新能源汽车电机热管控方法与流程
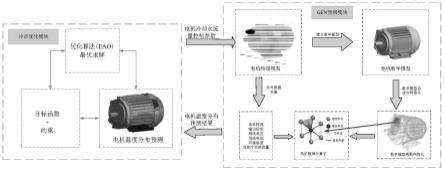
1.本发明属于新能源汽车电机控制技术领域,具体的为一种新能源汽车电机热管控方法。
背景技术:
2.近年来,我国大力推进新能源汽车的发展,新能源汽车保有量的占比越来越高。驱动电机作为新能源汽车的三大核心部件之一,对整车性能起着至关重要的作用,新能源汽车依靠一个或多个驱动电机来驱动车辆行驶,将驱动电池的电能有效转化为机械能。目前,新能源汽车驱动电机大多采用永磁同步电机(permanent magnet synchronous motors,pmsm),因为永磁同步电机功率和转矩密度高、效率高、过载能力强、性价比高、噪声低,能良好地适配整车性能。如果要实现较高的传动效率,必须保证电机各部件尤其是转子绕组和定子具有良好的散热。但由于轻量化和高功率密度的要求,使得电机在长时间或过载运行时会产生大量的热量,温度急剧升高,而如果温度持续升高,则会对电机产生永久性损伤。为防止新能源汽车在行驶过程中由于温度过高造成电机永磁体产生退磁现象,影响到电机及其控制器的寿命和整车安全性,需要对驱动电机进行实时的热管控。
3.对驱动电机进行热管控首先需要完成对pmsm的温度预测,在pmsm的内部安装温度传感器,是获得部件温度最直接的方法,但这种方法对传感器的安装位置、数量以及精度等都有较高的要求,成本也会随着增加。因此在电机在工作过程中,需要使用间接预测方法来预测电机关键部件的温度,目前的间接预测方法主要有:磁通观察法、信号注入法、等效热网络法。
4.(1)磁通观察法通过磁通观察器得到磁通的变化,并建立一个精确的参数化电机温度模型,以得到电机转子永磁体的温度。但是这种方法对观测器件的精度具有较高要求,对于测量误差十分敏感且不适用于电机静止和低速的工况。
5.(2)信号注入法利用饱和效应和高频阻抗确定磁体的温度。然而,这种方法需要注入电压信号,这会增加电流谐波,电机也会因此产生额外的损耗。
6.(3)等效热网络法将电机中的传热过程抽象出来以建立等效热网络,其中集中参数热网络模型应用最为广泛,其对电机结构的划分更为细致。但是该方法需要电机专业的背景知识,了解电机内部的几何结构与参数,这限制了该方法的应用。
7.由此可知,这些传统的预测方法需要电机相关的专业背景知识以及相关参数选择经验,且不适合汽车行程过程中的实时预测。
技术实现要素:
8.有鉴于此,本发明的目的在于提供一种新能源汽车电机热管控方法,利用数据驱动的方式,得到新能源汽车行驶过程中的电机温度分布预测结果;根据该预测结果对对冷却水阀门流量进行控制,以控制电机的温度。
9.为达到上述目的,本发明提供如下技术方案:
10.一种新能源汽车电机热管控方法,包括如下步骤:
11.步骤一:采集数据:在汽车行驶过程中,实时采集电机关于机械、电气和温度的时间序列数据;
12.步骤二:将实时采集的时间序列数据输入到电机温度预测模型中,得到电机温度分布预测结果;
13.步骤三:根据电机温度分布预测结果求解当前工况下的最佳冷却水流量,使电机的最高温度保持在设定范围以内。
14.进一步,所述步骤二中,电机温度预测模型的构建方法为:
15.21)数据采集:采集电机在不同工况下的时序数据,时序数据中包括电机的转速、输出扭矩、母线电压、母线电流以及环境温度和冷却液的流量、温度;
16.22)数据预处理:对采集的时序数据进行缺失值填充、异常值剔除和数值标准化处理;
17.23)将经预处理后的时序数据分为训练集和测试集;
18.24)训练模型:构建深度学习模型,以训练集训练深度学习模型以更新模型参数,以损失函数为目标函数以判断是否达到模型训练的终止条件;当达到模型训练终止条件后,得到预测模型;
19.25)将测试集输入预测模型中并得到电机温度分布的预测结果;判断预测结果是否达到预设的评价指标:若是,则以该预测模型构建得到电机温度预测模型;若否,则执行步骤24)。
20.进一步,所述深度学习模型采用gen(graph effect network,图影响力神经网络)模型,所述gen模型为在gat(graph attention network,图注意力神经网络)模型中引入微分算子层后得到,所述微分算子层用于对一个节点的不同相邻节点分配不同的权重以识别出各相邻节点对于该节点的影响程度;
