用于检测网站攻击的方法和设备与流程
本发明涉及网络安全领域,具体而言,涉及用于检测网站攻击的方法和设备。
背景技术:
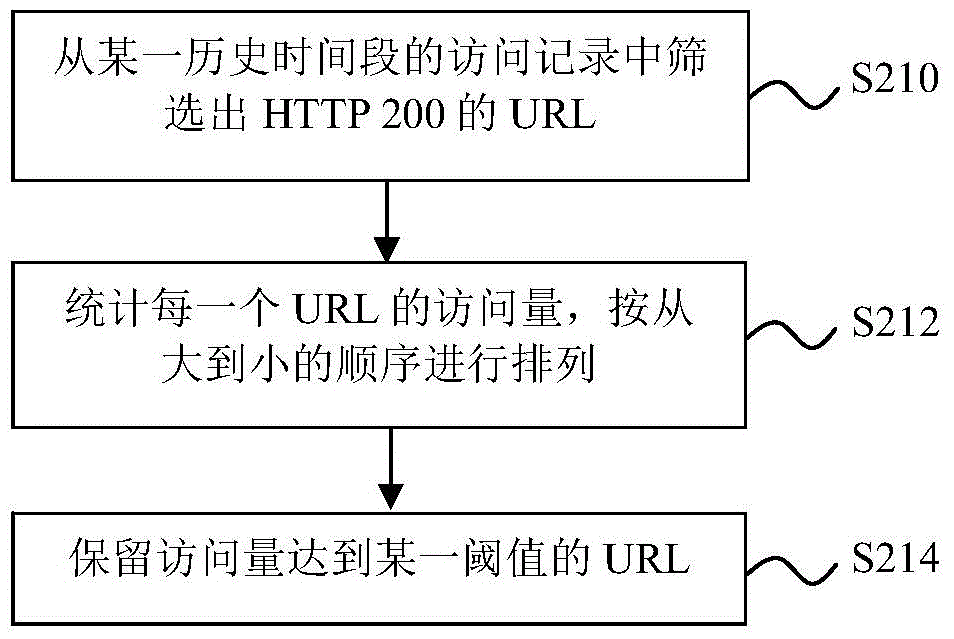
:当前信息安全领域,正在面临多种挑战。一方面,企业安全架构日趋复杂,各种类型的安全设备、安全数据越来越多,传统的分析能力明显力不从心;另一方面,以APT(高级可持续性威胁)为代表的新型威胁的兴起,内控与合规的深入,越来越需要储存与分析更多的安全信息,并且更加快速的做出判定和响应。在以往,了解难以察觉的安全威胁会耗费数天甚至数月的时间,因为大量的互不相干的数据流难以形成简明、有条理的事件“拼图”。所采集和分析的数据量越大,看起来越混乱,重构事件所需的时间也越长。如果攻击快速且凶猛(例如拒绝服务攻击或快速传播的蠕虫),花数天或数月诊断问题会带来巨大的合规和财务影响。因此,存在改善这种状况的需求。技术实现要素:根据本发明的一方面,提供了一种检测网站攻击的方法,包括:从该网站的历史访问记录中选择多个统一资源定位符(URL);对该多个统一资源定位符进行聚类;以及根据聚类的结果,从该多个统一资源定位符中生成白名单。根据本发明的另一方面,提供了一种用于检测网站攻击的设备,包括选择装置,用于从该网站的历史访问记录中选择多个统一资源定位符;聚类装置,用于对该多个统一资源定位符进行聚类;以及生成装置,用于根据聚类的结果,从该多个统一资源定位符中生成白名单。本发明的实施方式可能包括下列一个或多个特征。该多个统一资源定位符对应的HTTP响应状态可能是请求已成功。至少部分该多个统一资源定位符对应的用户可能属于将网站用户聚类后得到的最大的类。对该多个统一资源定位符进行聚类可以包括:分解该多个统一资源定位符的每一个中的URL串、URL串中的目录和URL请求参数,生成URL串子集、URL串中的目录子集和URL请求参数子集。对该多个统一资源定位符按照URL串子集进行聚类。识别出URL串中的数字、 全局唯一标识符或BASE64编码的子字符串,用于确定URL串聚类的距离。对该多个统一资源定位符按照URL串中的目录子集进行聚类。通过将两个URL串中的目录拼接得到的目录数减去所述两个目录中重复的目录数,确定目录聚类的距离。对该多个统一资源定位符按照URL请求参数子集进行聚类。对于所述多个统一资源定位符的每一个中唯一的参数名,对对应于该唯一的参数名的所有出现过的参数值进行聚类。或者,对该多个统一资源定位符中出现过的所有参数名单独进行一次聚类。在对该多个统一资源定位符按照URL串子集、URL串中的目录子集和URL请求参数子集分别进行聚类的情况下,确定每一个URL串、URL串中的目录和URL请求参数在相应子集中所属类的百分位作为异常值。将URL串、URL串中的目录和URL请求参数的异常值相加确定相应的统一资源定位符的总异常值。将总异常值低于阈值的统一资源定位符列入白名单。本发明的某些实施方式可能具有下列一个或多个有益效果:可以实现无监督学习,不需要冷启动;产生的结果是黑/白名单,并且用户可以修改;可以检查URL级别的常见OWASP攻击。本发明的其他方面、特征和有益效果将在具体实施方式、附图及权利要求中得到进一步明确。附图说明下面结合附图对本发明做进一步说明。图1是根据本发明的检测网站攻击的方法的流程图;图2是根据一种实施方式的过滤URL历史访问记录的流程图;图3是根据一种实施方式的发掘网站结构的流程图;图4是根据本发明的生成URL各个子集的示例图;图5是根据一种实施方式的生成白名单的流程图;图6是根据另一种实施方式的过滤URL历史访问记录的流程图;图7是根据另一种实施方式的发掘网站结构的流程图;图8是根据再一种实施方式的发掘网站结构的流程图;以及图9是根据本发明的检测网站攻击的设备的功能框图。具体实施方式参看图1,在步骤S110中对网站的URL历史访问记录进行过滤。URL历史访问记录中通常混合有正常的URL和恶意的URL,经过滤从中选择出多个正常的URL或者多个至少绝大部分正常的URL。参看图2,图2对图1中的步骤S110进一步说明,其中对URL历史访问记录进行HTTP200过滤。其中,HTTP状态码由RFC(RequestforComments)2616规范定义,用于表示网页服务器HTTP的响应状态。