一种基于群智能融合模型的电网暂态频率特征预测方法
1.本发明属于电力系统趋势预测技术领域,涉及基于深度学习的电网安全稳定分析方法,具体涉及一种基于群智能融合模型的电网暂态频率特征预测方法。
背景技术:
2.电力系统频率是表征电能质量与系统运行状态的关键指标,频率稳定由系统有功发电与负荷的平衡关系决定。当电力系统遭受严重扰动而产生大量功率缺额时,频率会在短时间内急剧下降,如果偏移到正常运行范围之外,则可能会引起发电机组解列、部分线路负荷切除等故障,严重的甚至会导致电力系统发生频率崩溃。因此,在系统受到扰动后对电网暂态频率态势进行高精度预测,对保证受端电网频率稳定具有重要意义。
3.传统的电力系统暂态特征预测方法主要有以下两类方式:基于因果理论的时域仿真法、平均系统频率模型(asf)、系统频率响应模型(sfr)和基于统计理论的机器学习方法等。使用机器学习进行频率特征预测可以完全偏离物理模型层面去挖掘历史数据输入输出之间的关联关系。理论上,如果样本数量充足和采样合理,机器学习方法可精确拟合各种非线性环节的响应特性,为电力系统频率分析提供了新思路。目前现有进行暂态特征预测的机器学习方法大多基于单一模型,然而单一模型在时效要求统一的前提下,通常预测精度不足。并且,机器学习模型自身由于结构可调节的范围广泛,无法直接确定其内部结构,结构过大会导致训练过慢以及过拟合;结构过小无法达到要求的精度。因此,针对以上问题,设计一种能够组合多种模型进行暂态特征预测,并且将组合后的模型结构调整至最优的预测方法,具有重大的意义。
技术实现要素:
4.针对现有利用机器学习进行暂态频率特征预测方法存在的问题,本发明提供了一种基于群智能融合模型的电网暂态频率特征预测方法。本发明首先使用stacking融合机制将梯度提升决策树模型(gbdt)与长短期记忆模型(lstm)分层对模型进行集成;其次,通过麻雀搜索算法对模型超参进行优化,实现兼顾准确性与时效性的预测方法。
5.本发明的技术方案:
6.一种基于群智能融合模型的电网暂态频率特征预测方法,包括以下步骤:
7.步骤1:构建gbdt-lstm融合模型的训练样本集
8.步骤1.1:采集电力系统所有原动机-调速器在受到扰动后的系统频率动态,包括被控变量最低频率δωm、最低频率时刻tz;控制变量包括容量基准值sb、系统总容量sn、机械功率增益系数km、扰动功率pd、发电机的总惯性时间常数h、调速器的频率调差系数r、发电机的等效阻尼系数d、原动机的再热时间常数tr、汽轮机的高压杠功率系数fh;
9.步骤1.2:对步骤1.1采集的电力系统运行参数进行数据处理,针对异常值即离群点以及重复值进行删除;
10.步骤1.3:将经过数据处理后的电力系统运行参数中的扰动功率pd、发电机的总惯
性时间常数h、调速器的频率调差系数r、发电机的等效阻尼系数d、原动机的再热时间常数tr、汽轮机的高压杠功率系数fh作为gbdt-lstm融合模型的输入参数;受到扰动后的系统频率动态指标,最低频率δωm、最低频率时刻tz作为gbdt-lstm融合模型以及群智能融合模型的目标输出;
11.构建gbdt-lstm融合模型训练样本集:
12.x=[pd,h,r,d,tr,fh]
[0013]
y=[δωm,tz]
[0014]
h=[x,y]
[0015]
其中,x是gbdt-lstm融合模型的输入参数,y是gbdt-lstm融合模型以及群智能融合模型的目标输出,h为gbdt-lstm融合模型的训练样本集;
[0016]
步骤1.4:对gbdt-lstm融合模型的训练样本集进行归一化处理:
[0017][0018]
其中,h
norm
,h
min
和h
max
分别为gbdt-lstm融合模型的训练样本集h数据归一化后的值、最小值和最大值。
[0019]
步骤2:训练gbdt-lstm融合模型
[0020]
步骤2.1:将步骤1得到的训练样本集h,67%作为训练样本h
train
,33%作为测试样本h
test
。
[0021]
步骤2.2:初始化gbdt模型参数以实例化估计器对象:迭代次数、基回归估计器的最大深度、基回归树在分裂时的最小样本数或占比、学习率、损失函数。损失函数使用平滑平均绝对误差(huber),公式如下:
[0022][0023]
其中,i表示损失函数huber,r表示真实值,为预测值,σ为huber损失函数对应的参数。
[0024]
步骤2.3:将训练数据h
