一种基于生成式决策模型的电网运行调整方法
本发明涉及信息,尤其涉及一种基于生成式决策模型的电网运行调整方法。
背景技术:
1、电网是一个将电力从生产端(发电站)输送到消费端(楼房、工厂等)的互连系统。电网系统的稳定运行是一个动态平衡的过程,在这个过程中存在频繁、剧烈且难以预测的供需变化以及极端天气、设备故障等异常事件,需要介入外部手段进行调控,以避免电力系统的失衡造成停电事件引发甚至安全事故,对社会经济和公共安全造成严重影响。
2、传统的电力系统调度方法主要包括基于专家经验的人工调控方法,以及基于数学模型的建立和求解方法。然而随着以电网规模扩大和能源结构转变为特点的新型电力系统的兴起和不断发展,电网系统的运行调度任务呈现出决策维度扩展,决策难度升级的特点,基于专家经验驱动和数学模型驱动的传统方法由于专业知识有限、可扩展性差、动态优化困难等问题而受到限制,不适用于复杂的新型电力系统调度决策场景。
3、基于数据驱动的智能电网调度方法随着大数据和人工智能技术的发展而逐步兴起,为电网运行决策提供新范式,是信息时代背景下完成电力系统数智化转型的一块重要拼图。强化学习方法作为机器学习和人工智能技术在决策领域的分支,其基本原理是让智能体在训练中根据得到的奖励和惩罚不断学习,最终根据学习经验做出高水平决策,随着大数据和人工智能技术的发展,强化学习与深度学习技术融合在围棋、电子游戏和机器人控制等复杂连续的决策任务中展现出超过人类专家的强大能力。因此,强化学习相关技术将是今后数据驱动电网系统调度决策的主流方法。
4、现有的基于强化学习的电网系统调度方法主要可以分为基于专家示例的行为克隆方法和奖励驱动的在线强化学习方法。前者通过智能体模仿高质量的专家电网系统决策调度示例来学习调度策略。然而该方法忽略了专家示例中存在的不谬误会对智能体的学习产生误导,同时专家示例无法保证全面性,因为实际调度任务往往存在专家示例没有涉及的情况,而对专家策略的盲目克隆无法保证智能体对于未知情况的可迁移性。后者则通过智能体与电网仿真环境交互,以不断探索与试错的方式从环境的奖励反馈中来学习电网调度策略。然而该方法高度依赖来自电网环境的密集的奖励信号反馈,然而对于高度复杂的新型电力系统,调度决策产生的影响往往存在“滞后性”和“非及时性”,从而导致奖励信号的延迟性和稀疏性,进而造成智能体学习效率低下,甚至在策略和调度目标之间建立错误的关联。例如一次调度失误造成的严重影响,可能需要经过多轮仿真后导致潮流不收敛或是大规模断线停电才会被暴露。
5、综上所述,目前需要设计电网调度系统的新方法,以解决专家示例的谬误性、非全面性问题以及电网环境奖励信号反馈的延迟性、稀疏性问题。
6、decision transformer以gpt-2(transformer类模型的一种)模型作为决策网络,通过注意力机制建立环境状态、调度策略和奖励反馈序列之间的深层关联,这种基于序列建模的新型强化学习建模方式为解决新型电网调度的系统任务提供了新的思路。
7、大多基于手工特征或者传统机器学习的方法,在准确度上有很大的提升空间。