作为其中一个HTTP状态码,HTTP200表示请求已成功、请求所希望的响应头或数据体将随此响应返回。进行HTTP200过滤时,可选定某一历史时间段,从这一历史时间段的HTTP访问记录中筛选出响应状态为200的URL访问记录,步骤S210。统计每一个URL的访问次数(访问量),并按次数从大到小的顺序进行排列,步骤S212。表1是一个示例性的统计结果。URL访问量http://www.example.com/a.html100http://www.example.com/b.html80http://www.example.com/c.html40……http://www.example.com/y.html1http://www.example.com/z.html1表1根据统计结果,保留访问量达到某一阈值(例如为前90%)的URL,步骤S214。例如,假设表1中总访问量为300,则只保留访问量超过30的URL。以表1为例,“…/a.html”、“…/b.html”和“…/c.html”这三个URL将被保留,而“…/y.html”和“…/z.html”这两个URL将被排除。这里,阈值90%也可根据不同网站而设置成其他值。返回图1,在步骤S112中,根据经过过滤得到的多个URL,发掘网站结构。大中型企业的、尤其是应用高级WEB框架开发的网站的结构通常相对具有条理。例如,域名是正常的中文拼音缩写组合、或是正常的英文单词缩写组合、或遵从类似的命名规范;URL结构树结构安排合理,相同内容位于同样的URL目录下;对于允许带请求参数的URL,参数同样有类似的命名规范。根据RFC1738规范定义,URL的格式是:scheme://[user:password@]domain:port/path?query_string#fragment_id。其中,query_string包含用符号“&”分割开的多个key=value格式,其中key是参数,value是参数值。例如:field1=value1&field2=value2&field3=value3中有三个参数:field1、field2和field3;以及三个相应的参数值value1、value2和value3。表2是一个关于网站结构的示例。表2从表2的示例中可见,每个目录代表一类功能,并且在参数(例如ref、node、nodeID、pf_rd_t)中只出现小写字母、数字和下划线“_”。参考图3和4,其中图3用于说明分解URL结构并进行聚类的一种实施方式。在步骤S310中,将每一个URL分解为下列结构:URL串、URL串中的目录以及URL请求参数。其中,URL串不包含参数,URL请求参数包括该URL中每一对参数名和参数值的组合。图4通过3个示例性的URL来说明分解URL结构并生成相应子集的过程。如步骤S410所示,其中一个URL“www.example.com/dir0/a.html?param1=v1”相应地分解为example.com/dir0/a.html(URL串)、dir0(URL串中的目录)以及param1=v1(URL请求参数)。通过分解其中每一个URL的上述结构,由经过过滤得到的多个URL生成三个子集,即:URL串子集、URL串中的目录子集和URL请求参数子集,步骤S312。步骤S412中示出了生成的三个子集。在步骤S314中,对URL串中的目录子集进行聚类。作为数据分析技术中的一个重要概念,聚类指的是一个将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的类是一组数据对象的集合,这些对象与同一个类中的对象彼此相似,与其他类中的对象相异。对URL串中的目录子集进行聚类可采用任何支持编辑距离的聚类算法,例如OPTICS、DBSCAN。其中,OPTICS(OrderingPointsToIdentifytheClusteringStructure)是一种在空间数据中寻找基于密度的簇(或类)的算法。OPTICS的基本思路与DBSCAN(Density-BasedSpatialClusteringofApplicationswithNoise)类似,但克服了DBSCAN的一个弱点,即:在密度变化的数据中确定有意义的簇。为此,数据库中的点被(线性)排序使得空间上最近的那些点在排序过程中成为邻居。