一种通用射影自修复码的编码、数据重构和修复方法与流程
本发明涉及分布式网络存储领域,更具体地说,涉及一种通用射影自修复码的编码、数据重构和修复方法。
背景技术:
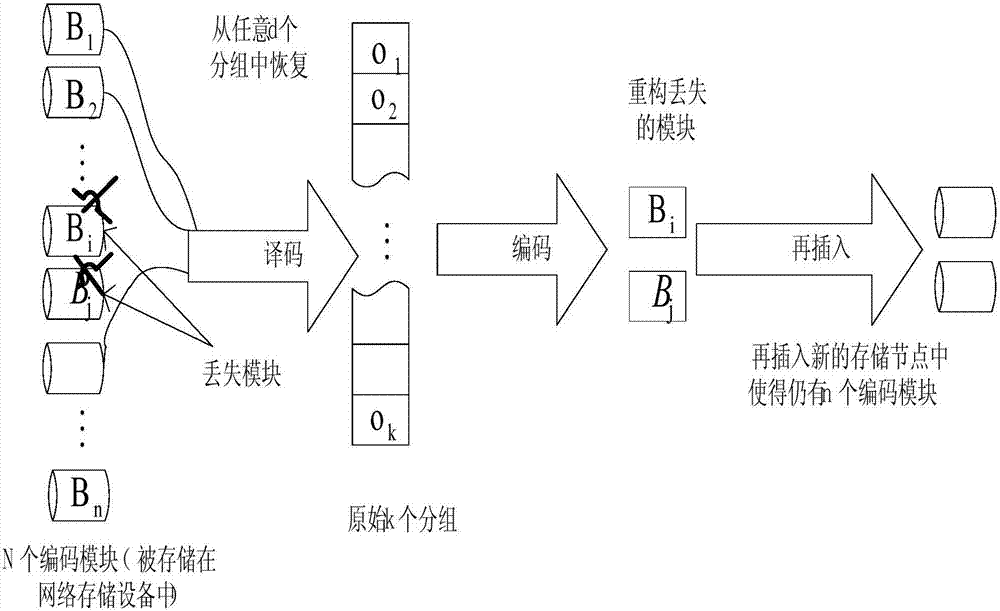
随着信息产生量的迅速增长,有效地存储海量数据的存储系统已经越来越重要。分布式存储系统以其高效的可扩展性和高可用性成为存储海量数据的有效系统。然而在分布式存储系统中,存储数据的存储节点是不可靠的。为了能够由不可靠的存储节点提供可靠的存储服务,需要在存储系统中引入冗余。引入冗余最简单的方法就是对原始数据直接备份,直接备份虽然简单但是其存储效率和系统可靠性不高,而通过编码引入冗余的方法可以提高其存储效率。在目前的存储系统中,编码方法一般采用MDS(MaximumDistanceSeparable最大距离可分离)码,MDS码可以达到存储空间效率的最佳,一个(n,k)MDS纠错码需要将一个原始文件分成k个大小相等的模块,并通过线性编码生成n个互不相关的编码模块,由n个节点存储不同的模块,并满足MDS属性(n个编码模块中任意k个就可重构原始文件)。这种编码技术在提供有效的网络存储冗余中占有重要的地位,特别适合存储大的文件以及档案数据备份应用。在分布式存储系统中,把大小为B的数据存储在n个存储节点中,每个存储节点存储的数据大小为α。数据接收者只需要连接并下载n个存储节点中的任意k个存储节点的数据即可恢复出原始数据B,这一过程称为数据重建过程。RS码是满足MDS码特性的一种码字。当存储系统中的存储节点失效时,为了保持存储系统的冗余量,需要恢复该失效节点存储的数据并将该数据存储在新节点中,该过程称为修复过程。然而,在修复过程中,RS码首先需要下载k个存储节点的数据并恢复出原始数据,之后为新节点编码出失效节点的存储数据。为了恢复一个存储节点的数据而解码出整个原始数据显然对传输带宽是一种浪费。然而,系统节点失效或者文件损耗,系统的冗余度会随着时间而逐渐减小,因此需要一种机制来保证系统的冗余。文献[R.RodriguesandB.Liskov,“HighAvailabilityinDHTs:ErasureCodingvs.Replication”,WorkshoponPeer-to-PeerSystems(IPTPS)2005.]中提出的EC(ErasureCodes纠错码)码,该码在存储开销上是比较有效的,然而支持冗余恢复所需要的通信开销也比较大。图1表示只要系统中有效节点数d≥k,就可以从现有节点中获得原始文件;图2表示恢复失效节点所存储内容的过程。从图1、图2中可以看出整个恢复过程是:1)首先从系统中的k个存储节点中下载数据并重构原始文件;2)由原始文件再重新编码出新的模块,存储在新节点上。该恢复过程表明修复任何一个失效节点所需要的网络负载至少为k个节点所存储的内容。同时,为了降低修复过程中所使用的带宽,文[A.G.Dimakis,P.G.Godfrey,M.J.Wainwright,K.Ramchandran,“Networkcodingfordistributedstoragesystems”,IEEEProc.INFOCOM,Anchorage,Alaska,May2007.]利用网络编码理论的思想提出了再生码(RGC,RegeneratingCodes),RGC码也满足MDS码特性。再生码的修复过程中,新节点需要在剩下的存储节点中连接d个存储节点并分别从这d个存储节点中下载β大小的数据,所以RGC码的修复带宽为dβ。同时给出了RGC码功能修复的模型并提出了RGC码的两类最佳码:最小存储再生码(MSR,Minimum-storageRegenerating)和最小修复带宽再生码(MBR,Minimum-bandwidthRegenerating)。RGC码的修复带宽优于RS码,但RGC的修复过程需要连接d(d>k)个存储节点(d称为修复节点)。