一种身份认证方法和装置与流程
本申请涉及网络技术,特别涉及一种身份认证方法和装置。
背景技术:
互联网技术的发展使得人们对网络的使用越发广泛,例如,可以通过邮箱收发邮件,网络购物,甚至网上办公等,部分应用要求较高的安全性,需要对用户的身份进行验证,比如,在网络购物时用户需要验证身份才能付款,或者在登录某个安全性要求较高的应用时,当用户通过身份验证后才允许登录。相关技术中,用于互联网的身份认证方式也有多种,例如,人脸识别、声纹识别等,但是通常使用的认证方式的操作比较繁琐,比如,用户需要输入自己的标识id再验证声纹;并且,现有的认证方式的可靠性较低,比如,攻击者可以通过模拟的视频或录像通过人脸识别,即使结合人脸和声纹等至少一种认证方式进行验证,各个认证方式之间比较独立,攻击者可以各个攻破。身份认证方式的上述缺陷对应用的安全性造成了风险。
技术实现要素:
有鉴于此,本申请提供一种身份认证方法和装置,以提高身份认证的效率和可靠性。
具体地,本申请是通过如下技术方案实现的:
第一方面,提供一种身份认证方法,所述方法包括:
获取采集到的音视频流,所述音视频流由待认证的目标对象产生;
判断所述音视频流中的唇语和语音是否满足一致性,若满足一致性,则 将对所述音视频流中的音频流进行语音识别得到的语音内容,作为所述目标对象的对象标识;
若预存储的对象注册信息中包括所述对象标识,在所述对象注册信息中获取所述对象标识对应的模版生理特征;
对所述音视频流进行生理识别,得到所述目标对象的生理特征;
将所述目标对象的生理特征与模版生理特征比对,得到比对结果,若所述比对结果满足认证条件,则确认所述目标对象通过认证。
第二方面,提供一种身份认证装置,所述装置包括:
信息获取模块,用于获取采集到的音视频流,所述音视频流由待认证的目标对象产生;
标识确定模块,用于判断所述音视频流中的唇语和语音是否满足一致性,若满足一致性,则将对所述音视频流中的音频流进行语音识别得到的语音内容,作为所述目标对象的对象标识;
信息管理模块,用于若预存储的对象注册信息中包括所述对象标识,在所述对象注册信息中获取所述对象标识对应的模版生理特征;
特征识别模块,用于对所述音视频流进行生理识别,得到所述目标对象的生理特征;
认证处理模块,用于将所述目标对象的生理特征与模版生理特征比对,得到比对结果,若所述比对结果满足认证条件,则确认目标对象通过认证。
本申请提供的身份认证方法和装置,通过根据用户在认证时的音视频流识别得到用户标识,并且还可以通过该同一个音视频流校验人脸特征和声纹特征,这种方式简化了用户操作,提高了认证效率,并且也保持了1:1的认证方式,保证了识别的精度;此外,还方法还通过唇语和语音的一致性判断保证了目标对象是活体,防止了攻击者伪造的视频录像,提高了认证的安全性和可靠性。
附图说明
图1是本申请一示例性实施例示出的一种身份注册流程;
图2是本申请一示例性实施例示出的一种唇语和语音一致性判断流程;
图3是本申请一示例性实施例示出的一种人脸特征识别的流程;
图4是本申请一示例性实施例示出的一种声纹特征识别的流程;
图5是本申请一示例性实施例示出的一种身份认证流程;
图6是本申请一示例性实施例示出的一种身份认证装置的结构图;
图7是本申请一示例性实施例示出的一种身份认证装置的结构图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
本申请实施例提供的身份认证方法,可以应用于互联网身份认证,例如,在登录一个网络应用时,经过该方法的身份认证才允许登录,以此保证应用使用的安全性。
