一种一体化的融媒体云生产发布系统与方法与流程
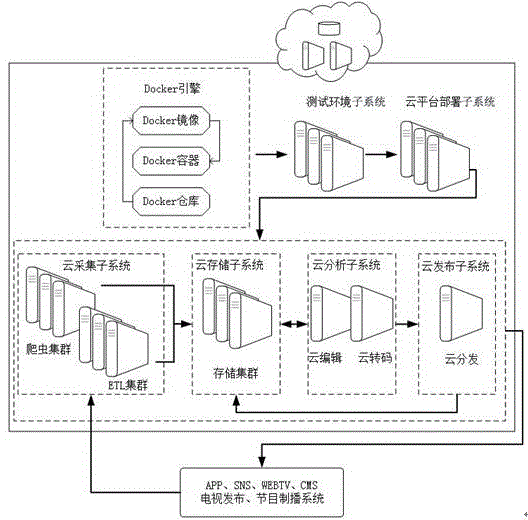
本发明涉及一种一体化的融媒体云生产发布系统与方法。
背景技术:
云计算是一个巨大的IT资源共享池,池中包括了存储器、服务、网络和应用等,并且池中的资源能够自动快速地进行更新与计算;云计算的特征有具备大规模计算能力与高强度集成性、设置虚拟资源池、采用分布式数据计算模式确保系统安全保障、模块化设计来提升扩展性、软硬件互不依赖,为广播电视行业的融媒体大数据提供了新的管理与生产模式;从开发环境层面,最近比较流行的Docker使用轻量级的容器虚拟平台,结合工作量和工具来管理和部署应用程序,并且跨入了云端时代;为了应对大数据模式下的融媒体内容的高效生产发布,依托云计算技术来实施融媒体资源的获取、存储、加工、发布将会成为广播电视行业技术的重大改造,现有系统与方法存在的问题主要有以下两方面:
1、现有用于统一融媒体生产发布系统开发团队的开发环境不便于频繁更新,启动销毁速度非常缓慢,对并行开发场景尤其是快速迭代的开发周期的支持效果不佳,效率极低。
2、采用本地部署融媒体生产发布系统时,存在耗时长、硬件成本高、低可扩展性、升级维护困难等问题,并且网络资源采集、数据存储、数据分析处理、媒体内容分发等方面都存在难以避免的局限性。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种一体化的融媒体云生产发布系统与方法,能够将开发、测试、部署、生产分发流程一体化,实现融媒体生产分发系统负载均衡、降低资源部署开销、云平台高效生产。
本发明的目的是通过以下技术方案来实现的:一种一体化的融媒体云生产发布系统,包括:
Docker引擎,用于创建Docker镜像和Docker容器,并推送给环境测试子系统;
测试环境子系统,用于对创建的Docker镜像和Docker容器进行测试,测试通过后推送给云平台部署子系统;
云平台部署子系统,用于在云端服务器上对测试环境子系统推送的Docker镜像进行部署;
云采集子系统,用于获取网络数据;
云存储子系统,用于存储云采集子系统获得的数据并提供统一的访问接口;
云分析子系统,用于对云存储子系统中的数据进行加工制作;
云发布子系统,用于对云分析子系统处理后的数据进行发布。
所述的Docker引擎包括:
Docker镜像创建模块,用于根据开发者命令创建Docker镜像;创建的Docker镜像包含一个运行在Apache上的Web应用程序和其使用的Ubuntu操作系统,Web应用程序包括种子URL、URL队列、安装包和协议;
Docker容器创建模块,用于根据Docker镜像生成对应的Docker容器,包含Web应用程序运行所需的所有环境;
Docker仓库,用于对Docker镜像对应的Docker容器进行存储。
所述的云采集子系统包括爬虫集群和ETL集群:
所述的爬虫集群负责数据提取,包括:
URL控制器,用于将部署在云端服务器的种子URL和从网页提取的URL存至URL数据库,自动重复检测新加添的URL并实现快速插入;
数据提取器,用于结合云端服务器部署的URL队列和网页提取的URL,利用查询探测算法采取模式匹配输入形成新的URL传给网页提取器;
搜索控制器,根据搜索策略对不同网络爬取目标设置不同的提取深度,对于符合提取的网页内容,将页面存入云存储子系统的页面库中,等待索引模块的结构化;
网页提取器,用于以多线程并行的方式根据http协议抓取网页;
状态日志,用于根据时间戳以纯文本形式来记录爬取的对象、时刻、当前系统并发连接数、系统CPU的状态信息;
所述的ETL集群用于将数据从来源端经过抽取、转换、装载到目的端,包括:
抽取模块,用于通过ETL库表抽取的方式,从各种原始的业务系统中读取数据;
转换模块,用于按照预设规则将抽取出的数据进行转换,采用异步数据加载并以文件方式处理,使本来异构的数据格式统一;
装载模块,用于将转换完的数据按照增量或全部导入数据仓库中。
所述的云分析子系统包括云编辑模块和云转码模块:
云编辑模块用于对文字、图片、纯音频、视音频进行加工制作;
云转码模块用于完成视频编解码的转换,以流的形式打开视频文件,获取视频流机器编码格式,从视频流中读取视频的帧数据,并根据获得的编码信息对视频的帧数据进行解码还原成原始数据,再对原始数据进行编码压缩,形成目标编码格式的帧数。