21.所述微分算子层采用拉普拉斯算子来表示不同相邻节点对于某节点的影响程度,并定义其为热扩散微分算子;令节点i与其任意相邻节点j和k之间连线组成三角形为δijk,则节点i处的热扩散微分算子为:
[0022][0023]
其中,(δt)i为节点i的热扩散微分算子,表示任意一个与节点i相连的节点j变化而给节点i带来的增益;ti表示函数t在节点i处的函数值;tj表示函数t在节点j处的函数值;w
ij
表示节点i与节点j之间的节点边e
ij
的边权重;ai表示节点i的节点权重;且:
[0024][0025][0026]
ai=∑aijk
[0027]
其中,l
ij
表示节点i与节点j之间相连的节点边长度,同理l
ik
和l
jk
分别表示节点k与节点i和节点j之间相连的节点边长度;aijk表示节点i在三角形δijk中的权重;sijk表示三角形δijk的面积;
[0028]
根据图网络节点相连关系构造一个以边权重w
ij
为元素的n
×
n的矩阵w,若节点i与节点j不相邻,则节点i与节点j之间不存在节点边,矩阵中对应位置的元素w
ij
=0;构造一个以节点权重ai为元素的对角矩阵a;构造一个以ti为列向量的矩阵t;则所有节点的热扩散微分算子可以表示为:
[0029]
δt=a-1
(d-w)t
[0030]
其中,δt为m阶矩阵,表示所有节点的热扩散微分算子,m为所有节点的数量;d表示所有节点组成的图网络的度矩阵。
[0031]
进一步,采用线性离散热扩散算子作为基元算子δt,通过n阶切比雪夫多项式将基元算子δt构建成非线性离散微分算子进行逼近,即:
[0032][0033]
其中,θ∈rm为切比雪夫多项式的系数向量。当t0(x)=1,t1(x)=x且k>1时,切比雪夫多项式的递归定义为tk(x)=2xt
k-1
(x)-t
k-2
(x),此时m阶切比雪夫多项式系数向量θ为gen网络的待学习优化参数;
[0034]
向gen模型中输入电机在t时刻实时采集的时间序列数据f
t
和,得到t时刻节点i的温度预测值为:
[0035][0036]
其中,x
it
表示预测得到的t时刻节点i的温度值;表示t-1时刻节点i的温度值;表示由gen模型预测得到t-1时刻到t时刻的温度变化量预测值。
[0037]
进一步,所述步骤22)中,采用归一化方法进行数值标准化处理:
[0038][0039]
其中,x表示原属性值;x
min
表示样本集中该属性的最小数值;x
max
表示样本集中该属性的最大数值,x
normal
表示归一化处理后的数值。
[0040]
进一步,所述步骤24)中,gen模型的训练方法为:
[0041]
241)随机初始化模型参数;
[0042]
242)向gen模型中输入训练集,以利adam算法对gen模型的参数进行迭代优化;
[0043]
243)以均方根误差为损失函数,用于衡量预测值与真实值之间的偏差,由下式计算:
[0044][0045]
其中,h(xi)表示预测值;yi表示真实值;m表示节点的数量;
[0046]
244)判断损失函数的值是否小于设定阈值,若是,则终止迭代,得到预测模型;若否,则循环执行步骤242)。
[0047]
进一步,所述步骤三中,求解最佳冷却水流量的优化问题的一般数学表达式为:
[0048]
minimize max(f(x1,x2,x3,x4,x5,x6,x7))
[0049]
subject to x
7l
<xi<x
7h
[0050]
其中,x1,x2,x3,x4,x5,x6,x7分别为电机转速、输出扭矩、母线电压、母线电流、环境温度、当前冷却液温度和冷却液流量;f(x1,x2,x3,x4,x5,x6,x7)表示电机温度预测模型中的
映射函数;x
7l
和x
7h
分别表示x7取值的上限和下限;
[0051]
在行驶过程中,变量x1,x2,x3,x4,x5,x6均为行驶状态下的实时状态数据,在优化过程中视为固定值,通过迭代优化得到当前行驶状态下最佳的冷却液流量以控制电机的温度。
[0052]
进一步,采用阿奎拉鹰算法对最佳冷却水流量的优化问题进行求解,阿奎拉鹰算法包括扩大探索,缩小探索,扩大开发和缩小开发这四个阶段:
[0053]
(1)扩大探索:
[0054]
阿奎拉鹰通过识别猎物区域,采用垂直高飞的方式选择最佳狩猎区域,这种行为表示为:
[0055]
s1(t+1)=s
best
(t)
×
(1-t/t)+(sm(t)-s
best
(t)*rand)
[0056]
