一种用于低压台区的用户网络拓扑识别装置及方法与流程
本发明属于电力自动化技术领域,具体涉及一种用于低压台区的用户网络拓扑识别装置及方法。
背景技术:
随着我国城镇化的迅速发展建设,电力用户数量大量增加,实现配电网用电管理的信息化和智能化具有重要意义。在实现配电网管理信息化和智能化的过程中,许多功能离不开配电网本身的拓扑结构信息。
在低压台区,由于过去对其重视程度不够,许多台区缺乏管辖用户信息,更不清楚用户点之间的拓扑关系。现有的台区识别方法主要基于载波通信技术,但变压器不能完全隔离载波信号,载波信号存在跨台区串扰问题,导致基于载波通信技术的识别方式准确率较低。
但现有的用于低压台区的网络拓扑识别方法存在如下几点缺陷:
1、通过低压台区运行的维护人员拉闸观察和人工描绘的方式记录台区结构的方法效率低,且无法实现统一的数字化存储,且没有统一的接口供系统进一步利用。
2、基于载波通信技术的台区识别方法中,变压器不能完全隔离载波信号,载波信号存在共高压、共地、共电缆沟串线等跨台区串扰问题,导致基于载波通信技术的识别方式准确率较低。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提供一种设计合理、有比较好的台区用户网络拓扑识别能力且能够提升配电网管理信息化和智能化的水平的用于低压台区的用户网络拓扑识别装置及方法。
本发明的目的是通过以下技术方案实现的:
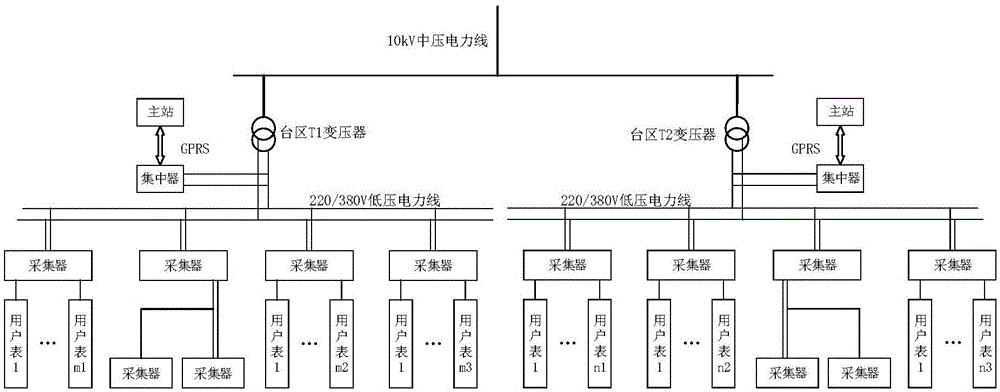
一种用于低压台区的用户网络拓扑识别装置,包括由采集器、集中器和主站组成的用电信息采集系统;所述采集器用于采集电能表的电能信息,并与集中器交换数据;所述集中器用于收集各采集器或电能表的数据,并进行台区拓扑识别所需的数据信息的储存和处理;通过获取主站发出的台区网络拓扑识别信号,并将储存的台区用户数据上传至主站;所述主站用于实现低压台区的用户网络拓扑识别算法,生成最终的台区网络拓扑图;向集中器发送拓扑识别指令、获取集中器上传的数据信息。
一种用于低压台区的用户网络拓扑识别方法,包括以下步骤:
(1)电能表用于定时采集用户电量数据和电能信息;
(2)电能表将数据和信息输出至各自对应的数据采集器,最终由集中器收集台区的所有采集器和电能表数据,从而得到台区用户网络拓扑识别的原始数据;
(3)需要获取台区网络拓扑时,由主站向集中器发送拓扑识别指令,集中器将储存的用户数据上传至主站;
(4)主站对上传的电压数据进行分组,每12h的电压数据为一组,各组数据分别进行用户网络拓扑识别;根据电压数据之间的相关性,计算各用户之间的皮尔逊相关系数rx,y;
(5)将用户之间的皮尔逊相关性系数作为样本,进行k-medoids聚类,得到不同k值下的聚类簇,形成簇队列,进行用户相邻性分析;
(6)用簇队列中低层次簇的“并”表示高层次簇,通过用户相邻性分析确定“并”簇用户之间的相邻性,结合皮尔逊相关系数,形成相邻用户表;
(7)结合各个原始数据组的相邻用户表,采用信息融合策略,将不同组的相邻用户表合并为一张台区用户网络拓扑图。
进一步的,步骤(4)中电压数据之间的相关性用皮尔逊相关系数rx,y反应;电气距离越近的用户,电压变化的相关性越强,rx,y越大;电气距离较远的用户,电压变化的相关性较弱,rx,y越小。
