分层多智能体深度强化学习配电网电压调节方法
本发明属于人工智能与控制系统交叉,更具体地说,涉及一种分层多智能体深度强化学习配电网电压调节方法。
背景技术:
1、传统基于模型的方法比如模型预测控制、随机规划、鲁棒优化等方法虽然能够在一定程度上解决电压越线问题,但是此类方法通常需要知晓配电网系统的模型参数或不确定性先验信息,其控制性能的好坏与系统参数精确与否关系很大。为解决这个问题,基于无模型的深度强化学习方法被应用到配电网电压调节问题中,比如有单时间尺度的multi-agent deep deterministic policy gradient(maddpg)算法,多时间尺度的soft actor-critic multi-agent soft actor-critic(sac-masac)算法,这些方法虽然能够有效解决配电网电压安全问题,但是这些方法都无法满足考虑多种类型混杂设备在不同时间尺度的协同电压调节的场景;当离散设备数量较多时,现有方法所采用的的单智能体集中式控制方案无法应对动作空间随设备数量增加而呈指数增长的局限,从而无法实现大量离散、连续设备的协同电压调节,限制了配电网中多类型混杂设备的协同调压潜力。
技术实现思路
1、针对现有技术的不足,本发明的目的在于提升高比例新能源发电接入配电网环境下的多类型混杂设备协同电压调节能力,解决大规模新能源发电不确定性导致的电压波动问题,同时通过优化配电网系统中可调控设备的有功、无功出力降低系统网损并最大程度减小离散设备的动作频率,提升设备的使用寿命。
2、为了解决上述技术问题至少之一,根据本发明的一方面,提供了一种分层多智能体深度强化学习配电网电压调节方法,包括如下步骤:
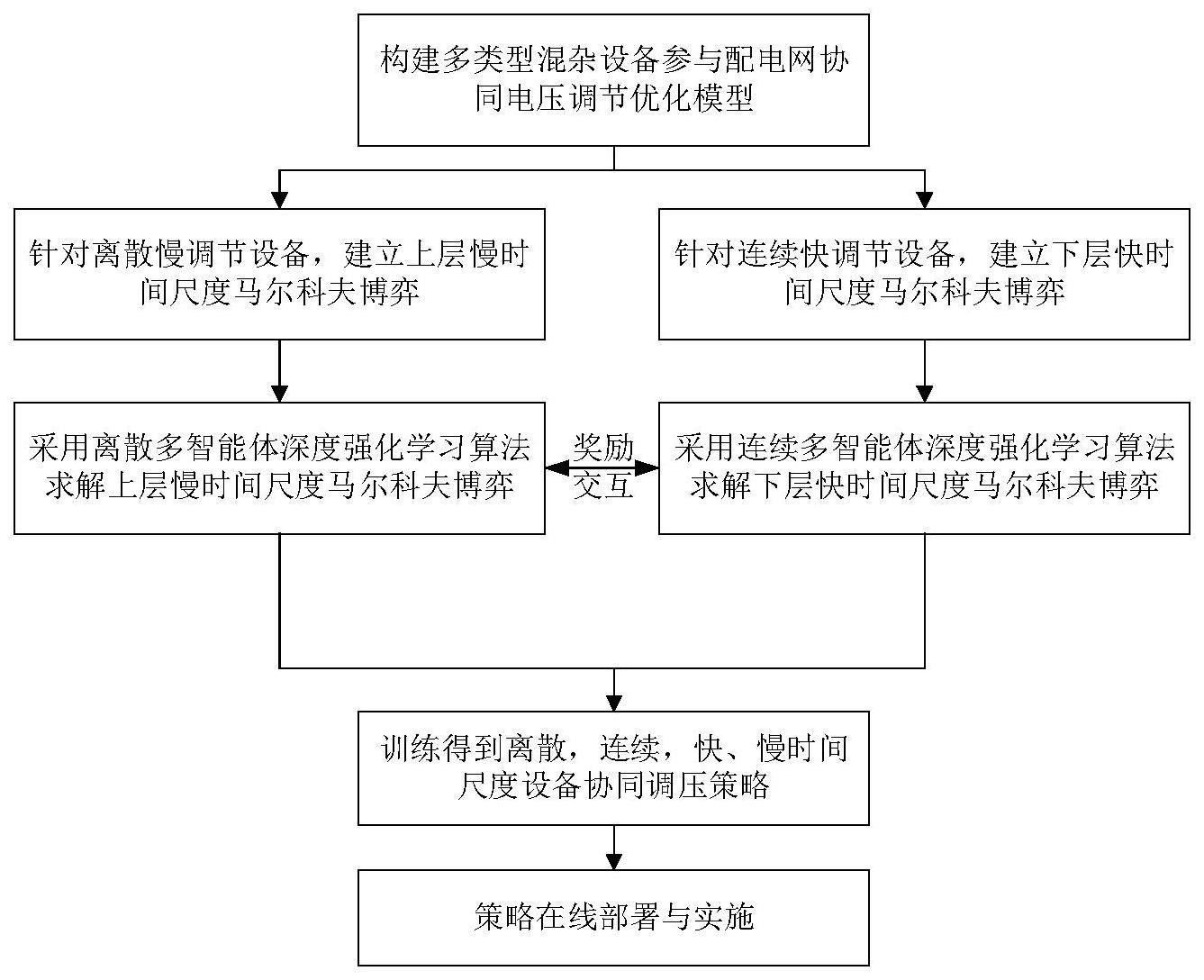
3、s1、考虑多类型混杂设备协同构建配电网电压调节优化模型,将一天作为一个总控制周期,每天划分为t个慢时间尺度时隙用于控制上层离散设备,每个控制时隙划分为γ个快时间尺度间隔用于控制下层连续设备,其中,t=γ·j。其中j为常数,并根据电气距离将配电网系统划分为i个子区域。多类型混杂设备协同配电网电压调节优化模型包括目标函数,约束条件以及决策变量。
4、(1-1)目标函数定义如下:
5、minc1+δ1c2+δ2c3 (1)
6、
7、
8、
9、其中:
10、①c1表示控制周期t内所有节点电压偏离安全范围的和,n为配电网节点个数,δvn,t,τ表示t时隙τ时刻节点n的电压偏离安全范围的大小,其表达式为:
11、
12、其中:vn,t,τ表示t时隙τ时刻节点n的电压幅值,vn,max与vn,min分别表示节点n的最大、最小安全电压边界。
13、②c2表示控制周期t内系统网损,表示t时隙τ时刻节点n到m的线路有功损耗,其表达式为:
14、
15、其中:gn,m为线路n到m导纳的实部,为电压相角,为配电网系统所有母线节点的集合。
16、③c3表示控制周期t内离散设备的调节次数,zn,t为离散设备在t时刻的调节次数,其表达式为:
17、
18、其中:χn,t,ψn,t分别为t时隙有载调压变压器档位及电容器组的投切数量;和分别为有载调压变压器和电容器组所在母线节点的集合。目标函数中c1+δ1c2+δ2c3表示电压偏移、系统网损以及离散设备调节次数的加权和,δ1和δ2分别为平衡电压偏移、系统网损以及离散设备调节次数的权重系数。
