基于数据挖掘的工业负荷辨识方法及系统与流程
本发明属于工业负荷辨识领域,具体涉及一种基于数据挖掘的工业负荷辨识方法及系统。
背景技术:
1、为贯彻节能减排和低碳发展的理念,积极建设新型电力系统,实现“双碳”的目标,就要加快落实新型电力系统的建设,增大新能源发电的占比。然而,新能源发电目前伴随着随机波动性和不确定性的问题。新能源的发电高峰期与负荷的用电高峰期并不一致,导致电力供需不平衡。在总负荷中,工业负荷量占比最大,且控制自动化水平最高,对实施需求响应具有十分重要的意义,因此,有必要对工业用户的用电行为展开深入研究,分析工业负荷辨识方法,以高效地实现电网的需求响应工作。
2、根据电力系统负荷监控和统计的现状,电网所观测的对象通常为综合负荷。为了保证新能源发电在电力系统中的主体地位,必须解决新型电力系统在电力供需平衡和安全稳定运行等方面的挑战。工业负荷含有大量的分布范围广、单体容量小的小型负荷,由于分布广、数据海量,故电网难以实现对单一负荷的直接控制。通过对综合负荷辨识,得到综合负荷中各类工业负荷的构成比例,进而结合工业负荷的调节特性,得到可监控的综合负荷的可调节能力,才能更好地实现对工业负荷的控制,达到促进新能源消纳的目的基于上述分析,本发明为增强对工业负荷的辨识,更好地实现对工业负荷的控制,采用更合理的送电策略,方便实施负荷能效管理,提出基于数据挖掘的电力系统工业负荷辨识方法。
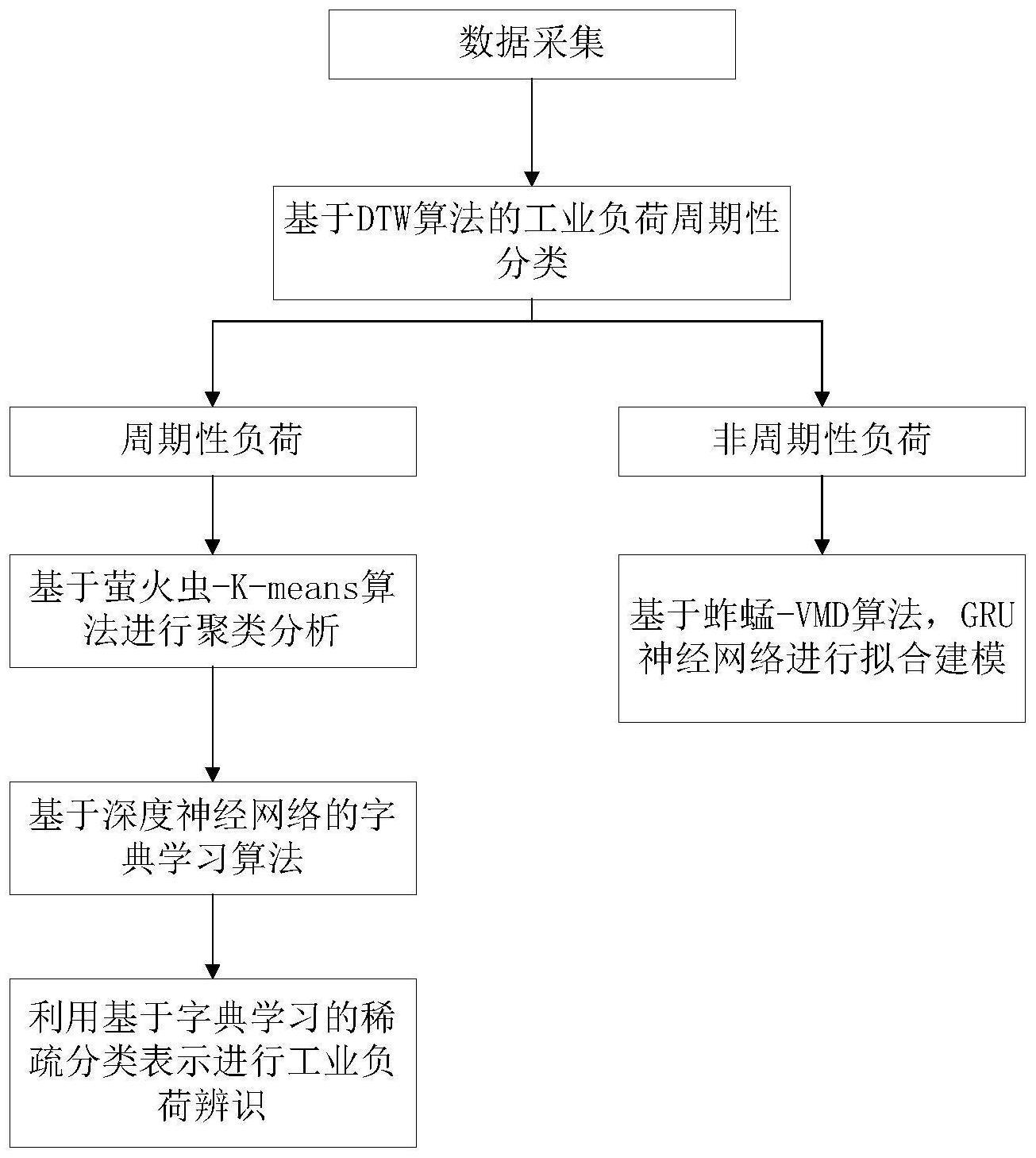
3、因此,本发明基于数据挖掘的工业负荷辨识方法及相关设备,其基于dtw算法提取负荷的dtw值,基于dtw值对负荷进行周期性辨别和分类;基于萤火虫-k-means算法对周期性负荷提取负荷特征曲线作为负荷标签信息;基于goa-vmd-gru算法对非周期性负荷进行拟合建模;基于深度神经网络字典学习算法和src模型对负荷进行辨别,提高了负荷辨别的精确度。本发明通通过提取负荷用电模式并识别来深入分析用户的用电行为,提高了负荷辨识的准确度,有利于改善电力系统负荷能效管理、提高电力运行效率。
技术实现思路
1、本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
2、鉴于上述和/或现有的基于数据挖掘的工业负荷辨识方法中存在的问题,提出了本发明。
3、因此,本发明所要解决的问题在于如何提供一种基于数据挖掘的工业负荷辨识方法。为解决上述技术问题,本发明提供如下技术方案:基于dtw算法进行工业负荷分类;基于聚类算法对周期性负荷进行负荷标签信息的提取;对非周期性负荷进行拟合建模;基于负荷标签信息实现对负荷信息的辨识。
