视频会议数据处理方法和平台与流程
本发明涉及视频会议技术领域,特别是一种视频会议数据处理方法和平台。
背景技术:
目前视频会议中一般通过麦克风激励的方式识别不同参会人员,根据哪一路声音源发声识别是谁在发言。
但是,往往很多情况下,尤其在大型会议中,有很多人共用一个麦克风,或者会有很多参会人使用同一路声音源,因而单从声音源判别的方式无法识别发言者,对会议效果产生很大的影响,参会人员无法将发言的内容与发言人对应起来,这使得视频会议的效果与现场会议产生了较大的差距,大大的降低了视频会议的用户友好程度。
技术实现要素:
本发明的一个目的在于提出一种方便视频会议用户识别发言人的方案。
根据本发明的一个方面,提出一种视频会议数据处理方法,其特征在于,包括:获取发言者的声纹信息;识别声纹信息,确定发言者的身份信息;将发言者的身份信息与视频画面进行视频合成,以显示视频合成后的视频画面。
可选地,视频画面为虚拟现实视频画面,视频终端为虚拟现实视频展示终端。
可选地,识别声纹信息,确定发言者的身份信息包括:根据声纹信息进行特征匹配,识别与声纹信息相匹配的声纹特征;查找相匹配的声纹特征对应的发言者的身份信息。
可选地,将发言者的身份信息与视频画面进行视频合成并显示包括:将发言者的身份信息与视频画面进行视频合成;将视频合成后的视频画面发送到视频终端以显示。
可选地,还包括:基于录入的参会人员的声音提取参会人员的声音的声纹特征,生成声纹库;将参会人员的声音的声纹特征与参会人员的身份信息相关联。
可选地,还包括:根据声纹特征与面部特征的关联关系获取发言者的面部特征;根据发言者的面部特征在视频画面中定位发言者;将发言者的定位标识与视频画面进行视频合成。
可选地,还包括:提取参会人员的面部特征;将参会人员的面部特征与声纹特征相关联。
通过这样的方法,能够根据参会人员的声音识别发言者的身份,并通过视频画面展示给参会人员,方便参会人员识别发言者的身份,提高视频会议的用户体验。
根据本发明的另一个方面,提出一种视频会议平台,包括:声纹信息提取模块,用于获取发言者的声纹信息;身份信息确定模块,用于识别声纹信息,确定发言者的身份信息;视频合成模块,用于将发言者的身份信息与视频画面进行视频合成,以显示视频合成后的视频画面。
可选地,视频画面为虚拟现实视频画面,视频终端为虚拟现实视频展示终端。
可选地,身份信息确定模块包括:声纹匹配单元,用于根据声纹信息进行特征匹配,识别相匹配的声纹特征;身份信息获取单元,用于获取相匹配的声纹特征对应的发言者的身份信息。
可选地,视频合成模块包括:视频合成单元,用于将发言者的身份信息与视频画面进行视频合成;视频发送单元,用于将视频合成后的视频画面发送到视频终端以显示。
可选地,还包括:声纹特征提取模块,用于基于录入的参会人员的声音提取参会人员的声音的声纹特征,生成声纹库;身份信息关联 模块,用于将参会人员的声音的声纹特征与参会人员的身份信息相关联。
可选地,还包括:面部特征获取模块,用于根据声纹特征与面部特征的关联关系获取发言者的面部特征;面部特征定位模块,用于根据发言者的面部特征在视频画面中定位发言者;视频合成模块还用于将发言者的定位标识与视频画面进行视频合成。
可选地,还包括:面部特征提取模块,用于提取参会人员的面部特征;面部特征关联模块,用于将参会人员的面部特征与声纹特征相关联。
这样的平台能够根据参会人员的声音识别发言者的身份,并通过视频画面展示给参会人员,方便参会人员识别发言者的身份,提高视频会议的用户体验。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明的视频会议数据处理方法的一个实施例的流程图。
图2为本发明的视频会议数据处理方法的另一个实施例的流程图。
图3为本发明的视频会议数据处理方法的又一个实施例的流程图。
图4为本发明的视频会议数据处理方法的再一个实施例的流程图。