此外,为了使两个点属于同一个簇而为每一个点存储一个特定的距离,这个距离代表成为一个簇而需要被接受的密度。OPTICS算法主要有两个参数eps和MinPts,其中,eps是指算法需要考虑的最大距离(半径),MinPts是指要形成簇所需的点的数量。需要指出的是,OPTICS算法本身对参数并不敏感,不同的eps和MinPts也可能得到类似的结果。OPTICS算法的标准伪码如下:其中,getNeighbors(p,eps)代表离特定点p距离在eps以内的所有点。core-distance(p,eps,Minpts)代表离p距离eps以内的点数量是否超过Minpts,如果没超过,返回UNDEFINED,如果超过,则把距离从小到大排序,返回第Minpts短的距离。OPTICS(DB,eps,MinPts)如上所述,DBSCAN算法的思路与OPTICS相似,其标准伪码如下:DBSCAN(DB,eps,MinPts)为简便起见,本发明下述实施例中的聚类算法都以标准OPTICS为例。在步骤S314中,将URL串中的目录确定为聚类特征;通过将两个URL串中的目录拼接得到的目录数减去这两个目录中重复的目录数确定聚类距离。表3为确定目录聚类距离的一个示例。URL串中的目录聚类距离dir1/dir2,dir1Dist(dir1/dir2,dir1)=dir1/dir2–dir1=2-1dir1/dir2,dir0Dist(dir1/dir2,dir0)=dir1/dir2dir0–[]=3-0dir1/dir2,dir2/dir3Dist(dir1/dir2,dir2/dir3)=dir1/dir2/dir3–dir2=3–1表3下面返回图1,在步骤S114中,根据聚类的结果,从经过过滤得到的多个URL中生成URL白名单。URL串中的目录子集在步骤S314中被分成若干个类。子集中的每个URL串中的目录属于其中一类。通过确定所属类的百分位,可得出每个URL串中的目录的聚类异常值,步骤S510。根据聚类异常值,可进一步确定相应URL的总异常值,步骤S512,其中,在只对URL串中的目录子集进行聚类时,总异常值等于相应的聚类异常值。将总异常值低于某一阈值的URL列入白名单,步骤S514。这里,某一个类的百分位,是指比该类大的所有类中的对象数占总对象数的百分比。例如,假设经过聚类后,URL串中的目录子集被分为7个类,大小依次为:100、80、60、14、7、3、1,那么其中最小的类的百分位是1-1/(100+80+60+14+7+3+1)=99.6%,而第二小的类的百分位是1-(1+3)/(100+80+60+14+7+3+1)=98.5%,依次类推。相应地,在最小的类中,每个URL串中的目录的聚类异常值为99.6%。在只对URL串中的目录子集进行聚类时,URL的总异常值也是99.6%。类似地,可将高异常值的URL报告成攻击,列入黑名单。所生成的黑名单或白名单也可由用户手动修改。异常值的阈值可以由用户手动设置,缺省可设为99。在生成URL白名单的情况下,如果实时URL访问日志中的URL不在白名单之列,则该URL将被视为恶意URL访问。其他的实施方式也是可行的。例如,可通过对发起HTTP请求的用户聚类来过滤网站的URL历史访问记录。参看图6,在步骤S610中,聚类的特征可设为用户的URL访问序列,例如,a.html→b.html→c.html→d.html。聚类的距离函数相应地设为URL访问序列距离(编辑距离)。例如,序列a.html→b.html→c.html→d.html和序列a.html→c.html→d.html之间的距离是1(1次删除);序列a.html→b.html→c.html→d.html和序列a.html→c.html→b.html→d.html的距离也是1(1次c、b对调)。以其他特征和距离函数进行 聚类运算也是可行的。例如,只考虑用户访问过的唯一的URL。如前所述,聚类运算可以选用任何支持编辑距离的聚类算法,例如,标准OPTICS或DBSCAN算法。对发起HTTP请求的用户聚类和HTTP200过滤两者可以并用,分别作为混合过滤方法中的一个规则,用于过滤URL历史访问记录,进而发掘网站结构。此外,混合过滤方法中还可以包括其他规则。