基于分层强化学习的电动汽车充电场站协同调峰方法
本发明涉及电力系统,尤其涉及一种基于分层强化学习的电动汽车充电场站协同调峰方法。
背景技术:
1、近年来,在全球能源紧缺和环境恶化的背景下,电动汽车由于其节能、环保等优势在国内外得到了广泛推广。随着越来越多的电动汽车涌入,原有的充电站规模很有可能无法满足其充电需求,由此可能会出现严重的充电排队的现象,这不仅浪费驾驶人员单位时间产出率,而且严重时可能影响配电网电能质量。如何制定有效的电动汽车充电引导策略来缓解电网压力,是未来电动汽车大规模普及的基础和保障。
2、为适应新一代电力系统发展和安全稳定优质运行的需要,构建清洁低碳安全高效的能源体系,控制化石能源总量,着力提高利用效能,本发明在当新能源波动导致电网供需不平衡时,调度中心将启动削峰响应,引导用户参与电网运行调节。电动汽车动作电站可以通过直接或间接的方式参与削峰响应,在缓解电网压力的同时,额外获得响应收益。
3、目前,针对电动汽车充电场站协同调峰方法模型的求解方法主要有传统求解器求解和传统强化学习算法求解。传统基于数学模型的求解器求解方法和强化学习方法可以得到最优解,但环境较为复杂、任务较为困难时,会导致需要学习的参数以及所需的存储空间急速增长,上述方法难以取得理想的效果。分层强化学习将复杂问题分解成若干子问题,通过分而治之的方法,逐个解决子问题从而最终解决一个复杂问题。分层强化学习算法求解为解决此类问题提供了新思路。
4、
5、该状态下的动作定义为令状态动作到充电桩功率的映射关系记为如下所示:
6、
7、
8、
9、其中sgn(z,j)为0/1变量,表示在决策时刻时充电桩csj是否有电动充电,若有sgn(z,j)=1;反之,sgn(z,j)=0,
10、假设在决策时刻上层智能体处于状态slow(z)采取动作alow(z)的单步转移奖励记为rlow(z),如下所示:
11、
12、考虑初始状态随机,则下层智能体的优化目标函数为:
13、
14、优化策略υ*为最大化所得的控制策略,即下层智能体采用td3算法进行求解。
15、本技术方案进一步的优化,所述步骤s4具体包括以下步骤,
16、s41、将充电服务价格空间用常量εpr离散为2nup+1个等级,其中则第k个决策时刻的动作aup(k)∈{-nup,-nup+1,…0,,…,nup}对应的充电服务价格为
17、上层智能体在决策时刻的决策状态为其中表示内的充电场站基线,w=δtou/δ;表示内削峰功率总量;prk,οk,分别表示在时电网分时电价、充电桩占用比及等待队列长度;
18、s42、在决策时刻上层智能体处于状态sup(k)采取动作aup(k)后,在下一时刻智能体状态转移至sup(k′),该过程产生的单步转移奖励记为rup(sup(k),aup(k),sup(k′)),如下所示:
19、
20、
21、其中为单位时间内下层满意度代价,r单位时间内经济性,其中若时段内没有电网削峰指令,γ(t),
22、s43、考虑电动车到达率为λ(t)情况下,计算从初始状态sup(0)开始时上层智能体按照控制策略π进行决策,经过k步转移累计的总期望收益:
23、
24、建立上层智能体的优化目标函数为:
25、
26、优化策略π*为最大化所得的控制策略,即
27、s44、使用深度强化学习dueling dqn算法对上层智能体进行求解;