如下以登录一个具有较高安全性要求的应用为例,假设该应用可以运行在用户的智能设备,例如,智能手机、智能平板等设备。当用户要在自己的智能设备上登录该应用时,可以通过该智能设备上的摄像头和麦克风采集音视频流,比如,用户可以对着自己手机的摄像头和麦克风读出自己的应用id,该应用id可以是用户在该应用注册的账号“123456”,当用户朗读完毕,手机可以采集到用户的音视频流,包括用户的视频图像和朗读的语音。
本申请实施例的身份认证方法,可以基于该采集到的音视频流进行处理,在进行认证之前,用户还需要进行身份注册流程,后续根据注册的信息进行 身份认证,注册流程也是基于如上述的采集音视频流。如下将分别描述身份注册流程和身份认证流程,此外,该身份注册或认证的处理,本实施例不限制实际应用时的执行设备,比如,智能手机采集到用户的音视频流后,可以将音视频流传输至应用后端的服务器处理,或者一部分处理在智能手机的客户端侧,另一部分处理在服务器侧,或者还可以采用其他方式。
身份注册
本实施例的方法中,用户在进行身份注册时,可以包括两类信息,其中,一类信息是:对象标识,例如,以用户登录某应用的例子,该用户可以称为目标对象,当用户在该应用注册时,该用户在应用中用于与其他用户区分的信息即为对象标识,比如可以是用户在应用的账号123456,该账号123456即为目标对象的对象标识。另一类信息是能够唯一标识用户的生理性信息,比如,用户的声纹特征,或者用户的人脸特征等,通常不同人的声纹和人脸是不同的,可以将标识各个用户的生理性信息称为模版生理特征。
将上述的对象标识和模版生理特征这两类信息建立对应关系,并进行存储,可以将对应存储的目标对象的对象标识和模版生理特征,称为“对象注册信息”。例如,用户小张可以存储其对象注册信息为“123456——模版生理特征a”,其中,为了更准确的标识用户,本例子采用的模版生理特征中包括的生理性信息的类型可以为至少两种,比如,人脸和声纹。
图1示例了一个例子中的身份注册流程,包括如下处理:
在步骤101中,获取目标对象的待注册音视频流。
例如,以一个用户注册某应用为例,用户可以对着自己的智能设备如手机读出自己在应用的账号“123456”。本例子中,可以将正在注册的用户称为目标对象,智能设备的摄像头和麦克风可以采集到该用户朗读时的音视频流,可以将注册时采集的该音视频流称为待注册音视频流,包括音频流和视频流,音频流即用户朗读的语音,视频流即用户朗读时的视频图像。
在获取到本步骤的音视频流后,如果要完成用户的注册,可以执行三个方面的处理,请继续参见图1:
一个方面的处理是,在步骤102中,判断待注册音视频流中的唇语和语音是否满足一致性。
这里的一致性指的是,唇部的运动和语音所表示的运动能否对应,比如,假设一个语音是“今天的天气晴朗”,该语音是缓缓慢速的朗读,语速较慢,而一个唇部运动是快速朗读“今天的天气晴朗”所使用的运动,显然这两个是对不上的,当唇部运动已经停止(内容已经读完)时,语音却还在继续(….天气晴朗)。这种情况可能出现在,比如,当攻击者要设法通过用户id和人脸检测时,可以通过一个该用户(被攻击的用户)以前的视频录像来攻击人脸检测,并且攻击者自己读用户id来攻击对语音内容id的识别,如果这样分别攻击,有可能通过认证,但是通常这种攻击方式中,唇语和语音是不一致的,可以通过一致性判断识别出并不是本人在朗读。
如步骤102所示,如果判断结果为待注册音视频流中的唇语和语音不满足一致性,可以提示用户注册失败,或者如图1所示,转至步骤101重新采集音视频流,以防处理失误。
否则,如果判断结果为两者满足一致性,则可以执行步骤103,将根据采集的音视频流中的音频流进行语音识别得到的语音内容,作为目标对象的对象标识。语音识别即使用计算机技术自动识别人所说语音的内容,即由语音到内容的识别过程。比如,对于待注册用户朗读“123456”的音频进行语音识别后,得到该音频流中的语音内容即“123456”,可以将识别得到的内容作为用户的标识,即用户id。
