自适应混响消除系统的制作方法
本发明涉及信号处理器、声音设备,以及生成多个用于驱动多个扬声器消除收听区域中混响效果的驱动信号的方法。本发明还涉及一种计算机可读存储介质。
背景技术:
在一个感兴趣的区域再现期望的多区域声场近年来引起了研究人员的注意。但是,这方面的大部分现有工作都没有考虑到实际的多区域声音再现系统会遇到的混响环境。由于混响房间信道未知,而且现有声场再现系统需要大量的扬声器和麦克风,因此很难对混响补偿过程进行处理。
混响是从外壳表面反射的声音的集合。当声音或信号在封闭的环境中反射时,会产生大量的反射,然后随着声音被墙壁、散射体和空气吸收而逐渐衰减。当声源停止时,这是最明显的,但是反射持续存在直到达到零幅度。大多数声场再现技术都是用自由场假设来设计的,但在大多数实际实现中情况并非如此。
房间混响是声场再现中的一个主要挑战,而对听众来说,不必要的混响通常会导致较差的声场再现以及定位困惑。因此,混响消除技术对于具有真实世界设置的再现系统是必不可少的。最自然的方法是无源技术。例如,房间可以配备吸音材料,从而提供适度的声音反射衰减。然而,相关成本对这种方法构成了重大挑战,并且在许多现实世界的应用场景(例如,办公室或家庭环境中的声场再现)中难以实现。技术上更先进的无源方法可以使用固定的或可变的方向性更高阶的扬声器,从而使得指向房间墙壁的声波辐射最小化。然而,这需要一些特定的声音再现装置,这在实践中是难以实现的。
为了均衡房间混响,房间响应的倒数通常应用于扬声器驱动信号。已经提出了基于模式匹配的技术,从而在混响室的整个控制区域上精确地再现单区域声场。引入了利用稀疏方法在期望的区域内再现多区域声场的方法。这使得随机放置的较少测量值在平面波分解领域中在期望的区域上大概地估计来自扬声器的房间传递函数。然后使用该估计值得到扬声器滤波器增益的最佳最小二乘解。对于这些方法,需要事先测量所有使用的扬声器的房间传递函数。这在实践中实施起来非常耗时,其性能在测量过程中易受周围环境条件的任何变化的影响。
波域自适应滤波(Wave Domain Adaptive Filtering,简称WDAF)是混响消除在声场再现中应用的一种更为实用的方法。已经介绍了波场合成系统中主动收听房间补偿。分别利用麦克风阵列输入和扬声器输出的变换对声场的波域表示进行了描述。这些技术遭遇了实际问题,例如,房间信道估计需要大量的麦克风。另外,这些技术中的自适应过程在一些混响环境中会出现分歧,这些混响环境具有较低的直接到混响路径功率比。需要迭代计算每次迭代中的伪逆,这可能导致病态性问题和信道估计误差。
技术实现要素:
本发明的目的在于提供一种信号处理器、声音设备,以及生成用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的方法,其中,信号处理器、声音设备,以及生成用于驱动多个扬声器以消除收听区域中混响效果的多个驱动信号的方法克服了现有技术中的一个或多个上述问题。
本发明的第一方面提供了确定用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的信号处理器,其中,该信号处理器用于:
基于物理声音函数从一个或多个测量的音频信号中确定多个测量的物理系数,使得所述多个测量的物理系数加权的物理声音函数之和近似于所述一个或多个测量的音频信号,其中,所述多个测量的物理系数中的至少一半为零;
确定所述多个测量的物理系数与多个期望的物理系数之间的残差;
基于所述确定的残差估计传递函数,其中,所述传递函数描述了从所述多个期望的物理系数到所述多个测量的物理系数的变换;
基于所述估计的传递函数更新所述多个驱动信号;其中,
所述信号处理器用于执行一次、两次或更多次上述步骤,例如,重复执行上述步骤。