图5为本发明的视频会议平台的一个实施例的示意图。
图6为本发明的视频会议平台的另一个实施例的示意图。
图7为本发明的视频会议平台的又一个实施例的示意图。
图8为本发明的视频会议平台的再一个实施例的示意图。
具体实施方式
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本发明的视频会议数据处理方法的一个实施例的流程图如图1所示。
在步骤101中,获取发言者的声纹信息。在一个实施例中,可以将从麦克风收集到的声音进行音频数据处理,得到发言者的声纹信息。
在步骤102中,识别声纹信息,确定发言者的身份信息。在一个实施例中,可以根据参会人员的声纹特征将发言者的声纹信息进行特征匹配,确定匹配的声纹特征,从而确定发言者的声纹信息。
在步骤103中,将发言者的身份信息与视频画面进行视频合成。合成后的视频画面具有发言者的身份信息。可以将合成处理后的视频画面发送到该会议的各个终端,以便参会人员在观看视频画面的同时能够获知发言者的身份信息。
通过这样的方法,能够根据参会人员的声音识别发言者的身份并通过视频画面展示给参会人员,方便参会人员识别发言者的身份,提高视频会议的用户体验。
在一个实施例中,视频画面可以为虚拟现实视频画面,可以通过虚拟现实视频展示终端在相关会场营造虚拟现实场景,或者为参会人员佩戴虚拟现实视频展示眼镜的方式营造现场会议的氛围,提高会议体验。通过这样的方法,能够进一步优化视频会议的效果。
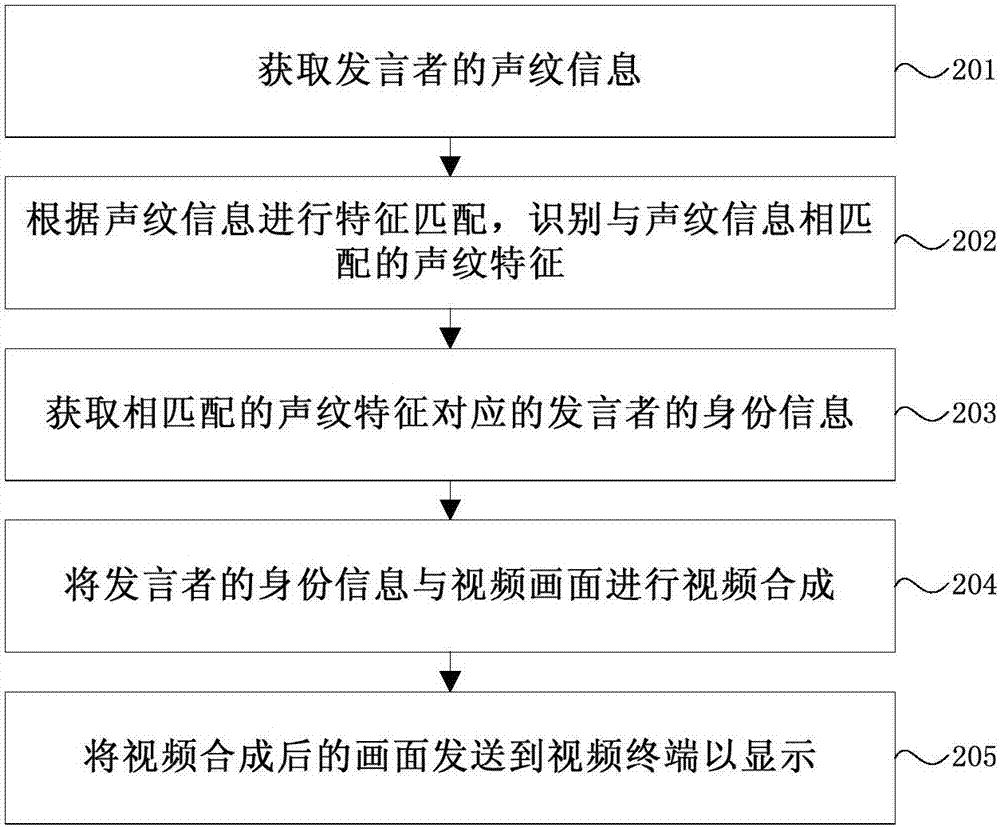
本发明的视频会议数据处理方法的另一个实施例的流程图如图2所示。
在步骤201中,获取发言者的声纹信息。在一个实施例中,可以将从麦克风收集到的声音进行音频数据处理,得到发言者的声纹信息。
在步骤202中,根据声纹信息进行特征匹配,识别与声纹信息相匹配的声纹特征。
在步骤203中,获取相匹配的声纹特征对应的身份信息。发言者的身份信息可以包括发言者的姓名、身份、所属机构和与会议的关联 信息等。根据这些信息可以比较直观的定位发言者的身份、立场。发言者的身份信息还可以包括发言者的电话号码等联系方式,方便参会人员在会后直接交流。
在步骤204中,将获取的身份信息与视频画面进行视频合成。在一个实施例中,可以在虚拟现实视频画面的预定位置显示发言者的身份信息。
在步骤205中,将视频合成后的画面发送到视频终端进行显示。
由于每一个参会人无法认识全部的参会人员,特别是大型会议中,知道声音源也无法确切知道该名发言者的姓名、职务以及与会议相关的信息等。通过这样的方法,能够根据参会人员的声音识别发言者,并查询到发言者的相关身份信息,将身份信息通过视频画面展示给参会人员,方便参会人员更好的了解发言者的身份和其背景信息,提高视频会议的用户体验。
在一个实施例中,需要先建立包括参会人员声纹特征的声纹库,基于该声纹库进行声纹信息的识别。本发明的视频会议数据处理方法的又一个实施例的流程图如图3所示。
在步骤301中,基于录入的参会人员的声音提取参会人员的声音的声纹特征,生成声纹库。在一个实施例中,可以在会议开始前要求每个参会人员录入声音。在另一个实施例中,可以只录入未提取过声纹特征的参会人员的声音。
在步骤302中,将参会人员的声纹特征与参会人员的身份信息相关联。在一个实施例中,可以事先录入每一个参会人员的身份信息,并在声音录入或声纹特征提取过程中关联声纹特征与身份信息。在一个实施例中,身份信息可以包括参会人员的姓名、职务、与本会议的关系或联系方式等。
在步骤303中,在会议过程中,收集发言者的声音,提取声纹信息。
在步骤304中,将发言者的声纹信息与声纹库中的声纹特征相匹配,确定匹配的声纹特征,再获取与该声纹特征相关联的身份信息。