进一步的,所述k-medoids聚类算法根据用户电压数据之间的相关性,通过聚类方式对带分叉线路的用户负荷进行网络拓扑识别;k-medoids聚类算法随机选取k个数据对象作为初始的聚类中心,并将剩余数据对象分配到与其最近的中心点所在簇,用簇内的某个非代表对象替代代表对象,计算相应的代价函数衡量聚类质量。
进一步的,所述用户相邻性分析,通过将不同聚类簇情况下由k-medoids方法得到的簇形成簇队列,用低层次簇的并表示高层次簇,采用自下而上的分析方法确认并簇用户之间的相邻性,从而形成不同原始数据组的相邻用户表,并采用信息融合策略。
进一步的,所述信息融合策略是将负荷相同的或者负荷变化在±0.01kw以下的多个样本压缩成一个样本,按样本采集时间的次序把样本分成n个研究组并得到n个用户相邻表;按照出勤队列次序进行信息融合,将不同组的相邻用户表合并成一张台区用户网络拓扑图。
与现有技术相比,本发明的技术方案所带来的有益效果是:
1.利用皮尔逊相关系数准确合理地描述台区用户电压数据的相关性,提高了使用k-medoids聚类算法判断台区网络拓扑的可靠性和准确性。
2.k-medoids聚类算法根据皮尔逊相关系数rx,y计算两个用户电压数据之间的距离,这种方法对异常数据和噪声数据不敏感,具有较强的鲁棒性,可有效减小脏数据的影响。
3.在对聚类结果进行用户相邻性分析后采用信息融合策略,能够有效滤除干扰信号,经过局部修正的台区用户网络图更加可信。
附图说明
图1是本发明的用电信息采集系统结构图;
图2是本发明的负荷分配示意图;
图3是本发明中涉及的k-medoids聚类算法的流程示意图;
具体实施方式
下面结合附图对本发明作进一步的描述。
一种用于低压台区的用户网络拓扑识别装置,如图1所示,包括采集器、集中器、主站;采集器用于采集多个或单个电能表的电能信息,并可与集中器交换数据的设备;集中器用于收集各采集器或电能表的数据,并进行台区拓扑识别所需的数据信息的储存和处理;通过获取主站发出的台区网络拓扑识别信号,并将储存的台区用户数据上传至主站;主站用于低压台区的用户网络拓扑识别算法的实现,生成最终的台区网络拓扑图;向集中器发送拓扑识别指令、获取集中器上传的数据信息。主站数据信息处理采用k-medoids聚类算法,通过计算各用户电压数据序列之间的皮尔逊相关系数,并对其进行聚类分析的方法进行用户相邻性分析、确定台区拓扑位置。该装置基于用户的电压数据相关性,可将各个用户分类来确定其台区归属关系,并得到网络拓扑图。
在本实施例中,用于低压台区的用户网络拓扑识别方法,基于上述用户网络拓扑识别装置,包括以下步骤:
(1)电能表或智能电表用于定时采集用户电量数据和电能信息;
(2)电表将数据和信息输出至各自对应的数据采集器,最终由集中器收集台区的所有采集器和电表数据,从而得到台区用户网络拓扑识别的原始数据;
(3)需要获取台区网络拓扑时,由主站向集中器发送拓扑识别指令,集中器将储存的用户数据上传至主站;
(4)主站对上传的电压数据进行分组,每12h的电压数据为一组,分别进行用户网络拓扑识别。根据电压数据之间的相关性,计算各用户之间的皮尔逊相关系数rx,y;电气距离越近的用户,电压变化的相关性越强,rx,y越大;电气距离较远的用户,电压变化的相关性较弱,rx,y越小。
(5)将用户之间的皮尔逊相关性系数作为样本,进行k-medoids聚类,得到不同k值下的聚类簇,形成簇队列,进行用户相邻性分析;
