基于双层强化学习电网-用户相协同的电压无功优化方法
1.本发明属于电力系统自动化技术领域和计算机技术领域,具体涉及基于双层强化学习电网-用户相协同的电压无功优化方法。
背景技术:
2.根据国际能源机构的数据,到2022年全球太阳能光伏发电(pv)的装机总容量逐步增加到240gw,同比增长41%。随着新能源技术的不断成熟越来越多的光伏电源也被安装在用户侧,在新增的pv中约43%来自住宅、商业和工业项目。间歇性pv的高渗透率改变了配电网的运行方式并导致节点电压频繁的违规。pv附带的逆变器作为一种快时间尺度的连续设备通常被用来减缓pv带来的电压问题。然而与电网侧的其它电压调节资源不同,配电运营商(dso)通常无法对用户侧的pv进行有效的观测和控制。因此需要发明一种有效的配电网无功优化方案来应对上述问题。
3.目前研究人员解配电网的无功电压优化(volt/var optimization,vvo)问题的方法大致可以分为两类:基于模型的方法和免模型的方法。其中基于模型的方法是将vvo描述为一个数学规划问题进行求解,但这种方法需要精确的参数来对问题进行建模,然而目前的电网公司往往并不能提供准确的电网物理模型。同时由于pv的间歇性,一些控制指令需要快速下达给设备,基于模型的方法具有较大的计算负担,并不能满足这一要求。因此基于深度强化学习(drl)的免模型方法是一种良好的替代方案,其求解思路是将所求问题的模型转换成一个马尔科夫决策过程(mdp),然后通过设置状态空间、动作空间和奖励函数让drl智能体在不断地和配电网环境互动来学习最佳的策略,同时训练好的drl智能体不存在计算负担,可以完成实时的决策。
4.如今已有很多种drl算法被用来求解配电网的vvo问题,其中多智能体强化学习(madrl)方法(比如madqn、maddpg、masac等算法)受到了许多学者的青睐,也在配电网无功优化领域取得了不错的效果。比如有研究将配电网分解为若干子网络并把每个子网络看作一个智能体,或者将有载调压变压器(oltc)、开关电容器组(scb)、静止无功补偿器(svc)和dg逆变器等调压设备分别看作一个智能体,然后使用madrl算法并通过集中式训练和分散式执行的框架对各智能体进行训练来求解最佳策略。还有研究提出一种双时间尺度的电压无功控制方法,使用单智能体强化学习算法对响应慢的调压设备进行集中控制,使用多智能体强化学习算法对响应快的设备进行分散式控制。上述这些madrl方法的主要思想是将vvo问题建模为多智能的马尔科夫博弈(markov game,mg)模型,这种mg是一种对称的合作博弈,其目的是为了寻找一个纳什均衡(nash equilibrium,ne)。然而上述的多智能体强化学习(madrl)方法均不能确保收敛到特定的纳什均衡,从而导致求解的不确定性和次优性。同时现存的madrl方案默认配电运行商(dso)可以监测和控制所有的设备,但是由于数据安全和隐私,dso并不能有效的对位于用户侧的设备进行调度。
技术实现要素:
5.为解决上述问题,本发明公开了基于双层强化学习电网-用户相协同的电压无功优化方法,从不对称的角度重新考虑了配电网的vvo问题,提出了一种非对称的马尔科夫博弈模型(asymmetric markov games,asmg),同时发明了一种多目标的双层无功电压优化(bi-levelvvo,bi-vvo)框架,除此之外,本发明还提出了一种无模型的bi-level actor-critic(bi-ac)算法来解决上述的不对称马尔科夫博弈模型,该算法为领导者和跟随着智能体制定了独特的策略(actor)和价值(critic)网络,同时还定义了领导者智能体的决策优先级,以便跟随者代理始终执行最佳响应策略,然后将整个求解过程分为离线训练和在线执行两个阶段。最后,本发明通过一个改进的ieee 33节点测试系统和实际电网运行数据验证了所提方案的有效性。
6.为达到上述目的,本发明的技术方案如下:
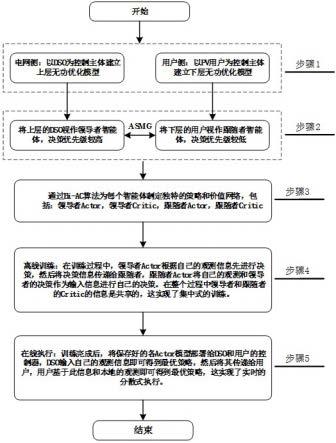
7.基于双层强化学习电网-用户相协同的电压无功优化方法,包括以下步骤:
8.步骤1:构建配电网的双层电压无功优化(bi-vvo)模型,在电网侧以配电运营商(dso)为控制主体构建上层的优化模型,其目标是降低整个系统的网损,在用户侧以光伏(pv)用户为控制主体构建下层的优化模型,其目的是降低配电网节点的电压偏差;
9.步骤2:将步骤1中的双层优化模型中的上层dso视作领导者,下层pv用户视作跟随者,并定义它们的决策优先级,以此来构建非对称马尔科夫博弈(asmg)模型。
10.步骤3:为了求解步骤1,2提出的方法,使用一种双层强化学习算法bi-levelactor-critic(bi-ac)为领导者和跟随着智能体制定独特的策略(actor)和价值(critic)网络。
11.步骤4:针对步骤3中的bi-ac算法,采用离线的方式训练各智能体,在此过程中智能体通过真实的配电网历史运行数据不断和仿真环境互动学习最佳的优化策略。
12.步骤5:在步骤4训练完成后,将各智能体的actor网络部署到控制器上,给控制器输入观测信息即可实时的得到优化策略。
13.由于stackelberg博弈是一种非对称的动态博弈,通常用于研究具有不同优先级的多层决策问题,每个层级通过交互博弈找到stackelberg均衡(stackelbergequilibrium,se)。虽然se对低优先级决策的智能体存在歧视,但se在广泛的环境中优于ne,尤其是在合作博弈中se是pareto最优的。如果将配电网中的各种无功优化设备分别看作博弈主体,则配电网的vvo正是一个合作的协同博弈过程。
14.在此基础上,本发明提出了一种pv高渗透配电网的电网-用户侧资源相协同的双层电压无功优化(bi-vvo)框架。其中,上层被电网侧的dso控制,其目的是通过控制电网侧的设备来减小整个系统的功率损耗。下层由用户侧的控制,其目的是通过调度位于用户侧的分布式资源来缓解pv带来的过电压问题。我们将该bi-vvo问题描述为asmg问题,分别定义上下两层的代理为领导者智能体和跟随者智能体,并定义决策优先级,即领导者先进行决策,然后只需要将决策信息传递给跟随者,跟随者在此基础上进行决策,也就是说下层优化在上层优化的基础上进行。最后本发明提出了一种bi-ac算法为领导者和跟随者智能体构建独特的动作(actor)和价值(critic)网络来训练各智能体学习最佳的策略。
15.本发明的有益效果:
16.本发明所提出的bi-vvo方法是一种多目标的优化方法,上层优化可以减小整个系
统的功率损耗,下层优化可以减小pv间歇性带来的电压偏差,该方法充分利用了电网侧和用户侧的优化设备,并可以在有限的通讯条件下调度用户侧的分布式资源。
17.同时我们提出的asmg模型中定义了领导者的决策优先级,领导者在优化完成后将最佳决策传递给跟随者,因此跟随者也总能执行最佳的响应策略。所提的asmg模型既保证了电网侧数据的隐私又确保用户侧利用其自身设备实现更好的决策。
18.同时本发明提出的bi-ac算法不依赖于精准的配电网模型和先验的统计信息,并将整个过程分为两个阶段:离线训练和在线执行。该算法在离线训练阶段采用集中式训练和分散式执行的框架,通过真实的配电网历史运行数据和电网环境不断活动来学习配电系统的动态特性,同时也可以捕获到pv的不确定性。在线执行阶段,训练好的智能体可以在较短的时间内计算出最佳策略,可以实时应对pv的间歇性和波动性。
附图说明
19.图1为本发明的流程图。
20.图2为基于asmg的bi-vvo框架图。
21.图3为各智能体离线训练完成后的在线执行过程。
22.图4为ieee33节点测试系统图。
23.图5为夏季和冬季典型日的pv有功出力曲线以及负荷有功功率。
24.图6为领导者和节点17的跟随者训练过程的累计奖励收敛情况。
具体实施方式
25.下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
26.如图所示,本发明所述的基于双层强化学习电网-用户相协同的电压无功优化方法,包括以下步骤:
27.步骤1:构建配电网的bi-vvo模型。
28.上层的控制主体是电网侧的dso,为了应对pv的间歇性在具体实施时我们选择的无功优化设备是静止无功补偿器(svc)。上层的优化目标是最小化配电系统的有功损耗,式(1)为精确的有功损耗计算公式:
[0029][0030]
