一种基于分段的监控视频内容描述方法与流程
本发明涉及监控视频描述领域,具体地,涉及一种基于分段的监控视频内容描述方法。
背景技术:
随着以多媒体为代表的信息技术产业的突飞猛进,人们对生活和工作环境的安全性要求也在不断提高,监控设施越来越多地出现在各种公共场所。目前,视频监控系统已经涉及到了社会生活的各行各业,例如交通路口、超市、银行、车站和居民小区等,与此同时,在各种大型活动场所和重要保卫区域的警卫工作中也配置了许多监控设备,如奥运会场地、人民广场、世博园区等。
与此同时,由于海量监控视频数据的出现,完全依靠人工监看的传统视频监控系统已经不能满足需求,人们需要更智能化、自动化、自主化的视频监控系统,因此智能视频监控系统成为了提升视频监控系统效能的主要发展方向。
智能视频监控技术主要指的是自动地分析和抽取视频源中的关键信息。智能视频技术借助计算机强大的数据处理功能,对视频画面中的海量数据进行高速分析,过滤掉用户不关心的信息,仅仅为监控者提供有用的关键信息,最终实现集视频采集、视频分析及描述为一体的智能监控系统。
1.监控视频内容描述和检索方法
在智能视频监控系统中,如何利用计算机从海量的监控视频中快速地检索出用户需要的信息是当前监控领域急需解决的问题之一。
基于内容的视频检索方法(Content-Based Video Queries,CBVQ)目前已成为多媒体技术研究领域的热点,它突破了传统的基于文本检索技术的局限,直接对视频的内容进行分析,抽取特征和语义,利用这些内容特征建立索引并进行检索,提供了一种符合人类认知规律的高效检索方法。随着各种图像处理技术的进步,尤其是特征提取和目标分类算法的改进,基于内容的视频检索方法得到了广泛的应用,也能够很好地满足海量监控视频的检索需要。
为了能够有效地支持基于内容的监控视频检索,就需要通过视频建模将视频内容的描述信息有效地组织起来。通过对视频内容信息进行结构化的分层描述,在视频数据流之外产生一路视频数据的描述流,从而可以基于描述流进行高效检索和关联调阅,这将为海量视频的快速检索提供可行的解决方案。
2.监控视频内容的结构分段
视频分段是把视频流分割成一系列有意义、可管理的单元(例如镜头),由于视频监控设备通常为7×24小时不间断地采集视频数据,在生成视频内容的描述流前必须首先进行合理的结构分段,然后再提取每段视频的内容描述信息并实时输出,因此视频分段是视频分析与基于内容描述的第一步。
一般来讲,可将视频的结构自下而上地分为图像帧、镜头、场景、视频四个层次,以便在各个层次上对视频进行内容分析与描述:
1)视频:是由一系列静止图像在时间上的变化组成的,一般视频采样率为24~30帧/秒,也即每秒钟播放24~30幅图片,因此人们在观看视频时,会有运动的感觉;
2)图像帧:是视频结构中的最小单元,是视频中的一幅静止图像;
3)镜头:是一个视频片段,一般是指摄像机一次连续拍摄得到的画面;
4)场景:一般定义为在时间上连续、语义上相关的连续镜头集合。
在监控视频中,摄像头的位置通常很长时间不会发生改变,按照镜头来实现视频结构分段的方法一般情况下不适用于监控领域。
与此同时,在对监控视频的内容进行检索时,用户往往更加关注于其中出现的运动目标,因此现有的监控视频内容描述方法一般首先基于运动目标检测进行视频分段,即当检测到有运动目标进入或离开时,将视频分作一段。
3.基于MPEG-7的视频内容信息描述
根据MPEG-7中多媒体描述方案的定义,可以将对视频内容的描述分为结构信息描述和语义信息描述两类:
1)结构信息描述