(6)用簇队列中较低层次簇的“并”表示较高层次簇,通过用户相邻性分析研究得到“并”簇用户之间的相邻性,结合皮尔逊相关系数,形成相邻用户表;其中用户相邻性分析是将不同聚类簇情况下由k-medoids方法得到的簇形成簇队列,用较低层次簇的并表示较高层次簇,采用自下而上的分析方法研究并簇用户之间的相邻性,从而形成不同原始数据组的相邻用户表,并采用信息融合策略。
(7)结合各个原始数据组的相邻用户表,采用信息融合策略,将不同组的相邻用户表合并为一张可信的台区用户网络拓扑图。
在本实施例中,k-medoids聚类算法根据用户电压数据相关性,通过聚类方式对带分叉线路的用户负荷进行网络拓扑识别。k-medoids聚类算法随机选取k个数据对象作为初始的聚类中心,并将剩余数据对象分配到与其最近的中心点所在簇。用簇内的某个非代表对象替代代表对象,计算相应的代价函数衡量聚类质量。
在本实施例中,信息融合策略是将负荷相同的或者负荷变化不大的多个样本压缩成一个样本,按样本采集时间的次序把样本分成n个研究组并得到n个用户相邻表。按照出勤队列次序进行信息融合,将不同组的相邻用户表合并成一张比较可信的台区用户网络拓扑图。
下面分别对本发明的功能和作用作进一步说明:
(1)图2为某线路用户的负荷分布示意图,为方便分析各用户的电压数据相关性,假定线路电抗远大于线路电阻,各节点的实际电压很接近额定电压un,用户i、j之间的电压差
n是总用户数,rk、xk分别为线路k的电阻和电抗,ps、qs分别为s节点的有功功率和无功功率,un为线路额定电压。
设δps(te,tf)、δqs(te,tf)为ps、qs在te、tf两时刻的有功增量和无功增量,用户i、j之间的电压差增量
用户负荷之间电压数据的相关性强弱在数学上用皮尔逊相关系数rx,y反应:
其中,ux,i、uy,i、
考虑到低压台区阻抗的大小及无功功率、有功功率的实际变化情况,分析可知电气距离越近的用户,电压变化的相关性越强,rx,y越大;电气距离较远的用户,电压变化的相关性较弱,rx,y越小。
(2)图3为k-medoids聚类算法流程图,k-medoids聚类算法随机选取k个数据对象作为初始的聚类中心,并将剩余数据对象分配到与其最近的中心点所在簇。用簇内的某个非代表对象替代代表对象,计算相应的代价函数衡量聚类质量。
其中,ci、mi是原来的簇和簇代表,di、ni是新的簇和簇代表。
如果chj大于0,则用非代表对象替代代表对象,直到所有簇内的非代表不能够替代代表对象为止。
根据皮尔逊相关系数rx,y计算用户x、y电压数据之间的距离。
|x-y|=1-|rx,y|
(3)用户相邻性分析,把由k-medoids聚类算法得到的所有簇排成一个有方向的簇队列,用户数目从少到多,用户数相同时按用户的编号排列。用ap,i表示包含有p个用户簇中的第i个簇,称a1,i为最低层次簇,an,i为最高层次簇。将ap,i分解成多个较低层次簇的组合,即用并来表达较高层次簇。通过按簇队列的正方向形成ap,i子簇,按簇队列的反方向挖掘ap,i子簇间用户相邻信息,避免出现环网或孤岛现象。
(4)信息融合策略,将n个用户相邻表中的记录按照记录出现的次数从多到少排列,次数相同时按照记录的平均皮尔逊相关系数排列,形成记录出勤队列。将记录出勤队列分成两个部分,全勤记录组和非全勤记录组。依次考察非全勤记录组中的每个成员,如果在全勤记录组中寻找不到该非全勤记录的两用户之间的路径,则把该非全勤记录变成全勤记录后加入到全勤记录组中。
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!