上述的对音频流进行语音识别,可以是在确定唇语和语音满足一致性后,对语音的音频流识别得到对象标识;或者,还可以是在判断唇语和语音是否满足一致性的过程中,对音频流识别得到对象标识。
另一个方面的处理是,对待注册音视频流进行生理识别,得到所述待注册音视频流的模版生理特征。本例子中,生理特征以人脸特征和声纹特征为例,但不局限于这两种特征,只要是能够唯一标识用户、能够区分不同用户的生理性特征都可以。本方面中,参见步骤104所示,可以对待注册音视频 流中的音频流进行声纹识别,得到目标对象的声纹特征。
再一个方面的处理是,对待注册音视频流中的视频流进行人脸检测,得到目标对象的人脸特征。
在该注册流程中,可以将上述检测得到的人脸特征称为模版人脸特征,作为后续认证过程中的标准,同样,将检测得到的声纹特征称为模版声纹特征,而模版声纹特征和模版人脸特征可以统称为模版生理特征。
本实施例还将模版生理特征和目标对象的对象标识,称为对象注册信息,在确定对象注册信息中的数据完整后,在步骤106中,将目标对象的对象标识及对应的模版生理特征,作为对象注册信息存储入数据库中。
此外,在图1所示的三个方面的处理中,这三个方面的执行顺序不做限制,比如,在步骤101获取到待注册音视频流后,可以并列执行上述三方面处理,如果唇语和语音不一致,可以将识别的声纹特征和人脸特征不存储;或者,也可以先执行唇语和语音一致性的判断,在通过一致性确定后,再执行声纹特征和人脸特征的检测识别。
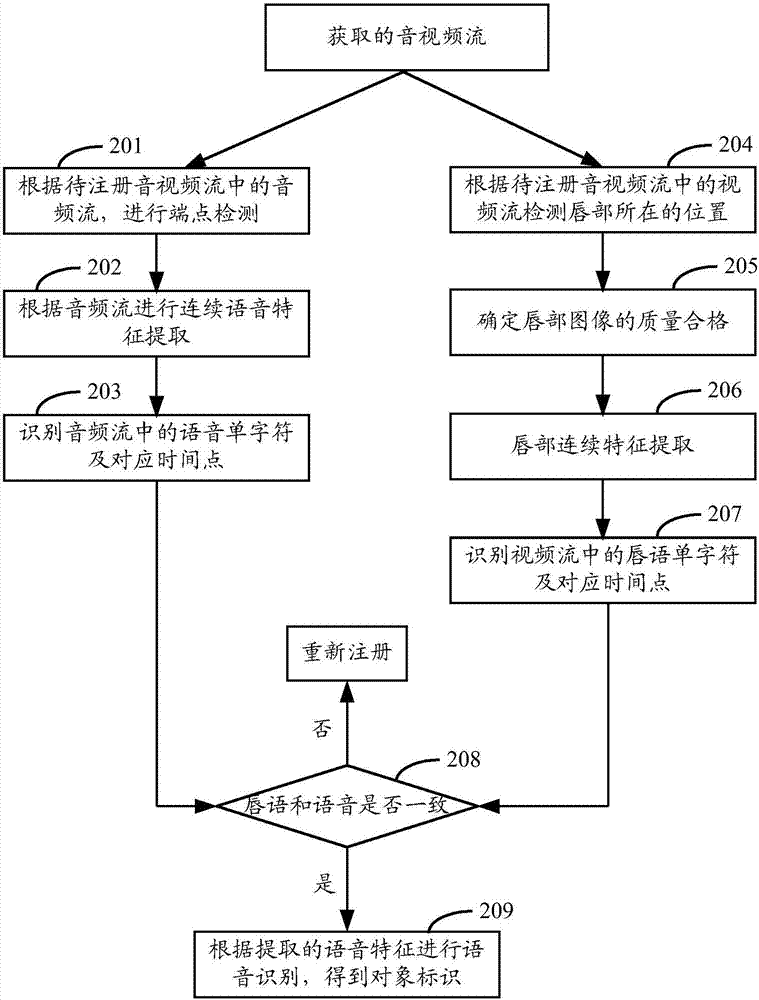
图2示例了图1中的唇语和语音一致性判断的流程,可以包括:
在步骤201中,根据待注册音视频流中的音频流,进行端点检测。本步骤可以从连续的音频流中检测出这段音频流的起始时间和终止时间。
在步骤202中,根据音频流进行连续语音特征提取,所述特征包括但不限于mfcc特征、lpcc特征。本步骤提取的特征可以用于语音识别。
在步骤203中,识别音频流中的语音单字符及对应时间点。本步骤中,可以根据步骤202中提取的语音特征识别出音频流中的各个单字符,并且确定其对应的出现和消失的时间点。所述语音识别的方法,包括但不限于隐马尔可夫模型(hiddenmarkovmode,hmm)、深度神经网络(deepneuralnetwor,dnn)和长短时记忆模型(longshorttimemodel,lstm)等方法。
在步骤204中,根据待注册音视频流中的视频流检测唇部所在的位置。本步骤可以从视频图像中检测出唇部所在位置。
在步骤205中,对检测出的唇部图像的质量进行判断,例如,可以判断 唇部位置的清晰度和曝光度等参数,若清晰度不够或者曝光度过高,则判断为质量不合格,可以返回重新采集待注册音视频流。若质量合格则继续执行步骤206,继续进行唇语识别。
在步骤206中,进行唇部连续特征提取,本步骤可以从连续的唇部图像中提取特征,所述特征包括但不限于裸像素、或者lbp、gabor、sift、surf等局部图像描述子。
在步骤207中,识别视频流中的唇语单字符及对应时间点。本步骤的唇语字符识别可以使用隐马尔可夫(hmm)或者长短时记忆模型等方法,单个唇语字符在视频时间序列中对应的时间点也由该模型在进行唇语识别时确定。
在步骤208中,判断唇语和语音的单字符及对应时间点是否满足一致性。例如,本步骤可以将语音单字符的时间点信息与唇语单字符的时间点信息进行比对,如果比对结果一致,则认为该音频流是真人所说,继续执行步骤209;若不一致,则怀疑为攻击行为,则返回重新开始注册流程。本实施例的对唇语和语音的字符和对应时间点的一致性检测方式,这种方式更加细化,可以对真人语音的判断有更高的准确性。