另外,修复节点需要对其存储的数据执行随机线性网络编码操作。为了满足所有编码包是相互独立的,RGC码的运算需要在一个较大的有限域内。专利PCT/CN2012/071177中提出了一种RGC码,该方案中修复一个丢失的编码模块只需要一小部分的数据量,而不需要重构整个文件。RGC码应用线性网络编码思想,利用NC(NetworkCoding,网络编码)属性(即最大流最小割)来改善修复一个编码模块所需要的开销,从网络信息论上可以证明用和丢失模块相同数据量的网络开销就可修复丢失模块。RGC码主要思想还是利用MDS属性,当网络中一些存储节点失效,也就相当于存储数据丢失,需要从现有有效节点中下载信息来使得丢失的数据修复丢失的数据模块,并将其存储在新的节点上。随着时间的推移,很多原始节点可能都会失效,一些再生的新节点可以在自身再重新执行再生过程,继而生成更多的新节点。因此再生过程需要确保两点:1)失效的节点间是相互独立的,再生过程可以循环递推;2)任意k个节点就足够恢复原始文件。图3描述了当一个节点失效后的再生过程。分布式系统中n个存储节点各自存储α个数据,当有一个节点失效,新节点通过从其他d≥k个存活节点中下载数据来再生,每个节点的下载量为β,每个存储节点i通过一对节点Xiin,Xiout来表示,这对节点通过一个容量为该节点的存储量(即α)的边连接。再生过程通过一个信息流图描述,Xin从系统中任意d个可用节点中各自收集β个数据,通过在Xout中存储α个数据,任何一个接收者都可以访问Xout。从信源到信宿的最大信息流是由图中最小割集决定,当信宿要重构原始文件时,这个流的大小不能低于原始文件的大小。每个节点存储量α和再生一个节点所需要的带宽γ之间存在一个折中,因此又引入最小带宽再生码(MBR)和最小存储再生码(MSR)。对于最小存储点可以知道每个节点至少存储M/k比特,因此可推出MSR码中当d取最大值即一个新来者同时和所有存活的n-1个节点通信时,修复带宽γMSR最小即而MBR码拥有最小修复带宽,可以推出当d=n-1时,获得最小修复负载对于节点失效修复问题,考虑了三种修复模型:精确修复:失效的模块需要正确构造,恢复的信息和丢失的一样(核心技术为干扰队列和NC);功能修复:新产生的模块可以包含不同于丢失节点的数据,只要修复的系统支持MDS码属性(核心技术为NC);系统部分精确修复:是介于精确修复和功能修复之间的一个混合修复模型,在这个混合模型中,对于系统节点(存储未编码数据)要求必须精确恢复,即恢复的信息和失效节点所存储的信息一样,对于非系统节点(存储编码模块),则不需要精确修复,只需要功能修复使得恢复的信息能够满则MDS码属性(核心技术为干扰队列和NC)。为了使RGC码运用到实际的分布式系统中,即使不是最优情况也至少需要从k个节点下载数据才能修复丢失模块,因此即使修复过程所需要的数据传输量比较低,RGC码也需要高的协议负载和系统设计(NC技术)复杂度来实现。另外RGC码中未考虑工程解决方法,如懒修复过程,因此不能避免临时失效所带来的修复负载。最后基于NC的RGC码的编解码实现所需要的计算开销比较大,比传统的EC码要高一个阶数。专利PCT/CN2012/083174中提出了一种实用射影自修复码的编码、数据重构及修复方法。实用射影自修复码(PPSRC,PracticalProjectiveSelf-repairingCodes)同样具有自修复码的两个典型属性:丢失的编码模块可从其他编码模块中下载少于整个文件的数据进行修复;丢失的编码模块从一个给定数的模块中修复,该给定数只与丢失了多少模块数有关,而与具体哪些模块丢失无关。这些属性使得修复一个丢失模块的负载比较低,另外由于系统中各节点地位相同、负载均衡使得在网络的不同位置,可以独立并发地修复不同丢失模块。该码字除了满足以上条件外还有以下特性:当一个节点失效时,可以有(n‐1)/2对修复节点可供选择;当有(n‐1)/2个节点同时失效时,我们仍然可以使用剩下的(n+1)/2个节点中的2两个节点来修复失效节点。