基于自组织映射神经网络深度强化学习的配电系统电压控制方法
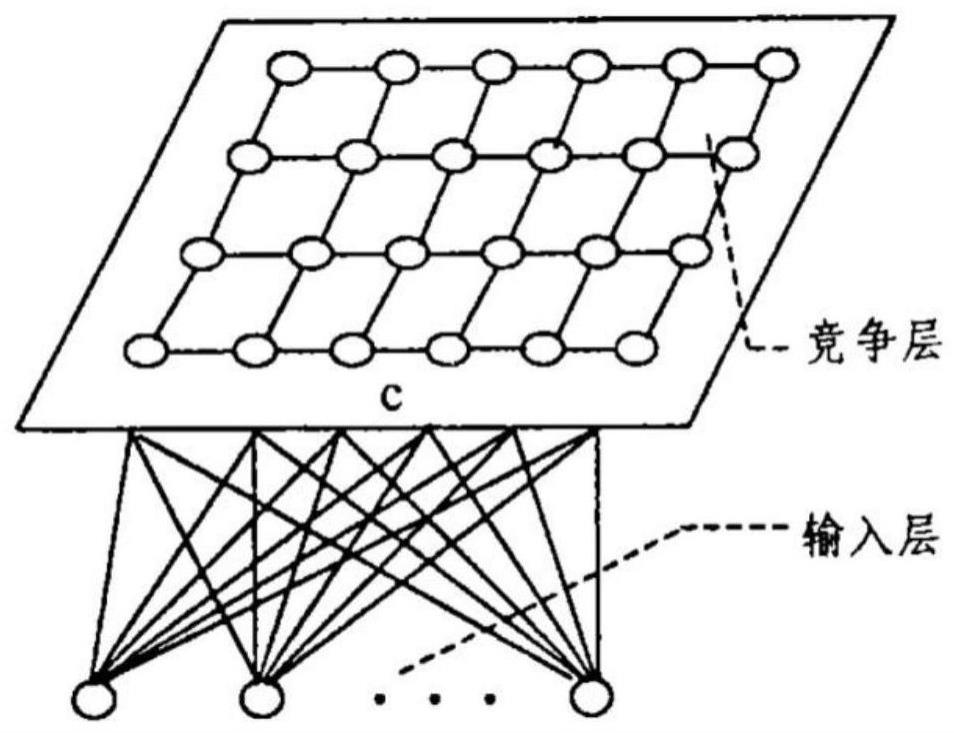
本发明涉及一种配电系统电压控制优化方法。
背景技术:
1、随着分布式可再生能源(der,如光伏发电以及风力发电等)在分布式系统中的渗透率不断提高,可再生能源输出功率的波动性和不确定性对配电系统运营商(dso)将电压维持在规定范围内提出了更大的挑战,这导致迫切需要研究更为先进的电压/无功控制(vvc)算法。
2、传统上,局部自动控制模型仅在使用局部电压测量方法来减轻电压偏差的情况中被广泛应用。这些模型中最成熟的是下垂控制,它可以根据ieee 1547-2018标准进行实现。然而,下垂控制可能导致不可行的电压分布和无功资源的利用不足,特别是当电压或无功限制放宽时。此外,配电网中接入的可控装置越来越稀疏,使得局部电压调节方法更难以达到全局电压偏差最小化的目标。因此,有必要提出基于最优潮流(opf)模型的全局优化模型。根据优化时间尺度的不同,基于最优潮流的电压/无功控制(vvc)算法可分为单时间尺度控制和多时间尺度控制两大类。单时间尺度模型主要关注具有短时间尺度响应特性的电力电子调压设备的协调,如光伏逆变器和静态无功补偿器(svc)。为了进一步实现在线或实时控制策略,有研究者采用梯度映射法、双上升法和广义快速双上升法设计基于局部测量信息的电压控制算法。
3、然而,局部逆变器的无功控制可能会增加有载调压变压器(oltc)触发分接变换的次数,甚至对其他电压调节装置产生不利影响。传统的控制装置通常寿命有限,响应速度慢,按小时控制。因此,它们不能有效地处理由于分布式可再生能源(der)功率的快速变化引起的快速电压波动。而具有快速性和灵活性的光伏逆变器是理想的电压调节装置,可用于以分钟为单位参与实时优化。
4、在此背景下,迫切需要一种合理的电压管理方法,有效地协调机械和电力电子设备不同响应速度和特性的调压装置,从而挖掘多个设备在多个时间尺度上共同控制电压的潜力。为了有效协调配电系统中具有不同时标响应特性的调压设备,提出了一种多时标电压模型。有文献提出,两级电压控制模型没有改变单时间尺度调节的本质。在此基础上,有文献提出分别在长时间尺度和短时间尺度上求解有载调压变压器(oltc)和逆变器连续无功补偿等离散变量。
5、上述基于最优潮流(opf)的电压/无功控制(vvc)算法中固有的两个缺点是:(1)潮流约束的非凸性。常用二阶锥松弛法、半正定松弛法、忽略功率损耗的线性化潮流模型、利用敏感因子矩阵对作用点处的潮流方程进行线性化等方法来表征潮流约束,但这些方法不可避免地会带来计算误差甚至是不可行的解。(2)不确定性变量建模。通过分别使用区间数或采样场景对不确定性进行建模,可以将电压/无功控制(vvc)模型转化为鲁棒优化模型或随机规划模型,这将带来计算误差或显著增加计算量的问题。