式中n是配电网的节点总数,pi,qi和pj,qj分别代表节点i和j的有功功率和无功功率的净注入量。系数α
ij
和β
ij
可由下式计算:
[0031][0032][0033]
式中,δi、vi和δj、vj分别代表节点i和节点j的电压相角和幅值r
ij
为两个节点之间的线路电阻,下层的控制主体是安装pv的用户,通过pv附带的逆变器对所在节点进行无功优化来缓解pv间歇性带来的电压偏差,其优化目标如式(4)。
[0034]videv
(t)=|v
i-v
set
|
ꢀꢀ
(4)
[0035]
式中,vi为节点i的电压幅值,v
set
为标准电压的设定值,一般设置为1。vvo问题中的等式和不等式的约束包括电力系统的潮流平衡约束,节点电压约束和控制设备的变量约束,其数学模型在下式中给出。
[0036][0037][0038]vmin
≤v
it
≤v
max
ꢀꢀ
(7)
[0039][0040][0041][0042][0043]
在上所述公式中,t是时间t的集合n是配电网节点的集合g
ij
和b
ij
为电力系统导纳矩阵第ij元素的实部和虚部,v
min
和v
max
是节点电压幅值的上下限。n
svc
是安装svc节点的数量,n
pv
是安装pv节点的数量,q
tpv,i
代表第i个pv节点pv在t时刻的无功输出,si是第i个pv的装机容量,p
tpv,i
是第i个pv节点pv在t时刻的有功功率输出。
[0044]
步骤2:针对步骤1的bi-vvo框架,本发明提出了非对称马尔科夫博弈(asmg)的概念,将上层dso视作领导者智能体,下层pv用户视作跟随者智能体,然后描述了asmg的状态空间、动作空间、奖励函数和状态转移概率,基于asmg的bi-vvo框架如图2所示。
[0045]
在一个n-智能体的马尔科夫博弈(mg)〈s,ai,p,ri,γ〉中,s表示状态空间,a表示联合动作空间,ri是第i个智能体的奖励函数,这里γ是折扣因子,在t时刻智能体i的动作a
it
∈ai。为了得到动作,为每一个智能体i设置一个策略函数然后根据状态转移概率p:s
×
a1×…×an
×
s来产生下一时刻的状态。
[0046]
对于一个马尔科夫博弈,最优的状态值v
i*
(s)和动作状态-动作值q
i*
(s,ai)根据最优贝尔曼方程来确定,其表达式如下:
[0047][0048][0049]
式中,s
t+1
表示智能体下一时刻的状态,p(s
t+1
∣s
t
,a
t
)表示智能体在t时刻做出动作a后从状态s
t
转移到s
t+1
的概率。下面结合bi-vvo问题描述asmg中领导者和跟随者的状态空间、动作空间、奖励函数和状态转移过程。
[0050]
1)状态空间:领导者的状态空间为s
l
=(p,q,v),这里p和q代表节点有功功率和无功功率净注入量pi和qi的集合,v是节点的电压幅值vi跟随者的状态空间为sf=(p,q,v,a),跟随者接收领导者的决策信息并将其作为自身的状态输入策略函数中,因此a是领导者的动作a
l
,除此之外,p、q、v代表安装pv用户所在节点的信息。
[0051]
2)动作空间:领导者的动作空间a
l
是每一个svc的无功功率输出集合,a
l,it
∈a
l
是t时刻第i台svc的无功输出q
tsvc,i
,其中q
tsvc,i
在式(8)中被定义。跟随者的动作空间af是每一个pv逆变器的无功功率输出,a
f,it
∈af是t时刻第i台pv的无功输出q
tpv,i
,其中q
tpv,i
在公式(9)中被定义。
[0052]
3)奖励函数:领导者的奖励函数是r
lt
=-p
loss
(t)
–
η,这里p
loss
(t)在公式(1)中被定义。跟随者的奖励函数为r
f t
=-v
dev
(t)
–
η,这里v
dev
(t)在公式(4)中被定义,η是奖励函数中的惩罚因子,当有节点的电压幅值都满足公式(7)时η=0。
[0053]
4)状态转移:在每个时刻t,领导者获得观测自己的状态为s
lt
=(p
t
,q
t
,v
t
),根据该状态做出相应的动作a
lt
,并把它传递给跟随者。跟随者在t时刻的状态为s
ft
=(p
it
,q
it
,v
it
,a
lt
),其中包括自己的当前的状态和领导者的动作,然后做出相应的动作a
ft