PPSRC码的编码以及自修复过程仅涉及异或运算,并不像一般自修复码,其编码需要计算多项式相对较复杂,PPSRC码的计算复杂度小于PSRC码(ProjectiveSelf-repairingCodes,射影自修复码)。同时,PPSRC码的修复带宽和修复节点优于MSR码。PPSRC码的冗余是可控的,适用于一般的存储系统,PPSRC码的重建带宽达到最佳。总而言之,PPSRC码有效地减少了数据存储节点,降低了系统数据存储的冗余度,很大程度上提高了实用自修复码的使用价值。然而,PPSRC码也存在一定的不足之处。首先,PPSRC码的编解码过程较为复杂,有限域及其子域的划分运算量相对较大,并且数据重构过程比较繁琐;其次,在PPSRC码中,编码模块是不可再分的,因此修复编码模块也必须是不可再分的。同时,PPSRC码的整个编解码过程运算复杂度较高,冗余量虽然可控但其实还是相当大的。通常PPSRC码存储节点数选取非常大,对于相对小一些的文件来说就显得完全没有必要了。这些均增加了PPSRC码在实际分布式存储系统中实施难度,该射影自修复码通用性不强。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述运算复杂、修复花销较大的缺陷,提供一种运算简单、修复数据花销较小的通用射影自修复码的编码、数据重构和修复方法。本发明解决其技术问题所采用的技术方案是:构造一种通用射影自修复码的编码方法,其特征在于,包括如下步骤:A)取得需要存储的、数据量为B的文件,将其等分为k个数据块,每个数据块包括m个数据;B)设置大小为q的基本有限域GF(q),所述每个数据块在所述基本有限域上用长度为m的向量表示;所述基本有限域的m-维向量空间为W,所述W的所有子空间组成射影几何PG(m-1,q);所述W的(t+1)-维子空间为t-空间,所述t-空间的集合S为t-扩展;得到第一有限域GF(qt+1)和表示所述向量空间W的第二有限域GF(qm),其中,B、k、q、t和m均为正整数,t+1整除m;C)取得表示所述第二有限域GF(qm)非零元素的循环乘法群GF(qm)*,w为其本原元;取得表示所述第一有限域GF(qt+1)非零元素的循环乘法群GF(qt+1)*,v为其本原元;构建存储节点i的编码向量Vi={wi-1,wi-1v,wi-1v2,...,wi-1vt},存储节点i的编码向量分别为所述t-扩展的一组基;其中,i为表示存储节点数的正整数,i=1,2,...,t;D)将对应于各存储节点i的编码向量分别与一个数据块相乘,得到该数据块存储在该存储节点的编码数据。更进一步地,还包括如下步骤:将多个数据块分别与各存储节点的编码数据相乘后得到的编码数据分别依次存储在各存储节点。更进一步地,所述步骤D)中编码向量与数据块相乘为其对应的二进制数进行异或运算。本发明还涉及一种在上述的通用射影自修复码编码方法的存储系统中进行的数据重构的方法,包括如下步骤:I)选择t-1个存储节点中的连续的、等于存储文件数据量或存储文件等分后得到的数据块数据量个存储节点;J)下载所述选择的存储节点中的第l列的编码数据,l为正整数,1≤l≤(t+1);K)分别取得所述选择的存储节点的解码向量,与其下载的编码数据运算,得到解码后的数据块;L)处理分别得到的所述解码后的数据块,得到存储文件。更进一步地,步骤K)所述的解码向量为各存储节点的编码向量的逆矩阵,其通过取得各存储节点的编码向量后求其逆而得。更进一步地,步骤K)中所述编码数据与解码矩阵的运算为其对应的二进制数进行异或运算。更进一步地,在所述步骤L)中组合所述步骤K)中得到的数据块,得到存储文件;所述组合包括按照设定顺序排列所述数据块。