一种高速服务区卡口车辆稽核系统及其方法与流程
本发明涉及交通控制,尤其涉及一种高速服务区卡口车辆稽核系统及其方法。
背景技术:
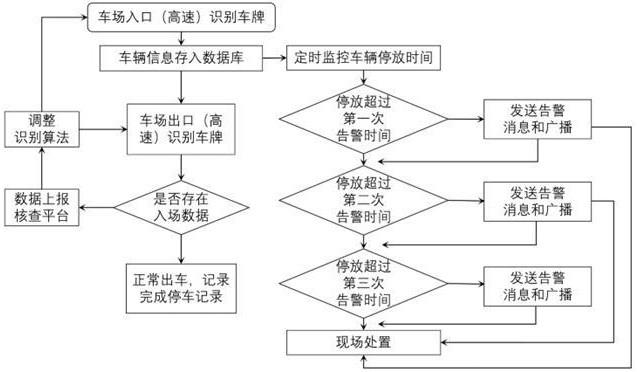
1、随着经济的高速发展,机动车保有量逐年增多,高速公路因便捷、高效而被选择作为首要出行方式,因此高速服务区的车辆服务体验面临着巨大的考验。随着物联网技术和人工智能ai技术的发展,精准的图片、视频识别算法技术和硬件产品提供了先进的技术手段,停车场系统利用这些技术手段进行数据采集和算法处理,对车辆信息数据进行数字化分析,产生相应的告警信息推送,结合工作人员智能终端,来对高速服务区车辆停放信息进行稽核,优化停车管理方式,提高车主服务体验。
2、cn113808398a公开一种车辆实时定位核查系统及核查方法,通过在云平台系统比对相关联的时间节点的前端采集子系统抓拍车辆信息以及车载采集子系统上传的车辆信息,判断车载采集子系统是否工作异常,从而保障车载采集子系统能够实时、有效地工作,保障云平台系统的核算数据更加精准,推动车辆运行数据的全面掌控。
3、传统的停车服务系统,仅局限于市政规划的停车场,其适应于车辆速度较慢、车辆流动性较弱且流动速率较慢的停车场景,在传统停车场中,因停车场位置比较集中,因而车主可以有更多的选择;高速车场停车位置比较分散、车辆流动速率较快,而传统的摄像设备通常采用射频识别技术,通过监测停车场进出口、高速站进出口等需要减速通过的点位,计算车辆每次进入停车场和驶出停车场之间的时间间隔来识别车辆,此种方式虽然简单方便,但其精度差,且具有局限性,特别是在极端恶劣天气下,如暴风、雨雪及沙尘等环境致使其无法准确识别车辆,因此传统的软硬件技术无法支持高速服务区卡口车辆的信息采集;另外,传统停车场与高速停车场的业务侧重点不一样,传统停车场对车辆停放时间没有限制,而高速服务区停车场则需要关注长时间驻停的车辆信息,高速服务区更加注重安全高效。
4、更进一步地,对于高速服务区而言,由于车流量巨大,为了方便管理服务区的道路交通,避免因管理不当引起的交通堵塞等问题,需要精准把控进入高速服务区的车辆信息。然而,由于高速服务区通常采用卡口相机的方式对出入服务区的车辆信息进行识别记录,在识别过程中难免会出现识别错误的情况,比如由于天气、灯光等因素的影响,导致现有的卡口相机通过图像识别车牌字符时将两个相似的字符识别混淆,例如“b”和“8”,“s”和“5”,“i”和“1”等,由此造成卡口相机识别错误,从而造成车辆信息记载错误的问题,引起后续稽核结果的失准。
5、综上,传统的停车软硬件技术不适用于高速服务区卡口稽核系统的要求,无法满足高速服务区车辆及道路交通管理的需求,也无法提升高速路车主的出行体验。
6、此外,一方面由于对本领域技术人员的理解存在差异;另一方面由于申请人做出本发明时研究了大量文献和专利,但篇幅所限并未详细罗列所有的细节与内容,然而这绝非本发明不具备这些现有技术的特征,相反本发明已经具备现有技术的所有特征,而且申请人保留在背景技术中增加相关现有技术之权利。
技术实现思路
1、针对现有技术之不足,本发明提供了一种高速服务区卡口车辆稽核系统及其方法,旨在解决现有技术中存在的至少一个或多个技术问题。
2、为实现上述目的,本发明提供了一种高速服务区卡口车辆稽核系统,包括:
3、摄像模块,用于获取车辆于高速服务区卡口入口的第一车辆图像和于高速服务区卡口出口的第二车辆图像;
4、处理模块,用于处理第一车辆图像和第二车辆图像以形成第一车辆信息集和第二车辆信息集;
5、其中,
6、处理模块能够基于第一车辆信息集与第二车辆信息集中的车辆信息匹配结果可选择地确定针对高速服务区卡口车辆的识别模型的优化模式。
7、优选地,处理模块基于第一车辆信息集与第二车辆信息集中的车辆信息匹配结果可选择地确定针对高速服务区卡口车辆的识别模型的优化模式包括:
8、若第一车辆信息集与第二车辆信息集彼此存在匹配对应的车辆信息,则处理模块以第一周期执行针对识别模型的第一优化模式;
9、若第一车辆信息集与第二车辆信息集彼此存在未匹配对应的车辆信息,则处理模块基于对未匹配对应的车辆信息的核验结果来确定是否执行针对识别模型的第二优化模式。
10、优选地,若第一车辆信息集与第二车辆信息集彼此存在匹配对应的车辆信息,则处理模块以第一周期执行针对识别模型的第一优化模式包括:
11、处理模块将匹配对应的车辆信息添加至第三车辆信息集,并基于第三车辆信息集包含的车辆信息以第一周期训练识别模型。
12、优选地,若第一车辆信息集与第二车辆信息集彼此存在未匹配对应的车辆信息,则处理模块基于对未匹配对应的车辆信息的核验结果来确定是否执行针对识别模型的第二优化模式包括:
13、处理模块将未匹配对应的车辆信息添加至第四车辆信息集,并交由人工核验,其中,
14、若针对未匹配对应的车辆信息的核验结果为车辆自身因素,则处理模块不执行针对识别模型的训练;
15、若针对未匹配对应的车辆信息的核验结果为非车辆自身因素,则处理模块基于第四车辆信息集包含的车辆信息以第二周期或第三周期训练识别模型。
16、优选地,若针对未匹配对应的车辆信息的核验结果为非车辆自身因素,则处理模块基于第四车辆信息集包含的车辆信息以第二周期或第三周期训练识别模型包括:
17、若针对未匹配对应的车辆信息的核验结果为环境因素,则处理模块基于第四车辆信息集包含的车辆信息以第二周期训练识别模型;
18、若针对未匹配对应的车辆信息的核验结果为偶然因素,则处理模块基于第四车辆信息集包含的车辆信息以第三周期训练识别模型。
19、优选地,处理模块基于第四车辆信息集包含的车辆信息以第二周期或第三周期训练识别模型之前还包括:
20、处理模块以数据增强和/或数据合成的方式对第四车辆信息集中至少包含车牌信息的图像数据进行扩充处理,并将扩充后的若干图像数据以与对应车牌数据相关联的方式形成训练样本。
21、优选地,处理模块能够基于第一车辆信息集中的车辆进入高速服务区的时间点针对场内车辆生成梯度时间告警信号。
22、优选地,本发明提供的高速服务区卡口车辆稽核系统还包括交互模块,该交互模块配置为向高速服务区的各方管理人员展示场内的车辆信息。
23、优选地,处理模块能够基于第一车辆信息集和第二车辆信息集中的车辆信息进行分析判断,并将异常车辆信息传输至稽查单位进行处置。处理模块可以将异常车辆信息实时发送至官方高速稽查单位,由稽查单位及时采取相应措施,避免安全隐患。
24、优选地,处理模块能够将第一车辆信息集和第二车辆信息集整合为停车记录列表,并将该停车记录列表通过交互模块输出至终端管理界面,以允许使用者筛选并浏览停车记录列表之中的车辆信息。
