基于机器学习与协同过滤的交通流自适应预测方法与流程
本发明涉及一种基于机器学习模型和协同过滤算法的城市道路短时交通流自适应预测方法,属于智能交通领域,尤其属于智能交通中的交通流预测。
背景技术:
1、随着社会和经济的发展,城市化进程快速推进,城市机动车保有量快速增长,交通拥堵问题日益严重。为了保证城市交通的健康平稳运行,智能交通系统应运建立起来。而短时交通流预测技术就是智能交通系统的关键组成部分,应用于实时信号控制、路径诱导、自动导航等模块。
2、短时交通流预测通常指的是交通流量的短时预测,预测时间一般限定在15分钟内。经过几十年的研究和发展,短时交通流预测模型领域诞生了许多模型,例如基于简单规则的历史趋势平均模型、基于线性回归以及卡尔曼滤波等数学模型的参数模型、数据驱动的非参数机器学习模型。随着近年交通检测器的快速发展和广泛应用,交通数据储存能力和处理能力的提高,基于机器学习的交通流短时预测研究成为热点。主要的非参数机器学习模型包括k最近邻、支持向量回归、神经网络等等。堆栈式长短期记忆神经网络(lstms,stacked long short-term memory networks)是循环神经网络的一种变体,属于深度学习模型,在时间序列建模问题上有一定的优势,具有长时记忆能力,常用于交通流预测。深度学习模型一般来说预测精度高于其它机器学习模型,但需要更多的数据、更长的时间进行训练,对算力的要求很高。
3、协同过滤算法是目前应用广泛的推荐算法。该算法通过对用户历史行为数据的挖掘发现用户的偏好,进而对用户进行归类,从而给同类用户进行商品推荐。
4、现有的短时交通流预测方法研究大多都是寻找一种全局最优的模型来解决所有道路的流量预测问题。但是实际上不同的道路之间等级差异和功能差异很大,导致了道路流量变化规律存在明显不同。并且对于同一条道路不同时段的流量变化特征也存在显著差异。因此不同模型对于不同道路以及不同时段的交通流存在不同的适用性。并且在现有研究中深度学习模型在短时交通流预测方面取得了优异的成绩,但是在实际应用中深度学习模型训练对服务器算力的要求过高以及模型训练时长过长,大幅增加了使用门槛和时间成本。因此在利用深度学习模型来提高预测精度的同时,如何节省算力和时间成本也成为一个急需解决的问题。
技术实现思路
1、本发明要解决的技术问题是:在利用深度学习模型来提高交通流预测精度的同时,如何节省算力和时间成本。
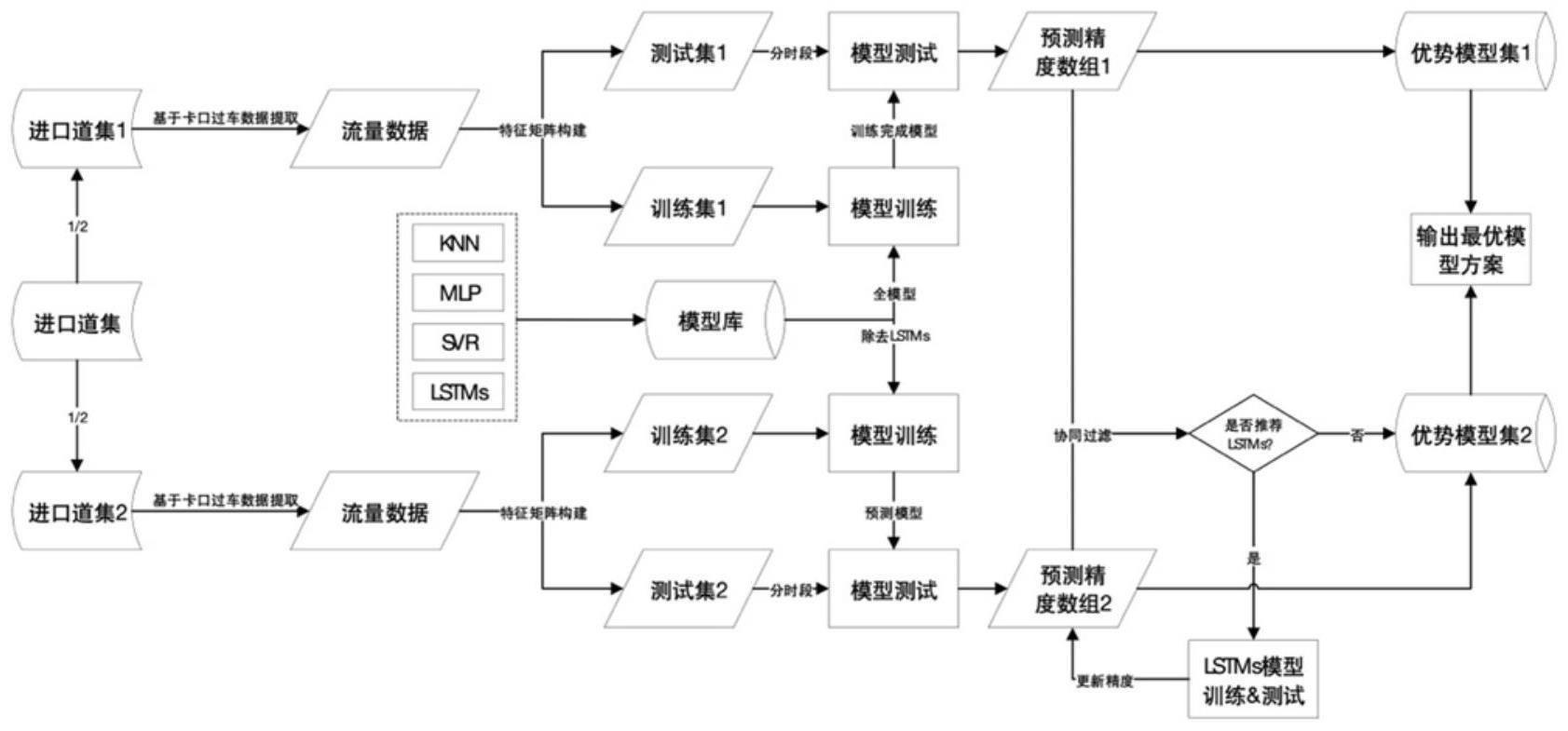
2、为了解决上述技术问题,本发明的技术方案是提供了一种基于机器学习与协同过滤的交通流自适应预测方法,其特征在于,包括以下步骤:
3、步骤1:建立用于机器学习模型训练的训练集以及测试集;