本发明还涉及一种在上述的通用射影自修复码编码方法的存储系统中进行的数据修复的方法,包括如下步骤:M)确认一存储节点已经失效并得到该存储节点的编码向量,设该失效的存储节点的编码向量为v1,v2,...,vα;N)依次由未失效的至少两个存储节点分别下载至少一个编码向量,并运算得到所述失效存储节点的编码向量;O)将得到的多个表示失效节点编码数据的编码向量存储在新的存储节点。更进一步地,所述步骤N)进一步包括:N1)由一未失效节点下载其编码向量u1,由另一未失效节点下载其编码向量u2,其中,v1=u1+u2;对所述下载的编码向量进行运算,得到失效存储节点的向量v1;N2)由再一未失效节点下载其编码向量u3,其中,v2=u2+u3;对所述下载的编码向量进行运算,得到失效存储节点的编码向量v2;N3)选择新的未失效存储节点重复步骤N2),直到得到失效存储节点的编码向量vα。更进一步地,所述步骤N)中的运算为其对应的二进制数进行异或运算;所述步骤N)中下载进行运算的编码向量的存储节点相同或不相同。实施本发明的通用射影自修复码的编码、数据重构和修复方法,具有以下有益效果:由于将存储文件分为数据块,且分别对数据块编码并将得到的相互独立的编码数据存储在多个存储节点,所以,在修复数据时可以单独下载各存储节点存储的数据块子集对失效的存储节点进行修复,其修复数据较为简单、下载的数据量较小。附图说明图1是现有技术中EC码的数据重构示意图;图2是现有技术中EC码的失效存储节点修复示意图;图3是现有技术中RGC码的数据重构示意图;图4是本发明通用射影自修复码的编码、数据重构和修复方法实施例中编码流程图;图5是所述实施例中一种情况下编码数据的存储分布示意图;图6是所述实施例中数据重构流程图;图7是所述实施例中数据修复流程图;图8是所述实施例中一种情况下编码数据的修复示意图;图9是所述实施例中一种情况下GPRSC码和MSR码的修复节点和修复带宽的折中曲线比较示意图;图10是所述实施例中另一种情况下GPRSC码和MSR码的修复节点和修复带宽的折中曲线比较示意图。具体实施方式下面将结合附图对本发明实施例作进一步说明。如图4所示,在本发明通用射影自修复码的编码、数据重构和修复方法实施例中,该编码方法包括如下步骤:步骤S41取得数据块:在本步骤中,取得需要存储的数据块,该数据块可能是将需要存储的、数据量为B的文件等分为k份而得到的数据块中的一个,在这种情况下,每个数据块包括m个数据,B=mk;也可以是数据量为B的文件只有一个数据块,在这种情况下,数据块的数据量为B;在多个数据块的情况下,对于本实施例中的方法而言,也是逐个按照本实施例中所揭示的编码方法取得一个数据块存储在各存储节点的编码数据,并将这些数据存储在对应的存储节点中。因此,每个数据块存储在一个节点上的编码数据相互之间是独立的;同时,一个数据块存储在一个存储节点上的编码数据(该数据包括多个数据项)的数据项之间,也是独立的、不相关的。步骤S42设置基本有限域,并将数据块在基本有限域上表示,进而得到第一有限域和第二有限域:在本步骤中,定义GF(q)表示大小为q的有限域,W为GF(q)的m-维向量空间。射影几何PG(m-1,q)是由W的所有子空间组成。其中,PG(m-1,q)的点为1-维子空间,线为2-维子空间。可以验证PG(m-1,q)中共有(qm-1)/(q-1)个点、有(qm-1)(qm-1-1)/(q2-1)(q-1)个线。任意的两个不同的点都包含在同一个线中,任意的两个不同的线都相交于一个点。通常称W的(t+1)-维子空间为t-空间。PG(m-1,q)的t-扩展为t-空间的集合S,其划分了PG(m-1,q)的点。存在PG(m-1,q)的t-扩展的充要条件是t+1整除m。扩展有限域可以构造t-扩展,我们用m-维有限域GF(qm)表示向量空间W。在扩展有限域中,用GF(qm)*表示GF(qm)的非零元素。显然GF(qm)*是循环乘法群。其中,B、k、q、t和m均为正整数,t+1可以整除m。