在步骤305中,将发言者的身份信息与视频画面进行视频合成。合成后的视频画面具有发言者的身份信息。可以将合成处理后的视频画面发送到该会议的各个终端,以便参会人员在观看视频画面的同时能够获知发言者的身份信息。
通过这样的方法,能够生成包括参会人员声纹特征的声纹库,并基于该声纹库进行声纹信息的识别,能够快速有效的识别发言者的声纹信息,并根据声纹特征与身份信息的关联关系确定发言人的身份信息,提高了运行效率,便于推广应用。
在一个实施例中,在根据参会人员的声音提取声纹特征生成声纹库时,可以根据参会人员的会场安排将录入的声纹特征分组存储,从而在识别发言者的声纹信息时,可以先根据声音源判断发言者所处的会场,再根据该会场分组内的声纹特征识别发言者的声纹信息。这样的方法大大减少了声纹信息识别的运算量,提高了运算效率。
在一个实施例中,还可以根据视频画面对发言者进行定位标注,这样能够方便参会人员更加直观的看到发言者,进一步提高用户体验。
本发明的视频会议数据处理方法的再一个实施例的流程图如图4所示。
在步骤401中,基于录入的参会人员的声音提取参会人员的声音的声纹特征,生成声纹库。在一个实施例中,可以在会议开始前要求每个参会人员录入声音。在另一个实施例中,可以只录入未提取过声纹特征的参会人员的声音。
在步骤402中,将参会人员的声纹特征与参会人员的身份信息相关联。在一个实施例中,可以事先录入每一个参会人员的身份信息,并在声音录入或声纹特征提取过程中将关联声纹特征与身份信息。在一个实施例中,身份信息可以包括参会人员的姓名、职务、与本会议的关系或联系方式等。
在步骤403中,提取参会人员的面部特征,并将参会人员的面部特征与声纹特征相关联。可以通过参会人员上传的照片采集参会人员的面部特征,或在录入参会人员声音的同时采集参会人员的面部特征。
在步骤404中,在会议过程中,收集发言者的声音,提取声纹信息。
在步骤405中,将发言者的声纹信息与声纹库中的声纹特征相匹配,确定匹配的声纹特征。
在步骤406中,获取与该声纹特征相关联的身份信息和面部特征。
在步骤407中,在视频画面中定位发言者并添加定位标识,将定位标识和发言者的身份信息与视频画面进行视频合成,以便将合成后的视频画面传送到各个终端。
通过这样的方法,能够采集参会人员的面部特征,并以声纹特征为标识确定发言者,并在视频画面中定位标注发言者,使参会人员在知晓发言者的身份信息的同时,对发言者能有更直观的认识,使视频会议更加人性化,进一步提高用户体验。特别是在虚拟现实视频会议场景下,能够快速定位发言者,达到面对面交流的效果。
本发明的视频会议平台的一个实施例的示意图如图5所示。其中,声纹信息提取模块501能够获取发言者的声纹信息。在一个实施例中,声纹信息提取模块501可以将从麦克风收集到的声音进行音频数据处理,得到发言者的声纹信息。身份信息确定模块502能够识别声纹信息,确定发言者的身份信息。在一个实施例中,身份信息确定模块502可以根据参会人员的声纹特征将发言者的声纹信息进行特征匹配,确定匹配的声纹特征,从而确定发言者的声纹信息。视频合成模块503用于将发言者的身份信息与视频画面进行视频合成,合成后的视频画面具有发言者的身份信息。可以将合成处理后的视频画面发送到该会议的各个终端,以便参会人员在观看视频画面的同时能够获知发言者的身份信息。
这样的视频会议平台能够根据参会人员的声音识别发言者的身份并通过视频画面展示给参会人员,方便参会人员识别发言者的身份,提高视频会议的用户体验。
在一个实施例中,视频画面可以为虚拟现实视频画面,可以通过虚拟现实视频展示终端在相关会场营造虚拟现实场景,或者为参会人 员佩戴虚拟现实视频展示眼镜的方式营造现场会议的氛围,提高会议体验。