其中,t为当前代数,t为总迭代次数,s1(t+1)表示扩大探索阶段产生的下一代的值,s
best
(t)表示当前代的最佳值,rand为[0,1]之间的随机值,sm(t)表示第t代解的位置均值,且:
[0057][0058]
其中,n为候选解的个数,dim为解的维数;
[0059]
(2)缩小探索:
[0060]
当在高空发现猎物区域时,阿奎拉鹰在目标猎物上方盘旋,然后发动攻击,这种行为表示为:
[0061]
s2(t+1)=s
best
(t)
×
levy(d)+sr(t)+(y-x)*rand
[0062]
其中,s2(t+1)表示缩小探索阶段产生的下一代的值;sr(t)为第t次迭代中的随机解;levy(d)为leay飞行函数,且:
[0063][0064]
其中,s为常数,β为常数;u和v为[0,1]之间的随机值,σ由下式计算得到:
[0065][0066]
x和y表示搜索过程的螺旋形状,计算如下:
[0067]
x=r
×
sin(θ)
[0068]
y=r
×
cos(θ)
[0069]
r=r1+u+d1[0070]
θ=-ω
×
d1+θ1[0071][0072]
其中,r1取1到20之间的一个值来确定搜索周期的数量;u为常数;d1为搜索空间d之间的整数;ω为常数。
[0073]
(3)扩大开发:
[0074]
当准确地确定了猎物的区域,并且阿奎拉鹰已经准备好着陆和攻击时,会垂直下
降并进行攻击,这种行为表示为:
[0075]
s3(t+1)=(s
best
(t)-sm(t))
×
α-rand+((ub-lb)
×
rand+lb)
×
δ
[0076]
其中,s3(t+1)表示扩大开发阶段产生的下一代的值;α和δ开采调整参数;ub和lb表示问题的上下界;
[0077]
(4)缩小开发:
[0078]
当阿奎拉鹰接近猎物时,它会根据猎物的随机移动在陆地上攻击猎物,这种行为表示为:
[0079]
s4(t+1)=qf
×sbest
(t)-(g1×
s(t)
×
rand)-g2×
levy(d)+rand
×
g1[0080][0081]
g1=2
×
rand-1
[0082][0083]
其中,s4(t+1)表示缩小开发阶段产生的下一代的值。
[0084]
根据权利要求8所述的新能源汽车电机热管控方法,其特征在于:在阿奎拉鹰算法中引入全局最优个体变异策略,对全局最优个体s
best
进行高斯变异操作,生成新个体s’best
,如果新个体的适应度值优于s
best
,则用s’best
代替s
best
;高斯变异操作如下:
[0085]
s'
best
=s
best
·
(1+n(0,δ2))
[0086]
其中,δ2表示方差,且:
[0087][0088]
其中,δ
2max
和δ
2min
表示方差变化的最大最小值。
[0089]
根据权利要求10所述的新能源汽车电机热管控方法,其特征在于:在阿奎拉鹰算法中引入leader选择策略,用leader代替s
best
,使其有力摆脱局部最优,所提出的leader选择策略如下所示:
[0090][0091]
p为选择最优解的概率;
[0092]
在阿奎拉鹰算法中提出一种开发和探索的平衡策略,利用一个非线性函数moa(t),实现开发和探索之间的平衡:
[0093]
moa(t)=1+(-1*t3/t3)
[0094]
判断rand是否小于moa(t):
[0095]
若是,则判断p1是否小于0.5:若是,则运用扩大的收缩机制;若否,则实行缩小的搜索机制;
[0096]
若否,则判断p2是否小于0.5:若是,则运用扩大的开发机制;若否,则应用缩小的开发机制;
[0097]
其中,rand、p1和p2均为[0,1]之间的随机值。
[0098]
本发明的有益效果在于:
[0099]
本发明的新能源汽车电机热管控方法,实时采集汽车行驶过程中电机关于机械、电气和温度的时间序列数据,并将时间序列数据输入到电机温度预测模型,从而可以得到
电机温度分布预测结果,根据预测得到的电机温度分布预测结果来求解当前工况下的最佳冷却水流量,从而可将电机的最高温度控制在设定的范围内,使电机保持在安全的温度环境下运行,能够有效提高电机运行性能和使用寿命,特别的,对于永磁同步电机,可以防止由于温度过高造成的电机永磁体产生退磁现象。
附图说明
[0100]
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
[0101]