。然后智能体获取各自的奖励r
it
,状态根据概率模型p(s
it+1
|s
it
,a
it
)转移到下一时刻s
it+1
。每一个智能体的目标是发现一个可以最大化其累计折扣回报ri=∑
τt=0
γ
trit
的策略。
[0054]
步骤3:针对步骤1,2提出的模型,本发明提出了一种bi-ac算法。
[0055]
考虑到svc和pv的动作是连续的,我们为每一智能体制定了一个actor模型和一个critic模型,并采用确定性策略函数来表示actor模型,以及使用函数qi(si,ai|θi)表示critic模型,其中和θi是神经网络的权重参数。下面介绍各模型在优化过程中的参数更新原理。本发明假设asmg模型中有一个领导者和m个跟随者,我们构建了一个联合策略集合{μ
l
,μ
f,1
,
…
,μ
f,m
}。领导者actor输出的动作跟随者actor输出的动作跟随者和领导者用来评判actor的critic模型为qi(s
lt
,a
lt
,a
f,kt
|θi)。智能体i的累计期望回报的梯度为j(μi)=e[ri],下式为领导者和跟随者的策略梯度更新式:
[0056][0057][0058]
式中,x
t
=(s
lt
,s
f,1t
,
…
,s
f,mt
),δ表示经验池(replay buffer),它包含(x
t
,x
t+1
,a
lt
,a
f,1t
,
…
,a
f,mt
,r
lt
,r
f,1t
,
…
,r
f,mt
)。同时可以通过最小化预测值和目标值之间的loss来更新值函数qi(s
lt
,a
lt
,a
f,kt
|θi)。更新式如(16)和(17)所示:
[0059][0060][0061]
式中,e代表期望,i可以代表l,f1…m,在更新过程中我们设计了目标actorμ'i和目标critic q'i以防止值的过估计并增加模型的稳定性。和θ'i分别为目标actor和目标critic神经网络的权重参数,使用目标网络替换q中的y
it
得到下式:
[0062][0063]
目标网络的权重更新式为:θ'
←
τθ+(1-τ)θ',这意味着目标值只能缓慢变化,这大大提高了学习的稳定性。
[0064]
步骤4:针对步骤1,2,3提出的模型,本发明使用集中式训练分散式执行的框架进
行离线训练。
[0065]
本发明使用数据驱动的方法对所有的模型进行集中训练,各智能体使用真实的配电网历史运行数据通过和仿真环境不断的互动来学习配电网的动态特性。在互动的过程中配电网的变量是pv的有功出力以及各节点负荷的有功功率和无功功率。我们使用的训练数据的时间间隔是5分钟,因此我们将每一天设置为一个回合t(episode),每个episode包括288个步数t(step),即t=288t。在训练开始时,随机初始化智能体i的actor和critic神经网络模型的参数和θi,然后设定随机探索的step的数量,在探索阶段智能体采取的动作是随机的。在一个step内,领导者根据当前观测的状态s
lt
计算出需要做的动作a
lt
,跟随者根据自己本地的观测状态s
ft
以及领导者的动作a
lt
计算出自己需要做的动作然后将联合动作输送到电力系统的仿真环境进行潮流计算,最后,从仿真环境的计算结果中得到领导者和跟随者t时刻的回报r
lt
和r
f t
,以及t+1时刻的状态s
lt
和s
ft
。然后将得到的信息存入经验池中(replay buffer)中,经验池存入的信息达到一定数量后进行模型的更新,每次从replay buffer中取出一个mini-batch利用式(19),(20),(21)对actor和critic神经网络模型的参数进行更新。
[0066][0067][0068][0069]
式中的σ为神经网络在梯度更新时的学习率。至此,随着训练回合的推进智能体学到的策略越来越好,训练结束后将各神经网络的参数进行保存。训练过程如下表所示:
[0070]
表1bi-ac算法的离线训练过程
[0071][0072]
步骤5:在步骤4训练完成后,将各智能体的actor网络部署到控制器上,给控制器输入观测信息即可实时的得到优化策略。在线执行的流程如图3所示。
[0073]