28、s45、令状态动作到充电桩功率的映射关系记为如下所示:
29、
30、
31、
32、其中为中间变量,下层智能体在决策时刻的决策状态为该状态下的动作定义为sgn(z,j)为0/1变量,表示在决策时刻时充电桩csj是否有电动充电,若有sgn(z,j)=1;反之,sgn(z,j)=0;
33、s46、在决策时刻下层智能体处于状态slow(z)采取动作alow(z)后,在下一时刻智能体状态转移至slow(z′),该过程产生的单步转移奖励记为rlow(slow(z),alow(z),slow(z′)),如下所示:
34、
35、s47、考虑电动车到达率为λ(t)情况下,计算从初始状态slow(0)开始时上层智能体按照控制策略υ进行决策,经过z步转移累计的总期望收益:
36、
37、考虑初始状态随机,设下层智能体的优化目标函数为:
38、
39、优化策略υ*为最大化所得的控制策略,即
40、s48、使用td3算法对下层智能体进行求解。
41、区别于现有技术,上述技术方案有如下有益效果:
42、基于分层强化学习的电动汽车充电场站协同调峰方法能够有效解决庞大状态空间和行为空间组合以及奖励稀疏的问题,以此加快计算的速度,获得更优的行为策略。利用奖励约束策略优化方法对智能体进行训练,将约束作为惩罚信号引入奖励函数中,解决了强化学习寻找奖励函数漏洞的问题。
技术实现思路
1、针对现有技术的不足,本发明提供了一种基于分层强化学习的电动汽车充电场站协同调峰方法,能够根据电网分时电价等广域信息发布下一时段充电服务价格,根据上级调度机构的调峰需求及当前断面的场站状态控制快充桩的充电功率。利用协同调峰系统,引导用户参与电网运行调节。电动汽车动作电站可以通过直接或间接的方式参与削峰响应,在缓解电网压力的同时,额外获得响应收益。利用奖励约束策略优化方法对智能体进行训练,将约束作为惩罚信号引入奖励函数中,解决了强化学习寻找奖励函数漏洞的问题。
2、为解决上述技术问题,本发明提供了如下技术方案:
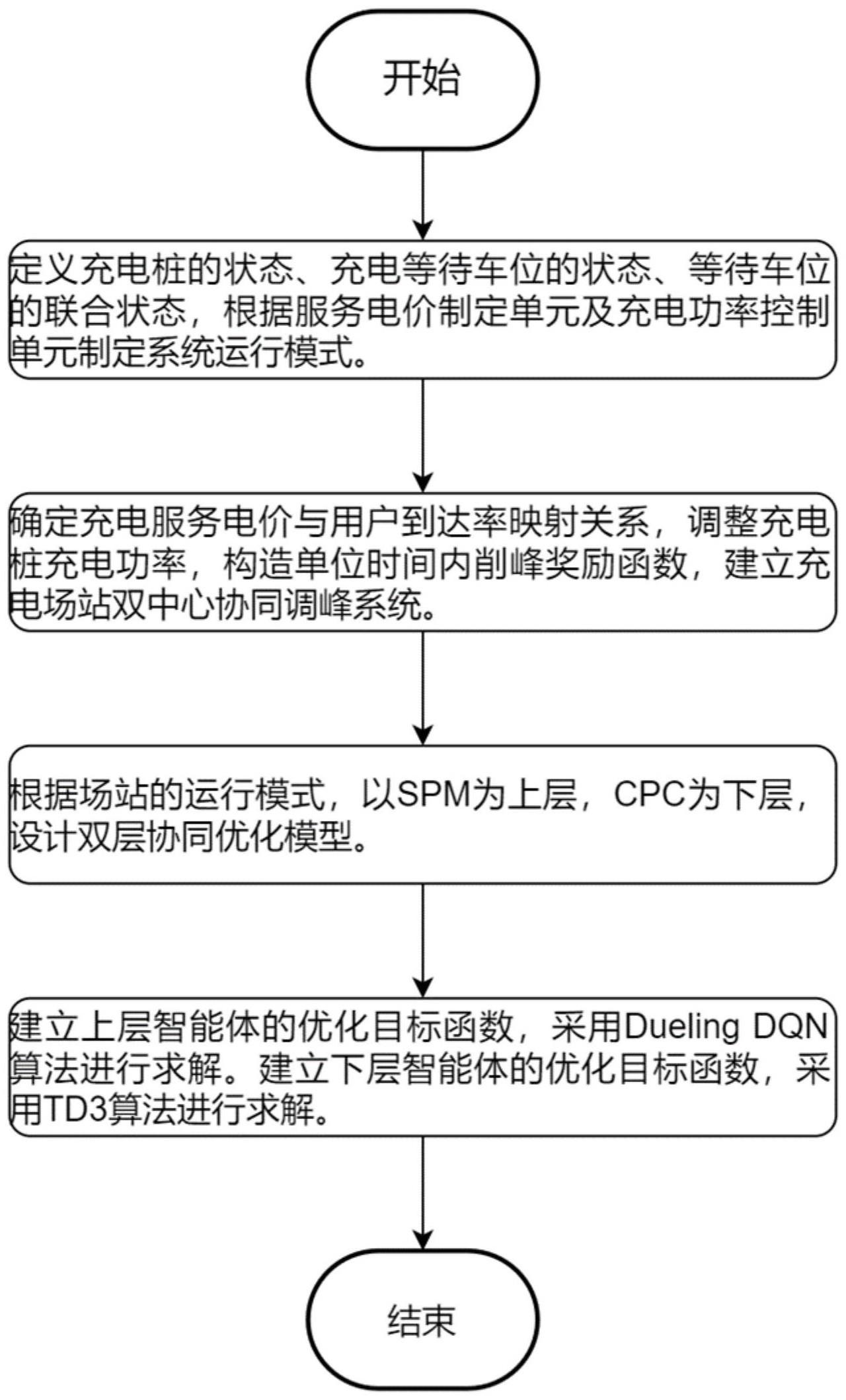
3、一种基于分层强化学习的电动汽车充电场站协同调峰方法,包括以下步骤:
4、s1、定义充电桩的状态、充电等待车位的状态、等待车位的联合状态,根据服务电价制定单元及充电功率控制单元制定系统运行模式;
5、s2、确定充电服务电价与用户到达率映射关系,调整充电桩充电功率,构造单位时间内削峰奖励函数,建立充电场站双中心协同调峰系统;
6、s3、根据场站的运行模式,以服务电价制定单元为上层,充电功率控制单元为下层,设计双层协同优化模型;
7、s4、建立上层智能体的优化目标函数,采用dueling dqn算法进行求解,建立下层智能体的优化目标函数,采用td3算法进行求解。
8、本技术方案进一步的优化,所述步骤s1中,制定系统运行模式包括以下步骤,
9、s11、确定直流快充桩数量为j个,充电等待车位数量为l个;
10、将j个直流快充桩分别记为cs1,cs2,…,csj,…,csj,在t时刻,充电桩csj的状态记为
11、
12、其中,mj,分别表示csj所接电动汽车的种类,电池最大容量以及额定充电功率,pj(t)分别表示当前电动汽车的荷电状态以及充电功率,若csj空闲,则mj,pj(t)=0,进而,将j个充电桩在t时刻的联合状态记为c(t)={c1(t),c2(t),…,cj(t),…cj(t)};