6、为了解决上述限制,最近的研究将深度强化学习(drl)应用于电压控制,并且drl已经成为上述基于模型方法的有效替代方案。深度强化学习的应用大致可以分为三类:应用于离散动作空间的算法、应用于连续动作空间的算法和应用于真实环境中多元智能体的算法。例如,应用深度q网络(deep q network,dqn)和dueling-dqn算法求解离散动作空间中的oltc和cbs策略。对于连续动作空间中的问题,有文献采用深度确定性策略梯度(deepdeterministic policy gradient,ddpg)算法来解决连续值动作问题,有效避免了离散化带来的误差。此外,为了处理实际应用中的多智能体合作,可以采用多智能体深度确定性策略梯度(maddpg)算法,并通过多智能体软演员评论家(masac)算法制定和求解多个子网络中的光伏逆变器调度情况。
技术实现思路
1、为了克服现有技术在深度强化学习(drl)算法在维数诅咒方面的问题,本发明针对配电网电压控制,提出了一种结合自组织映射神经网络的maddpg算法。
2、本发明采用自组织映射神经网络(som)来表示状态空间,保留输入数据的拓扑结构,通过自组织映射神经网络降低输入空间的维数,逼近逐渐变化的空间,结合maddpg算法使智能体能够高效地学习最优策略,同时还可以减轻维数诅咒的影响。通过自组织映射神经网络的降维处理大大提升了maddpg算法的训练学习效率,并对配电网中的调压设备的运行策略进行了优化,在保证配电网电压控制算法效果的同时,对现有的深度强化学习算法进行了优化提升。
3、为了实现上述目的,本发明的技术方案为:
4、一种基于模型辅助的深度强化学习算法的分布式电网电压控制方法,包括以下步骤:
5、s1:构建配电网实时电压控制模型框架;
6、s2:对电压控制问题进行数学建模,明确优化模型中的变量在深度强化学习算法中所对应的变量,将数学优化模型转化为马尔科夫决策过程。
7、s3:考虑深度强化学习算法的维数诅咒,采用自组织神经网络映射算法对强化学习算法进行优化。
8、s4:明确深度强化学习网络的训练方法,以及与自组织神经网络映射算法的结合应用。
9、s5:以一天24小时为周期,在ieee 33配电网母线基准系统上进行数值测试。构建基于ieee 33配电系统网络用于电压控制测试,在装有maddpg测试环境下的pycharm软件上调用搭建好的优化模型进行求解。
10、进一步,在所述步骤s1中,构建实时电压控制模型框架的具体过程包括:
11、s1-1:采用maddpg算法作为实时电压控制模型的主要框架,以最优的oltc和cbs的档位配置为基础,明确一个运行日内每个小时的档位情况,并作为算法框架中状态输入的一部分。
12、s1-2:在运行日每个小时内将时间段划分为n个时间间隔。在当前时间间隔内,结合状态空间中oltc和cbs的最优档位状态信息,对光伏逆变器进行无功调节。从而控制电压的快速波动,实现有效的电压调节。
13、进一步,在所述步骤s2中,电压控制数学优化模型与深度强化学习算法中马尔科夫三元组的具体定义如下:
14、配电网潮流模型是算法环境的一个重要组成部分,配电系统的运行状态可以通过潮流计算获得,通过求解潮流模型可产生大量系统数据以供训练,该模型可以表示为:
15、
16、pi=pres,i-pl,i (2)
17、qi=qres,i+qcbs,i-ql,i (3)