19、(1-2)多类型混杂设备协同电压调节优化模型包含的约束条件如下:
20、1)潮流平衡及电压约束:
21、
22、vn,min≤vn,t,τ≤vn,max (7)
23、其中:分别表示t时隙τ时刻光伏与储能系统在节点n的有功功率注入量;分别表示节点n负荷有功功率需求量及柔性负荷调节量;和分别表示t时隙τ时刻光伏逆变器,静止无功补偿器及电容器组的无功注入量;为节点n负荷无功需求量;bn,m为线路n到m导纳的虚部。
24、2)有载调压变压器与并联电容器约束:
25、χn,t∈{-5,-4,-3,-2,-1,0,1,2,3,4,5} (8)
26、v1,t,τ=v0,t,τ+χn,tvtap (9)
27、ψn,t∈{0,1,2,3,4,5} (10)
28、
29、其中:χn,t为有载调压变压器的动作范围,vtap表示有载调压变压器相邻两个档位的电压变化量;ψn,t为电容器组投切数量范围,为节点n所连接的电容器组中每组电容器的无功功率容量。
30、3)光伏逆变器有功、无功功率约束:
31、
32、
33、其中:和分别表示光伏逆变器的视在功率及有功功率最大范围。
34、4)储能系统约束:
35、
36、
37、bmin≤bn,t,τ≤bmax (16)
38、其中:和分别表示储能系统在节点n的最大充、放电功率;bn,t,τ为t时隙τ时刻储能系统当前电量;bmax和bmin分别为储能系统最大最小容量;ηc和ηd分别为充、放电效率系数。
39、5)静止无功补偿器与柔性负荷约束:
40、
41、
42、其中:与表示静止无功补偿器最大最小无功容量;和分别为t时隙τ时刻柔性负荷可调功率的上限与下限。
43、(1-3)多类型混杂设备协同电压调节优化模型包含的决策变量如下:每个慢时间尺度有载调压变压器的档位χn,t和电容器组投切个数ψn,t,每个快时间尺度光伏逆变器无功输出静止无功补偿器输出储能充放电功率以及柔性负荷调节量
44、s2、将上述多类型混杂设备协同调压问题建模为双层马尔科夫博弈,给定离散调节设备包括x个有载调压变压器和y个电容器组,则上层马尔科夫博弈总共x+y个智能体。
45、(2-1)针对上层慢时间尺度离散设备,设计上层马尔科夫博弈对应智能体的状态、动作以及奖励函数。
46、①上层慢时间尺度智能体状态:有载调压变压器x(1≤x≤x)对应智能体的状态设计为:
47、
48、其中:和分别表示有载调压变压器x所控制区域所有节点连接的光伏逆变器及负荷有功、无功功率;vx,t和分别表示有载调压变压器x所控制区域所有节点对应的电压及相角,χt-1为有载调压变压器x在t-1时隙的档位位置。电容器组y(1≤y≤y)对应智能体的状态设计为:
49、
50、其中:和分别表示t时隙电容器组y对应智能体所在区域的光伏与负荷有功,无功功率;vy,t和分别表示电容器组y对应智能体所在区域节点的电压和相角,ψy,t-1为电容器组y在t-1时隙的投切数量。
51、②上层慢时间尺度智能体动作:上层有载调压变压器x与并联电容器组y对应智能体的动作分别设计为
52、③上层慢时间尺度智能体奖励:上层智能体的奖励包括电压越过安全范围的惩罚项及离散设备动作次数的惩罚项,其表达式为:
53、rx,t=-(rx,t,1+β1rx,t,2) (21)