4、作为本发明所述基于数据挖掘的工业负荷辨识方法的一种优选方案,其中:基于dtw算法进行工业负荷分类包括,利用dtw算法对不同工业负荷的dtw值进行计算;根据动态规划思想找到弯曲代价最小的最优匹配路径,快速匹配相似的负荷时间序列,实现负荷周期性分类;基于dtw算法求得的dtw值将工业负荷分为周期性负荷和非周期性负荷,其中,周期性负荷包括强周期性负荷和弱周期性负荷;dtw大于0.7的为强周期负荷,介于0.6和0.7之间的为弱周期负荷,小于0.6的为非周期性负荷;按照周期性对负荷进行分类后,对周期性负荷做聚类分析,提取典型日负荷特征曲线作为工业负荷类别标签,对非周期性负荷则通过研究长期负荷时序曲线的拟合建模方法来分析其用电行为。
5、作为本发明所述基于数据挖掘的工业负荷辨识方法的一种优选方案,其中:基于聚类算法对周期性负荷进行负荷标签信息的提取包括,收集周期性工业用户的负荷数据作为输入;将萤火虫算法与k-means算法相结合,k-means算法用于聚类分析,萤火虫算法用于为k-means算法的参数寻优;对输入数据使用萤火虫算法结合k-means算法的聚类算法进行聚类分析,得到不同类别的负荷特性曲线作为负荷标签信息。
6、作为本发明所述基于数据挖掘的工业负荷辨识方法的一种优选方案,其中:对非周期性负荷进行拟合建模包括,提取其月负荷特征曲线进行建模;使用基于蚱蜢算法优化的vmd算法将负荷序列分解,使原本存在波动的负荷序列自适应地分解为多个imf分量;使用gru神经网络对分解得到的各个分量进行建模;对各分量的建模结果进行集成,以达到精确建模的目的。
7、作为本发明所述基于数据挖掘的工业负荷辨识方法的一种优选方案,其中:基于负荷标签信息实现对负荷信息的辨识包括,聚类分析得到的负荷用电模式作为负荷类别标签以进行基于深度神经网络(dnndl)的字典学习算法,然后创建基于判别字典的稀疏表示分类(src)模型,同时训练判别字典和分类器;基于判别字典的scr的分类准则为:如果理想稀疏编码q=[q1,q2,…qn]∈rk×n中qi是[0,0,…,1,1,1,…0]t∈rk(“1”仅表示非零项)这种形式的,则通过稀疏系数的绝对值大小以及原子所属类别确定类别。假设测试信号yi属于类别l(l=1,2,…l),那么基于字典di的判别稀疏编码qi中的项都是非零的,其它子字典的稀疏编码都是零;基于判别式字典学习的稀疏表示分类具体步骤如下:
8、判别字典学习把字典学习与线性分类器混合为一个优化目标,表示为:
9、