步骤S43得到各存储节点的编码向量:在本步骤中,用w为GF(qm)*的一个固定生成元,而v为GF(qt+1)*的一个生成元,w和v分别称为GF(qm)*和GF(qt+1)*的本原元。对于GF(qm)*的任意元素z,我们用zGF(qt+1)*={zx:x∈GF(qt+1)*}表示GF(qm)*的陪集。当i=0,1,2,…,(qm–1)/(qt+1–1)–1时,陪集wiGF(qt+1)形成了PG(m,q)的一个t-扩展。考虑到实际应用,码字的运算域为GF(2)。大小为B的文件被分割为大小相等的若干数据块,每个数据块的编解码方法都是一样的。因此,我们只给出一个数据块的编解码方法,不失一般性,考虑一个数据文件只含有一个数据块,大小为B,可以用长度为B的GF(2)上的元素表示。令t为满足(t+1)整除B的正整数,N为正整数(2B–1)/(2t+1–1),也就是GF(qB)*在GF(qt+1)*中陪集的个数。令V1={1,v,v2,…,vt}为向量空间GF(2t+1)的一组基。对于i=1,2,…,n,节点i的编码向量分别为t-扩展的一组基,即Vi={wi–1,wi–1v,wi–1v2,…,wi–1vt}是对应于节点i,i=1,2,…,n的编码向量。本实施例中,在一些情况下,也可以先设置上述步骤S42、S43,在按照步骤S42、S43的限制,去划分数据块。也就是说,在一些情况下,可以先执行上述步骤S42、43,再执行步骤S41。这些步骤之间可以视具体情况加以调节。步骤S44依据得到的编码向量,得到存储在各存储节点的编码数据:在本步骤中,节点i存储的编码数据为数据文件与编码向量wi–1vj的乘积,j=0,1,2,…,t。对于所有存储节点而言,分别使用对应的上述编码向量与数据块运算得到存储在该存储节点的、对应于该数据块的编码数据(在存储文件只有一个数据块时对应该存储文件)。此时,乘积是指数据文件与编码向量对应的二进制数的异或运算。总之,取数据量大小为B的文件(为简单起见这里不进行文件分块,各文件快的编解码是一样的),将该文件用GF(2)(为不失一般性,此处q=2)上长度为B的向量表示;取正整数t,满足(t+1)整除B。v是GF(2t+1)的本原元,构造编码向量Vi={wi–1,wi–1v,wi–1v2,…,wi–1vt};节点i存储的编码数据为数据文件与编码向量wi–1vj的乘积,j=0,1,2,…,t。乘积是指数据文件与编码向量对应的二进制数的异或运算。为更加具体起见,给出一个B=8,n=10以及t=3的例子。8位的数据bits分别用o1,o2,o3,o4,o5,o6,o7,o8表示。对这8bits的数据进行编码并分别存储在10个存储节点中,每个存储节点存储t+1=4bits。具体说明如下:设有限域的生成多项式为f(x)=x8+x4+x3+x2+1,其乘法群的生成元为w,则令v=w17,则v的指数和0形成了子域GF(24)。存储节点1的编码向量为1,v,v2,v3,即为N1={1,w17,w34,w51}。而另外7个存储节点存储的向量空间分别为N2={w,w18,w35,w52},N3={w2,w19,w36,w53},N4={w3,w20,w37,w54},N5={w4,w21,w38,w55},N6={w5,w22,w39,w56},N7={w6,w23,w40,w57},N8={w7,w24,w41,w58},N9={w8,w25,w42,w59},N10={w9,w26,w43,w60}。指定前8个元素分别表示为1=00000001,w=00000010,w2=00000100,w3=00001000,w4=00010000,w5=00100000,w6=01000000,w7=10000000。那么对于存储节点1,其编码向量可以计算出,v=w17=w7+w4+w3,v2=w34=w6+w3+w2+w,v3=w51=w3+w所以节点存储的编码数据分别为o1,o4+o5+o8,o2+o3+o4+o7和o2+o4。