在MPEG-7中,视频结构信息的描述是建立在对视频进行分段的基础上,使用片段描述方案来描述每一片段内的视频结构信息(包括颜色、纹理、形状、运动、声音等特征描述子)。根据定义,片段描述方案是一个抽象类型,按照分段规则的不同可以得到5个具体化的子类型:音频片段、视频片段、视听片段、运动区域以及静止区域。每种类型片段描述的详细特征属性(如图1所示),同时视频的分段描述具有递归性,即片段可以再被分为更小的片段,形成一棵层次树。
2)语义信息描述
在MPEG-7中,多媒体描述方案提供了对多媒体内容的语义描述方案,用来表示语义实体所对应的视频语义信息,例如对象、代理对象、事件、概念、语义状态、语义空间、语义时间、属性和语义实体之间的关系等。语义描述方案从现实世界语义和概念的角度描述视听内容,它强调现实世界里的事件、对象、时间、地点和抽象,它包括事件描述方案,对象描述方案,语义时间描述方案,语义地点描述方案等。
4.现有基于分段的监控视频内容描述方案的不足:
1)单个目标的描述信息被分为了若干段,不便于检索:由于现有的监控视频内容描述方法一般是基于运动目标检测来实现的,因此当检测到有运动目标进入或离开时,就会对视频进行分段,然后直接对该视频段进行描述。而某个目标从出现到结束的整个时间间隔内,可能有其他目标进入或者离开,这将导致该目标的描述信息分成若干部分,若用户在检索时需要查找某一目标的描述信息时,将很难得到一份完整的目标描述信息。
2)难以处理长时间无运动目标出现或者目标数目过多的情况:在现有的监控视频内容描述方法中,长时间无运动目标出现会导致视频无法正常地进行分段和描述。与此同时,若视频中出现的目标数目过多,将会导致视频分段过于频繁,从而失去视频分段对层次化结构描述的意义。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于分段的监控视频内容描述方法,能够更好地适应于用户对视频中感兴趣运动目标的检索,为后期的海量监控视频信息的存储和检索提供有效支持。
本发明提供一种基于分段的监控视频内容描述方法,该方法为包括检测运动目标并提取其底层特征、视频分段、基于上述分段准则对视频内容信息进行描述、基于上述描述信息流进行目标检索,具体包括如下步骤:
步骤一、检测运动目标并提取其底层特征:针对监控视频检索过程中用户通常更关注运动目标的特点,首先检测视频中出现的运动目标,并对检测到的目标作实时地跟踪,在跟踪过程中,利用当前帧所检测到的运动目标位置对跟踪结果进行修正,与此同时根据MPEG-7标准提供的相关算法,逐帧提取运动目标的颜色、纹理、形状以及空间位置等底层特征,并保存在该目标的相应缓存中;
步骤二、视频分段:视频分段由相应的起始帧和结束帧确定,首先将输入视频序列的第一帧作为当前视频段的起始帧,然后当检测到监控视频中有运动目标进入或者离开时,将视频的上一帧作为当前视频段的结束帧,则当前视频段结束,实时地生成该视频段的内容描述信息,并封装成IP包发送,同时将视频的当前帧作为新视频段的起始帧,每个视频段的目标数目在其分段间隔内保持不变,且各段之间不存在交叉重叠;若检测到某一运动目标离开,还需要实时地生成相应目标的内容描述信息,并封装成IP包发送。
步骤三、基于上述分段准则对视频内容信息进行描述:在一视频段结束时实时地将该视频段的内容描述信息,并按照固定的格式形成XML描述流打包输出,同时释放相应信息所在缓存;在检测到一目标离开视频,实时地将该目标的描述信息按照固定的格式形成XML描述流打包输出,同时释放相应信息所在缓存;为了减少描述信息的冗余,目标的底层特征描述信息为该目标单帧提取的底层特征的统计值;