train
输入到gbdt模型中进行建模学习,得到一个初步训练好的gbdt模型。用测试数据h
test
进行检测,得到预测结果,选取平均绝对误差mae、平均绝对误差百分比mape和均方误差mse对测试结果进行评估。
[0025]
步骤2.4:根据stacking算法的思想,将gbdt模型的输出与原训练样本集的输入参数x共同作为lstm模型的输入融合特征x
lstm
。
[0026]
步骤2.5:初始化lstm参数:学习率、迭代次数、第一层隐藏层神经元数量和第二层隐藏层神经元数量。
[0027]
步骤2.6:构建lstm模型,选取均方误差mse作为损失函数,adam优化器对网络参数进行更新,加快模型收敛速度。
[0028]
adam更新公式如下:
[0029]
[0030]
其中,w表示网络参数,c表示次数,α表示学习率,为mc的纠正,为vc的纠正,ε为维持数值稳定而添加的常数。
[0031][0032][0033]
β1和β2是常数,用来控制指数衰减;mc是梯度的指数移动平均值;vc是平方梯度。mc和vc的更新如下:
[0034]
mc=β1*m
c-1
+(1-β1)*gc[0035][0036]
其中gc为一阶导。
[0037]
步骤2.7:将步骤2.4得到的融合特征x
lstm
输入到lstm模型中进行建模学习,计算模型的误差。当误差满足给定的精度要求时,结束训练,保存lstm模型的权重矩阵和偏置参数矩阵;如果误差不满足给定的精度要求,继续进行迭代训练,直到满足精度要求或者达到指定的迭代次数。
[0038]
步骤2.8:基于测试样本,对当前训练好的gbdt-lstm融合模型进行检验,计算测试误差。
[0039]
步骤3:使用麻雀搜索算法优化gbdt-lstm融合模型超参
[0040]
步骤3.1:初始化麻雀搜索算法参数,设种群中麻雀数量为n,由n只麻雀组成的种群为s,第i只麻雀的适应度值为f
si
,所有麻雀适应度平均值为所有麻雀的适应度值为fs,设平均绝对误差mae为适应度值。
[0041]
s=[s
1 s2···sn-1 sn]
[0042][0043]
在每次迭代的过程中,种群中发现者麻雀的位置更新规则如下:
[0044][0045]
其中,si表示第i只麻雀;t代表当前迭代数;iter
max
是一个常数,表示最大的迭代次数;η∈(0,1]是一个随机数;r2(r2∈[0,1])和st(st∈[0.5,1])分别表示是预警值和安全值;q是服从正态分布的随机数;l表示一个矩阵,其中该矩阵内每个元素全部为1。
[0046]
在每次迭代的过程中,种群中加入者麻雀的位置更新规则如下:
[0047][0048]
其中,s
p
是目前发现者所占据的最优位置;s
worst
则表示当前全局最差的位置;a表
示一个矩阵,其中每个元素随机赋值为1或-1,并且a
+
=a
t
(aa
t
)-1
。当时,这表明,适应度值较低的第i个加入者没有获得食物,需要向其他地方觅食,以获得更高的适应度值。
[0049]
在迭代寻优的过程中,若意识到危险的麻雀占总数的10%-20%,则对全体麻雀影响如下:
[0050][0051]
其中,s
best
是当前的全局最优位置;ξ作为步长控制参数,是服从均值为0,方差为1的正态分布的随机数;k∈[-1,1]是一个随机数;f
si
则是当前麻雀个体的适应度值;fg和fw分别是当前最佳和最差的适应度值;π是最小的常数,以避免分母出现零。
[0052]
通过以上更新位置规则,在每次迭代中找寻最优适应度值,得到群智能融合模型最优超参。
[0053]
步骤3.2:根据麻雀搜索算法得出的最优超参,优化gbdt-lstm融合模型结构,得到群智能融合模型。使用优化后的群智能融合模型对电网暂态特征进行预测。
[0054]
本发明的有益效果:本发明通过设计融合模型以及使用群智能优化算法-麻雀搜索算法进行模型结构优化,构建了基于群智能融合模型的电网暂态特征预测方法,有效改善了单一机器学习模型不能兼顾时效性与准确性的缺点;同时,使用麻雀搜索算法对融合模型结构进行调整,使网络结构更加精简,提高了运行速度和控制精度。
附图说明
[0055]
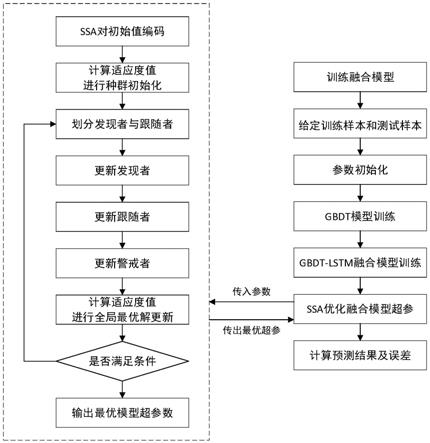
图1为基于群智能融合模型的电网暂态频率特征预测方法流程图。
[0056]
图2为所采用的群智能融合模型结构示意图。
[0057]