在步骤209中,可以根据步骤202中提取的语音特征进行语音识别,得到用户id即对象标识。所述语音识别的方法,包括但不限于隐马尔可夫模型(hiddenmarkovmode,hmm)、深度神经网络(deepneuralnetwor,dnn)和长短时记忆模型(longshorttimemodel,lstm)等方法。
此外,在上述图2所示的例子中,对音频流的语音识别可以在确定唇语和语音满足一致性之后的步骤209中执行;或者,还可以是在步骤203中识别音频流中的单字符时间点时,同时根据语音特征进行语音识别得到用户id,那么这种情况下,当在步骤208确定唇语和语音满足一致性之后,就可以直接将前面识别到的用户id作为对象标识。
图3示例了图1中的人脸特征识别的流程,可以包括:
在步骤301中,根据待注册音视频流中的视频流检测人脸图像。本步骤可以从音视频流中的视频流中提取视频帧图像,并检测其中是否出现人脸, 如出现则继续执行302,否则返回继续判断。
在步骤302中,检测人脸图像的质量。本步骤可以对步骤301中检测到的人脸进行人脸特征点检测,根据特征点检测的结果判断人脸在水平方向和竖直方向的角度,若都在一定的倾角范围内,则满足质量要求,否则,不满足质量要求;同时判断人脸区域的清晰度和曝光度等参数,也需要在一定的阈值范围内满足要求。如果人脸图像的质量较好,可以更好识别到人脸特征。
在步骤303中,对于满足质量要求的人脸图像,可以由人脸图像中提取特征向量,所述特征向量包括但不限于:局部二值模式特征(localbinarypattern,lbp)、gabor特征、卷积神经网络特征(convolutionalneuralnetwork,cnn)等。
在步骤304中,将在步骤303中提取的多个人脸特征向量进行融合或者组合,构成用户的唯一人脸特征,即模版人脸特征。
图4示例了图1中的声纹特征识别的流程,可以包括:
在步骤401中,获取待注册音视频流中的音频流。
本例子的声纹特征识别可以根据待注册音视频流中的音频流执行。
在步骤402中,确定音频流的音频质量满足质量标准条件。
本步骤中,可以对音频质量进行判断,采集的音频流的质量较好时,对音频进行声纹识别的效果就更好,因此,可以在进行后续的声纹识别之前,先对音频流的质量进行判定。比如,可以计算音频流中的人声信号强度、信噪比等信息,来判断这段语音是否符合质量标准条件,比如,该质量标准条件可以是设定信噪比在一定的范围内,人声信号强度高于一定的强度阈值等。如果质量通过,可以继续执行步骤403;否则可以重新采集待注册音视频流。
在步骤403中,由音频流中提取声纹特征向量。
本例子中,待注册音视频流的数量可以有多条,比如,用户可以读两次自己的用户id,对应采集到两条音视频流。本步骤中,可以提取其中的每一条音视频流中的音频流的声纹特征向量,该特征向量的提取可以采用多种常规方式,不再详述,比如,可以从音频流的语音信号中提取语音特征参数 mfcc(melfrequencycepstrumcoefficient,梅尔频率倒谱系数)特征,然后使用i-vector(一种说话人识别算法)和plda(probabilisticlineardiscriminantanalysis,声纹识别的信道补偿算法)等方法计算特征向量。
在步骤404中,判断多条音频流的声纹特征向量是否满足一致性。
例如,当用户在注册时朗读了至少两次自己的用户id时,采集到的音频流是对应的至少两条。为了保证该多条音频流之间的声纹特征的差别不会过大,所以可以进行多条音频流之间的声纹一致性判断。比如,可以根据在步骤403中由每条音频流提取的声纹特征向量,计算该多条音频流之间的相似度分数。