13、s12、记录完充电桩的联合状态后,再将l个充电等待车位分别记为q1,q2,…,qi,…,ql,在t时刻,充电等待车位ql状态记为ql={ml,hl,τl},其中ml,hl,τl分别表示ql上停留电动汽车的种类、荷电状态以及到达时间;
14、s13、若ql无电动汽车等待,则ml,hl,τl=0,当等待区域有lrear辆电动汽车停留时,则l个等待车位的联合状态记为
15、q={q1,q2,…,ql,…ql}
16、
17、s14、当有电动汽车结束充电服务离开充电桩csj时,若等待队列有电动汽车,则等待车位q1中的电动汽车接入csj开始充电服务,如下所示:
18、
19、ql=ql+1,l∈[1,lrear-1]
20、
21、
22、其中p0表示电动汽车接入充电桩的初始充电功率,
23、将电动汽车到达作为触发事件,假定m种电动汽车以泊松过程依次到达充电场站,到达率为λm(t),m∈φm={1,2,…,m},将电动汽车到达场站的时间序列记为kev表示抵达充电场站电动汽车的总数,τk为第k个电动汽车到达场站的时间,当第k辆电动汽车到达场站时,将该触发事件记为e(τk)={me(τk),he(τk),τk},me(τk),he(τk)分别表示到达电动汽车的种类和电池荷电状态,
24、当第m辆电动汽车在τm时刻抵达充电场站时,若等待区域没有空余车位,即lrear=l,该电动汽车立即离开场站;若等待区域有空余车位,lrear<l,则该电动汽车进入等待车位,与此同时等待队列状态响应变化,如下所示
25、lrear=lrear+1
26、qlrear=e(τm)。
27、本技术方案进一步的优化,所述步骤s2中建立充电场站双中心协同调峰系统包括以下步骤:
28、s21、令δtou为分时电价下发的时间间隔且对应分时电价周期总数为k,将一天内任意t时刻电网的调峰电价记为prt,令prt∈φpr,φpr是有限的电价状态空间;令为第k个分时电价prt下发的时刻,则记分时电价序列为其中,prk∈φpr,令
29、s22、在第k个电价周期下发时刻服务电价制定单元根据场站未来时间窗口δtou内的场站基线、电网分时电价prk、上级削峰指令以及当前时刻排队电动汽车数量lrear、充电桩的占用比ο,制定内的充电服务电价为了方便表示,将服务电价简记为φpr为充电场站服务价格调节区间;
30、s23、当服务电价制定单元在决策时刻发布内的服务电价计划后,获得该时段电动汽车的到达率
31、s24、当电网无调峰需求时,tps为电网调峰时段的集合,cpc将各个充电功率调整为电动汽车的额定充电功率充电,其中令第d个调度时刻下发的削峰指令记为一天的决策总数为z=t/δ,t为一天总时长,δ为调度指令下发周期,在cpc的z个决策时刻充电功率控制单元下发充电功率控制指令为简记为
32、s25、当电网有调峰需求时,充电功率控制单元根据当前充电桩状态削峰指令充电服务价格和电网分时电价下发充电功率控制指令如下所示:
33、
34、为j维的向量,向量各个数值为充电桩的充电调整功率,为下层智能体在第z个决策时刻第j个充电桩的充电功率为c,
35、