用于现有声音再现系统的大量扬声器-麦克风信道的必要性使得混响环境中多区域声场再现的应用变得复杂。第一方面的信号处理器使用稀疏方法提供了用于多区域声场再现的自适应混响消除。该稀疏方法的使用导致需要的用于估计再现声场的麦克风的数量显着减少。信号处理器还有助于系统在混响环境中在较宽的频率范围内收敛。
在本发明实施例中,更新多个驱动信号包括计算更新滤波器,即反映混响消除的一组更新滤芯的步骤。
优选地,信号处理器用于重复地执行上述步骤,直到残差足够小,例如,小于预定阈值。
数学上来说,第一方面的信号处理器可以用于找到稀疏矢量b,使得Φb近似于测量的信号v,其中,Φ是具有包括物理声音函数的列的矩阵。
第一方面的信号处理器可以用于多区域声场再现系统,其包括Q个扬声器和M个麦克风的圆形阵列。扬声器放置在期望的再现区域之外,麦克风可以随意放置在所选的感兴趣区域内。所提出的系统例如可以应用于电话会议系统和汽车音频系统,其中,采用了圆形或线性扬声器阵列,并且麦克风可以自由分布在听众周围。自适应混响消除系统旨在基于来自稀疏麦克风测量的迭代反馈对混响效果进行纠正,并通过具有更新的FIR增益滤波器的扬声器阵列主动回放输入信号。
假定lq(t)作为第q个扬声器的驱动信号,vm(t)作为第m个麦克风测量值的记录信号。采用傅里叶变换,麦克风处接收的测量值可以以矩阵形式表示为:
v(k)=C(k)l(k) (1)
其中,l(k)=[l1(k),...,lQ(k)]T是扬声器驱动信号,v(k)=[v1(k),...,vM(k)]T是麦克风测量值,C(k)表示频率k下的第(m,q)个麦克风-扬声器对之间的信道。注意,可以将信道效果C(k)分成直接和混响路径C(k)=Cd(k)+Cr(k),其中,Cd(k)和Cr(k)表示第(m,q)个麦克风-扬声器对之间的直接和混响信道。
在一个优选实施例中,使用基函数集{Gn}的正交集合,其通过实施从各个角度到达的平面波函数上修改的Gram-Schmidt过程,对任何物理上可行的声场进行描述。因此,将(1)中的测量值表示为:
其中,bn(k)是再现声场的系数,xm表示第m个麦克风位置。注意,将N设置为足够大。可以将多个测量的物理系数看作是稀疏近似,即,近似解决了尚未确定的线性方程系统的稀疏矢量y。v中的测量值是感知矩阵Φ和稀疏信号y的行的乘积。为了从不充分的观察值v中对y进行准确和稳定的估计,当y足够稀疏时,如果观察值是稀疏信号在非相干基础上的线性投影,则是有利的。所提出的公式与这个要求是一致的,即v中声压场的随机采样与y的原始基础是不相关的。
在根据第一方面所述的信号处理器的第一种实现方式中,所述信号处理器还用于在确定所述多个测量的物理系数时,将所述测量的音频信号与所述测量的物理系数的线性变换之间的误差测量最小化,并将所述多个测量的物理系数的非零项的数量最小化。
线性变换可以是一个感知矩阵,即,它可以在其列中包含物理声音函数基础的基函数向量。通过同时将误差测量最小化和将多个测量的物理系数的非零项的数量最小化,确保在仍然获得多个测量的物理系数的稀疏矢量b的同时,尽可能准确地处理测量值。这可以很容易地进行处理。
在根据第一方面所述的信号处理器的第二种实现方式中,所述信号处理器还用于在将所述误差测量最小化,并将所述多个测量的物理系数的非零项的数目最小化时,根据以下等式确定所述多个测量的物理系数的矢量b:
其中,||y||p是向量y的p-范数,Φ是包括具有所述物理声音函数N>>M的列的感知矩阵M×N,v是观察向量M×1,其包括所述收听区域内M个位置对应的所述一个或多个测量的音频信号,其中,特别地,M个位置是随机选择的。
一个实施例中,感知矩阵Φ是M×N感知矩阵,其列优选包含M个麦克风位置处的基函数Gn(x;k)的值。