同理,可以依次计算出其它节点的数据块存储情况,图5给出了本实施例中GPSRC(10,2)存储的编码数据分布图。通过本实施例中GPSRC码(GeneralProjectiveSelf-RepairingCodes,通用射影自修复码)的构造过程可知,文件B被存储在n个节点中,每个节点存储的数据量为(t+1)并且每个节点存储数据的编码向量是相互独立。当k>2时,PSRC码和GPSRC码均不满足MDS特性。可见GPSRC码的重建过程不同于之前的RS码、EC码以及RGC码等。GPSRC的编码矩阵的任意一列的连续B个元素相互独立。不妨假设数据收集者分别下载了节点i,i+1,…,i+B的第一个编码数据,编码向量分别为wi,wi+1,…,wi+B–1。如果存在B个不全为0的系数c1,c2,…,cB,使得c1wi+c2wi+1+…+cBwi+B–1=0。那么对上式两端同时除以wi,则得到c1+c2w1+…+cBwB–1等于0,这与1,w1,…,wB–1是GF(2B)的一组基是相互矛盾的。因此,GPSRC码的重建数据的方法为:下载连续的B个存储节点的第l列编码数据,1≤l≤(t+1)。我们知道,编码矩阵的任意一列的连续的B个元素均相互独立,所以可以解码出B个原始数据,即可以恢复出原始数据B。请参见图6,在图6中示出了本实施例中GPSRC码的数据重建过程,包括如下步骤:步骤S61选择等于存储文件数据量或数据块数据量的存储节点:在本步骤中,由t-1个存储节点中,选择等于存储文件数据量或存储文件等分后得到的数据块数据量个存储节点,例如,如果文件或数据块中数据为8bits,则选择8个存储节点。值得一提的是,如果存储文件只有一个数据块,且为B个,则上述选择的存储节点的数量为B;如果该存储文件被等分,则上述存储节点的数量是该数据块中数据的数量。不管何种情况出现,在本实施例中,这些被选择的存储节点一定是连续的。在本实施例中,作为一个例子,在存储文件只有一个数据块且其中数据量为B的情况下,选择的存储节点数量为B,此处B的数值与存储文件包括的数据量B是相同的。步骤S62分别下载所选存储节点中的第l列编码数据:在本步骤中,下载上述步骤中连续的B个存储节点的第l列编码数据,其中,1≤l≤(t+1)。步骤S63将各存储节点下载的编码数据分别与其对应的解码向量运算,得到其数据块:由于从各存储节点下载的数据是编码数据,需要将其解码,并组合起来才能得到当初经过编码存储在存储节点的原始数据。而在本步骤中,就是将下载的编码数据分别按照取得该数据的存储节点的位置进行解码。通常来讲,各个存储节点的编码是不同,将各存储节点用于编码的编码向量按照其存储数据的位置对应起来时,就形成该存储节点的编码矩阵。解码也是一样,同样存在用于解码的向量或矩阵。由于编码矩阵的任意一列的连续的B个元素均相互独立,故通过下载的数据与解码矩阵,解码出原始数据。实际上,使用的是解码矩阵中与下载数据对应的解码向量。在本步骤中,解码矩阵是各存储节点编码矩阵的逆矩阵,按照编码数据所在位置,即可由解码矩阵中得到解码向量。所以,在本步骤中,解码向量通过取得各存储节点的编码向量后求其逆而得。编码数据与解码矩阵的运算为其对应的二进制数进行异或运算。步骤S64组合得到的数据块,得到存储文件:将解码出的数据进行整合,恢复出原始数据B。请参见图7,图7示出本实施例中数据修复的过程,包括如下步骤:步骤S71确定失效存储节点,并设置其编码数据:在本步骤中,确定一个存储节点是否失效,如果一个存储节点失效,由其所在位置(或节点编号)可以得到该存储节点的编码矩阵或编码向量。在本步骤中,当确定一个存储节点失效后,可以先设置其编码数据为v1,v2,...,vα;在后面的步骤中,逐个得到上述编码数据中的每个数据块,将其组合后存储在新的节点,即可完成数据修复。步骤S72分别由至少两个存储节点下载至少一个编码数据修复失效存储节点的编码数据:在本步骤中,分别由至少两个未失效的存储节点中分别下载至少一个编码数据,分别得到上述步骤中设置的失效节点的编码数据或编码数据块。