叠加编码中的速率匹配和软信道比特存储的制作方法
本申请根据35U.S.C.§119要求2014年12月30日递交的,发明名称为“Rate Matching and Soft Channel Bits Storage for Superposition Coding,”的美国临时申请案62/097,809的优先权;以及2014年12月30日递交的,发明名称为“Soft Buffer Partition for Superposition Coding,”的美国临时申请案62/097,813的优先权,且将上述申请作为参考。
技术领域
本发明有关于移动通信网络,且尤其有关于叠加编码(superposition codi ng)中的速率匹配(rate matching),软信道比特存储(soft channel bits storage)以及软缓冲区分区(soft buffer partition)。
背景技术:
在无线蜂窝通信系统中,多用户多输入多输出(multiuser multiple-input multiple-output,MU-MIMO)是一种有前途的技术,可显著提高小区容量(capacity)。在MU-MIMO中,意图(intend)发送给不同用户的信号被同时发送给正交(或准正交)预编码器(precoder)。此外,从发送机和接收机角度的多用户操作联合优化的理念有潜力进一步改进多用户系统容量,即便传输/预编码是非正交的。其中,传输/预编码是非正交的可能是(但不限于)因为大量非正交波束/层的同时传送,在一个波束中可能存在多层数据传送。这种非正交传送可使多个用户在没有空间分隔的情况下共享相同的资源元素,并可以以少量发送天线(即2或4,或甚至1)改进网络的多用户系统容量,其中基于空间复用(spatial multiplexing)的MU-MIMO通常受较宽波束宽度所限。一种有关于与自适应Tx功率分配和码字级干扰消除(Codeword Level Interference Cancellation,CW-IC)接收机的联合Tx/Rx优化方法近来成为一种值得注意的技术趋势,这种方法包括基于叠加编码的非正交多路访问(non-orthogonal multiple access,NOMA)和其他方案。
在LTE中,速率匹配算法重复或击穿(puncture)源码字(mother codeword)的比特,以根据时间-频率资源的尺寸和所需码率(可能与信道编码器的源码率不同)生成所需数目的比特。此外,若要采用软分组组合(soft packet combining)来增强解码性能,速率匹配也需要考虑接收机处的码块的软缓冲区尺寸。当采用叠加编码时,意图发送给一用户的传输块(Transport Block,TB)也可能需要在另一个用户的接收机处解码。然而,根据LTE标准,每个码块的软缓冲区尺寸取决于UE类别。因此,两个接收机的软缓冲区尺寸可能并不相同。为了使能(enable)LTE中的叠加编码,有关速率匹配的一些问题需要解决。具体来说,在叠加编码中,有关发送机处的软缓冲区尺寸设定和接收机处的软信道比特存储的两个问题应被讨论和解决。
此外,接收机处的软缓冲区为所需信号预留(reserve),也为干扰信号预留以由CW-IC进行处理。如此一来,UE和网络应在对两种类型信号的软缓冲区分区上有相同的理解。否则,一些传输块的软信道比特可能无法累积(accumulated),而多次传送(重传)的软分组组合也无法有效运作。而在LTE-Rel-12中,软缓冲区仅为所需TB预留,且用于TB的分区方案有关于下行链路(downlink,DL)混合自动重传请求(hybrid Automatic Repeat Request,HARQ)进程的数量。因此,需提出一种在叠加编码中用于所需以及干扰TB的软缓冲区分区和限制激活(active)DL HARQ进程的总数的方法。