信号处理器可以包括用于获得关于M个位置的信息的输入,即位置可以是随机的,但对于信号处理器是已知的或近似已知的。
这代表了计算多个测量物理系数的一种特定有效的方式。
在根据第一方面所述的信号处理器的第三种实现方式中,物理声音函数的所述基础与内积是正交的,对于第一矢量bi和第二矢量bj,其可以表示为:
<bi|bj>=∫Rbi(x)bj(x)w(x)dx=σij
其中,R是所述多个扬声器的再现区域,w(x)是加权函数,对于i=j,σij为1,否则为0。换言之,可以将物理声音函数的基础选择为与定义为再现区域上的积分的内积正交,例如,多个扬声器之间的区域。
在根据第一方面所述的信号处理器的第四种实现方式中,物理声音函数的所述基础包括物理声音函数的正交集合,其中,所述物理声音函数是从多个角度对应的平面波函数上修改的Gram-Schmidt过程中获得的。
这具有以下优点:可以使用物理声音函数的基础描述任何可行的声场,并且以加权的最小二乘意义匹配期望的声场。
在根据第一方面所述的信号处理器的第五种实现方式中,所述传递函数指定所述物理声音函数的所述基础的第一与第二系数之间的零耦合,其中,特别地,所述传递函数可以表示为对角矩阵U(k)。
假定物理声音函数的基础的不同系数之间的传递函数的零耦合具有计算简化的优点。特别地,作为对角矩阵U(k)的传递函数的对角表示可以极大地简化计算。
在根据第一方面所述的信号处理器的第六种实现方式中,所述信号处理器还用于在估计所述传递函数时,使用最小均方滤波器和/或使用递归最小二乘滤波器估计所述对角矩阵U(k)。这些表示了计算对角矩阵的有效方法。
在根据第一方面所述的信号处理器的第七种实现方式中,所述信号处理器还用于在估计所述对角矩阵U(k)时,根据以下等式计算所述对角矩阵U(k)的第n个元素:
其中,是增益因子,优选地定义为λ是遗忘因子,是所述对角矩阵的第τ次迭代的第n个对角元素,是所述多个期望的物理系数的第n个元素,是所述多个测量的物理系数的第τ次迭代的第n个元素。
这代表了对对角矩阵U(k)进行迭代计算的一种特别有效的方式。
在根据第一方面所述的信号处理器的第八种实现方式中,所述信号处理器还用于在更新所述驱动信号时,计算驱动信号更新σ*,使得所述驱动信号更新σ*的能量水平受限于上限,其中,特别地,将所述驱动信号更新σ*的所述能量水平计算为σ*的平方值。
限制驱动信号更新的能量水平具有以下优点:将驱动信号更新为期望的最佳驱动信号这一过程以小步骤进行。因此,避免了驱动信号更新期间不期望的声音效果。
在根据第一方面所述的信号处理器的第九种实现方式中,所述信号处理器还用于在更新所述驱动信号时,将所述驱动信号更新σ*计算为:
s.t.||σ(k)q||2≤N1q=1...Q
其中,Gd(k)表示假定自由场传播的所述多个扬声器的格林函数的预定声场系数矩阵,I是单位矩阵,是所述对角矩阵的估计,N1是预定参数,特别地,N1=(1-β(k)2)/Nw,其中,β(k)是反射系数,Nw是所述收听区域的墙壁数量。
这表示了实现驱动信号更新的有效方式。特别地,上面定义的迭代过程利用了矩阵U(k)的对角结构并限制了驱动信号更新的能量水平。
在根据第一方面所述的信号处理器的第十种实现方式中,所述信号处理器还用于执行将所述驱动信号更新σ*预处理为0和/或将所述对角矩阵U(k)预处理为单位矩阵的初始步骤。
初始预处理步骤的优点在于:以合理的起始点对多个驱动信号进行初始化,并且信号处理器执行的方法实现方式可以因此更快地趋向于期望的最优解。
在本发明实施例中,信号处理器用于通过确定更新滤波器确定驱动信号更新。在这种情况下,可以将更新滤波器可以预处理为0,即,将更新滤波器预处理为零更新。
