ
(s
n,t
,a
n,t
),并作为状态输入集s
n,t
下选择信号相位a
n,t
的最终的奖励值:
[0063][0064]
步骤12:利用式(3)计算critic信号价值网络的损失函数c_loss,然后利用误差反向传播法更新critic信号价值网络的参数πv;
[0065][0066]
步骤13:将经验存储集合d中第n回合下所有时刻的状态输入集分别输入actor-old信号策略网络和actor-new信号策略网络,得到第n回合下每个信号相位在两个网络中对应的动作概率,并相应构成第n回合下动作概率集合prob
n,old
和prob
n,new
,从而利用式(4)得到第n回合下重要性采样权重ration:
[0067][0068]
本实施例中,通过计算重要性采样权重可以得到actor-old信号策略网络和actor-new信号策略网络输出的概率分布变化,用于判断两个信号策略网络参数梯度的变化幅度;
[0069]
步骤14:利用式(5)计算actor_new信号策略网络的损失函数a_loss,然后利用误差反向传播法更新actor_new信号策略网络的参数π
θ
:
[0070][0071]
式(5)中,e表示期望,clip(
·
)表示裁剪操作,ε表示裁剪系数,a
θ
′
(s
n,t
,a
n,t
)表示actor-old信号策略网络在第n回合下t时刻的优势函数,β表示范围控制的动态调整参数,并由式(6)得到,σ
β
表示控制阈值,且σ
β
>0;
[0072][0073]
本实施例中,ε裁剪系数取值为0.2,σ
β
控制阈值取值为0.1,通过将重要性采样权重与优势函数相乘并进行梯度裁剪作为actor_new信号策略网络的参数更新函数,使得具有更高平均奖励期望的信号相位选择概率得到增大,并且本实施例中采用动态调整参数β,能够随着奖励期望的值动态调整梯度变化幅度,从而加快信号策略网络参数的收敛;
[0074]
步骤15:判断n=n是否成立,若成立,则将π
θ
赋值给π
θ'
,并保存模型参数π
θ
,从而完成actor信号策略网络和critic信号价值网络的训练;在实际信号控制中,基于参数π
θ
的actor信号策略网络根据交叉口交通状态输入,计算得到输出相应的信号相位;否则,n+1赋值给n,并返回步骤6顺序执行。
[0075]
本实施例中,一种电子设备,包括存储器以及处理器,该存储器用于存储支持处理器执行该交通信号控制方法的程序,该处理器被配置为用于执行该存储器中存储的程序。
[0076]
本实施例中,一种计算机可读存储介质,是在计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行该交通信号控制方法的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1