技术实现要素:
本发明提出用于叠加编码的发送机处的软缓冲区尺寸设定和接收机处的软信道比特存储方法。在叠加编码方案中,意图发送给一用户设备的传输块需被另一用户设备的接收机解码。然而,由于每个码块的软缓冲区尺寸取决于UE类别,两个接收机的软缓冲区尺寸可能并不相同。基站可将发送机处采用的用于速率匹配的软缓冲区尺寸发送给用户设备,以用于叠加解码。用户设备按照发送机处采用的用于速率匹配的软缓冲区尺寸,将与干扰信号有关的信息比特存储到其软缓冲区中。如此一来,用户设备可解码干扰信号并从所需信号中减去干扰信号,以进行叠加解码。
当接收机采用CW-IC且发送机采用叠加编码方案时,若接收机的软缓冲区不仅为所需信号预留,也为干扰信号预留以进行CW-IC处理是有好处的。这样一来,多次传送(重传)的干扰TB的软信道比特可被组合,以提高数据解码的成功率。本发明提出一种叠加编码方案中用于所需和干扰TB的软信道比特的软缓冲区分区方法。所提出的方法在调整所需和干扰TB的软缓冲区尺寸时具有充分的灵活性。
其他实施例和好处将在以下具体实施方式中进行描述。本部分并无意图限定本发明,本发明以权利要求书为准。
附图说明
图1是根据一新颖性方面的具有用于叠加编码和干扰消除的速率匹配和软信道比特存储的移动通信网络的示意图。
图2是在执行本发明一些实施例的基站和UE的简化方块示意图。
图3是通信系统中将TB的信息比特映射为码字,再将码字映射为基带信号以进行传送的功能性方块示意图。
图4是eNodeB处的LTE速率匹配进程和UE处的HARQ软分组组合的示意图。
图5是叠加编码的LTE速率匹配的第一实施例的示意图,其中eNodeB基于每个UE预留的码块软缓冲区尺寸确定用于速率匹配的软缓冲区尺寸。
图6是叠加编码的LTE速率匹配的第二实施例的示意图,其中eNodeB基于涉及叠加编码的两个UE所预留的码块软缓冲区尺寸中的最小尺寸确定用于速率匹配的软缓冲区尺寸。
图7是根据一新颖性方面的从eNB角度的速率匹配和软信道比特存储方法的流程图。
图8是根据一新颖性方面的从UE角度的速率匹配和软信道比特存储方法的流程图。
图9是基于3GPP LTE中给出的NIR的公式的软缓冲区分区的示意图。
图10是与所需和干扰信号有关的下行链路HARQ进程的示意图。
图11是基于激活DL HARQ进程的最大总数目的软缓冲区分区的示意图。激活DL HARQ进程的最大总数目包括用于所需信号的激活DL HARQ进程的 第一数目,加上用于干扰信号的激活DL HARQ进程的第二数目。
图12是用于所需以及干扰信号的具有软信道比特存储和软缓冲区分区的叠加编码进程的示意图。
图13是根据一新颖性方面的从eNB角度的软缓冲区分区方法的流程图。
图14是根据一新颖性方面的从UE角度的软缓冲区分区方法的流程图。
具体实施方式
现在请参考本发明的一些实施例的细节描述,其中一些示范例将在附图中进行描述。
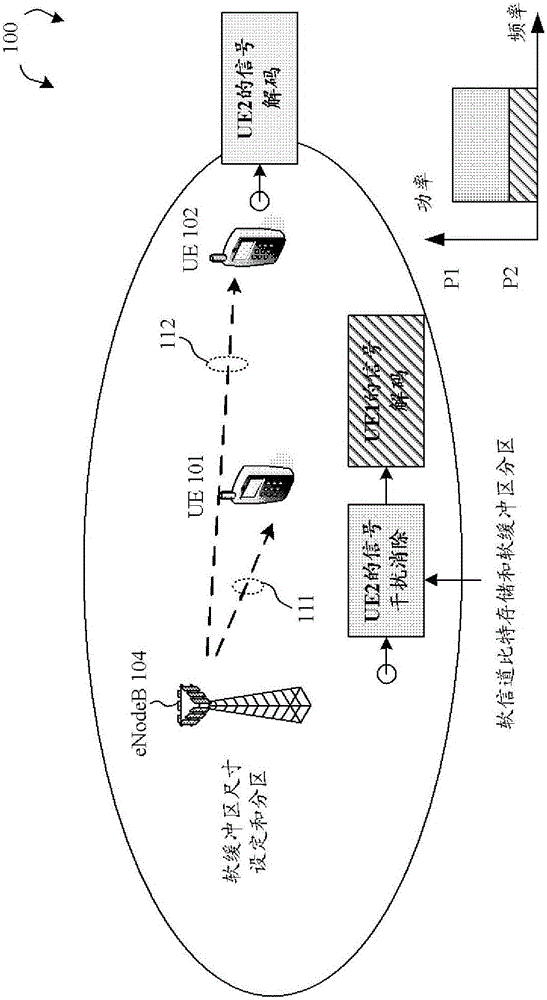
图1是根据一新颖性方面的具有叠加编码的移动通信网络100的示意图。移动通信网络100是OFDM网络,包括多个用户设备UE 101、UE 102,以及服务基站eNB 104。在基于OFDMA下行链路的3GPP LTE系统中,无线电资源在时域划分为子帧,每个子帧包括两个时隙(slot),每个时隙在一般循环前缀(Cyclic Prefix,CP)的情况下包括七个OFDMA符号,或者在扩展(extended)CP的情况下包括六个OFDMA符号。基于系统带宽,每个OFDMA符号进一步在频域上包括多个OFDMA子载波。资源栅格(resource grid)的基础单元被称为资源元素(Resource Element,RE),其跨越一个OFDMA符号上的一OFDMA子载波。资源元素被分组为资源块(Resource Block,RB),其中每个资源块包括一个时隙中的12个连续子载波。
