一种高性能混凝土配比数据处理方法与流程
本发明涉及数据处理,具体涉及一种高性能混凝土配比数据处理方法。
背景技术:
1、随着人们生活水平的提高,对居住品质的要求日渐严苛,对于房屋的质量以及施工材料也提出了更高的要求,因此高性能的混凝土被逐步应用于建筑行业,其与普通的混凝土相比,制作工艺更加复杂且施工过程更加讲究科学性;不仅需要根据工作要求合理选择原材料,还需要按照一定的比例把原材料混合起来,高性能混凝土是建筑物的框架承载着整个建筑物的重量;因此必须具有强度高的特征,而其配比工艺在一定程度上决定了混凝土的强度和建筑物的质量。
2、在高性能混凝土生产的过程中需要做大量的配比试验从而进行最优外加剂用量以及粉煤灰用量的选择;而该过程中往往会产生大量的试验数据,生产平台对试验数据进行存储时会浪费大量的存储空间以及降低记录时效。因此,在对试验数据进行存储前进行数据压缩处理就显得尤为重要。但是传统的游程编码压缩算法,对数值不同但是较为接近的冗余数据的压缩效果较差。
技术实现思路
1、为了解决现有的压缩算法对数值不同但是较为接近的冗余数据的压缩效果较差的技术问题,本发明的目的在于提供一种高性能混凝土配比数据处理方法,所采用的技术方案具体如下:
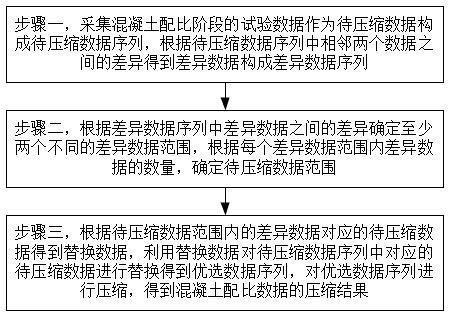
2、采集混凝土配比阶段的试验数据作为待压缩数据构成待压缩数据序列,根据待压缩数据序列中相邻两个数据之间的差异得到差异数据构成差异数据序列;
3、根据差异数据序列中差异数据之间的差异确定至少两个不同的差异数据范围,根据每个差异数据范围内差异数据的数量,确定待压缩数据范围;
4、根据待压缩数据范围内的差异数据对应的待压缩数据得到替换数据,利用替换数据对待压缩数据序列中对应的待压缩数据进行替换得到优选数据序列,对优选数据序列进行压缩,得到混凝土配比数据的压缩结果。
5、优选地,所述根据每个差异数据范围内差异数据的数量,确定待压缩数据范围,具体包括:
6、对于任意一个差异数据范围,将该差异数据范围内的任意一个差异数据记为目标差异数据,将目标差异数据出现的频次记为目标差异数据的特征数量;
7、将该差异数据范围内所有差异数据的特征数量的均值与差异数据序列中所有差异数据的特征数量的均值之间的差值作为该差异数据范围的特征评价指标;
8、根据差异数据范围的特征评价指标对差异数据范围进行筛选,得到待压缩数据范围。
9、优选地,所述根据差异数据范围的特征评价指标对差异数据范围进行筛选,得到待压缩数据范围,具体包括:
10、将特征评价指标大于预设的评价阈值对应的差异数据范围记为待压缩数据范围。
11、优选地,所述根据差异数据序列中差异数据之间的差异确定至少两个不同的差异数据范围具体为:
12、将差异数据序列中所有差异数据按照设定顺序进行排列得到排列数据序列,根据排列数据序列中相邻两个差异数据之间的差异确定数据分割长度;
13、将差异数据序列中差异数据的最大值作为全局数据范围的上限,将差异数据序列中差异数据的最小值作为全局数据范围的下限;
14、利用数据分割长度将全局数据范围划分为至少两个不同的差异数据范围。
15、优选地,所述根据排列数据序列中相邻两个差异数据之间的差异确定数据分割长度具体为:
16、对于排列数据序列中任意相邻的两个差异数据,将相邻的两个差异数据中的较大值与相邻的两个差异数据中的较小值之间的差值作为特征差值;获取排列数据序列中所有特征差值的最大值记为数据分割长度。
17、优选地,所述根据待压缩数据序列中相邻两个数据之间的差异得到差异数据构成差异数据序列具体为:
18、对于待压缩数据序列中任意相邻两个待压缩数据,将两个待压缩数据之间的差值作为差异数据;将待压缩数据序列中所有的差异数据构成差异数据序列。
19、优选地,所述根据待压缩数据范围内的差异数据对应的待压缩数据得到替换数据具体为:
20、对于任意一个待压缩数据范围,计算该待压缩数据范围内所有差异数据对应的待压缩数据的均值,得到对应待压缩数据的替换数据。
21、优选地,所述采集混凝土配比阶段的试验数据作为待压缩数据构成待压缩数据序列具体为:
22、采集相同原材料下粉煤灰掺量不同时在不同天数下混凝土的抗压强度数据;
23、对于任意一种天数,将混凝土的抗压强度数据按照对应的粉煤灰掺量从小到大的顺序进行排列,构成该天数对应的待压缩子序列;将所有种天数对应的待压缩子序列,按照天数从小到大的顺序进行排列,得到待压缩数据序列。
24、本发明实施例至少具有如下有益效果:
25、本发明首先采集混凝土配比阶段的试验数据作为待压缩数据,将待压缩数据构成待压缩数据序列,进而分析待压缩数据序列中相邻两个数据之间的差异情况,获得差异数据构成差异数据序列,后续基于差异数据序列进行分析筛选出可以进行有损压缩的待压缩数据,以提高数据的冗余程度,使得数据压缩效果更好。然后,根据差异数据序列中差异数据之间的差异确定了所有差异数据的数值的不同范围,即差异数据范围,并对差异数据范围内差异数据的数量进行分析,确定待压缩数据范围,通过差异数据的数量对差异数据范围进行筛选,确定进行有损压缩的必要性较高的差异数据范围,并记为待压缩数据范围;最终获取替换数据,利用替换数据对待压缩数据进行替换得到优选数据序列,即利用替换数据对对应的待压缩数据进行有损处理,以提高优选数据序列中数据之间的冗余程度,提高压缩效率,获得压缩效果较佳的混凝土配比数据的压缩结果。
技术特征:
1.一种高性能混凝土配比数据处理方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种高性能混凝土配比数据处理方法,其特征在于,所述根据每个差异数据范围内差异数据的数量,确定待压缩数据范围,具体包括:
3.根据权利要求2所述的一种高性能混凝土配比数据处理方法,其特征在于,所述根据差异数据范围的特征评价指标对差异数据范围进行筛选,得到待压缩数据范围,具体包括:
4.根据权利要求1所述的一种高性能混凝土配比数据处理方法,其特征在于,所述根据差异数据序列中差异数据之间的差异确定至少两个不同的差异数据范围具体为:
5.根据权利要求4所述的一种高性能混凝土配比数据处理方法,其特征在于,所述根据排列数据序列中相邻两个差异数据之间的差异确定数据分割长度具体为:
6.根据权利要求1所述的一种高性能混凝土配比数据处理方法,其特征在于,所述根据待压缩数据序列中相邻两个数据之间的差异得到差异数据构成差异数据序列具体为:
7.根据权利要求1所述的一种高性能混凝土配比数据处理方法,其特征在于,所述根据待压缩数据范围内的差异数据对应的待压缩数据得到替换数据具体为:
8.根据权利要求1所述的一种高性能混凝土配比数据处理方法,其特征在于,所述采集混凝土配比阶段的试验数据作为待压缩数据构成待压缩数据序列具体为:
技术总结
本发明涉及数据处理技术领域,具体涉及一种高性能混凝土配比数据处理方法,该方法包括:采集混凝土配比阶段的试验数据作为待压缩数据构成待压缩数据序列,根据待压缩数据序列中相邻两个数据之间的差异得到差异数据构成差异数据序列;根据差异数据序列中差异数据之间的差异确定差异数据范围,根据每个差异数据范围内差异数据的数量确定待压缩数据范围;根据待压缩数据范围内的差异数据对应的待压缩数据得到替换数据,利用替换数据对待压缩数据进行替换得到优选数据序列,对优选数据序列进行压缩得到混凝土配比数据的压缩结果。本发明解决了现有的压缩算法的压缩效果较差的问题,能够获得压缩效果较佳的数据压缩结果。
技术研发人员:吴大勇,段佑强,孙位蕊
受保护的技术使用者:菏泽鹏远混凝土有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!