若该相似度分数在一定的分数阈值范围内,表示音频流之间满足相似要求,可以继续执行步骤405;否则,表明用户输入的这多次音频差别太大,可以指示正在注册的用户重新朗读其用户id,即重新采集音频流。
在步骤405中,根据多条音频流的声纹特征向量生成模版声纹特征。
本步骤中,可以根据在前面步骤中分别对各条音频流提取的声纹特征向量进行加权求和,得到模版声纹特征。
在完成上述的注册流程后,在数据库中已经存储了目标对象的对象注册信息,该对象注册信息可以包括对象标识和对应的模版生理特征,该模版生理特征可以包括模版声纹特征和模版人脸特征,如下可以根据该对象注册信息执行对象的身份认证处理。
身份认证
图5示例了一个例子中的身份认证流程,该流程中,认证所使用的生理特征以综合人脸特征和声纹特征为例来说明,并且,可以在确定正在认证的目标对象是活体对象而非录像视频后,再进行生理特征的比对。如图5所示,该认证流程包括如下处理:
在步骤501中,获取采集到的音视频流,所述音视频流由待认证的目标对象产生。
例如,假设用户要登录某个安全性要求较高的应用,需要通过该应用的 身份认证才能登录。本步骤中,用户可以在自己的智能设备例如智能手机上打开应用的客户端,并且用户可以通过智能手机的摄像头和麦克风采集待认证的音视频流,该音视频流可以是用户朗读自己的应用id。
在步骤502中,判断音视频流中的唇语和语音是否满足一致性。
本例子中,可以先判断音视频流中的唇语和语音是否满足一致性,具体判断一致性的流程可以参见图2,不再详述。
如果满足一致性,表明正在认证的目标对象是活体而非录像视频等,则继续执行步骤503;否则,可以返回执行501重新采集。
在步骤503中,对音视频流中的音频流进行语音识别,得到音频流的语音内容。例如,识别到的语音内容可以是用户id“123456”。
在步骤504中,将语音内容作为目标对象的对象标识,判断预存储的对象注册信息中是否包括该对象标识。
例如,若预存储的对象注册信息中包括所述对象标识,可以在对象注册信息中获取所述对象标识对应的模版生理特征,例如模版人脸特征和模板声纹特征,并继续对待认证的音视频流进行生理识别,得到目标对象的生理特征,以与模版生理特征进行比对。如果预存储的对象注册信息中未包括对象标识,可以提示用户未注册。
在步骤505中,对音视频流进行声纹识别,得到目标对象的声纹特征。本步骤的声纹特征的提取可以参见图4。
在步骤506中,对音视频流进行人脸识别,得到目标对象的人脸特征。
然后可以将目标对象的生理特征与模版生理特征比对,得到比对结果,若所述比对结果满足认证条件,则确认所述目标对象通过认证。例如包括如下的步骤507至步骤509。
在步骤507中,将目标对象的声纹特征与模版声纹特征比对,得到声纹比对分数。
在步骤508中,将目标对象的人脸特征与模版人脸特征比对,得到人脸比对分数。
在步骤509中,判断声纹比对分数和人脸比对分数是否满足认证条件。
例如,若所述声纹比对分数和人脸比对分数满足如下至少一种,则确认所述目标对象通过认证:所述声纹比对分数大于声纹分数阈值,且人脸比对分数大于人脸分数阈值;或者,所述声纹比对分数和人脸比对分数的乘积大于对应的乘积阈值;或者,所述声纹比对分数和人脸比对分数的加权和大于对应的加权阈值。
若本步骤中确定声纹比对分数和人脸比对分数满足认证条件,则确认目标对象通过认证;否则,确定目标对象未通过认证。
此外,在本身份认证的例子中,与前面的身份注册流程类似,对音频流进行语音识别得到用户id的处理,既可以在确定唇语和语音满足一致性之后执行,也可以在识别音频流中的单字符时间点时同时获得用户id。上面的例子中,是以在确定唇语和语音满足一致性之后再识别用户id为例。