多个物理下行链路信道和参考信号被定义,以采用资源元素集合息携带来自更高层的信息。对于下行链路信道来说,物理下行链路共享信道(Physical Downlink Shared Channel,PDSCH)是LTE中主要的数据传送(data-bearing)下行链路信道。而物理下行链路控制信道(Physical Downlink Control Channel,PDCCH)用来携带LTE中的下行链路控制信息(Downlink Control Information,DCI)。控制信息可包括调度(scheduling)决定,有关参考信号信息的信息,形成将由PDSCH携带的相应TB的规则,以及功率控制命令。对于参考信号来说,小区特定参考信号(Cell-specific Reference Signal,CRS)被UE用来在非预编码或基于码本的预编码传输模式中解调控制/数据信道,进行无线电链路监测,以及信道状态信息(Channel State Information,CSI)反馈测量。UE特定参考信号(DM-RS)被UE用来在基于非码本的预编码传送模式中对控制/数据信道进 行解调。
在图1所示的示范例中,UE 101(UE#1)由其服务基站eNB 104提供服务。UE#1接收eNB 104发送的所需无线电信号111。然而,UE#1也接收干扰无线电信号。在一示范例中,由于意图发送给相同服务小区中的不同UE(如UE102/UE#2)的NOMA操作,UE#1接收相同服务eNB 104发送的干扰无线电信号112。UE#1可配置干扰消除接收机,以从所需信号中消除干扰信号的影响。
假定NOMA操作中发送机采用叠加解码方案。给定一NOMA场景,其中UE#1和UE#2被调度在相同的时间-频率资源,且意图发送给UE#1和UE#2的TB叠加,并以不同的发送功率电平(P1>P2)组播(multi-cast)给两个用户。假设UE#1比UE#2离基站(eNB 104)更近,UE#1和UE#2分别被称为高几何状态(high-geometry)UE和低几何状态(low geometry)UE。根据NOMA的信号接收规则,UE#1的接收机应对意图发送给UE#2的TB进行CW-IC。具体来说,UE#1对意图发送给UE#2的TB进行解码,在接收信号中重建UE#2的信号,并随后将重建信号从接收信号中减去,以形成干净的(clean)接收信号。UE#1因此可通过干净的接收信号对其自己的信号进行解码。当UE#1对UE#2的TB解码失败时,若UE#1存储该TB的软信道比特,有利于对该TB的下一次解码。因此,当采用NOMA时,高几何状态UE不仅为其自己的信号,也为需被CW-IC处理的干扰信号配置软缓冲区是有好处的。这样一来,干扰TB的多次传送(重传)可被组合,以提高解码的成功率。
在LTE中,速率匹配算法重复或击穿源码字中的比特,以根据时间-频率资源的尺寸和所需码率(可能与信道编码器的源码率不同)生成所需数目的比特。此外,若要采用软分组组合来增强解码性能,速率匹配也需要考虑接收机处码块的软缓冲区尺寸。在叠加编码方案中,意图发送给UE#2的传输块将被U#1和UE#2解码。然而,由于每个码块的软缓冲区尺寸取决于UE类别,两个接收机的软缓冲区尺寸可能并不相同。根据一新颖性方面,在叠加编码中,速率匹配的两个问题,即发送机(eNB 104)处的软缓冲区尺寸设定和接收机(UE#1)处的软信道比特存储被讨论和解决。
此外,接收机中的软缓冲区为所需信号预留,以及为干扰信号预留以由CW-IC进行处理。如此一来,UE和网络应在对两种类型的信号的软缓冲区分区上有相同的理解。否则,一些传输块的软信道比特可能无法累积,而多次 传送(重传)的软分组组合也无法有效运作。而在Rel-12LTE中,软缓冲区仅为所需TB预留,且用于TB的分区方案有关于DL HARQ进程的数量。因此,提出一种在叠加编码中用于所需以及干扰TB的软缓冲区分区和限制激活DL HARQ进程的总数的方法。