具体来讲,在本实施例中,由一未失效节点下载其编码数据块u1,由另一未失效节点下载其编码数据块u2,其中,这两个未失效存储节点下载的数据存在以下关系:v1=u1+u2;对所述下载的编码数据块进行运算,得到失效存储节点的编码向量v1。由再一未失效节点下载其编码向量u3,将其与上述步骤中已经下载的编码数据配合,其中,该再一存储节点和已经现在过编码数据的存储节点上下载的数据存在以下关系:v2=u2+u3;对这编码数据块进行运算,得到失效存储节点的编码向量v2。之后,选择新的未失效存储节点重复上述步骤,直到得到失效存储节点的编码向量vα。在本步骤中,上述编码数据之间的运算为其对应的二进制数进行异或运算;此外,在本步骤中,上述下载进行运算的编码数据块的存储节点相同或不相同,即在某些情况下,可以由一个存储节点下载两个编码数据并进行运算。当然,在一些情况下,一个存储节点也可以根据情况选择下载多个数据块并进行运算。步骤S73得到失效存储节点的编码数据并存储在新节点:在本步骤中,将上述步骤中得到的多个编码数据块组合在一起,请将其存储在一个新的存储节点上,完成数据修复。在本实施例中,在PSRC(n,k)码中,共有n个存储节点,每个存储节点存储α的编码数据量。当一个存储节点Nl失效时,可以通过选择任意1个存储及其相应的另一个存储节点并下载这2个存储节点来恢复出失效节点Nl存储的数据。GPSRC(n,k)码中,当一个存储节点失效时,那么最多从(α+1)=(t+2)个存储节点中各下载一个数据,修复带宽为(α+1)=(t+2)。一个失效的数据可以通过任意的选择1个节点的数据并对应的下载另一个节点的一个数据来恢复。假设一个节点丢失数据的编码向量为v1,v2,…,vα,那么可以任意的选择一个节点的编码向量u1以及相对应的另一个节点的编码向量u2,使得v1=u1+u2。之后,选择修复v2的一个编码向量为u2以及其相对应的编码向量u3使得v2=u2+u3。同样的道理,可以得到v3=u3+u4,…,vα=uα+uα+1。所以修复编码向量v1,v2,…,vα共下载了最多(α+1)个存储节点的编码向量(u1,u2,…,uα+1),修复带宽为(α+1)。同时,我们称该修复过程为最佳带宽修复过程。在图5给出的GPSRC(10,2)码中,当节点1失效时,首先下载节点2的{u1=00010100}和节点6的编码向量{u2=00100000+00110101=00010101}可以修复向量{v1=u1+u2=00000001}。根据最佳带宽修复过程,下载节点3的{u3=01011010}节点4的{u4=01010000}和节点7的{u5=11001001}即可恢复出节点1的所有失效数据。修复过程为{v1=u1+u2,v3=u1+u3,v4=u4+u3,v2=u5+u4+v1}。修复带宽为5,修复节点为5。其他节点的修复带宽也均是5。如图8所示,节点1存储数据量可以由其它节点的数据块相异或而得出,具体地说,N1=N2(o3+o5)+N3(o2+o4+o5+o7)+N4(o5+o7)+N6(o1+o3+o5)+N7(o1+o4+o7+o8)。那么若节点1失效,在修复过程中需要下载节点2的数据块(o3+o5)、节点3的数据块(o2+o4+o5+o7)、节点4的数据块(o5+o7)、节点6的数据块(o1+o3+o5)和节点7的数据块(o1+o4+o7+o8)即可修复节点1存储的数据。其它节点存储的数据的修复过程与第一个节点的表示方法类似地得出。这里补充说明的一点是,每个节点存储的原始数据块之间是可以相异或的。具体地说,为了修复节点9存储的数据块,需要从前8个节点存储的数据块中选择一些数据块进行异或运算。然而,这些节点存储的原始数据是并不能直接修复出节点9丢失的数据块。这时我们需要将前面节点存储数据块进行简单异或来进行修复。