本发明的第二方面涉及生成用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的声音设备,其中,该声音设备包括:
输出,用于利用所述多个驱动信号驱动所述多个扬声器;
输入,用于接收一个或多个测量的音频信号;
根据第一方面或者第一方面任意一种实现方式所述的信号处理器,其中,所述信号处理器用于更新所述多个驱动信号。
本发明的第三方面涉及生成用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的方法,其中,该方法包括:
使用初始的多个驱动信号驱动所述多个扬声器;
在一个或多个测量位置上测量一个或多个音频信号;
基于物理声音函数从一个或多个测量的音频信号中确定多个测量的物理系数,使得所述多个测量的物理系数加权的所述物理声音函数之和近似于所述一个或多个测量的音频信号,其中,所述多个测量的物理系数中的至少一半为零;
确定所述多个测量的物理系数与多个期望的物理系数之间的残差;
基于所述确定的残差估计传递函数从所述多个期望的物理系数到所述多个测量的物理系数的变换;
基于所述估计的传递函数更新所述初始的多个驱动信号,其中,可以一次、两次或更多次执行上述步骤,例如,重复地执行。
根据本发明第三方面的方法可以由根据本发明第一方面的信号处理器执行。根据本发明第三方面的方法的其他特征或实现方式可以执行根据本发明第一方面的信号处理器的功能及其不同的实现方式。
在根据第三方面所述的方法的第一种实现方式中,将所述误差测量最小化,并将所述多个测量的物理系数的非零项的数目最小化包括步骤:根据以下等式确定所述多个测量的物理系数的矢量b:
其中,||y||p是向量y的p-范数,Φ是包括具有所述物理声音函数N>>M的列的感知矩阵M×N,v是观察向量M×1,其包括所述收听区域内M个位置对应的所述一个或多个测量的音频信号,其中,特别地,信号处理器用于随机选择M个位置。
本发明的第四方面提供了一种存储程序代码的计算机可读存储介质,所述程序代码包括用于执行第三方面或者第三方面任意一种实现方式提供的方法的指令。
附图说明
为了更清楚地说明本发明实施例中的技术特征,下面将对实施例描述中所需要使用的附图作简单地介绍。下面描述中的附图仅仅是本发明的一些实施例,这些实施例在不违背本发明如权力要求书中所定义的保护范围的情况下,可以进行修改。
图1示出了根据本发明实施例的信号处理器;
图2示出了根据本发明另一实施例的声音设备;
图3示出了根据本发明另一实施例的混响消除方法的流程图;
图4示出了根据本发明另一实施例的多区域声场再现系统的结构;
图5示出了根据本发明另一实施例的自适应混响消除系统的操作概况;
图6示出了根据本发明另一实施例的混响消除方法的简化流程图。
具体实施方式
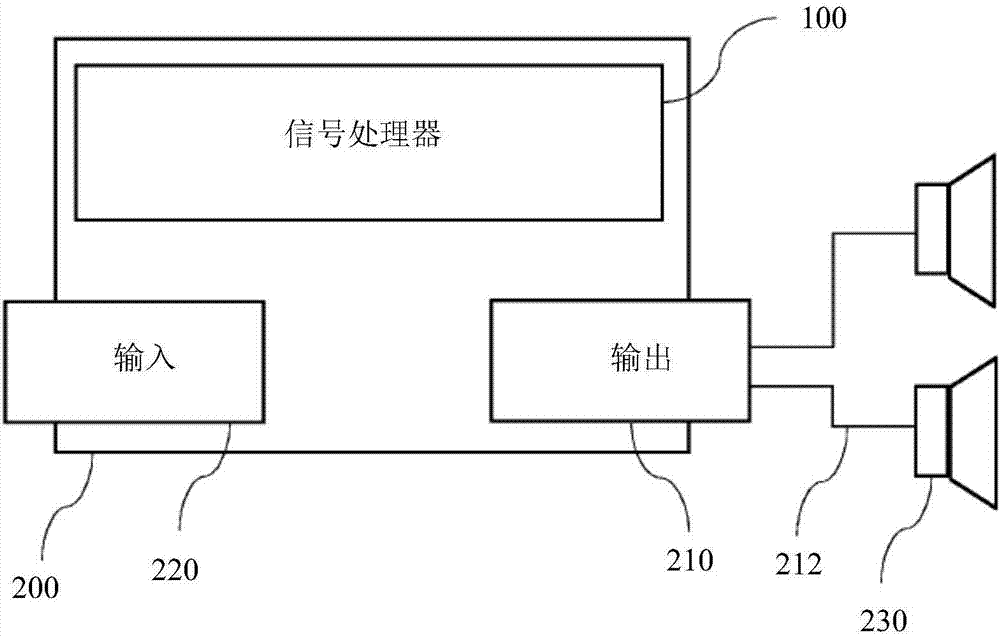
图1示出了确定用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的信号处理器100。
信号处理器100包括系数单元110,该系数单元110用于根据物理声音函数从一个或多个测量的音频信号中确定多个测量的物理系数,使得多个测量的物理系数加权的物理声音函数之和近似于所述一个或多个测量的音频信号,其中,所述多个测量的物理系数中的至少一半为零。物理声音函数的基础可以是固定的,或者可以有几个物理声音函数的基础,其中,可以选择一个具体的基础,例如,通过设置基础选择参数。
信号处理器100还包括残差单元120,该残差单元120用于确定多个测量的物理系数与多个期望的物理系数之间的残差。
信号处理器100还包括传递单元130,该传递单元130用于基于确定的残差估计传递函数,其中,该传递函数描述了从多个期望的物理系数到多个测量的物理系数的变换。