18、式中,ω表示配电网中所有分支机构的集合;i和j分别为支路ij的输入节点和输出节点;pij、qij表示支路ij的有功功率和无功功率;pi和qi分别为节点i注入的有功功率和无功功率;zij和bij分别为支路ij的电阻和电抗;δij为节点i与j之间的相角差;pres,i为节点i处可再生能源发电机组注入的有功功率;qres,i和qcbs,i分别为节点i处可再生能源发电机组和cb注入的无功功率;pl,i和ql,i分别为节点i处负荷的有功功率和无功功率;vi是节点i的电压幅值。
19、电压控制模型基于已知的oltc和cbs在t时段的状态,求解光伏逆变器在每个时间间隔内的最优输出策略;为便于描述,在后续建模过程中将省去下标t;这样,当前时刻的电压控制模型可以描述为:
20、
21、subjectto.(1)-(3)
22、qg(i,τ)=qpv,i,τ (5)
23、
24、式中,m为配电系统的母线节点个数;v0为标准电压;为安装在母线i上的光伏逆变器产生的无功功率上限;qpv,i,τ是安装在母线i上的光伏逆变器在时间τ时产生的无功功率;
25、将多个光伏逆变器的调度问题描述为马尔可夫决策过程;在马尔可夫决策过程中(mdp),将每个逆变器建模为一个智能体,通过多个智能体的协作实现电压控制;马尔科夫决策过程(mdp)是一个五元组<s,a,p,r,γ>,其主要组成成分包括状态空间、动作空间、奖励函数;
26、s2-2:状态空间:包括学习环境中所有光伏智能体的观测状态;因此,时间τ时的状态oτ可以用式(7)来描述:
27、oτ={ot,1,oτ,2,…,oτ,k} (7)
28、oτ,k={pτ,k,soltc,scbs,pl} (8)
29、式中pτ,k为第k个光伏智能体在τ时刻的输出;soltc表示当前时间段下oltc的档位状态;scbs表示当前时间段下cbs的档位状态;pl为负载的有功功率;
30、s2-3:动作空间:马尔科夫过程中的动作为光伏逆变器的无功功率,该无功功率是一个连续变量,第k个光伏智能体在时刻τ的作用表示为aτ,k=qτ,k;
31、s2-4:奖励函数:以第k个光伏智能体为例;第k个光伏智能体在时刻τ的奖励rτ,k包含对电压偏差违规的惩罚rτ(即优化模型的目标函数)和系统运行约束γτ,可表示为:
32、rτ=rτ+γτ (9)
33、电压偏差损失rτ表示全局电压偏差,由式(10)得到:
34、
35、式中,ζ0为电压偏离标准电压的惩罚系数;
36、电压管理模型的违规处罚分为逆变器无功补偿违规处罚γ1和电压违规处罚γ2;当时,γ1是一个绝对值很大的负数;电压违规处罚γ2表示为式(11):
37、
38、式中|*|+表示正函数;ζ1为母线电压超过给定上下限且满足|ζ1|>>|ζ0|的惩罚系数。
39、进一步,在所述步骤s3中,深度强化学习在维数诅咒方面的改进措施,具体包括:
40、s3-1:自组织映射神经网络;
41、自组织映射神经网络可以将高维或连续输入的数据映射到一维或二维空间中,在其拓扑结构中,一个节点就是一个簇;自组织映射神经网络通过使神经元的权重越来越接近输入向量来执行无监督训练;首先,初始化神经网络中神经元的权值;然后从数据集中随机采样作为网络的输入向量;该网络计算每个神经元和输入向量之间的欧氏距离,距离计算公式如下:
42、