步骤四、基于上述描述信息流进行目标检索:输入目标类别关键词如行人、小轿车,利用目标的类别描述信息找到相应目标,同时输入颜色或其他特征关键词如白色的小轿车,结合目标的底层特征描述信息进行检索,找到相应目标后,将目标的起始结束帧信息和相应视频段ID作为检索结果返回。
优选地,在步骤一中,检测视频中出现的运动目标,是利用混合高斯模型对背景进行建模,以此找到每一帧中与背景不同的运动目标(前景),并保存每个目标的位置信息。
优选地,在步骤一中,对检测到的目标作实时地跟踪,是当检测到新目标后,利用新目标的位置信息对跟踪作初始化,然后采用轮廓跟踪、均值漂移、粒子滤波等跟踪算法对该目标进行跟踪,并返回目标在每一帧的位置信息;在跟踪过程中利用相应的运动目标检测结果,即当前帧中所有运动目标的位置信息,对不准确的跟踪结果进行修正。
优选地,在步骤二中,视频段的内容描述信息包括视频段的ID、视频段的起始帧和结束帧序列号、各个目标之间的空间关系;目标的内容描述信息包括:目标的类别和ID、目标的起始帧和结束帧序列号、目标的底层特征以及相应视频分段ID集合。
优选地,在步骤三中,视频段的内容描述信息按照固定的格式形成XML描述流,是利用XML语言来描述视频段中各项内容信息,形成一个固定结构的层次化内容描述框架,即在任意一个视频段元素中,包含视频段ID(属性),视频段的起始帧和结束帧序列号(属性)以及各个目标之间的空间关系(子元素)。
更优选地,各个目标之间的空间关系,是通过对各个目标之间的空间关系进行逐帧分析,判断空间关系在时间域的变化情况并直接对其进行描述,以减少空间关系描述信息的冗余。
优选地,在步骤三中,视频目标的描述信息按照固定的格式形成XML描述流,是利用XML语言来描述视频目标的各项内容信息,形成一个固定结构的层次化内容描述框架,即在任意一个视频目标元素中,包含目标的类别和ID(属性)、目标的起始帧和结束帧序列号(属性)、目标的底层特征(子元素)以及相应视频段ID集合(子元素)。
更优选地,目标的起始帧和结束帧序列号,是将目标出现在视频的第一帧提前若干帧数作为目标的开始帧,同时将目标的最后一帧推迟若干帧数作为目标的结束帧;若干帧数是指预先设定的误差允许范围,以保证所得到描述包含一个运动目标的完整信息,例如取作10帧。
更优选地,目标的底层特征描述信息,是该目标单帧提取的底层特征的统计值,是通过对运动目标单帧提取的特征值(颜色、纹理和形状)作均值滤波或中值滤波,获得每个运动目标底层特征的统计值,同时通过多项式曲线拟合的方法生成目标的运动轨迹,即基于目标在每一帧的空间位置的二维坐标进行一次拟合或者二次拟合,输出拟合曲线的参数值。
更优选地,相应视频段ID集合,是在某个目标出现的时间间隔内,包含若干个视频段,通过ID索引到相应视频段,以及相关的视频段内容描述信息。
在上述基于分段的监控视频内容描述方法的基础上,进一步提供了在特殊情况下的改进措施,包括:
1)针对某些监控视频中长时间未出现运动目标而导致视频流无法正常分段的问题,采用按照时间进行分段的策略,即通过时间准则进行分段,对视频段设置一个帧数上限,对于超过一定帧数的视频流进行强制分段,避免出现长时间无分段的情况;
2)针对某些监控视频中运动目标过多而导致难以全部检测并以此完成视频分段的问题,采用选择性分段的策略,即根据特定的运动目标进行分段,选择用户感兴趣的运动目标。