图2是在移动通信网络200中执行本发明一些实施例的基站201和UE 211的简化方块示意图。对于基站201来说,天线221发送和接收无线电信号。RF收发机模块208耦接至天线,从天线接收RF信号,转换为基带信号,并将基带信号发送给处理器203。RF收发机208也将从处理器接收的基带信号转换为RF信号,并将RF信号发送给天线221。处理器203处理接收到的基带信号,并调用不同的功能模块来执行基站201的功能。存储器202存储程序指令和数据209,以控制基站的操作。UE 211存在类似的配置,其中天线231发送和接收RF信号。RF收发机模块218耦接至天线,从天线接收RF信号,转换为基带信号,并将基带信号发送给处理器213。RF收发机218也将从处理器接收的基带信号转换为RF信号,并将RF信号发送给天线231。处理器213处理接收到的基带信号,并调用不同的功能模块来执行UE 211的功能。存储器212存储程序指令和数据219,以控制UE的操作。存储器212也包括多个软缓冲区220,以存储编码码块(encoded code block)的软信道比特。
基站201和UE 211也包括多个功能模块,以执行本发明的一些实施例。不同的功能模块为电路,可通过软件、固件、硬件或任何上述的组合配置与实现。功能模块被处理器203和213执行(如通过执行程序代码209和219)时,可允许基站201调度(通过调度器204),编码(通过编码器205),映射(通过映射电路206),以及发送控制信息和数据(通过控制电路207)给UE 211;并允许UE 211接收,解映射(通过解映射器216),和依照干扰消除能力对控制信息和数据(通过控制电路217)解码(通过解码器215)。在一示范例中,基站201提供其他UE的码块软缓冲区尺寸给UE 211。在NOMA操作中,一经接收到意图发送给其他UE的叠加码块和相应的软缓冲区尺寸,UE 211随后能够通过HARQ处理器232进行HARQ,将软信道比特存储到用于所需和干扰TB的分区后软缓冲区中,并通过IC电路233进行CW-IC,以对叠加码块进行解码,并相应消除干扰信号的影响。
图3是通信系统中发送装置的功能性方块示意图,其将TB的信息比特映射 为码字,再将码字映射为基带信号以进行传送。在步骤301中,信息比特被放到TB中,并附着(attach)在CRC上。此外,TB被分割成码块并附着在CRC上。在步骤302中,信道编码(如Turbo编码的前向纠错)以特定码率进行。在步骤303中,进行速率匹配,以建立具有所需码率的输出,且TB被映射为码字。在步骤304中,码字基于预定义扰码(scramble)规则(如按UE对应的无线网络临时标识符(Radio Network Temporary Identifier,RNTI)扰码)扰码。在步骤305中,进行调制映射,其中码字基于各种调制阶数(如PSK,QAM)进行调制,以获得复值(complex-valued)调制符号。在步骤306,进行层映射(layer mapping),其中基于采用的发送天线的数目,复值符号被映射到不同的MIMO层。在步骤307中,进行预编码,其中每个天线端口有特定的预编码矩阵索引(Precoding Matrix Index,PMI)。在步骤308中,每个天线的复值符号被映射到相应的物理资源块(Physical Resource Block,PRB)的资源元素上。最后在步骤309,OFDM信号产生,用于通过天线端口进行的基带信号传送。