图1为本发明新能源汽车电机热管控方法的原理框图;
[0102]
图2为电机温度预测模型的构建方法流程图;
[0103]
图3为节点i热扩散微分算子计算示意图;
[0104]
图4为gen模型的输入、输出结构示意图;
[0105]
图5为eao算法探索开发平衡示意图。
具体实施方式
[0106]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好的理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0107]
本实施例的新能源汽车电机热管控方法,包括如下步骤:
[0108]
步骤一:采集数据:在汽车行驶过程中,实时采集电机关于机械、电气和温度的时间序列数据;具体的,本实施例的实时采集的时间序列数据包括电机转速、输出扭矩、母线电压、母线电流、环境温度、当前冷却液温度和冷却液流量。
[0109]
步骤二:将实时采集的时间序列数据输入到电机温度预测模型中,得到电机温度分布预测结果。具体的,如图2所示,本实施例的电机温度预测模型的构建方法为:
[0110]
21)数据采集:采集电机在不同工况下的时序数据,时序数据中包括电机的转速、输出扭矩、母线电压、母线电流以及环境温度和冷却液的流量、温度。具体方法为设定数据采集的频率,按照一定时间间隔采集电机在不同工况下的数据,并以时间序列数据的形式保存,且时序数据的时间基准同步。
[0111]
22)数据预处理:所采集的数据往往存在数据缺失、数据不一致、数据冗余、异常值等问题,对采集的时序数据进行缺失值填充、异常值剔除和数值标准化处理,将其整理为适应深度学习模型输入的形式。具体的,本实施例采用归一化方法进行数值标准化处理:
[0112][0113]
其中,x表示原属性值;x
min
表示样本集中该属性的最小数值;x
max
表示样本集中该属性的最大数值,x
normal
表示归一化处理后的数值。
[0114]
23)将经预处理后的时序数据分为训练集和测试集;
[0115]
24)训练模型:构建深度学习模型,以训练集训练深度学习模型以更新模型参数,以损失函数为目标函数以判断是否达到模型训练的终止条件;当达到模型训练终止条件后,得到预测模型;
[0116]
本实施例中,深度学习模型采用gen(graph effect network,图影响力神经网络)
模型,gen模型为在gat(graph attention network,图注意力神经网络)模型中引入微分算子层后得到,图注意力网络(graph attention network,gat)是图卷积神经网络(graph convolution network,gcn)的一种变体,用于解决gcn平等对待每一个相邻节点的问题。
[0117]
微分算子层用于对一个节点的不同相邻节点分配不同的权重以识别出各相邻节点对于该节点的影响程度。本实施例的微分算子层采用拉普拉斯算子来表示不同相邻节点对于某节点的影响程度,并定义其为热扩散微分算子。令节点i与其任意相邻节点j和k之间连线组成三角形为δijk,如图3所示,则节点i处的热扩散微分算子为:
[0118][0119]
其中,(δt)i为节点i的热扩散微分算子,表示任意一个与节点i相连的节点j变化而给节点i带来的增益;ti表示函数t在节点i处的函数值;tj表示函数t在节点j处的函数值;w
ij
表示节点i与节点j之间的节点边e
ij
的边权重;ai表示节点i的节点权重;且:
[0120][0121][0122]ai
=∑a
ijk
[0123]
其中,l
ij
表示节点i与节点j之间相连的节点边长度,同理l
ik
和l
jk
分别表示节点k与节点i和节点j之间相连的节点边长度;a
ijk
表示节点i在三角形δijk中的权重;s
ijk
表示三角形δijk的面积;
[0124]
根据图网络节点相连关系构造一个以边权重w
ij
为元素的n
×
n的矩阵w,若节点i与节点j不相邻,则节点i与节点j之间不存在节点边,矩阵中对应位置的元素w
ij
=0;构造一个以节点权重ai为元素的对角矩阵a;构造一个以ti为列向量的矩阵t;则所有节点的热扩散微分算子可以表示为:
[0125]
δt=a-1
(d-w)t
[0126]
其中,δt为m阶矩阵,表示所有节点的热扩散微分算子,m为所有节点的数量;d表示所有节点组成的图网络的度矩阵。
[0127]