8、现有的基于强化学习的电网系统调度决策方法存在许多缺陷和不足。
9、第一,许多在线强化学习方法都依赖智能体与电网系统频繁的交互以进行试错式学习,这种方式通常导致模型训练效率低下,且需要高昂成本和技术力搭建电网系统仿真环境以支持模型的训练;
10、第二,由于新型电力系统的不稳定性和电力需求的不可预测性,基于探索和交互的学习方式还会导致模型策略梯度的方差较大,进而导致学习曲线震荡,收敛缓慢,降低学习效率。
11、第三,强化学习方法通常高度依赖来自电网环境的密集的奖励信号反馈,然而对于高度复杂的新型电力系统,调度决策产生的影响往往存在“滞后性”和“非及时性”,从而导致奖励信号的延迟性和稀疏性,进而造成智能体学习效率低下,甚至在策略和调度目标之间建立错误的关联。例如一次调度失误造成的严重影响,可能需要经过多轮仿真后导致潮流不收敛或是大规模断线停电才会被暴露。
技术实现思路
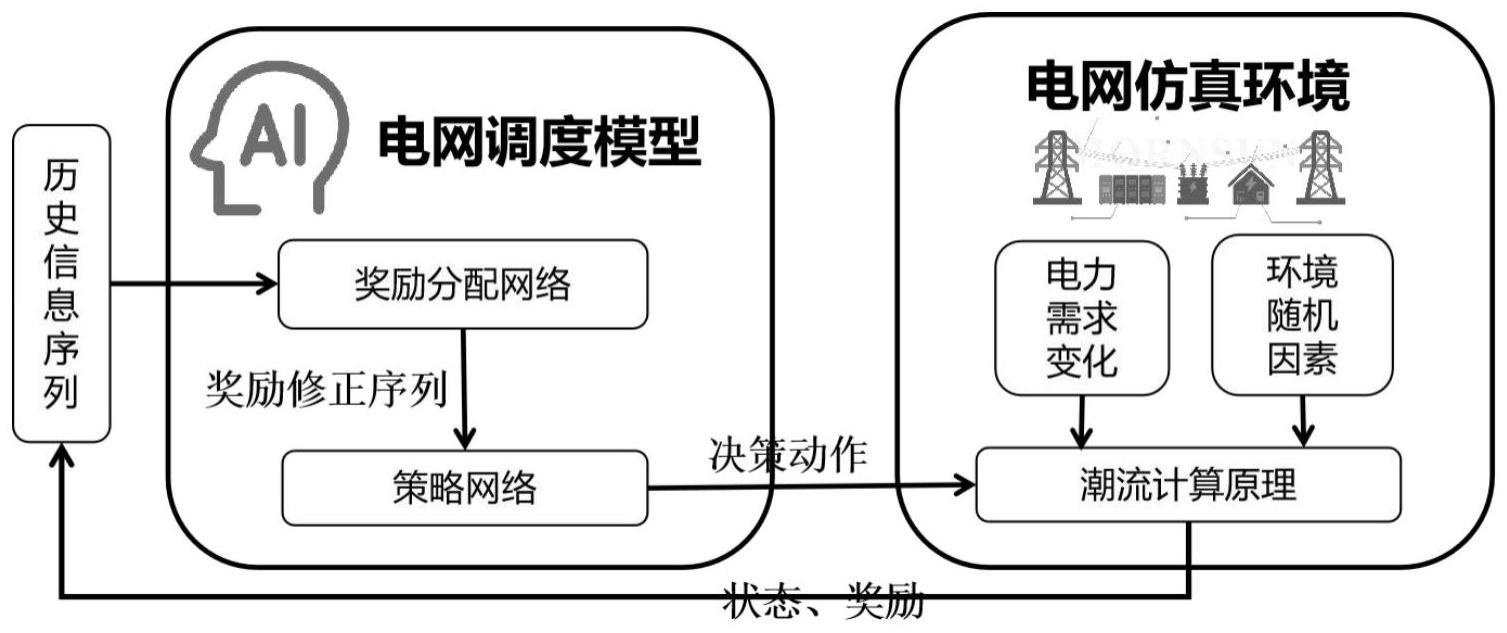
1、为此,本发明首先提出一种基于生成式决策模型的电网运行调整方法,选取transformer模型作为因果自注意力机制的决策模型,基于因果自注意力机制构建电网智能决策方法框架,采用构建电网调度模型,设计奖励分配模型和策略模型两个部分,借助奖励分配网络对奖励信号进行自适应重分配,策略模型接收奖励修正后的序列作为输入,并输出当前时刻的动作at,实现实时生成电网系统的调度策略;具体而言,所述电网在线调度策略包括功率调度策略和拓扑调度策略,其中功率调度策略主要包括对系统中的火电、新能源等发电机组的功率的调节、对储能设备充放能功率的调节以及对可调负载功率的调节,拓扑调度策略则主要包括电网系统中各线路的断开和连接的决策,以及变电站中各支线与母线的连接的决策;构建电网仿真环境模块模拟电网的实际运行情况,接收动作at作为功率和拓扑的调整调度策略,并考虑电力需求变化和环境随机因素的影响,根据底层潮流收敛原理仿真计算得到下一步状态st+1以及电网环境的奖励rt+1,如此往复进行直到电网调度任务的结束;在此基础上,通过双层优化算法对策略网络和奖励分配网络进行高效交替的更新优化。
2、所述奖励分配模型输入为某一时刻电网环境的状态st和动作at,输出为模型该状态下采取该策略所分配的奖励ft。通过输入历史多步状态序列(st-l,......,st-2,st-1)和动作序列(at-l,......,at-2,at-1)得到该序列下的重构奖励分配方案(ft-l,......,ft-2,ft-1),并由此计算新的目标奖励经过奖励分配网络修正后的序列作为transformer策略模型的输入序列。
3、所述策略模型接收经过奖励分配网络后的奖励修正序列并借助自注意力机制构建的电网调度策略与电网状态、目标奖励之间的内在联系推理出下一步合理的电网调度调整方案at,其具体实现方式为:
4、(3)计算嵌入向量:首先模型将输入序列映射为嵌入空间下的电网信息序列x,由此在经过映射后的嵌入空间下来统一表示电网系统的状态、动作和奖励信息,以及计算它们之间的联系:x=(x1,x2,......),xk=ex(i),