本发明的视频会议平台的另一个实施例的示意图如图6所示。其中,声纹信息提取模块61用于获取发言者的声纹信息。身份信息确定模块62包括声纹匹配单元621和身份信息获取单元622,声纹匹配单元621能够根据声纹信息进行特征匹配,识别与声纹信息相匹配的声纹特征;身份信息获取单元622能够获取相匹配的声纹特征对应的身份信息。发言者的身份信息可以包括发言者的姓名、身份和与会议的关联信息。根据这些信息可以比较直观的定位发言者的身份、立场。发言者的身份信息还可以包括发言者的电话号码等联系方式,方便参会人员在会后直接交流。视频合成模块63包括视频合成单元631和视频发送单元632,视频合成单元631能够将获取的身份信息与视频画面进行视频合成,视频发送单元632能够将合成后的视频画面发送到视频终端以展示给参会人员。
这样的平台能够根据参会人员的声音识别发言者,并查询到发言者的相关身份信息,将身份信息通过视频画面展示给参会人员,方便参会人员更好的了解发言者的身份和其背景信息,提高视频会议的用户体验。
本发明的视频会议平台的又一个实施例的示意图如图7所示。其中,声纹信息提取模块701、身份信息确定模块702和视频合成模块703的结构和功能与图5的实施例中相似。视频会议平台还包括声纹特征提取模块704和身份信息关联模块705。其中,声纹特征提取模块704能够基于录入的参会人员的声音获取参会人员的声音的声纹特征,生成声纹库;身份信息关联模块705将参会人员的声纹特征与参会人员的身份信息相关联。在一个实施例中,可以实现录入每一个参会人员的身份信息,并在声音录入或声纹特征提取过程中关联声纹特征与身份信息。在一个实施例中,身份信息可以包括参会人员的姓名、职务、与本会议的关系或联系方式等。
这样的平台能够生成包括参会人员声纹特征的声纹库,并基于该 声纹库进行声纹信息的识别,能够快速有效的识别发言者的声纹信息,并根据声纹特征与身份信息的关联关系确定发言人的身份信息,提高了运行效率,便于推广应用。
在一个实施例中,声纹特征提取模块704在根据参会人员的声音提取声纹特征生成声纹库时,可以根据参会人员的会场安排将录入的声纹特征分组存储,从而在识别发言者的声纹信息时,可以先根据声音源判断发言者所处的会场,再在该会场分组内的声纹特征识别发言者的声纹信息。这样的平台大大减少了声纹信息识别的运算量,提高了运算效率。
在一个实施例中,视频会议平台还可以根据视频画面对发言者进行定位标注,这样能够方便参会人员更加直观的看到发言者,进一步提高用户体验。
本发明的视频会议平台的再一个实施例的示意图如图8所示。其中,声纹特征提取模块804用于基于录入的参会人员的声音提取参会人员的声音的声纹特征,生成声纹库。身份信息关联模块805用于将参会人员的声纹特征与参会人员的身份信息相关联。面部特征提取模块806能够提取参会人员的面部特征,可以通过参会人员上传的照片提取参会人员的面部特征,或在录入参会人员声音的同时提取参会人员的面部特征。面部特征关联模块807用于将参会人员的面部特征与声纹特征相关联。
声纹信息提取模块801用于在会议过程中根据收集到的发言者的声音提取声纹信息。身份信息确定模块802用于将发言者的声纹信息与声纹库中的声纹特征相匹配,确定匹配的声纹特征,并获取与该声纹特征相关联的声纹信息。面部特征获取模块808用于获取与该声纹特征相关联的面部特征信息。面部特征定位模块809用于根据获取的发言者的面部特征信息在视频画面中进行定位操作。视频合成模块803用于将发言者的定位标识和发言者的身份信息与视频画面进行视频合成,以便将合成后的视频画面传送到各个终端。
这样的平台能够分析参会人员的面部特征,并以声纹特征为标识 确定发言者,并在视频画面中定位标注发言者,使参会人员在知晓发言者的身份信息的同时,对发言者能有更直观的认识,使视频会议更加人性化,进一步提高用户体验。特别是在虚拟现实视频会议场景下,能够快速定位发言者,达到面对面交流的效果。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
- 还没有人留言评论。精彩留言会获得点赞!