信号处理器100还包括更新单元140,该更新单元140用于基于估计的传递函数更新多个驱动信号。更新单元140可以用于生成为零的初始更新,即,初始生成输入信号对应的驱动信号。该输入信号可以由外部单元提供给信号处理器100,或者可以在信号处理器100中确定该输入信号。
信号处理器100用于控制其单元,使得它们重复计算多个驱动信号的更新。
系数单元110、残差单元120、传递单元130以及更新单元140可以用相同的物理硬件实现,例如,可以将它们实现为信号处理器100的编程的不同部分。
图2示出了生成用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的声音设备200。该声音设备200包括输出210,用于驱动具有多个驱动信号212的多个扬声器;输入220,用于接收一个或多个测量的音频信号;信号处理器230,例如,图1中的信号处理器,用于更新多个驱动信号。
图3示出了生成用于驱动多个扬声器消除收听区域中混响效果的多个驱动信号的方法300的流程图。该方法包括第一步骤:使用初始的多个驱动信号驱动310多个扬声器。
该方法包括第二步骤:在一个或多个测量位置上测量320一个或多个音频信号。例如,可以使用放置在收听区域中随机位置上的麦克风,测量一个或多个音频信号。该方法可以包括另一步骤:确定随机放置的麦克风的位置,使得测量的音频信号可以与相应的麦克风的位置相关。
在第三步骤330中,基于物理声音函数从一个或多个测量的音频信号中确定多个测量的物理系数,使得所述多个测量的物理系数加权的所述物理声音函数之和近似于所述一个或多个测量的音频信号,其中,所述多个测量的物理系数中的至少一半为零。特别地,可以要求多个测量的物理系数中的至少3/4,或优选地,至少90%为零。
在第四步骤340中,确定所述多个测量的物理系数与多个期望的物理系数之间的残差。
在第五步骤350中,基于所述确定的残差估计传递函数,其中,所述传递函数描述了从所述多个期望的物理系数到所述多个测量的物理系数的变换。
在第六步骤360中,基于估计的传递函数确定初始的多个驱动信号的更新版本。将初始的多个驱动信号的更新版本输出到多个扬声器。该方法可以在步骤320中继续。
在另一步骤(图3中未示出)中,可以确定是否残差小于预定的阈值误差。如果残差小于预定阈值,则可以输出更新的驱动信号,并且不执行该方法的另一迭代;如果残差大于预定阈值,则随着第一步骤继续执行该方法。现在利用更新的多个驱动信号而非初始的多个驱动信号驱动多个扬声器。
图4示出了根据本发明另一实施例的多区域声场再现系统400的结构。该多区域声场再现系统400包括自适应房间混响消除系统420、扬声器阵列410、位于第一收听区域430的第一麦克风阵列440以及位于第二收听区域432的第二麦克风阵列442。扬声器阵列定义了包括第一和第二收听区域430、432的收听区域435。
自适应房间混响消除系统420包括声音设备,例如,图2的声音设备,其包括输入、输出和信号处理器。该输入用于从第一和第二麦克风阵列440、442接收音频信号441。该输出用于用驱动信号421驱动扬声器阵列410。
图5示出了根据本发明另一实施例的多区域声场再现系统500的操作概况。该多区域声场再现系统500包括自适应混响消除系统520和位于混响房间512的扬声器阵列510。该多区域声场再现系统500还包括求和单元522。如图5所示,该求和单元522是自适应混响消除系统520外部的单元。然而,在其他实施例中,求和单元522可以是自适应混响消除系统的一部分。
在第τ次迭代中,自适应混响消除系统520生成驱动多个扬声器510的更新的驱动信号l(k)+σ(k)τ。混响房间512的墙壁反射生成的声波。