54、其中:rx,t,1=zx,t表示离散设备动作次数;表示γ时间间隔内所有节点电压越过安全范围的总和,为t时隙τ时刻上层智能体所在区域的所有节点电压越过安全范围之和;ni表示区域i中节点个数,β1为权重系数。
55、(2-2)针对下层快时间尺度连续设备,设计下层马尔科夫博弈对应智能体的状态、动作以及奖励函数。
56、①下层快时间尺度智能体状态:下层定义每个子区域为一个智能体,则区域i对应智能体的状态设计为:
57、
58、其中:和分别表示t时隙τ时刻区域i对应智能体中光伏与负荷的有功与无功功率;vi,t,τ和分别表示区域i对应智能体所在区域节点的电压和相角,bi,t,τ为区域i内储能系统当前电量。
59、②下层快时间尺度智能体动作:每个区域内包含光伏逆变器,静止无功补偿器,储能系统或柔性负荷等调控资源,因此区域i对应智能体的动作设计为:
60、
61、其中:和分别表示光伏逆变器与静止无功补偿器的无功输出量,为储能系统充电或放电功率,为柔性负荷的调控量。
62、③下层快时间尺度智能体奖励:下层每个智能体的奖励包含4个部分,其中包括电压越过安全范围惩罚,系统网损惩罚,储能系统充放电惩罚及调度柔性负荷惩罚,其表达式为:
63、
64、其中:为t时隙τ时刻的系统网损,β2,ε1和ε2分别为正权重系数。
65、s3、上层离散多智能体注意力深度强化学习算法与下层连续多智能体注意力深度强化学习算法中的每个智能体都包含策略网络、目标策略网络、评价网路、目标评价网络以及注意力网络。
66、(3-1)每个上层智能体x的动作网络和目标动作网络包含一层输入层,wu层隐藏层和一层输出层。每个动作网络输入层神经元的个数为每个离散设备对应智能体所观测状态的维数,动作网络输出层神经元的个数对应每个离散设备动作的个数,其输出层通过采用归一化激活函数得到动作网络输出的类分布,通过对类分布采样得到每个离散设备的动作
67、(3-2)每个上层智能体x的评价网络和目标评价网络包含一层输入层,mu层隐藏层和一层输出层。每个评价网络的输入由三个部分完成,首先,每个上层智能体通过各自的单层感知机完成对本地观测状态的编码其次,由单层感知机完成状态和动作的编码并将该编码值输入到注意力网络,最后由注意力网络输出其他智能体对当前智能体的贡献值并将该贡献值与编码共同作为评价网络的输入。最终,每个评价网络输出得到每个智能体对应的动作价值函数
68、(3-3)每个下层智能体i的动作网络和目标动作网络与上层智能体类似,包含一层输入层,wl层隐藏层和一层输出层。每个动作网络输入层神经元的个数为配电网每个子区域所观测状态的维数,动作网络通过输出均值μ和方差σ2共同构成连续动作的高斯分布,通过对高斯分布采样得到每个连续设备的动作
69、(3-4)每个下层智能体i的评价网络和目标评价网络包含一层输入层,ml层隐藏层和一层输出层。每个评价网络的输入由三个部分完成,首先,每个下层智能体通过各自的单层感知机完成对本地观测状态的编码其次,由单层感知机完成状态和动作的编码并将编码值输入到注意力网络,最后由注意力网络输出其他智能体对当前智能体的贡献值并将该贡献值与编码共同作为评价网络的输入。最终,每个评价网络输出得到每个智能体对应的动作价值函数
70、s4、上下两层算法通过奖励信息的交互实现快慢时间尺度的协同电压调节,在训练过程中:
71、①每个上层智能体x在t(0≤t<t)时隙观测配电网的本地环境状态,并根据所观测到的状态基于策略函数选择离散动作以控制上层离散设备;同时每个下层智能体在t时隙的τ(0≤τ<γ)时刻观测配电网的本地环境状态,并根据各自所观测到的状态基于策略函数选择连续动作以控制下层连续设备,配电网环境在上下两层设备动作基础上运行并根据公式(24)反馈奖励ri,t,τ给下层智能体,同时配电网运行到τ+1时刻状态,此时收集下层智能体的经验元组保存到下层经验池ml。下层智能体在τ+1时刻继续根据观测状态基于策略函数选择连续动作并收集下层智能体的经验元组保存到下层经验池ml。当下层经验池的经验数量大于所设定的阈值kl,则下层多智能体通过最小化损失函数训练评价网络参数表述为:
72、
73、其中:表示期望算子,表示下层智能体i的目标动作价值函数,γ为折扣因子,和分别表示下层智能体i的评价网络与目标评价网络的参数。
74、同时通过梯度下降方法训练和更新策略网络参数策略梯度表述为:
75、
76、其中:μ为温度系数用于平衡和dl(s)表示下层智能体状态相关基线。
77、通过完成下层目标动作网络和目标策略网络参数的更新,其中ζl分别为下层智能体目标网络的软更新权重。
78、②当下层每个智能体x运行至γ时刻,将t时隙内γ个电压越线奖励值求和传递给上层智能体并根据公式(21)得到上层智能体x的奖励rx,t,此时配电网环境进入到t+1时刻状态,同时收集上层智能体的经验元组保存到上层经验池mu。上层智能体在t+1时刻继续观测配电网各自的本地环境状态基于策略函数做出连续动作并收集上层智能体的经验元组保存到上层经验池mu。当上层经验池的经验数量大于所设定的阈值ku,则上层多智能体通过最小化损失函数训练评价网络参数表述为:
79、
80、其中:表示上层智能体x的目标动作价值函数,和分别表示上层智能体x的评价网络与目标评价网络的参数。
81、同时通过梯度下降方法训练策略网络参数策略梯度表述为:
82、
83、其中:μ为温度系数用于平衡和du(s)表示上层状态相关基线。
84、通过更新上层目标动作网络和目标策略网络参数,其中ζu分别为上层智能体目标网络的软更新权重。
85、③当上层智能体运行至t时刻,上、下层智能体完成一个周期的训练,重复上述步骤①-②直至训练过程结束,得到快慢时间尺度对上下两层设备的优化控制策略。最终将训练得到的控制策略通过动作网络的在线部署实现所提出方法在配电系统的实施。
86、根据本发明的另一方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本发明的分层多智能体深度强化学习配电网电压调节方法中的步骤。
87、根据本发明的又一方面,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现本发明的分层多智能体深度强化学习配电网电压调节方法中的步骤。
88、相比于现有技术,本发明至少具有如下有益效果:
89、与基于下垂控制方法相比,所提方法能充分利用各种连续、离散、多时间尺度混杂设备的调压潜力,具有更强的调压能力;
90、与基于模型的电压调节方法相比,所提方法对于模型参数不确定性具有鲁棒性;
91、与基于无模型深度强化学习的电压调节方法相比,所提方法具有更高的可扩展性和更好的调压性能。
- 还没有人留言评论。精彩留言会获得点赞!