4、步骤2:基于训练集以及测试集构建用于输入机器学习模型的特征矩阵,该特征矩阵包含流量信息、对应时段的工作日/非工作日信息以及对应的时段信息;
5、步骤3:建立模型精度p的计算公式,如下式所示:
6、
7、式中,mape为基于平均绝对百分比误差转化计算得到的模型精度指标;
8、步骤4:构建包含多个非参数机器学习模型以及一个深度学习模型的模型库;
9、步骤5:确定不同进口道流量预测在不同时段的优势模型,包括以下步骤:
10、步骤501:将n个进口道划分为两个进口道集合,分别表示为进口道集合c1以及进口道集合c2;
11、步骤502:对属于进口道集合c1的进口道,利用训练集对模型库中的所有模型进行全模型的训练;训练完成后,利用测试集分t个时段对模型的预测精度进行计算,则获得进口道集合c1中各个进口道在每种模型下不同时段的预测精度三维数组为pi*m*t,其中,i为进口道编号,i∈c1;m表示模型库中的第m种模型;t为时段种类,t∈t;
12、对属于进口道集合c2中的进口道,利用训练集对模型库中除去深度学习模型外的其他模型进行训练;训练完成后,利用测试集分t个时段对模型的预测精度进行计算,则获得进口道集合c2中各个进口道在除去深度学习模型外的其他模型下不同时段的预测精度数组pj*m*t,其中,j为进口道编号,j∈c2;m表示模型库中除深度学习模型外的第m种模型;t为时段种类,t∈t;
13、步骤503:根据预测精度数组获取优势模型,并保存优势模型,最终得到分别属于进口道集合c1以及进口道集合c2不同进口道流量预测在不同时段的优势模型
14、步骤6:参考皮尔逊相关系数计算公式对进口道间的相似度进行计算:
15、
16、
17、
18、式中,si*j为进口道集合c1中的进口道i和进口道集合c2中的进口道j之间的相似度;pimt、pjmt分别为进口道i、进口道j基于预测模型m在预测时段t的流量预测精度,i∈c1,j∈c2;分别为进口道i、进口道j的精度平均值;nm为模型库中非参数机器学习模型的数量、nt为时段个数;
19、步骤7:基于步骤6计算得到的相似度获得进口道集合c1中的进口道i和进口道集合c2中的进口道j之间的相似度矩阵si*j,遍历相似度矩阵si*j的每一列得到最终的优势模型其中,对于相似度矩阵si*j中的当前一列,有:
20、获取相似度矩阵si*j当前一列的最大值v以及对应的进口道号,i=n1,j=n2,若v≥阈值,则认为进口道i=n1是进口道j=n2的相似进口道;若v<阈值,则在进口道集合c1中没有与进口道j=n2相似的进口道;
21、若进口道j=n2存在相似进口道,则基于相似进口道i=n1对深度学习模型进行推荐:根据进口道i=n1的优势模型集合判断深度学习模型是否为其优势模型之一,具体步骤如下:
22、若则进口道j=n2保持原有的优势模型策略
23、若则进口道j=n2对模型库中的lstms进行训练,得到预测精度更新该进口道流量预测的优势模型
24、若进口道j=n2不存在相似进口道,则同样进口道j=n2对模型库中的lstms进行训练,得到预测精度更新该进口道流量预测的优势模型
25、优选地,所述步骤1包括以下步骤:
26、步骤101:确定研究的交通流预测空间范围、采集数据时间范围、流量统计间隔、预测时间间隔;在指定空间和时间范围内采集城市道路交叉口进口道的卡口过车数据集,用于后续的流量数据提取;
27、步骤102:对获取的卡口过车数据进行数据预处理,得到预处理后的卡口过车数据集,按照统计间隔对预处理后的卡口过车数据集进行流量统计,得到每个交叉口的各个进口道的流量数据集;
28、步骤103:将流量数据集切分为训练集以及测试集。
29、优选地,步骤2中,对所述流量信息利用标准化公式进行归一化处理。
30、优选地,步骤2中,对所述工作日/非工作日信息以及对应的时段信息以独热编码的方式进行归一化处理。
31、优选地,步骤3中,所述模型精度指标mape的计算公式为:
32、
33、式中,yt为t时段的流量真实值;为流t时段的流量预测值;n为统计的时段个数;∈为一个极小值。
34、优选地,步骤501中:若n为偶数,则由前n/2个进口道组成所述进口道集合c1,后n/2个进口道组成所述进口道集合c2;若n为奇数,则由前(n+1)/2个进口道组成所述进口道集合c1,后(n-1)/2个进口道组成所述进口道集合c2。
35、优选地,步骤503中,优势模型选择逻辑为:假设某进口道流量预测精度最高的两个模型分别为m1、m2,精度分别为p1、p2且p1≥p2:
36、若m1、m2都为非参数机器学习模型,则取精度最高的模型m1为优势模型;
37、若m2为深度学习模型,则模型m1为优势模型;
38、若m1为深度学习模型且则模型m1为优势模型,则m2为优势模型。
39、与现有技术相比,本发明具有如下有益效果:
40、1)提高了预测精度。
41、利用数据驱动的非参数机器学习模型库对城市道路流量分进口道、分时段进行预测。摒弃了全局最优预测模型方案,在多种模型中择优进行选择,保证了每个进口道不同时段能有最优的预测效果;并且在模型库中加入了预测性能更好的深度学习模型lstms,提高了预测精度上限。
42、2)节省算力和训练时间。
43、利用协同过滤的思想,只须用部分进口道进行全模型训练,即可达到所有进口道获得最优模型的效果。避免了所有进口道进行深度学习模型的训练,节省了算力和训练时间。
- 还没有人留言评论。精彩留言会获得点赞!