比如,为了修复出节点9的数据块(o1+o2),可以选择节点8的数据块(o1+o2+o3+o4+o8)、(o3+o5+o7+o8)简单异或,得到数据块(o1+o2+o4+o5+o7)。同时选择节点4的数据块(o4)、(o5+o7)简单异或得到(o4+o5+o7)。所以有,(o1+o2)=(o1+o2+o4+o5+o7)+(o4+o5+o7)。同理可以修复出节点9的其它数据块,节点10的修复方式亦然。根据以上分析,我们给出GPSRC的一般修复过程。首先,可以从两个节点分别下载t个编码数据,可以修复失效节点的t个编码数据;同时,我们下载一个编码数据和已经下载的2t个编码数据一起修复失效节点剩下的一个编码数据。以上修复过程的修复带宽为2t+1、修复节点为3。同理,可以从两个节点中分别下载(t-1)个编码数据块并从另外两个节点下载两个编码数据,这样,修复带宽为2t,修复节点为4。同理可以得出其它节点的修复过程,统称这些修复过程为一般修复过程。一般修复过程在修复带宽和修复节点性能中有一个折中,该折中函数可以表示为γ+d=2t+4=2(1+B/k),fort+2≥d≥2其中,γ为修复带宽,d为修复节点。所以修复带宽可以表示为图9和图10分别给出了参数B=16,k=4和B=32,k=4时GPSRC和MSR码的折中曲线。可以得到当给定修复节点数量时,GPSRC的修复带宽小于MSR码的修复带宽,而当给定修复带宽时,GPSRC的修复节点数量也小于MSR码的修复节点。因此,可以说,一般情况下GPSRC在修复带宽和修复节点性能中均优于MSR码,尽管其代价为失去MDS特性。在本实施例中的通用射影自修复码(GPSRC)与RGC码不同之处在于,RGC码主要思想还是利用MDS属性,当网络中一些存储节点失效,需要从现有有效节点中下载信息来使得丢失的数据修复丢失的数据模块,并将其存储在新的节点上。再生过程需要确保两点:1)失效的节点间是相互独立的,再生过程可以循环递推;2)任意k个节点就足够恢复原始文件。RGC码中要重构任意一个模块,至少需要和其他k个节点通信,当只有一个模块丢失,所需要的最小通信量是与所有活动的n-1个节点通信,而GPSRC码则比较灵活,修复节点和修复带宽可以折中考虑,最少只需要和2个节点进行通信。HSRC码的编码需要计算多项式相对较复杂,系统计算复杂度较高。同时为了修复一个特定的失效节点,一旦随机的选择了一个节点为辅助节点,就只剩下一个节点可供选。GPSRC码则不同,修复一个失效节点可以存在多种修复方案。具体来说,对于一个失效节点,至少存在一个节点对可以进行修复。在本实施例中,GPSRC码在修复节点和修复带宽方面可以折中考虑,具体编码方案实施过程中可以达到修复节点少,修复带宽小的效益,特别适合应用于实际的分布式存储系统。同时,GPSRC码提供了有效的冗余修复方案,具体包括:1)丢失的编码块可以直接下载其他编码模块的若干子集进行修复,下载的数据量小于整个文件的数据量;2)丢失的编码块可以通过固定数目的编码模块进行修复,该固定数目只与系统丢失了多少模块数有关,而与具体哪些模块丢失无关。这些属性使得修复一个丢失模块的负载比较低,同时可以独立并发地修复不同丢失模块。GPSRC码不仅满足PSRC的基本特性,而且在选择存储节点的数量上更灵活,相比于之前的编码方案,GPSRC的编码效率更高。一个GPSRC(n,k)码可以通过远小于k个节点来修复一个失效模块,而且很多情况下一个节点的修复能力不止一个,那么修复一个丢失模块所需要的节点数大幅度减少,从而也减少了系统的通信开销;GPSRC码的构造过程、修复过程和重建过程均只涉及异或运算,所以计算复杂度很低、计算开销很小,适合实际的存储系统;GPSRC码可以并发修复不同的模块,很大程度上降低了系统修复时延,这使得GPSRC易于实施、修复代价低。以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1