本发明首先对输入的监控视频进行实时的运动目标检测和跟踪,并基于MPEG-7标准提取出每一帧内所有目标的属性特征。根据当前视频内容描述方法在监控领域的不足,针对监控视频检索过程中用户通常更加关注于某些感兴趣运动目标的特点,将视频的描述流信息按照目标和视频段进行输出,当检测到视频中有运动目标进入或者离开时,则当前视频段结束,可以实时地按照固定的格式输出该分段的内容描述信息,若检测到某一运动目标离开,还需要实时地输出相应目标的内容描述信息。在目标描述中,通过视频段ID集合可以索引到相应视频段,以及相关的视频段内容描述信息。
与现有技术相比,本发明具有如下有益的改进效果:
1)针对监控视频检索过程中用户通常更加关注于某些感兴趣运动目标的特点,基于运动目标的出现和离开对视频进行分段,同时将视频的描述流信息按照目标和视频段进行输出,当检测到视频中有运动目标进入或者离开时,则当前视频段结束,并实时输出该视频段的内容描述信息,若检测到某一运动目标离开,还需要实时地输出相应目标的内容描述信息;在目标描述中,通过视频段ID集合可以索引到相应视频段,以及相关的视频段内容描述信息。
2)提供了在某些特殊情况下的改进措施,针对某些监控视频中长时间未出现运动目标而导致视频流无法正常分段的问题,采用按照时间进行分段的策略,即通过时间准则进行分段;与此同时,针对某些监控视频中运动目标过多而导致难以全部检测并以此完成视频分段的问题,采用选择性分段的策略,即根据特定的运动目标进行分段。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明一实施例基于MPEG-7标准的各种片段的内容描述信息;
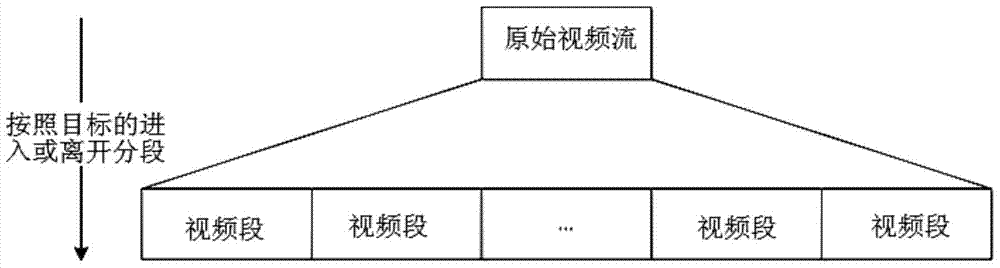
图2为本发明一实施例视频分段示意图;
图3为本发明一实施例单个视频段的描述文档示意图;
图4为本发明一实施例单个目标的描述文档示意图;
图5为本发明一实施例具体实验中第240帧检测到的运动目标示意图;
图6为本发明一实施例具体实验中自行车1和行人1的进入和离开示意图;
图7为本发明一实施例具体实验中视频分段示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
本实施例针对一段实际环境中拍摄的监控视频序列,采用本发明中所提出的基于分段的监控视频内容描述方法,以Visual Studio2010作为测试平台,并使用OpenCV、tinyxml等工具包。
如图1所示,为本实施例基于MPEG-7标准的各种片段的内容描述信息,例如静止区域的描述主要包含该区域的颜色、纹理和形状特征,而运动区域的描述还包含了时间和运动等描述信息。
如图2所示,为本实施例视频分段示意图,将原始视频流按照运动目标的进入或者离开进行分段。
如图3所示,为本实施例单个视频段的描述文档示意图,其利用XML语言来描述视频段中各项内容信息,形成一个固定结构的层次化内容描述框架,即在任意一个视频段元素中,包含视频段ID(属性),视频段的起始帧和结束帧序列号(属性)以及各个目标之间的空间关系(子元素)。
如图4所示,为本实施例单个目标的描述文档示意图,其利用XML语言来描述视频目标的各项内容信息,形成一个固定结构的层次化内容描述框架,即在任意一个视频目标元素中,包含目标的类别和ID(属性)、目标的起始帧和结束帧序列号(属性)、目标的底层特征(子元素)以及相应视频段ID集合(子元素),其中:目标的底层特征描述包括对运动目标的颜色、纹理、形状和运动轨迹的描述。
本实施例方法具体包括如下步骤:
步骤一、首先检测视频中出现的运动目标,并对检测到的目标作实时跟踪,同时逐帧对所有运动目标作底层特征提取,如在第240帧中检测到行人1和自行车1,如图5所示,每个目标可提取如下底层特征(以颜色特征为例):
1)主颜色(Dominant Color):记作DDC={{Ci,Pi,Vi},S},其中S表示各个主颜色之间的全局空间相似性,Ci表示第i个主颜色的具体值,Pi表示第i个主颜色的比例,Vi表示第i个主颜色的方差;
2)可伸缩颜色(Scalable Color):记作DSC={Num1,Num2,{Coefi}},其中Numi表示颜色直方图作Harr变换后保留的系数个数,Num2表示二进制传输时舍弃的比特数,Coefi表示第i个Harr变换系数(共计Num1个);
3)颜色结构(Color Structure):记作DCS={{Valuei}},其中Valuei表示第i个特征值(共计64个);
4)颜色分布(Color layout):记作DCL={{YCoefi},{CbCoefi},{CrCoefi}},其中YCoefi表示第i个Y分量系数(共计64个),CbCoefi表示第i个Cb分量系数(共计28个),CrCoefi表示第i个Cr分量系数(共计28个)。
步骤二、视频分段由相应的起始帧和结束帧确定,首先将输入视频序列的第一帧作为当前视频段的起始帧,然后每当检测到监控视频中有运动目标进入或者离开时,将视频的上一帧作为当前视频段的结束帧,标志当前视频段结束;同时将视频的当前帧作为新视频段的起始帧。此时,每个视频段的目标数目在其分段间隔内保持不变,且各段之间不存在交叉重叠。
步骤三、当检测到视频中有运动目标进入或者离开时,则当前视频段结束,可以实时输出该视频段的内容描述信息,若检测到某一运动目标离开,还需要实时地输出相应目标的描述信息。
下面以行人1(运动目标)和自行车1(运动目标)的内容描述为例进行说明,检测到行人1在第234帧进入视频,在第305帧离开视频,在此期间自行车1在第238帧进入视频,在第297帧离开视频,如图6所示,根据分段准则可以得到三个视频段(如图7所示)。此时,行人1的内容描述信息包含其颜色、纹理、形状、运动轨迹等底层特征,其中颜色、纹理和形状的描述是通过对行人1单帧提取的特征值作均值滤波或中值滤波得到相应统计值,而运动轨迹则是通过找到行人1在视频中的若干个关键点,然后利用多项式拟合的方法得到相邻关键点之间的运动轨迹,所用的多项式拟合方法包括一次拟合和二次拟合两种;在行人1从出现到结束的时间范围内包含三个视频段,分别为视频段1、视频段2和视频段3;自行车1的内容描述信息基本上与行人1类似,在自行车1从出现到结束的时间范围内,包含一个视频段,即视频段2;而在视频段2的内容描述信息中包含了行人1和自行车1之间的空间关系变化情况,即由“行人1在自行车1的左边”变为“行人1在自行车1的右边”。
步骤四、基于上述描述信息流进行目标检索:可以输入目标类别关键词(如行人、小轿车等),利用目标的类别描述信息找到相应目标,也可以同时输入颜色等特征关键词(如白色的小轿车),结合目标的底层特征描述信息进行检索,找到相应目标后,将目标的起始结束帧信息和相应视频段ID作为检索结果返回。
本实施例所述一种基于分段的监控视频内容描述方法通过上述的具体步骤,解决了现有技术的不足,能够更好地适应于用户对视频中感兴趣运动目标的检索,为后期的海量监控视频信息的存储和检索提供有效支持。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!