43、式中:n为网络神经元数量;神经网络中距离最小的神经元称为最优匹配神经元(bmus),可以用神经网络节点来表征输入向量;自组织映射神经网络不仅需要计算距离,还需要使神经元尽可能靠近输入向量;也就是说,神经元的权重不断更新,使距离变小;同时,bmu附近的神经元也被修改,使它们更接近输入向量,这样节点就不断地“拉动”神经网络;
44、s3-2:自组织映射神经网络的训练与更新;
45、为了达到使自组织神经网络能够更好地拟合输入向量的目的,需要了解相邻神经元的半径,即神经元的更新模式;自组织映射神经网络中神经元的半径在训练开始时较大,随着训练时间的增加而逐渐减小,半径的计算公式如下:
46、
47、λ=k/σ0 (14)
48、式中:t为当前时间,σ0为网络的初始半径,k为迭代次数;该公式采用指数衰减法,使半径随着训练的增加而减小,从而达到目标;半径确定后,对范围内的所有神经元进行权值更新;神经元离bmu越近,更新幅度越大,更新公式为:
49、w(t+1)=w(t)=θ(t)l(t)(i(t)-w(t)) (15)
50、
51、
52、式中:l(t)为学习率,类似于半径计算公式采用指数递减,随着训练迭代逐渐减小;距离bmu越近,distbmu越小,该值越接近1,说明神经元的权值更新变化越大;经过多次训练迭代,自组织映射神经网络上的神经元可以表示输入向量的拓扑结构。
53、进一步,在所述步骤s4中,结合自组织映射神经网络的深度强化学习算法训练过程具体包括:
54、s4-1:som-maddpg的结合使用;
55、将maddpg算法与自组织映射神经网络相结合,将已有的状态空间数据输入到自组织映射神经网络中进行离线训练;从而确定自组织映射神经网络中每个神经元的权值向量,然后将神经元权值作为新的状态输入数据,用于后续的maddpg训练;无论输入参数的数量是多少,智能体都能学习到与自组织映射神经网络网络中神经元数量相同的状态;因此,在高维状态定义中能显著降低状态复杂性;
56、s4-2:som-maddpg的训练过程;
57、在som-maddpg训练模型中,reply buffer遍历环境中所有可能的状态,并将这些数据作为自组织映射神经网络离线训练的样本;自组织映射神经网络训练并找到与样本数据欧几里德距离最小的神经元作为最佳匹配单元(bmu);每个bmu都可以代表一类数据,因此可以将bmu的权值向量作为maddpg训练的输入状态,大大减小了状态大小;
58、并且maddpg算法的神经网络训练过程与ddpg算法相同;每个智能体由演员家网络、评论家网络、目标演员家网络和目标评论家网络四个神经网络组成,分别用θμ、θq、θμ′和θq′表示;每个智能体使用ddpg算法来学习最佳策略;
59、s4-3:som-maddpg算法的更新方法;
60、评论家网络参数的更新方法具体如下:
61、演员家网络的参数需要借助由演员家网络和探测噪声得到的控制策略的梯度不断更新;
62、at,τ,k=μ(wt,τ,k|θμ)+θt (18)
63、μ(wt,τ,k|θμ)=arg maxμjπ(μ|wt,τ,k,θμ) (19)
64、其中wt,τ,k为新的当前状态,θt为探测噪声;进入当前状态,光伏智能体根据演员家网络和探索噪声选择动作;光伏智能体神经网络在训练过程中需要其他智能体的动作信息作为辅助,从而实现多个智能体之间的交互与协作;因此,光伏智能体评论家网络的输入动作为光伏智能体动作与其他智能体动作的集合;
