基于耦合驱动算法的行人安全过街仿真系统
本技术属于交通数据分析,具体涉及一种基于耦合驱动算法的行人安全过街仿真系统。
背景技术:
1、行人是城市道路和公共场所中最为普遍的交通参与者之一,其行为和决策对于公共安全具有很大的影响。而行人仿真在公共安全研究中扮演着重要的角色,增强仿真环境中智能体的真实性一直是一个难题。
2、现有技术中,缺乏在仿真中结合反映行人动力学行为的因素,而且还会在仿真中出现行人碰撞等非现实的现象,限制了仿真的真实性和可信度。以及无法由无信号交叉口车辆仿真推广到更复杂的行人仿真的问题,或者是行人仿真不适用于无信号交叉口的仿真问题。
技术实现思路
1、有鉴于此,本技术的目的在于提出基于耦合驱动算法的行人安全过街仿真系统,用以解决或部分解决上述技术问题。
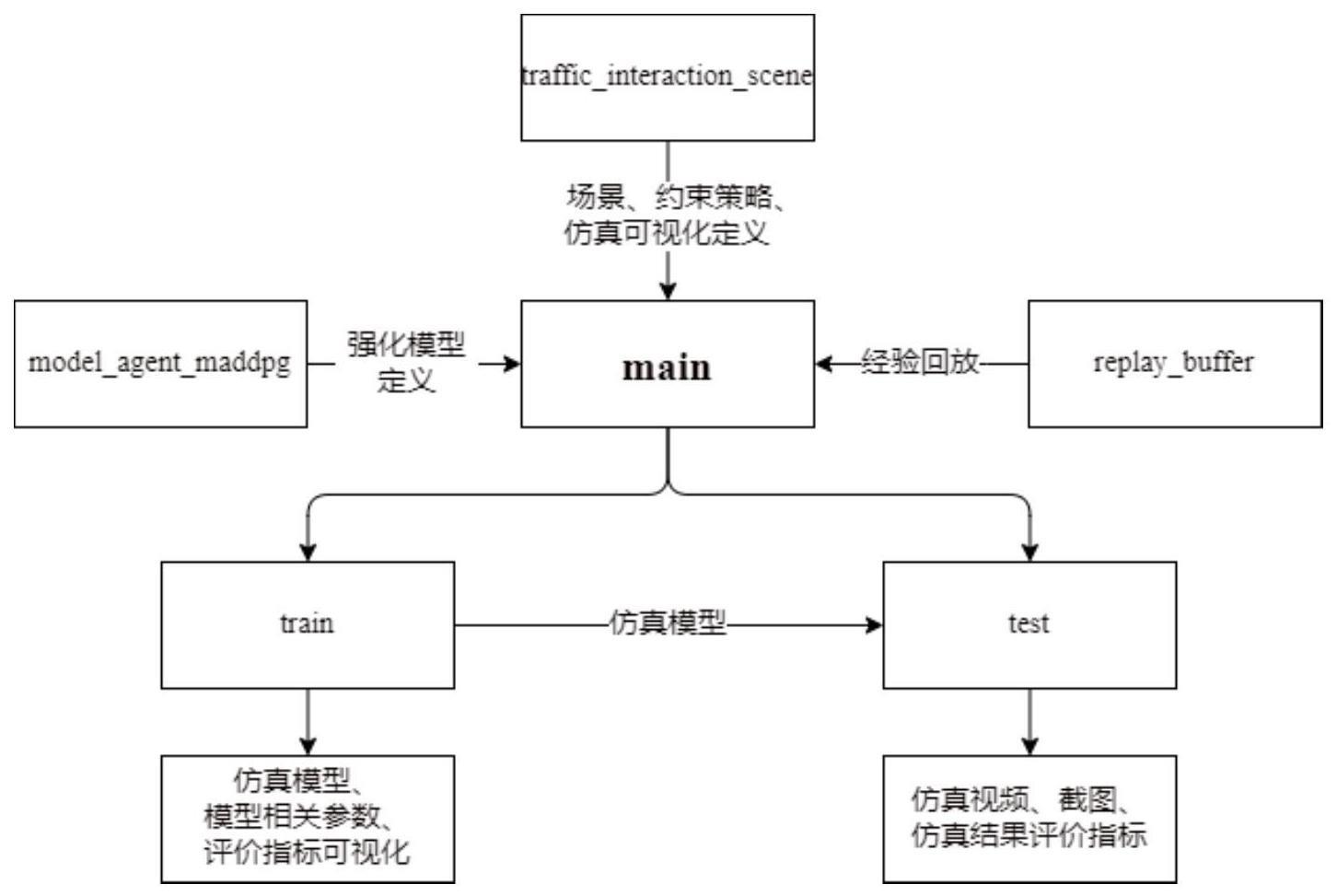
2、基于上述目的,本技术提供了一种基于耦合驱动算法的行人安全过街仿真系统,包括主函数模块,深度强化模型模块,智能体环境交互模块和经验回放模块;
3、所述主函数模块用于调用所述深度强化模型模块、所述智能体环境交互模块和所述经验回放模块;
4、所述深度强化模型模块包括策略网络子模块、策略目标网络子模块、价值网络子模块、价值目标网络子模块和经验池子模块;
5、所述策略网络子模块用于策略网络参数的迭代更新,根据指定时刻行人智能体状态进行动作选择,并与环境交互生成下一状态;
6、所述策略目标网络子模块用于从所述经验池子模块中采样,选取最优动作,并定期更新策略网络目标参数;
7、所述价值网络子模块用于价值网络参数的迭代更新,计算指定时刻的即时报酬和输出总和;
8、所述价值目标网络子模块用于计算价值网络参数的q值,并定期更新价值网络目标参数;
9、所述经验池子模块用于策略网络参数、策略网络目标参数、价值网络参数、价值网络目标参数的存储,并为所述策略目标网络子模块和所述价值目标网络子模块的动作生成提供采样依据;
10、所述智能体环境交互模块包括环境交互子模块,所述环境交互子模块用于将所给的深度确定性策略梯度算法产生的行人加速度与行人动力学模型产生的加速度进行比较,使行人智能体倾向于选择相对安全的动作,以及使选择动作的策略从更优角度出发取合理值,最终将较大值作为最后的加速度进行输出;
11、所述经验回放模块包括经验回放缓冲区子模块和经验回放器子模块,所述经验回放缓冲区子模块根据经验数据在所述经验回放缓冲区子模块中的优先级进行采样。
12、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,所述主函数模块包括训练子模块和测试子模块;所述训练子模块用于根据已有的信息,训练仿真模型;所述测试子模块用于检验所述训练子模块的实际效果,所述测试子模块通过调整行人流量的大小进行不同场景下的测试。
13、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,所述训练子模块的训练过程包括:
14、输入训练集、定义训练环境的参数;
15、代入数据在指定的训练环境中训练模型;
16、如果训练回合数到达指定的迭代上限,或是训练的指标达到要求,则停止训练;
17、输出最后训练完成的仿真模型;
18、所述测试子模块的测试过程包括:
19、输入测试数据集、定义测试环境的参数;
20、代入数据在指定的训练环境中训练模型;
21、如果测试回合数到达指定的迭代上限,则停止测试仿真;
22、输出仿真场景测试视频,每一帧仿真场景的截图以及评估模型效果的数据。
23、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,所述训练子模块中,使用随机生成的时间序列tseq=[t1,...,tn]构建训练集,以模拟不同道路的行人流量;
24、每条道路的时间序列根据泊松分布随机生成,时间序列的生成方式为:
25、