本申请实施例的身份认证方法,使得用户在认证时,只需要产生一次音视频流即可,比如用户读一次自己的用户id即可,该方法就可以根据该音频音视频流进行语音识别得到用户id,并且还可以通过该同一个音视频流校验人脸特征和声纹特征,这种方式不仅简化了用户操作,提高了认证效率,并且也保持了1:1的认证方式,即识别到的生理特征只与数据库中的对象标识对应的特征比较,保证了识别的精度;此外,还方法还通过唇语和语音的一致性判断保证了目标对象是活体,防止了攻击者伪造的视频录像,提高了认证的安全性和可靠性;该方法中的用户id、识别得到的生理特征,都是基于同一个音视频流得到,能够在一定程度上识别攻击者的伪造音视频流。
为了实现上述的身份认证方法,本申请实施例还提供了一种身份认证装置,如图6所示,该装置可以包括:信息获取模块61、标识确定模块62、信息管理模块63、特征识别模块64和认证处理模块65。
信息获取模块61,用于获取采集到的音视频流,所述音视频流由待认证的目标对象产生;
标识确定模块62,用于判断所述音视频流中的唇语和语音是否满足一致 性,若满足一致性,则将对所述音视频流中的音频流进行语音识别得到的语音内容,作为所述目标对象的对象标识;
信息管理模块63,用于若预存储的对象注册信息中包括所述对象标识,在所述对象注册信息中获取所述对象标识对应的模版生理特征;
特征识别模块64,用于对所述音视频流进行生理识别,得到所述目标对象的生理特征;
认证处理模块65,用于将所述目标对象的生理特征与模版生理特征比对,得到比对结果,若所述比对结果满足认证条件,则确认目标对象通过认证。
参见图7,在一个例子中,特征识别模块64可以包括:声纹识别子模块641和人脸识别子模块642。
所述声纹识别子模块641,用于对所述音视频流进行声纹识别,得到所述目标对象的声纹特征;
所述人脸识别子模块642,用于对所述音视频流进行人脸识别,得到所述目标对象的人脸特征;
所述认证处理模块65,用于将所述目标对象的声纹特征与模版声纹特征比对,得到声纹比对分数,并将所述目标对象的人脸特征与模版人脸特征比对,得到人脸比对分数,若所述声纹比对分数和人脸比对分数满足认证条件,则确认所述目标对象通过认证。
在一个例子中,若所述声纹比对分数和人脸比对分数满足如下至少一种,则确认所述目标对象通过认证:所述声纹比对分数大于声纹分数阈值,且人脸比对分数大于人脸分数阈值;或者,所述声纹比对分数和人脸比对分数的乘积大于对应的乘积阈值;或者,所述声纹比对分数和人脸比对分数的加权和大于对应的加权阈值。
在一个例子中,如图7所示,标识确定模块62可以包括:
字符识别子模块621,用于对音视频流中的音频流进行语音单字符及对应时间点识别,对音视频流中的视频流进行唇语单字符及对应时间点识别;
一致判断子模块622,用于若所述语音和唇语的单字符及对应时间点一 致,则确定满足一致性。
在一个例子中,所述信息获取模块61,还用于获取所述目标对象的待注册音视频流;
所述标识确定模块62,还用于在所述待注册音视频流中的唇语和语音满足一致性时,将对所述音视频流中的音频流进行语音识别得到的语音内容,作为所述目标对象的对象标识;
所述特征识别模块64,还用于对所述待注册音视频流进行生理识别,得到所述待注册音视频流的所述模版生理特征;
所述信息管理模块63,还用于将所述目标对象的对象标识及对应的所述模版生理特征,对应存储在所述对象注册信息中。
以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!