图3(a)、图3(b)、图3(c)、图3(d)分别为在具体实施步骤3.1和3.2中设置的参数区间内对融合模型使用麻雀搜索算法进行超参寻优的过程中,学习率、迭代次数、第一层隐藏层神经元数量、第二层隐藏层神经元数量的变化曲线。
[0058]
图4为在具体实施步骤3.1和3.2中设置的参数区间内对融合模型使用麻雀搜索算法进行超参寻优过程中的误差变化曲线。
[0059]
图5(a)为使用单一机器学习模型lstm,学习率为0.001、迭代次数为100、第一层隐藏层神经元数量为64和第二层隐藏层神经元数量为64,每批数据量为10的情况下,对样本集进行预测效果。
[0060]
图5(b)为使用融合模型gbdt-lstm,学习率为0.01、迭代次数为100、第一层隐藏层神经元数量为64和第二层隐藏层神经元数量为64,每批数据量为10的情况下,对样本集进行预测效果。
[0061]
图5(c)为使用麻雀搜索算法优化超参后融合模型ssa-gbdt-lstm,学习率为0.0041、迭代次数为149、第一层隐藏层神经元数量为68和第二层隐藏层神经元数量为11,每批数据量为10的情况下,对样本集进行预测效果。
[0062]
图6为单一模型lstm、融合模型gbdt、群智能融合模型ssa-gbdt-lstm三种模型样
本集预测评估结果。
具体实施方式
[0063]
下面结合附图以及技术方案对本发明实例做进一步的详细说明。
[0064]
如图1所示,一种基于群智能融合模型的电网暂态频率特征预测方法,具体步骤如下:
[0065]
步骤1:构建gbdt-lstm融合模型的训练样本集。
[0066]
步骤1.1:采集电力系统所有原动机-调速器在受到扰动后的系统频率动态,包括被控变量最低频率δωm、最低频率时刻tz,控制变量包括容量基准值sb、系统总容量sn、机械功率增益系数km、扰动功率pd、发电机的总惯性时间常数h、调速器的频率调差系数r、发电机的等效阻尼系数d、原动机的再热时间常数tr、汽轮机的高压杠功率系数fh。为模拟不同扰动情况,扰动功率pd值服从[0.5,1.5]均匀分布;为描述电力系统不同运行工况,系统其他重要参数取参数的经典范围,发电机的总惯性时间常数h值服从[3,9]均匀分布,调速器的频率调差系数r值服从[0.04,0.1]均匀分布,发电机的等效阻尼系数d值服从[0,2]均匀分布,原动机的再热时间常数tr值服从[6,14]均匀分布,汽轮机的高压杠功率系数fh值服从[0.15,0.4]均匀分布。
[0067]
步骤1.2:对步骤1.1采集的电力系统运行参数进行数据处理,针对异常值即离群点以及重复值进行删除。
[0068]
步骤1.3:将经过数据处理后的电力系统运行参数中的扰动功率pd、发电机的总惯性时间常数h、调速器的频率调差系数r、发电机的等效阻尼系数d、原动机的再热时间常数tr、汽轮机的高压杠功率系数fh作为gbdt-lstm融合模型的输入参数;受到扰动后的系统频率动态,最低频率δωm、最低频率时刻tz作为gbdt-lstm融合模型以及群智能融合模型的目标输出。构建gbdt-lstm融合模型训练样本集:
[0069]
x=[pd,h,r,d,tr,fh]
[0070]
y=[δωm,tz]
[0071]
h=[x,y]
[0072]
其中,x是gbdt-lstm融合模型的输入参数,y是gbdt-lstm融合模型以及群智能融合模型的目标输出,h为gbdt-lstm融合模型的训练样本集。
[0073]
步骤1.4:对gbdt-lstm融合模型的训练样本集进行归一化处理:
[0074][0075]
其中,h
norm
,h
min
和h
max
分别为gbdt-lstm融合模型的训练样本集h数据归一化后的值、最小值和最大值。
[0076]
步骤2:训练gbdt-lstm融合模型。
[0077]
步骤2.1:将步骤1得到的训练样本集h,67%作为训练样本h
train
,33%作为测试样本h
test
。
[0078]
步骤2.2:初始化gbdt模型参数。
[0079]
迭代次数为285、基回归估计器的最大深度为4、基回归树在分裂时的最小样本数或占比为2、学习率为0.71、损失函数和当损失函数选择为'huber'时对应的σ为0.9。
[0080]
步骤2.3:将训练数据h
train
输入到gbdt模型中进行建模学习,得到一个初步训练好的gbdt模型。用测试数据h
test