5、(4)计算注意力:transformer策略网络采用gpt-2模型结构,其通过将多个decoder结构堆叠,形成多层结构,其中每一个decoder由带掩码的多头自注意力层、前馈神经网络组成,且每层的输出都进行残差连接和层归一化处理,其注意力原理如下所示,其中q、k、v分别为电网信息序列x的query、key、vector子向量,wq、wk、wv则分别为生层三个子向量的线性变换矩阵,m为掩码矩阵,其作用是计算电网信息序列注意力权重时掩盖掉未来的信息,从而实现“因果”机制,dk为key子向量的维度,其作用是对注意力权重进行标准化处理:
6、q=xwq
7、k=xwk
8、y=xwv
9、
10、同时采用多头机制,通过多个注意力头来计算多个注意力的方式,不同的注意力头从不同的特征和角度建模电网信息序列之间的关联,如时域空间和频域空间的关联等,从而更好地捕捉电网信息中的细节和复杂性。
11、所述双层优化算法的具体实现方式为:
12、对于模型的训练,采样电网实际运行调度场景中的状态sreal、奖励rreal和动作areal组成的数据示例对模型进行离线训练,并计算策略模型输出的动作预测值apred和数据实例中的动作真实值areal之间的误差作为策略模型的损失函数:
13、
14、之后将数据集按照一定比例分为训练集和验证集,并如下修正策略模型和奖励分配模型的损失函数:
15、
16、
17、其中,和分别为策略模型在验证集和测试集上的误差,φ和θ分别为策略模型和奖励分配模型的参数,γ为决策序列的总长度,λ为正则项的权重因子,为提高模型的训练效率,通过如下方法对外层优化目标进行近似替代:
18、(1)通过一步梯度近似对外层优化目标进行近似替代:
19、
20、(2)通过链式求导法则对一阶梯度进行展开:
21、
22、(3)通过泰勒展开对一阶梯度和二阶梯度的向量积进一步替换:
23、
24、本发明所要实现的技术效果在于:
25、通过输入来自电网环境的状态和奖励反馈,高效实时生成电网系统的功率调整和拓扑调整方案,辅助人类专家进行调度决策,实现电网系统的安全稳定运行,降低调度决策成本和能源损耗。
26、具体而言具有如下优点:
27、1.以基于因果自注意力的transformer模型作为决策网络,建立电网环境状态、调度策略和奖励反馈之间的深层关联和长序列依赖,从而克服新型电力系统的不稳定性和电力需求波动性等非稳态挑战。
28、2.基于离线数据驱动模型训练,避免了在线训练过程对电网环境交互的高度依赖,以更高效稳定的方式探索电网系统的调度策略。
29、3.通过奖励分配网络对电网系统延迟滞后的奖励信号进行自适应重分配,以更合理的奖励分布重构电网环境延迟稀疏的奖励反馈,辅助策略模型学习和决策,优化策略模型的学习效率。
30、4.通过设计双层优化算法对调度策略问题和奖励分配问题进行解耦,以保证策略模型和奖励分配模型训练的高效性。
- 还没有人留言评论。精彩留言会获得点赞!