根据图7和8的实施方式,在生成URL串子集、URL串中的目录子集以及URL请求参数子集后,也可分别对URL串子集和URL请求参数子集进行聚类。在步骤S714中,聚类的特征是URL串,聚类的距离函数是URL串加权编辑距离。和通用编辑距离相比,加权编辑距离的差别在于其从URL串中识别出数字、全局唯一识别符(GUID)和BASE64编码的子字符串,将其作为一个特殊字符;否则一个字符就是一个符号(聚类时URL串的单位元素)。例如,123455.html和1.html的距离是1;7ca657b5-1110-43e7-bc5c-1ee25560e40f.html和7227db62-49aa-4c36-9a87-b0d737ab0ed7.html的距离也是1(识别成GUID);而abc.html和a.html的距离是2(既不是数字也不是GUID)。如前所述,可以选用任何支持编辑距离的聚类算法,例如,标准OPTICS或DBSCAN算法。URL串子集在步骤S714中被分成若干个类。相应地,子集中的每个URL串属于其中一类。与对URL串中的目录子集进行聚类类似,通过确定所属类的百分位,可得出每个URL串的聚类异常值。根据该聚类异常值,可进一步确定相应URL的总异常值,其中,在只对URL串子集进行聚类时,总异常值等于相应的聚类异常值。将总异常值低于某一阈值的URL列入白名单。在步骤S814中,对每个唯一URL下的唯一的参数名,所有出现过的参数值进行聚类。例如,对于URL“http://abc.com/dir1/dir2/a.html?param1=v1¶m2=v2”和“http://abc.com/dir1/dir2/b.html?param1=v1¶m2=v2”,需要做4种聚类:abc.com/dir1/dir2/a.html?param1、abc.com/dir1/dir2/a.html?param2、abc.com/dir1/dir2/b.html?param1和abc.com/dir1/dir2/b.html?param2,其中聚类距离函数是参数值的加权编辑距离(类似于URL串)。作为替代的,对所有URL下出现过的所有参数名单独做一次聚类。比如param1、param2。如前所述,可使用标准OPTICS或DBSCAN算法进行聚类。URL请求参数子集在步骤S814中被分成若干个类。相应地,子集中的每个URL请求参数属于其中一类。与对URL串中的目录子集进行聚类类似,通过确定所属类的百分位,可得出每个URL请求参数的聚类异常值。根据该聚类异常值,可进一步确定相应URL的总异常值,其中,在只对URL请求参数子集进行聚类时,总异常值等于相应的聚类异常值。将总异常值低于某一阈值的URL列入白名单。另外,在生成URL串子集、URL串中的目录子集以及URL请求参数子集后,还可对这三个子集中的任意两个或全部进行聚类。以对三个子集分别进行聚类为例,参看图3、7和8,分别确定每个URL中的URL串、URL串中的目录和URL请求参数的聚类异常值,该URL的总异常值等于三个聚类异常值的和。将总异常值低于某一阈值的URL列入白名单。作为替代,可以将总异常值高的URL直接报告成攻击,列入黑名单。此外,在列入黑名单之前,可将总异常值高的URL先经过正常用户聚类过滤。在此假设最大的类里的用户访问到的都应是正常的URL,因此属于这类的URL即便总异常值高也不被列入黑名单。图9所示的根据本发明的用于检测网站攻击的设备900包括选择装置910、聚类装置912和生成装置914。选择装置910用于从网站的历史访问记录中选择多个统一资源定位符,聚类装置910用于对所述多个统一资源定位符进行聚类,以及生成装置914用于根据聚类的结果,从该多个统一资源定位符中生成白名单。设备900的功能模块910、912、914可以通过硬件、软件或硬件与软件的结合实现,从而执行上述根据本发明的方法步骤。此外,选择装置910、聚类装置912和生成装置914可以组合或者进一步分解成子模块,从而执行上述根据本发明的方法步骤。因此,上述功能模块的任何可能的组合、分解或进一步的定义都落入权利要求所保护的范围之内。本发明不限于上述具体描述,本领域技术人员在上述描述基础上容易想到的任何改变,都在本发明的范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1