在接收端,UE预留软缓冲区以存储软信道比特,用于HARQ软分组组合和接收到信息比特的解码。TB的软缓冲区尺寸可表示为NIR比特(也称为子缓冲区尺寸),码块的软缓冲区尺寸表示为Ncb比特(也称为码块软缓冲区尺寸)。根据3GPP TS 36,212,尺寸Ncb可按照如下公式确定:
其中
-NIR是TB的软缓冲区尺寸;
-C是一个码字中包含的码块的数目;以及
-Kw是turbo编码器的输出的尺寸。
速率匹配和软信道比特存储
图4是eNodeB处的LTE速率匹配进程和UE处的HARQ软分组组合的示意图。在eNodeB处,信息比特以码率R=1/3进行turbo编码,以产生Kw个编码比特。发送的编码比特的数目基于所分配的时间-频率资源的尺寸和指定给UE的调制编码方案(Modulation Coding Scheme,MCS)确定。可应用两步骤的速率匹配。第一步骤仅在Ncb<Kw时应用,目的是击穿编码比特,使得被击穿编码比特不超过软缓冲区尺寸Ncb。在第二步骤,E个连续编码比特从被击穿编 码比特(第一步骤的输出)中选出,其中E是根据所分配资源的尺寸和MCS确定的比特的数目。如图4所示,E个编码比特的起始点由冗余版本(Redundancy Version,RV)的值RVi,i=0,1,2,3决定。在重传事件中,采用不同的RVi以在增量冗余软分组组合方案中获取更高的编码增益。
在UE接收机处,计算第j次传送(重传)的对数似然比(Log Likelihood Ratio,LLR){bj(k);k=0,1,…,E-1},其中LLR也称为软信道比特。若码块的软缓冲区是空的,软信道比特存储在尺寸为Ncb的软缓冲区中;否则,软缓冲区中存储的软信道比特基于新计算出的{bj(k)}更新。最后,进行turbo解码以恢复信息比特。
图5是叠加编码的LTE速率匹配的第一实施例的示意图,其中eNodeB基于每个UE预留的码块软缓冲区尺寸Ncb,确定用于速率匹配的软缓冲区尺寸。在图5所示的示范例中,UE#1和UE#2为相同时间-频率资源中被调度的两个UE,且意图发送给UE#1和UE#2的TB叠加。根据NOMA的信号接收规则,若UE#1是高几何状态UE,则意图发送给UE#2的TB将在UE#1和UE#2的接收机处解码。UE#1和UE#2的每个码块的软缓冲区尺寸分别被标示为Ncb,1和Ncb,2,并且假定Ncb,1<Ncb,2。在本实施例中,速率匹配的第一步骤基于UE#2(TB的目标UE)的软缓冲区尺寸Ncb,2,在eNodeB处进行。也就是说,前Ncb,2比特从长度为Kw的turbo编码器输出中选出。在速率匹配的第二步骤,E个连续比特从第一步骤的输出比特序列中选出。
根据一新颖性方面,eNodeB发送机处用于速率匹配的软缓冲区尺寸Ncb,2应发送给UE#1,以用于码块解码。码块的冗余版本也应发送。如图5所示,在UE#1的接收机处,所有的软信道比特{bj(k);k=0,1,…,E-1}被输入到turbo解码器中。若解码失败,且软信道比特要被存储到软缓冲区中,当Ncb,1<Ncb,2,时,UE#1接收机处预留的缓冲区尺寸不足以存储所有的Ncb,2个软信道比特。如此一来,只有对应于长度turbo编码器输出的前Ncb,1个比特的软信道比特才被存储,对应于剩余Ncb,2-Ncb,1个编码比特的软信道比特被丢弃(discard)。在UE#2的接收机处,由于接收机的每码块软缓冲区尺寸与速率匹配的第一步骤采用的软缓冲区尺寸相同,软信道比特存储的行为与传统LTE系统中的相同。
图6是叠加编码的LTE速率匹配的第二实施例的示意图,其中eNodeB基于涉及叠加编码的两个UE所预留的码块软缓冲区尺寸中的最小尺寸Ncb,确定 用于速率匹配的软缓冲区尺寸。在图6所示的示范例中,UE#1和UE#2为相同时间-频率资源中被调度的两个UE,且意图发送给UE#1和UE#2的TB叠加。根据NOMA的信号接收规则,若UE#1是高几何状态UE,则意图发送给UE#2的TB将在UE#1和UE#2的接收机处解码。UE#1和UE#2的每个码块的软缓冲区尺寸分别被标示为Ncb,1和Ncb,2,并且假定Ncb,1<Ncb,2。在本实施例中,速率匹配的第一步骤基于码块软缓冲区尺寸Ncb=min(Ncb,1,Ncb,2)。在eNodeB处进行速率匹配采用的软缓冲区尺寸Ncb应发送给UE#1和UE#2,以用于码块解码。码块的冗余版本也应发送。由于Ncb≦Ncb,1且Ncb≦Ncb,2,软信道比特存储的行为与传统LTE系统中的相同。