进一步,采用线性离散热扩散算子作为基元算子δt,通过n阶切比雪夫多项式将基元算子δt构建成非线性离散微分算子进行逼近,即:
[0128][0129]
其中,θ∈rm为切比雪夫多项式的系数向量。当t0(x)=1,t1(x)=x且k>1时,切比雪夫多项式的递归定义为tk(x)=2xt
k-1
(x)-t
k-2
(x),此时m阶切比雪夫多项式系数向量θ为gen网络的待学习优化参数;
[0130]
如图4所示,向gen模型中输入电机在t时刻实时采集的时间序列数据f
t
和,得到t时刻节点i的温度预测值为:
[0131][0132]
其中,x
it
表示预测得到的t时刻节点i的温度值;表示t-1时刻节点i的温度值;表示由gen模型预测得到t-1时刻到t时刻的温度变化量预测值。
[0133]
同理,对于t+1时刻,重复上述过程,输入为t+1时刻的电机特征参数f
t+1
,输出为t至t+1时间段内的温度变化预测值y
it+1
。
[0134]
对于0时刻和1时刻,假设0时刻各点温度值均相同并指定为室温x0,节点i在0~1时间段内的温度变化预测值为y
i1
,则节点i在1时刻的温度值为
[0135]
具体的,gen模型的训练方法为:
[0136]
241)随机初始化模型参数;
[0137]
242)向gen模型中输入训练集,以利adam算法对gen模型的参数进行迭代优化。gen模型的输入层将训练集数据输入到gen循环神经网络层,gen循环神经网络层会对信息选择保留或遗忘,并在迭代中不断更新;gen循环神经网络层的输出作为隐藏层的输入,两个全连接隐藏层对输入的信息进行处理,隐藏层的输出作为输出层的输入,最后由输出层输出电机在各个节点处的温度预测值;
[0138]
243)以均方根误差为损失函数,用于衡量预测值与真实值之间的偏差,由下式计算:
[0139][0140]
其中,h(xi)表示预测值;yi表示真实值;m表示节点的数量;
[0141]
244)判断损失函数的值是否小于设定阈值,若是,则终止迭代,得到预测模型;若否,则循环执行步骤242)。
[0142]
25)将测试集输入预测模型中并得到电机温度分布的预测结果;判断预测结果是否达到预设的评价指标:若是,则以该预测模型构建得到电机温度预测模型;若否,则执行步骤24),重新训练模型。本实施例的评价指标采用均方误差(mean square error,mse),由下式计算:
[0143][0144]
其中,yi表示测试集中的真实值;表示测试集中的预测值;
[0145]
若均方误差小于设定阈值时,则表明预测结果达到评价指标要求,否则,表明预测结果未达到评价指标要求。
[0146]
步骤三:根据电机温度分布预测结果求解当前工况下的最佳冷却水流量,使电机的最高温度保持在设定范围以内。
[0147]
获得永磁同步电机温度分布预测结果后,需要结合预测模型、目标函数和约束条件进行最优求解,得到当前情况下的最佳冷却水流量,使得永磁同步电机的未来时间内的最高温度维持在较低水平。求解最佳冷却水流量的优化问题的一般数学表达式为:
[0148]
minimize max(f(x1,x2,x3,x4,x5,x6,x7))
[0149]
subject to x
7l
<xi<x
7h
[0150]
其中,x1,x2,x3,x4,x5,x6,x7分别为电机转速、输出扭矩、母线电压、母线电流、环境温度、当前冷却液温度和冷却液流量;f(x1,x2,x3,x4,x5,x6,x7)表示电机温度预测模型中的映射函数;x
7l
和x
7h
分别表示x7取值的上限和下限。
[0151]
在行驶过程中,变量x1,x2,x3,x4,x5,x6均为行驶状态下的实时状态数据,在优化过程中视为固定值,通过迭代优化得到当前行驶状态下最佳的冷却液流量以控制电机的温
度。
[0152]
本实施例采用增强的阿奎拉鹰算法(enhanced aquila optimizer,eao)对该优化问题进行快速准确地求解。
[0153]
类似于其他的元启发式算法,ao的优化过程开始于初始化一组随机的解决方案,并采用了四种方式对解进行更新:通过垂直下降的高飞方式选择搜索空间、通过轮廓飞行的短滑翔攻击进行搜索、采用低飞的方式进行攻击和猛扑过去抓住猎物。这四种更新方式分别对应于扩大探索,缩小探索,扩大开发和缩小开发这四个阶段。当t≤(2/3)t时,各有50%的概率选择扩大探索和缩小探索,否则,各有50%的概率选择扩大开发和缩小开发。