麦克风540测量再现区域中的多个音频信号541,并从这些测量的音频信号中确定多个测量的物理系数bn(k)。测量的物理系数bn(k)与多个期望的物理系数之间的差值在求和单元522中形成,并反馈到自适应混响消除系统520。基于该表示残差523的差值,自适应混响消除系统更新驱动信号,其开始了迭代混响消除过程的下一次迭代。
图6示出了根据本发明另一实施例的自适应混响方法的流程图。
在第一步骤602中,将扬声器驱动信号预处理为l(k),即,初始更新为0。
在第二步骤604中,根据物理声音函数确定多个测量的物理系数,使得基础的物理声音函数之和近似于一个或多个测量的音频信号,其中,对该总和与多个测量的物理系数一起进行加权。
基于多个测量的物理系数与多个期望的物理系数之间的差异,确定新的残差。
在第三步骤606中,使用RLS自适应滤波方法确定对角矩阵U(k)τ的对角项。
在第四步骤608中,利用更新的多个驱动信号驱动扬声器阵列。
如果该残差足够小,则该方法可以输出预定义驱动信号(例如,输入信号乘以频域中的预定义滤波器)l(k)与更新信号σ(k)之和。在本发明的实施例中,更新信号σ(k)可以基于更新过滤器确定,例如,通过将更新滤波器应用于预定义的驱动信号。
在另一步骤610中,将逆傅里叶变换应用于更新的多个驱动信号l(k)+σ(k)τ。在另一步骤612中,利用多个扬声器对傅里叶变换后的信号611进行格式化。然后,随着递增的迭代索引τ,该方法在步骤604中继续。
在下文中将更详细地描述如何使用稀疏近似方法从所选择的感兴趣区内随机放置的测量值vm(k)中计算bn(k)。
该方法的一个基本原理是假定再现声场S(x;k)仅由少数的赫姆霍兹解产生。基于这个假设,考虑下面的lp范数(其中,0<p<1)的非凸优化问题
其中,y是基函数系数集,字典Ф是M×N感知矩阵(N>>M),其列包含M个位置上Gn(x;k)的值的,v是M×1观察矢量,其包含期望的区域内M个随机选择的位置上实际再现声场S(x;k)的值。误差与他加的复杂高斯噪声水平有关。假定y为稀疏信号,即,y在未知位置上具有有限数量的非零项。因此,可以应用正规化的迭代再加权最小二乘(IterativelyReweighted Least Square,简称IRLS)算法求解方程(3),并得到最优估计器其在混响环境中具有再现声场的特征。
其中,只有m'(m'≤M)个非零分量并且可以用作基函数系数bn(k)的估计。
总的来说,基于(1)中的声场测量值对声场系数bn(k)以下列矩阵形式进行计算
b(k)=TC(k)1(k)=Tv(k) (5)
其中,b(k)=[b1(k),...,bN(k)],T是一个表示b(k)和v(k)关系的变换矩阵(N×M),可以看作是稀疏测量在正交集{Gn}跨越的子空间上的投影。
可以通过bd(k)和b(k)表征期望的多区域声场Sd(x;k)和混响房间S(x;k)中的实际再现声场,bd(k)和b(k)分别表示正交基函数集{Gn}的系数集。注意,Sd(x;k)的系数可以离线得到。
将混响房间信道看作再现声场与期望的声场之间的变换,其可以通过基函数系数的线性变换进一步表示:
b(k)=U(k)bd(k) (6)
其中,U(k)=diag[U1(k),...,UN(k)]表示波数为k的混响房间效果。注意,假设可以在定义的基函数域中忽略不同指数的声场系数之间的耦合,则用一个对角结构将U(k)参数化。可以以迭代方式对房间信道变换U(k)进行估计。更新扬声器信号后,将定义为麦克风的测量的声场系数。如果将残差的平方范数最小化,则可以对房间信道变换的进行准确的估计。这也可以将实际的再现声场与期望的再现区域上期望的多区域声场进行精确匹配。可以将此视为自适应滤波问题,可以通过使用诸如最小均方(Least Mean Square,简称LMS)滤波器和递归最小二乘(Recursive Least Squares,简称RLS)滤波器等算法,主动估计U(k)。