25、优选地,处理模块能够基于车辆信息列表/集中的车辆进入高速服务区的时间点针对场内车辆生成梯度时间告警信号。
26、优选地,本发明还涉及一种高速服务区卡口车辆稽核方法,可以包括:
27、获取车辆于高速服务区卡口入口的第一车辆图像和于高速服务区卡口出口的第二车辆图像;
28、处理第一车辆图像和第二车辆图像以形成第一车辆信息集和第二车辆信息集;
29、基于第一车辆信息集与第二车辆信息集中的车辆信息匹配结果可选择地确定针对高速服务区卡口车辆的识别模型的优化模式。
30、优选地,基于第一车辆信息集与第二车辆信息集中的车辆信息匹配结果可选择地确定针对高速服务区卡口车辆的识别模型的优化模式之步骤可包括:
31、若第一车辆信息集与第二车辆信息集彼此存在匹配对应的车辆信息,则以第一周期执行针对识别模型的第一优化模式;
32、若第一车辆信息集与第二车辆信息集彼此存在未匹配对应的车辆信息,则基于对未匹配对应的车辆信息的核验结果来确定是否执行针对识别模型的第二优化模式。
33、优选地,若第一车辆信息集与第二车辆信息集彼此存在匹配对应的车辆信息,则以第一周期执行针对识别模型的第一优化模式之步骤可包括:
34、将匹配对应的车辆信息添加至第三车辆信息集;
35、基于第三车辆信息集包含的车辆信息以第一周期训练识别模型。
36、优选地,若第一车辆信息集与第二车辆信息集彼此存在未匹配对应的车辆信息,则基于对未匹配对应的车辆信息的核验结果来确定是否执行针对识别模型的第二优化模式之步骤可包括:
37、将未匹配对应的车辆信息添加至第四车辆信息集,并交由人工核验,其中,
38、若针对未匹配对应的车辆信息的核验结果为车辆自身因素,则不执行针对识别模型的训练;
39、若针对未匹配对应的车辆信息的核验结果为非车辆自身因素,则基于第四车辆信息集包含的车辆信息以第二周期或第三周期训练识别模型。
40、采用本发明所述的高速服务区卡口车辆稽核系统,可以有效地对高速服务区车场停车记录管理维护,通过对车位信息进行实时监控,能够及时响应应急处置,同时通过数字化平台分析车流量,执勤人员可对停车流量进行分析对比,提前预知大流量和异常流量车辆时段,及时做出应急服务调整,同时为其他平台提供数据支持。此外,本发明支持个性化车辆超时告警功能,能够指导执勤人员快速有效地对告警车辆进行稽核处置,形成工作闭环,减少车位无效占用的风险。本发明中,稽核系统能够在卡口相机识别出错的情况下基于识别出错的样本作为训练集再次对识别模型进行优化,降低在后续出现相似的容易识别错误的特征图像时卡口相机再次识别错误的概率,并且在长期连续的运转中不断优化更新自身的识别样本库以及识别模型,以显著降低卡口相机识别错误的概率,为服务区的车流量精确管理提供有力的技术保障。卡口相机在绝大多数场景下的识别结果是可靠的,识别错误通常是由天气、灯光及拍摄角度等多种因素造成的,因此何时会出现识别错误/匹配失败的情况是无法准确预测的,若以固定周期对识别算法/模型进行训练或优化,则样本数据的特征段大致相同,基于此训练带来的优化效果并不显著,且消耗大量计算时间占用过多不必要的资源,而若以识别失败的次序为训练周期,则既能够保证及时对识别算法/模型进行优化更新的需求,也能够在每次优化训练时都有新的偶然样本(因天气或偶然事件所导致的识别失败)作为训练集,充分扩展了训练集的特征段,以使得优化训练的优化效果更显著。
- 还没有人留言评论。精彩留言会获得点赞!