[0154]
(1)扩大探索:
[0155]
阿奎拉鹰通过识别猎物区域,采用垂直高飞的方式选择最佳狩猎区域,这种行为表示为:
[0156]
s1(t+1)=s
best
(t)
×
(1-t/t)+(sm(t)-s
best
(t)*rand)
[0157]
其中,t为当前代数,t为总迭代次数,s1(t+1)表示扩大探索阶段产生的下一代的值,s
best
(t)表示当前代的最佳值,rand为[0,1]之间的随机值,sm(t)表示第t代解的位置均值,且:
[0158][0159]
其中,n为候选解的个数,dim为解的维数;
[0160]
(2)缩小探索:
[0161]
当在高空发现猎物区域时,阿奎拉鹰在目标猎物上方盘旋,然后发动攻击,这种行为表示为:
[0162]
s2(t+1)=s
best
(t)
×
levy(d)+sr(t)+(y-x)*rand
[0163]
其中,s2(t+1)表示缩小探索阶段产生的下一代的值;sr(t)为第t次迭代中的随机解;levy(d)为leay飞行函数,且:
[0164][0165]
其中,s为常数,β为常数;u和v为[0,1]之间的随机值,σ由下式计算得到:
[0166][0167]
x和y表示搜索过程的螺旋形状,计算如下:
[0168]
x=r
×
sin(θ)
[0169]
y=r
×
cos(θ)
[0170]
r=r1+u+d1[0171]
θ=-ω
×
d1+θ1[0172][0173]
其中,r1取1到20之间的一个值来确定搜索周期的数量;u为常数;d1为搜索空间d之间的整数;ω为常数。
[0174]
(3)扩大开发:
[0175]
当准确地确定了猎物的区域,并且阿奎拉鹰已经准备好着陆和攻击时,会垂直下降并进行攻击,这种行为表示为:
[0176]
s3(t+1)=(s
best
(t)-sm(t))
×
α-rand+((ub-lb)
×
rand+lb)
×
δ
[0177]
其中,s3(t+1)表示扩大开发阶段产生的下一代的值;α和δ开采调整参数;ub和lb表示问题的上下界;
[0178]
(4)缩小开发:
[0179]
当阿奎拉鹰接近猎物时,它会根据猎物的随机移动在陆地上攻击猎物,这种行为表示为:
[0180]
s4(t+1)=qf
×sbest
(t)-(g1×
s(t)
×
rand)-g2×
levy(d)+rand
×
g1[0181][0182]
g1=2
×
rand-1
[0183][0184]
其中,s4(t+1)表示缩小开发阶段产生的下一代的值。
[0185]
在阿奎拉鹰算法中引入全局最优个体变异策略,对全局最优个体s
best
进行高斯变异操作,生成新个体s’best
,如果新个体的适应度值优于s
best
,则用s’best
代替s
best
;高斯变异操作如下:
[0186]
s'
best
=s
best
·
(1+n(0,δ2))
[0187]
其中,δ2表示方差,且:
[0188][0189]
其中,δ
2max
和δ
2min
表示方差变化的最大最小值。
[0190]
在阿奎拉鹰算法中引入leader选择策略,用leader代替s
best
,使其有力摆脱局部最优,所提出的leader选择策略如下所示:
[0191][0192]
每一个解都可以独立选择自己的leader,在每次迭代中选择目前最优的解或种群中的任意一个解作为目标靠近,p为选择最优解的概率,在迭代早期,为了加快收敛速度,p值设置为0.9,倾向于最优解方向移动;而在迭代的后期,应致力于发现新解,p值设置为0.7,使其有更大的可能向着群体中一般的甚至是糟糕的个体移动,有效增强了迭代后期的探索能力。
[0193]
如图5所示,在阿奎拉鹰算法中提出一种开发和探索的平衡策略,利用一个非线性函数moa(t),实现开发和探索之间的平衡:
[0194]
moa(t)=1+(-1*t3/t3)
[0195]
判断rand是否小于moa(t):
[0196]
若是,则判断p1是否小于0.5:若是,则运用扩大的收缩机制;若否,则实行缩小的搜索机制;
[0197]
若否,则判断p2是否小于0.5:若是,则运用扩大的开发机制;若否,则应用缩小的
开发机制;
[0198]
其中,rand、p1和p2均为[0,1]之间的随机值。
[0199]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1