图7是根据一新颖性方面的从eNB角度的速率匹配和软信道比特存储方法的流程图。在步骤701中,基站对第一码块进行编码,其中该第一码块将要通过时间-频率资源发送给第一UE。在步骤702中,基站对第二码块进行编码,其中该第二码块将要发送给第二UE。其中,第一码块和第二码块叠加。在步骤703中,基站基于第一码块的第一软缓冲区尺寸,对第一UE进行速率匹配。在步骤704中,基站基于第二码块的第二软缓冲区尺寸,对第二UE进行速率匹配。在步骤705中,基站发送两个码块的编码信息块。基站也将第二软缓冲区尺寸的信息发送给第一UE以用于干扰消除。
图8是根据一新颖性方面的从UE角度的速率匹配和软信道比特存储方法的流程图。在步骤801中,第一UE从基站接收与意图发送给第一UE的第一码块有关的多个第一编码信息比特。在步骤802中,第一UE从基站接收与意图发送给第二UE的第二码块有关的多个第二编码信息比特。第一码块与第二码块叠加。在步骤803中,第一UE对第一码块进行解码,并且若对第一码块解码失败,按照第一码块软缓冲区尺寸存储多个第一信息比特的软信道比特。在步骤804中,第一UE对第二码块进行解码,并且若对第二码块解码失败,按照第二码块软缓冲区尺寸存储多个第二信息比特的软信道比特。
软缓冲区分区
在Rel-12LTE中,软缓冲区仅对所需TB预留。不同分量载波(component carrier)、HARQ进程和空间层中携带的TB的分区方案将在以下进行简要描述。TB的软缓冲区尺寸可表示为NIR比特(也被称为子缓冲区尺寸)。根据3GPP TS 36.212的最近版本,尺寸NIR可按照如下公式确定:
其中
-Nsoft:软信道比特的总数;
-KC∈{1,2,5}:基于Nsoft和UE所支持空间层的数目而决定;
-KMIMO:若UE被配置为基于传送模式3、4、8、9或10接收PDSCH传送,则等于2。否则,等于1;
-MDL_HARQ:DL HARQ进程的最大数目;以及
-Mlimit:等于8的常量。
对于频分双工(Frequency Division Duplex,FDD)LTE系统来说,DL HARQ进程的最大数目MDL_HARQ等于8。对于时分多工(Time Division Duplex,TDD)LTE系统来说,基于TDD下行链路-上行链路配置,MDL_HARQ在4以上15以下进行变化。min(MDL_HARQ,Mlimit)意味着BS不会给一个UE的每个分量载波安排多于min(MDL_HARQ,Mlimit)的“激活”DL HARQ进程。因此,UE不需要预留多于KC×KMIMO×min(MDL_HARQ,Mlimit)个TB的软缓冲区。一个激活DL HARQ进程意味着与DL HARQ进程有关的TB已被UE接收但尚未成功解码,而软信道比特存储在软缓冲区中。
在DL HARQ进程的最大数目小于Mlimit的TDD系统中或FDD系统中,等式min(MDL_HARQ,Mlimit)=MDL_HARQ成立。只要采用的DL HARQ进程不多于MDL_HARQ,就不会发生用于TB的软缓冲区不足的问题。然而,对于DL HARQ进程的最大数目大于Mlimit的TDD系统来说(即TDD上行链路-下行链路配置2、3、4和5),BS将不会给用户每个分量载波同时安排多于Mlimit的“激活”DL HARQ进程,以避免用于TB的软缓冲区空间不足。