26、其中,△tmin表示前后行人进入交叉口的时间间隔阈值;fr是行人流量,即每小时通过该道路的行人数目除以道路数;r表示服从标准正态分布的随机变量。
27、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,所述深度强化模型模块采用深度确定性策略梯度算法,深度确定性策略梯度算法中,将t时刻智能体状态st的策略网络参数、策略网络目标参数、价值网络参数、价值网络目标参数输入演员网络计算当前状态下的动作。
28、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,将深度确定性策略梯度算法和行人二维优化速度模型耦合驱动,包括:
29、将每个行人的状态作为程序输入,包括行人的速度、与前一辆行人的距离、前一辆行人的速度及行人是否已经通过交叉路口信息;
30、与行人的环境进行交互,生成两个加速度,一个加速度由深度强化学习策略生成的,另一个加速度由当前行人的速度、与前一行人的距离以及前一行人的速度决定的行人动力学模型加速度;
31、将生成的两个加速度大小进行比较决策,以更新实际加速度;
32、输出行人的加速度,并使用输出的加速度更新行人状态;
33、如果有未通过交叉路口的行人,则循环遍历所有行人,直到遍历完毕。
34、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,深度确定性策略梯度算法采用双网络结构,双网络结构经过随机抽样训练后目标网络的权值进行一次软更新,最终输出策略网络参数和评价网络参数作为状态参量,参与t+1时刻的深度确定性策略梯度算法的神经网络。
35、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,当所述经验池子模块存满时,以最新样本覆盖最老样本,每次训练从缓冲区中随机抽取样本以更新策略和评论家网络。
36、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,所述智能体环境交互模块还包括可视化子模块,所述可视化子模块用于对所述环境交互子模块的过程进行可视化展示。
37、作为基于耦合驱动算法的行人安全过街仿真系统优选方案,所述经验回放缓冲区子模块中,经验数据被添加到所述经验回放器子模块中,每次从所述经验回放器子模块中采样预设数量的经验数据进行训练,同时记录被采样数据在所述经验回放器子模块中的id和权重。
38、从上面所述可以看出,本技术提供的技术方案,通过主函数模块调用深度强化模型模块、智能体环境交互模块和经验回放模块;深度强化模型模块包括策略网络子模块、策略目标网络子模块、价值网络子模块、价值目标网络子模块和经验池子模块;策略网络子模块用于策略网络参数的迭代更新,根据指定时刻行人智能体状态进行动作选择,并与环境交互生成下一状态;策略目标网络子模块用于从经验池子模块中采样,选取最优动作,并定期更新策略网络目标参数;价值网络子模块用于价值网络参数的迭代更新,计算指定时刻的即时报酬和输出总和;价值目标网络子模块用于计算价值网络参数的q值,并定期更新价值网络目标参数;经验池子模块用于策略网络参数、策略网络目标参数、价值网络参数、价值网络目标参数的存储,并为策略目标网络子模块和价值目标网络子模块的动作生成提供采样依据;智能体环境交互模块包括环境交互子模块,环境交互子模块用于将所给的ddpg强化模型产生的行人加速度与行人动力学模型产生的加速度进行比较,将较大值作为最后的加速度进行输出;经验回放模块包括经验回放缓冲区子模块和经验回放器子模块,经验回放缓冲区子模块根据经验数据在经验回放缓冲区子模块中的优先级进行采样。本发明考虑了行人动力学行为,增加了环境建模,使得对行人智能体的描述更加接近于真实场景,增强了行人仿真方面的真实性;可以正确描述行人智能体安全、高效地完成行人过街任务,并且控制效率较高,完成行人避免碰撞的能力更强,能够较好、较快地适应于无信号交叉口场景下的行人仿真。
- 还没有人留言评论。精彩留言会获得点赞!