65、
66、式中,n为样本量;
67、maddpg算法采用软更新的方法;它赋予目标网络和原始网络相同的权值,并在每一步更新目标演员家网络和目标评论家网络的参数;更新方法如下:
68、
69、其中α是更新因子;
70、以配电网模型作为算法的环境进行仿真,将oltc和cbs的最优档位策略作为算法状态空间的一部分进行输入,并结合自组织映射神经网络进行学习优化,是本算法的整体工作流程。
71、进一步,在所述步骤s5中,在ieee 33母线基准系统上进行数值计算,通过python进行优化求解,并分析所提方法的有效性与可靠性:
72、s5-1:构建求解工具;
73、使用anaconda3对算法环境进行配置,配置的虚拟环境中需要装有tensorflow、pytorch以及maddpg环境包等,在配置好虚拟环境的pycharm软件平台中编程,优化计算是在装有intel(r)core(tm)i5-7200u cpu@2.50ghz处理器和8gb ram的pc上执行的,软件环境为windows10操作系统;
74、s5-2:设置优化方案与指标;
75、为清楚对比文中所搭建算法模型对配电网电压波动所起到的效用,设置两种方案进行对比观察:(1)不加任何优化的maddpg算法(2)结合som的分布式maddpg算法。
76、根据所考虑的量化分析指标,对两种方案下算法的奖励收敛情况、配电网整体的电压波动进行分析:(1)深度强化学习算法的奖励收敛情况;(2)配电网中各节点的电压波动情况。
77、本发明的工作原理是:
78、1.综合考虑配电网设备情况,建立配电网电压控制模型框架。
79、2.建立配电系统电压控制数学优化模型,将该优化模型转化为马尔科夫决策过程的三元组,明确深度强化学习中的状态、动作与奖励的定义。
80、3.分析现有深度强化学习算法的缺陷,通过自组织映射神经网络的方法对现有深度强化学习算法进行优化提升。
81、4.将自组织映射神经网络模型与深度强化学习算法进行结合应用,构建优化提升后的算法训练模型。
82、5.所提深度强化学习算法可以结合oltc、cbs的档位设定,对光伏逆变器的无功出力进行有效调节,达到缓解配电系统电压波动和电压越限等问题的目的,并通过自组织映射神经网络对深度强化学习算法的训练效率进行提升优化。
83、本发明的优点是:
84、1.能够有效减轻新能源渗透率较高的配电系统中频繁出现的电压越限和电压波动等问题。
85、2.将光伏逆变器优化化为马尔可夫博弈过程,采用maddpg算法求解,充分考虑智能逆变器在快时间尺度下的协同控制行为。并根据数据驱动代理模型计算出的奖励信号,指引深度强化学习的训练方向,有效调节光伏逆变器的无功输出,实现在线电压管理。
86、3.使用自组织映射神经网络来表示状态空间,保留了输入数据的拓扑结构。同时,通过自组织映射神经网络降低输入空间的维数,逼近逐渐变化的空间,利用maddpg算法使智能体能够高效地学习最优策略,还可以减轻维数爆炸问题的影响。
87、4.通过将自组织映射神经网络与深度强化学习算法结合到一起,提升了算法的训练效率,同时也保证了算法的有效性,能够有效的缓解电压越限等问题。
- 还没有人留言评论。精彩留言会获得点赞!