图9是基于等式(2)中给出的NIR的公式的软缓冲区分区的示意图。软缓冲区可容纳Nsoft个软信道比特。软缓冲区被划分为KC×KMIMO×min(MDL_HARQ,Mlimit)个等尺寸的子缓冲区。图9左上角绘示出了阴影子缓冲区901。具有长度NIR的一个TB的软信道比特存储在阴影子缓冲区901中。在一新颖性方面,限制激活DL HARQ进程的数目,以节约TDD上行链路-下行链路配置2、3、4和5的软缓冲区尺寸的想法可用于叠加编码中的软缓冲区分区。
图10是与所需和干扰信号有关的下行链路HARQ进程的示意图。图10绘示了“干扰信号的DL HARQ进程”的意思。在图10所示的示范例中,TB1和TB2在相同时间-频率资源上叠加,且从UE#1的角度来说,TB1和TB2分别为所需TB(意图发送给高几何状态UE#1)和干扰TB(意图发送给其他UE)。TB1和TB2的传送均在子帧3发生。假定两个TB均在子帧3遇到解码失败,如此一来,所需信号的激活DL HARQ进程的数目在子帧3到10为1,且在相同的间隔,干扰信号的激活DL HARQ进程的数目为1。TB1和TB2的重传在子帧11发生。假定TB1的解码失败,TB2的解码成功。如此一来,TB2的软信道比特可被清除,干扰信号的激活DL HARQ进程的数目变为0,所需信号的激活DL HARQ进程的数目保持为1。
所提出的叠加编码中的软缓冲区分区的方法描述如下。NIR公式将保持不变,除了min(MDL_HARQ,Mlimit)替换为值PMAX。也就是说,
其中
-Nsoft:软信道比特的总数;
-KC∈{1,2,5}:基于Nsoft和UE所支持空间层的数目而决定;
-KMIMO:若UE被配置为基于传送模式3、4、8、9或10接收PDSCH传送,则等于2。否则,等于1;
-PMAX:激活DL HARQ进程的最大总数目。
图11是基于激活DL HARQ进程的最大总数目PMAX的软缓冲区分区方法的示意图。激活DL HARQ进程的最大总数目PMAX包括用于所需信号的激活DL HARQ进程的第一数目,加上用于干扰信号的激活DL HARQ进程的第二数目。假定对UE来说,需要在叠加编码中采用码字级干扰消除,BS调度器一般不会给UE的每个分量载波安排多于PMAX个激活DL HARQ进程,包括与所需TB有关的DL HARQ进程以及与干扰TB有关的DL HARQ进程。举例来说,若高几何状态UE在分量载波中具有T个用于所需TB的激活DL HARQ进程,则分量载波中用于干扰TB的激活DL HARQ进程的数目不多于(PMAX-T)个。
PMAX的值可通过任何参数,如DL HARQ进程的最大数目的预定义公式确定,且UE和网络可自行计算PMAX。PMAX的值也可由BS配置并发送给UE。用与所需和干扰TB的软缓冲区的尺寸可由BS调度器在每个分量载波和每个时刻(time instant)动态调整。只要激活DL HARQ进程的总数不超过PMAX,软缓冲区尺寸对于激活TB来说即够用。一种极端情况是干扰TB的软缓冲区尺寸为0。在此情况下,没有软分组组合用于干扰TB。
采用所提出的方法,对应于所需TB的DL HARQ进程和对应于干扰TB的DL HARQ进程的软缓冲区尺寸相同。若两种类型的DL HARQ进程需要具有不同的软缓冲区尺寸,则可对两种类型的DL HARQ进程的软缓冲区尺寸进行微量调整。在一示范例中,对应于所需信号的子缓冲区的尺寸与对应于干扰信号的子缓冲区的尺寸的比值为预定义值。在另一示范例中,对应于所需信号的子缓冲区的尺寸与对应于干扰信号的子缓冲区的尺寸的比值可配置(configurable)。