进行检测,得到预测结果,选取平均绝对误差mae、平均绝对误差百分比mape和均方误差mse对测试结果进行评估,测试结果mse为0.00029,mae为0.0127,mape为0.05652。
[0081]
步骤2.4:根据stacking算法的思想,将gbdt模型的输出与原训练样本集的输入参数x共同作为lstm模型的输入融合特征x
lstm
。
[0082]
步骤2.5:初始化lstm参数。
[0083]
学习率为0.01、迭代次数为150、第一层隐藏层神经元数量为64和第二层隐藏层神经元数量为64,每批数据量为10。
[0084]
步骤2.6:构建lstm模型,选取均方误差mse作为损失函数,adam优化器对网络参数进行更新,加快模型收敛速度。
[0085]
步骤2.7:将融合特征x
lstm
输入到lstm模型中进行建模学习,计算模型的误差。当误差满足给定的精度要求时,结束训练,保存lstm模型的权重矩阵和偏置参数矩阵;如果误差不满足给定的精度要求,继续进行迭代训练,直到满足精度要求或者达到指定的迭代次数。
[0086]
步骤2.8:基于测试样本,对当前训练好的gbdt-lstm融合模型进行检验,计算测试误差。选取平均绝对误差mae和平均绝对误差百分比mape对测试结果进行评价,测试误差mse为1.443306e-05,mae为0.0023,mape为0.00088。
[0087]
步骤3:使用麻雀搜索算法优化gbdt-lstm融合模型超参。
[0088]
步骤3.1:对麻雀搜索算法进行参数初始化,种群大小设为n=100,最大迭代次数为8,安全阈值st=0.8,发现者占种群规模的20%,意识到危险的麻雀数量sd=5。
[0089]
步骤3.2:设置麻雀搜索算法寻优参数区间,gbdt-lstm融合模型学习率为[0.001,0.02]、迭代次数为[100,200]、第一层隐藏层神经元数量为[1,100]和第二层隐藏层神经元数量为[1,100]。
[0090]
图3(a)、图3(b)、图3(c)、图3(d)为在上述设置的参数区间内对融合模型使用麻雀搜索算法进行超参寻优的过程中,学习率、迭代次数、第一层隐藏层神经元数量、第二层隐藏层神经元数量的变化曲线,得出群智能融合模型最优参数,学习率为0.0041、迭代次数为149、第一层隐藏层神经元数量为68和第二层隐藏层神经元数量为11。
[0091]
相比于原有融合模型,使用麻雀搜索算法进行超参寻优后的群智能融合模型,迭代次数和隐藏层神经元数量更少,结构更精简,模型预测推理速度更快,预测所需时间更少。
[0092]
图4为在上述设置的参数区间内对融合模型使用麻雀搜索算法进行超参寻优的过程中的误差变化曲线。
[0093]
图5(a)为使用单一机器学习模型lstm,学习率为0.001、迭代次数为100、第一层隐藏层神经元数量为64和第二层隐藏层神经元数量为64,每批数据量为10的情况下,对样本集进行预测效果。
[0094]
图5(b)为使用融合模型gbdt-lstm,学习率为0.01、迭代次数为100、第一层隐藏层神经元数量为64和第二层隐藏层神经元数量为64,每批数据量为10的情况下,对样本集进行预测效果。
[0095]
图5(c)为使用麻雀搜索算法优化超参后群智能融合模型ssa-gbdt-lstm,学习率为0.0041、迭代次数为149、第一层隐藏层神经元数量为68和第二层隐藏层神经元数量为11,每批数据量为10的情况下,对样本集进行预测效果。
[0096]
图6为单一模型lstm、融合模型gbdt、群智能融合模型ssa-gbdt-lstm三种模型样本集预测评估结果,群智能融合模型测试误差mse为5.296956e-06,mae为0.0016,mape为0.00066。
[0097]
由结果可知融合模型gbdt-lstm比单一模型lstm预测准确度提高0.04%,群智能融合模型ssa-gbdt-lstm比融合模型gbdt-lstm预测准确度提高0.07%。
[0098]
综上可见,在电网频率暂态特征预测中,本发明运用基于gbdt和lstm的融合模型gbdt-lstm,并且使用麻雀搜索算法对融合模型进行超参寻优的特征预测方法,实现了兼顾准确性与时效性的预测方法,使得模型结构更加精简,提高了预测精度以及预测推理速度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1