由于U(k)的对角结构,对未知的对角项Un(k)进行计算可以进一步简化为一个单一的自适应滤波问题。假定为第τ自适应步骤中对U(k)的估计,则可得到:
其中,为增益因子λ为遗忘因子。选择RLS算法,因为它提供了一个快速的收敛速率。因此,可以基于第τ自适应步骤中的残差,应用等式(7)获得对角元素Un(k)的迭代估计。
可以基于房间信道变换的有效估计得到扬声器阵列上的最佳滤波器更新信号。它旨在将残差最小化,保证估计收敛。对初始的扬声器阵列信号进行预处理,从而在自由场假设下再现期望的多区域声场。因此,可以通过用等式(5)中的直接信道Cd(k)代替C(k)表示期望的声场bd(k)的系数。
bd(k)=TCd(k)l(k) (8)
假定Gd(k)=TCd(k)表示自由场传播下所有扬声器的格林函数的预定声场系数矩阵。结合(6)中房间信道模型和估计器得到:
在(9)之后,在向扬声器添加更新信号σ(k)之后,测量的声场系数可以由以下等式给出:
可以用(8)和(10)写入测量的声场系数与期望的声场系数之间的差异:
其中,I为单位矩阵。
s.t.||σ(k)q||2≤N1(q=1...Q),其中,
Gd(k)可以离线计算。N1的值是可调的,取决于房间环境的混响程度。可以将其设置成小于或等于(1-β(k)2)/Nw,其中,β(k)为反射系数,Nw为墙壁的数量。注意,对每个扬声器滤波器更新信号的能量上的附加约束进行应用,使得σ(k)q的混响效果不明显,并且由此可以减轻自适应处理,从而避免对混响信道矩阵的伪逆进行有效计算。这些公式保证了系统的收敛性,并且相比现有技术而言,计算复杂性更低,收敛性更快。
总之,在本发明实施例中,将再现的声场描述为期望的再现区域上正交基函数的加权序列,然后将其用于根据基函数系数自适应地对期望的多区域声场进行均衡。提出了一种采用稀疏麦克风测量的多区域声场再现的自适应混响消除系统。所提出的方法将声场表示为扩展期望的再现区域的空间频率正交基函数。将再现的声场视为期望的声场的线性变换。然后采用稀疏方法引入自适应信道估计过程,从而直接在正交基函数域中识别这些变换,得到所需的扬声器更新信号。这些扬声器更新信号补偿了房间混响,保证了混响环境下自适应估计的收敛性。
本发明实施例的优点包括:
-所提出的信号处理器、声音设备以及方法不需要事先测量所使用的扬声器的传递函数。它们可以适应测量过程中周围环境条件的变化。
-所提出的信号处理器、声音设备以及方法通过采用稀疏方法在相同的硬件设置和环境设置下对期望的声场进行精确再现,即可以使用较少的麦克风测量值实现相同的性能。
-所提出的信号处理器、声音设备以及方法示出了良好的再现性能的更好的收敛行为,尤其是在具有低的直接到混响路径功率比的混响房间中。这是通过制定一种新的多约束凸优化以及避免对混响信道矩阵的伪逆进行主动计算实现的,保证了系统的收敛性。
-自适应混响消除系统基于较少麦克风测量值的迭代反馈纠正不需要的混响效果,使得即使在极端复杂的环境(例如,车厢)中,听众仍然可以享受精确的声场再现。
-计算复杂度更低,收敛更快。
本发明实施例的应用包括使用多个扬声器的任何声音再现系统或环绕声音系统。
特别地,本发明实施例可以应用于:
-电视扬声器系统;
-汽车娱乐系统;
-电话会议系统;和/或
-家庭影院系统;其中,
一个或多个听众的个人收听环境是令人满意的。
上文所有描述仅仅为本发明的实施方式,本发明所保护的范围并不仅限于此。任何变化或替换都可以通过本领域技术人员轻松地进行。因此,本发明的保护范围应以所附权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!