36、各个充电桩充电功率变化如下:
37、
38、s26、充电场站将在决策时段内,cpc以历史运行曲线为基准削减的用电功率,同时调度中心会根据场站的实际响应情况对场站的削峰行为进行奖惩,将削峰时段内任意时刻t下的单位时间削峰奖惩记为γ(t)
39、
40、
41、其中,ptbl为充电场站基线,kcop为惩罚系数,为削峰量,kint为奖励系数,εt为实际削减量,φj为充电桩的集合,pj(t)为第j个充电桩t时刻的充电功率。
42、本技术方案进一步的优化,所述步骤s3中,建立双层协同优化模型包括以下步骤:
43、s31、根据场站的运行模式,以服务电价制定单元为上层,充电功率控制单元为下层,设计双层协同优化模型,上层智能体综合考虑场站运行收益以及用户对于服务电价的满意度,制定充电服务价格改变电动汽车用户的到达率,使场站初步实现削峰填谷,下层智能体综合削峰响应收益以及用户对于削减充电功率的满意度代价,在削峰时段控制充电桩的充电功率以响应上层调度机构;
44、s32、在第k个分时电价周期内的任意时刻t,令充电桩状态为c(t),充电服务电价为将场站充电服务单位时间收益记为如下所示:
45、
46、
47、其中,为充电桩csj所连电动汽车刚抵达场站时的充电服务价格,若电动汽车在等待过程中充电服务费用上涨,出于对用户的补偿,该电动汽车的充电服务费用不变;
48、s33、当削峰时段τps削减部分充电桩的充电功率时,对于该部分用户给予一定的补偿,记为ccom,则场站在一天的运行过程获得的整体收益reco,如下所示:
49、reco=rser+rps-ccom
50、
51、
52、
53、令rser为动车用户提供充电服务获得服务收益,rps为通过参与电网的削峰响应获取响应报酬,表示单位时间内给予充电桩cpsj上电动汽车的补偿成本,该值由当前电动汽车的充电功率,额定充电功率和补偿系数决定,如下:
54、
55、s34、由于上层智能体通过制定不同电价周期δtou内的充电服务价格,影响电动汽车用户在峰谷时段的到达率,进而提高场站充电桩的利用率以提高场站的充电收益,于此同时,部分充电用户会由于服务电价的上涨而降到充电服务的满意度,因此将[t,t′]时段内用户对于充电服务价格的满意度代价记为
56、
57、
58、其中为充电服务价格空间φpr内的原始充电服务电价,dspm为固定代价系数,上层智能体在考虑服务价格满意度情况下,实现场站一天的经济效益最优,其优化目标记为goalspm,如下所示
59、
60、其中为子目标权重系数;
61、s35、下层智能体在削峰时段τps内会削减部分充电桩的充电功率,导致电动汽车用户充电时间延长,假设在下层智能体的削峰时段内的任意决策时刻其充电控制指令为则在决策时段内任意时刻t下,单位时间内下层满意度代价为如下所示:
62、
63、
64、上层智能体在兼顾用户满意度代价及补偿的情况下,实现削峰响应经济收益最大,其优化目标记为goalcpc,
65、
66、其中为子目标权重系数。
67、本技术方案进一步的优化,所述步骤s4中建立上下层智能体的优化目标函数并使用相关算法进行求解:
68、上层智能体的目标是在有限时间范围内最大化累积奖励,由于车辆流量的随机性,它自然是一个随机变量,当从初始状态sup(0)开始时经过k步转移累计的总收益为:
69、