图12是用于所需以及干扰信号的具有软信道比特存储和软缓冲区分区的叠加编码进程的示意图。在步骤1211中,服务基站BS 1201调度第一UE#1和第二UE#2进行NOMA操作。UE#1是高几何状态UE,UE#2是低几何状态UE。在步骤1212中,BS通过PDCCH发送控制信息给UE#1和UE#2。控制信息可包括UE#2的码块软缓冲区尺寸信息,并可包括UE#1的总激活DL HARQ进程的最大数目。在步骤1213中,BS在NOMA下发送叠加传输块TB1和TB2给UE#1和UE#2。TB1的编码和速率匹配基于UE#1的第一软缓冲区尺寸,而TB2的编码和速率匹配基于UE#2的第二软缓冲区尺寸。
在步骤1221中,UE#1试图基于与接收到的所需信号有关的编码信息比特对TB1进行解码。在步骤1222中,UE#1试图基于与接收到的干扰信号有关的编码信息比特对TB2进行解码。需注意,UE#1仅在从BS获知第二码块软缓冲区尺寸时,才试图对TB2进行适当解码。若TB1/TB2的解码未成功,UE#1在软缓冲区中存储编码信息比特的软信道比特。TB1/TB2将以另一冗余版本重传,且UE#1将试图进行HARQ软分组组合和再次解码。在步骤1223中,UE#1在接收信号中重建干扰信号TB2,并通过将重建干扰信号从接收信号中减去进行CW-IC。在步骤1231中,BS为UE#1和UE#2调度更多的下行链路传送。在步骤1232中,BS发送更多的TB给UE#1和UE#2。尽管通常来说BS将不会在 NOMA方案中给高几何状态的UE调度多于PMAX的DL HARQ进程,有时可能会发生例外。若激活DL HARQ进程的数目大于PMAX,则UE可基于所需和干扰TB的优先级设定,重新安排软缓冲区分配。
在第一种选择(步骤1241)中,对应于所需信号的TB比干扰信号的TB具有更高的优先级。假定所有的软缓冲区分区(子缓冲区)已被占满。在第一场景中,对应于所需信号的新的DL HARQ进程被激活。若子缓冲区已被干扰信号的DL HARQ进程所占据,则存储在子缓冲区中的干扰信号的软信道比特被清除,且新的所需TB的软信道比特被存储在被清空的子缓冲区中。否则,新的DL HARQ进程的软信道比特被丢弃。在第二种场景中,对应于干扰信号的新的DL HARQ进程被激活。新的DL HARQ进程的软信道比特被丢弃。在第二种选择(步骤1242)中,对应于所需信号和干扰信号的TB具有相同的优先级。若所有的子缓冲区已被占据,新激活的DL HARQ进程的软信道比特总是被丢弃。
图13是根据一新颖性方面的从eNB角度的软缓冲区分区方法的流程图。在步骤1301中,基站对第一码块进行编码,其中第一码块将要通过时间-资源块发送给第一UE。在步骤1302中,基站对第二码块进行编码,其中第二码块将要发送给第二UE。第一码块和第二码块叠加。在步骤1303中,基站确定第一UE的总激活DL HARQ进程的最大数目,其中最大数目包括所需信号的激活DL HARQ进程的第一数目,加上干扰信号的激活DL HARQ进程的第二数目。在步骤1304中,基站基于总激活DL HARQ进程的最大数目(如不超过该最大数目)调度第一UE的DL传送。
图14是根据一新颖性方面的从UE角度的软缓冲区分区方法的流程图。在步骤1401中,UE获取总激活DL HARQ进程的最大数目,其中最大数目包括所需信号的激活DL HARQ进程的第一数目,加上干扰信号的激活DL HARQ进程的第二数目。在步骤1402中,UE将缓冲区划分为具有第一子缓冲区尺寸的第一数量的子缓冲区,和具有第二子缓冲区尺寸的第二数量的子缓冲区。在步骤1403中,UE在第一数量的子缓冲区之一存储与所需信号有关的多个第一软信道比特。在步骤1404中,UE在第二数量的子缓冲区之一存储与干扰信号有关的多个第二软信道比特。
本发明虽以较佳实施例揭露如上以用于指导目的,但是其并非用以限定 本发明的范围。相应地,在不脱离本发明的范围内,可对上述实施例的各种特征进行变更、润饰和组合。本发明的范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!