我们使用标准ieee 33节点配电网测试系统和江苏省某试点项目里面的真实pv和负荷数据对本发明所提方法进行了有效性验证。同时我们将本发明所提出的bi-ac算法与单智能体模型的softactor-critic(sac)算法和多智能体模型的maddpg算法进行了比较,其中每个智能体模型的制定和培训过程由“tensorflow”在配备16gb内存和2.50ghz intel(r)core(tm)i7-11700的计算机上完成。下面我们阐述仿真实验的场景设计。
[0074]
在33节点测试系统中,我们嵌入3台光伏电源作为用户侧的调压资源,分别被安装在17,22,32节点,其装机容量分别为2mva,0.9mva,1mva。嵌入两台svc作为电网侧的调压资源,分别被安装在5,12节点,无功容量均为600kvar。33节点测试系统如图4所示。我们选取浙江省某三个大型企业的光伏电源的有功出力作为光伏输出,负荷数据来自浙江省的某试点项目,图5为夏季和冬季典型日的pv有功出力曲线以及负荷有功功率。我们将数据分为训练集和测试集,在离线训练过程中使用500天的历史光伏和负荷数据,分辨率为5min,这144000个训练样本能更好的描述不确定性问题以及拟合真实的环境。
[0075]
在电网侧由一个领导者代理对两个svc进行控制,领导者的输入为整个系统的节点信息,输出为两个svc的无功功率。用户侧由三个跟随者代理(跟随者1,跟随者2,跟随者3)分别控制17,22,32节点的pv逆变器,跟随者的输入分别为各光伏电源所在节点的节点信息,输出为逆变器的无功功率。在离线训练阶段,代理模型被训练500回合,每回合包含288步,电压限制都设置为[0.95,1.05],若电压越限则代理受到相应惩罚,惩罚因子η设置为2。
若在训练过程中潮流不收敛,则返回终止指令。在回合结束或者出现终止情况时对环境进行初始化。每一个代理都分别有一个actor模型和critic模型,且所有代理的神经网络架构是相同的,其超参数下表所示。
[0076]
表2算法的超参数设置
[0077][0078]
为了对比本发明所提方法的性能,我们将maddpg算法作为多代理rl基线,为了更好的对比se相比与ne的优势,将maddpg的一个智能体看作bi-ac的领导者,其他三个智能体看作跟随者,不同的是它们无法接收领导者的动作信息。maddpg各智能体模型的超参数设置和bi-ac算法一样。同时,将sac算法作为集中式rl基线。在不考虑通信的情况下把所有控制设备看作一个sac智能体,该代理可以通过全局信息进行优化决策。由于基于drl算法的随机性,我们使用不同的随机种子对每个算法进行三次训练,训练结果的平均值和误差界在图中以实线和填充区表示。训练过程中领导者和节点17的跟随者的平均累计奖励如图6所示。
[0079]
在训练过程中,由于maddpg以及本发明所提算法与增加了熵项的sac算法相比探索能力相对较弱,因此增加了前两者的探索步数。在探索阶段智能体产生的动作是随机的,因此每个智能体得到了较低的回报。由于本文所提方法的跟随者在领导者决策的基础上进行决策,因此两者的平均累计奖励收敛缓慢且具有较大的浮动。在对环境的变化有了充分的认知以后,各智能体学习到了良好的决策,每回合的平均累计回报趋于稳定。在各算法的训练稳定后,配电网的电压违规次数接近于0,这也证实了rl方法良好的性能。
[0080]
表3各算法在最后100回合的性能比较
[0081][0082]
如图6所示,由于集中式算法sac根据全局的信息对所有设备进行控制,因此它的累计奖励要高于其他两种算法。由于本文所提方法的智能体之间存在通讯,对于全局有功损耗的优化性能要优于maddpg。bi-ac的跟随者是在领导者最优决策的基础上进行优化,因此用户侧跟随者的回报要远高于maddpg。表3展示了各算法在最后100回合的有功损耗和3个光伏用户侧的电压偏差以及整个系统的电压违规率的平均值。
[0083]
需要说明的是,以上内容仅仅说明了本发明的技术思想,不能以此限定本发明的保护范围,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰均落入本发明权利要求书的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1