10、式中,d表示字典,w表示分类器模型的参数,a表示变换矩阵,使稀疏编码x具有判别性,表示f范数,y表示训练信号,q表示理想判别稀疏编码,h表示标签矩阵,α和β分别表示稀疏编码误差和分类误差的正则化参数;利用矩阵f范数将优化目标进行等效变换,定义训练信号矩阵和字典矩阵,转换后优化目标表示为:
11、
12、对字典dnew进行如下转换:
13、
14、
15、
16、式中,表示字典,表示线性变换矩阵,表示分类器模型参数;
17、基于判别字典学习的稀疏表示分类准则为:对于每个测试信号yi的稀疏编码,通过以下优化目标实现:
18、
19、根据分类器模型参数来计算稀疏表示系数向量:
20、
21、根据聚类分析得到的负荷数据样本作为字典学习的输入,设置字典大小,满足过完备字典的要求;然后设置稀疏度的约束和最大迭代次数,设置正则化参数α和β用于平衡优化目标中的稀疏编码误差和分类器误差;最后经训练产生判别字典,基于判别字典及稀疏编码的线性组合获得稀疏系数的绝对值大小以及原子所属类别来确定负荷类别。
22、作为本发明所述基于数据挖掘的工业负荷辨识方法的一种优选方案,其中:基于负荷标签信息实现对负荷信息的辨识还包括,在dnndl的模型训练过程中,网络参数根据优化目标采用梯度下降算法,进行自适应更新,使用非线性响应函数实现数据中的内在特征表示,并逐步将初始的低级特征表示转化为高级特征表示,从而获得更加抽象和具判别性的特征,最终建立层次化的特征表达体系。
23、作为本发明所述基于数据挖掘的工业负荷辨识方法的一种优选方案,其中:基于负荷标签信息实现对负荷信息的辨识还包括,dnndl,将ae和字典学习进行有机结合,通过之前获得的负荷类别标签信息,基于字典学习建立src模型,获取稀疏系数的绝对值大小以及原子所属类别来确定负荷类别。
24、一种基于数据挖掘的工业负荷辨识系统,其特征在于:包括:编码器模块,用于实现从样本数据到低维空间表示的非线性映射;字典学习模块,用于将编码器模块的输出作为输入进行字典和稀疏表示的学习,发现样本数据隐含的特定结构并提取特征,最终输出稀疏系数矩阵;谱聚类模块,用于将稀疏系数矩阵作为数据的相似度矩阵进行聚类,得到聚类结果。
25、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如上所述的方法的步骤。
26、一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
27、本发明的有益效果为:本发明提高了负荷辨别的精确度,通过提取负荷用电模式并识别来深入分析用户的用电行为,提高了负荷辨识的准确度,有利于改善电力系统负荷能效管理、提高电力运行效率。
- 还没有人留言评论。精彩留言会获得点赞!