70、如果考虑初始状态随机,则上层智能体的优化目标函数为:
71、
72、优化策略π*为最大化所得的控制策略,即上层智能体采用dueling dqn算法进行求解;
73、下层智能体在决策时刻的决策状态为
74、上层智能体在兼顾用户满意度代价及补偿的情况下,实现削峰响应经济收益最大,其优化目标记为goalcpc,
75、
76、其中为子目标权重系数。
77、s4、建立上层智能体的优化目标函数,采用dueling dqn算法进行求解。建立下层智能体的优化目标函数,采用td3算法进行求解。
78、制定基于分层强化学习的充电场站协同调峰优化策略包括以下步骤:
79、s41、将充电服务价格空间用常量εpr离散为2nup+1个等级,其中则第k个决策时刻的动作aup(k)∈{-nup,-nup+1,…0,…,nup}对应的充电服务价格为
80、上层智能体在决策时刻的决策状态为其中表示内的充电场站基线,w=δtou/δ;表示内削峰功率总量;prk,οk,分别表示在时电网分时电价、充电桩占用比及等待队列长度。
81、s42、在决策时刻上层智能体处于状态sup(k)采取动作aup(k)后,在下一时刻智能体状态转移至sup(k′),该过程产生的单步转移奖励记为rup(sup(k),aup(k),sup(k′)),如下所示:
82、
83、
84、其中为单位时间内下层满意度代价,r单位时间内经济性若时段内没有电网削峰指令,γ(t),
85、s43、考虑电动车到达率为λ(t)情况下,计算从初始状态sup(0)开始时上层智能体按照控制策略π进行决策,经过k步转移累计的总期望收益:
86、
87、建立上层智能体的优化目标函数为:
88、
89、优化策略π*为最大化所得的控制策略,即
90、s44、使用深度强化学习dueling dqn算法对上层智能体进行求解。
91、s45、令状态动作到充电桩功率的映射关系记为如下所示:
92、
93、
94、为中间变量
95、
96、其中下层智能体在决策时刻的决策状态为该状态下的动作定义为为下层智能体在决策时刻的基线功率,sgn(z,j)为0/1变量,表示在决策时刻时充电桩csj是否有电动充电。若有sgn(z,j)=1;反之,sgn(z,j)=0。
97、s46、在决策时刻下层智能体处于状态slow(z)采取动作alow(z)后,在下一时刻智能体状态转移至slow(z′),该过程产生的单步转移奖励记为rlow(slow(z),alow(z),slow(z′)),如下所示:
98、
99、s47、考虑电动车到达率为λ(t)情况下,计算从初始状态slow(0)开始时上层智能体按照控制策略υ进行决策,经过z步转移累计的总期望收益:
100、
101、考虑初始状态随机,设下层智能体的优化目标函数为:
102、
103、优化策略υ*为最大化所得的控制策略,即
104、s48、使用td3算法(twin delayed deep deterministic policy gradientalgorithm)对下层智能体进行求解。
105、需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
106、尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
107、如下所示:
108、
109、为j维的向量,向量各个数值为充电桩的充电调整功率,为下层智能体在第z个决策时刻第j个充电桩的充电功率为c。
110、
111、各个充电桩充电功率变化如下:
112、
113、s26、充电场站将在决策时段内,cpc以历史运行曲线为基准削减的用电功率。同时调度中心会根据场站的实际响应情况对场站的削峰行为进行奖惩,将削峰时段内任意时刻t下的单位时间削峰奖惩记为γ(t)
114、
115、
116、其中,ptbl为充电场站基线,一般由充电场站典型运行日历史运行数据统计获得。kcop为惩罚系数,为削峰量,kint为奖励系数,εt为实际削减量,φj为充电桩的集合,pj(t)为第j个充电桩t时刻的充电功率。
117、s3、根据场站的运行模式,以spm为上层,cpc为下层,设计双层协同优化模型。
118、建立双层协同优化模型包括以下步骤:
119、s31、根据场站的运行模式,以spm为上层,cpc为下层,设计双层协同优化模型。上层智能体综合考虑场站运行收益以及用户对于服务电价的满意度,制定充电服务价格改变电动汽车用户的到达率,使场站初步实现削峰填谷。下层智能体综合削峰响应收益以及用户对于削减充电功率的满意度代价,在削峰时段控制充电桩的充电功率以响应上层调度机构。
120、s32、在第k个分时电价周期内的任意时刻t,令充电桩状态为c(t),充电服务电价为将场站充电服务单位时间收益记为如下所示:
121、
122、
123、其中,为充电桩csj所连电动汽车刚抵达场站时的充电服务价格,若电动汽车在等待过程中充电服务费用上涨,出于对用户的补偿,该电动汽车的充电服务费用不变。
124、s33、当削峰时段τps削减部分充电桩的充电功率时,我们对于该部分用户给予一定的补偿,记为ccom。则场站在一天的运行过程获得的整体收益reco,如下所示:
125、reco=rser+rps-ccom
126、
127、
128、
129、令rser为动车用户提供充电服务获得服务收益,rps为通过参与电网的削峰响应获取响应报酬。表示单位时间内给予充电桩cpsj上电动汽车的补偿成本,该值由当前电动汽车的充电功率,额定充电功率和补偿系数决定,如下:
130、
131、s34、由于上层智能体通过制定不同电价周期δtou内的充电服务价格,影响电动汽车用户在峰谷时段的到达率,进而提高场站充电桩的利用率以提高场站的充电收益。于此同时,部分充电用户会由于服务电价的上涨而降到充电服务的满意度,因此将[t,t′]时段内用户对于充电服务价格的满意度代价记为
132、
133、
134、其中为充电服务价格空间φpr内的原始充电服务电价,dspm为固定代价系数。上层智能体在考虑服务价格满意度情况下,实现场站一天的经济效益最优,其优化目标记为goalspm,如下所示
135、
136、其中为子目标权重系数。
137、s35、下层智能体在削峰时段τps内会削减部分充电桩的充电功率,导致电动汽车用户充电时间延长。因此,设计基于相对延长充电时间的用户满意度指标。假设在下层智能体的削峰时段内的任意决策时刻其充电控制指令为则在决策时段内任意时刻t下,单位时间内下层满意度代价为如下所示:
138、
139、
- 还没有人留言评论。精彩留言会获得点赞!