一种一体化的融媒体云生产发布方法,包括以下步骤:
S1.开发者通过Docker引擎构建Docker镜像和Docker容器,并进行保存;
S2.测试环境子系统对Docker镜像和Docker容器进行测试,测试通过后将Docker镜像和Docker容器推送给云平台部署子系统;
S3.云平台部署子系统在云端服务器上对测试环境子系统推送的Docker镜像进行部署;
S4.云采集子系统获取网络数据,并将采集到的数据存保存到云存储子系统中;
S5.云分析子系统对云存储子系统中保存的数据进行加工制作;
S6.云发布子系统用于对加工制作后的数据进行发布。
所述的步骤S1包括以下子步骤:
S11.开发者通过Docker引擎构建Docker镜像,所述的Docker镜像包含一个运行在Apache上的Web应用程序和其使用的Ubuntu操作系统,Web应用程序包括种子URL、URL队列、安装包和协议;
S12.开发者通过Docker引擎根据创建Docker容器,所述的创建Docker容器包括Web应用程序运行所需的所有环境;
S13.Docker引擎将Docker镜像和Docker容器进行保存,并传输给测试环境子系统。
所述的步骤S4包括以下步骤:
S41.爬虫集群初始化运行参数;
S42.爬虫集群将部署在云端服务器的种子URL和从网页提取的URL存至URL数据库,自动重复检测新加添的URL并实现快速插入,按照种子队列选取相对应的主题网页用作一系列目标信息的初始位置网页;
S43.ETL集群将爬虫集群提取的数据从来源端经过抽取、转换后装载到目的端;
S44.将提取的网页存入云存储子系统的页面库中,页面库分析所提取的网页,提取关键字段形成索引并根据生成的索引地址快速定位融媒体内容的物理地址,同时将融媒体内容元数据描述、文稿内容抽取出来作为发布的主要标签字段。
所述的步骤S5包括步骤:
S51.获取云存储系统的中的数据;
S52.采用统一用户管理的多样化编辑工具对文字、图片、纯音频、视音频进行加工制作;
S53.针对视频文件,以流的形式打开视频文件,获取视频流机器编码格式,从视频流中读取视频的帧数据,根据获得的编码信息对视频的帧数据进行解码还原成原始数据,再对原始数据进行编码压缩,从而形成目标编码格式的帧数据。
本发明的有益效果是:结合Docker和云计算技术,实现开发、测试、部署和生产的流程一体化,并以系统负载均衡、降低资源部署开销、云平台高效生产为原则,投入少、传播快、效果佳、高效可靠的。
附图说明
图1为本发明的系统原理框图。
图2为本发明的流程图。
图3为实施例一的示意图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
如图1所示,一种一体化的融媒体云生产发布系统,包括:
Docker引擎,用于创建Docker镜像和Docker容器,并推送给环境测试子系统;
测试环境子系统,用于对创建的Docker镜像和Docker容器进行测试,测试通过后推送给云平台部署子系统;
云平台部署子系统,用于在云端服务器上对测试环境子系统推送的Docker镜像进行部署;
云采集子系统,用于获取网络数据;
云存储子系统,用于存储云采集子系统获得的数据并提供统一的访问接口;
云分析子系统,用于对云存储子系统中的数据进行加工制作;
云发布子系统,用于对云分析子系统处理后的数据进行发布。
所述的Docker引擎包括:
Docker镜像创建模块,用于根据开发者命令创建Docker镜像;创建的Docker镜像包含一个运行在Apache上的Web应用程序和其使用的Ubuntu操作系统,Web应用程序包括种子URL、URL队列、安装包和协议;
Docker容器创建模块,用于根据Docker镜像生成对应的Docker容器,包含Web应用程序运行所需的所有环境;可以运行、开始、停止、移动和删除;
Docker仓库,用于对Docker镜像对应的Docker容器进行存储。
所述的云采集子系统包括爬虫集群和ETL集群:
所述的爬虫集群负责数据提取,包括:
URL控制器,用于将部署在云端服务器的种子URL和从网页提取的URL存至URL数据库,自动重复检测新加添的URL并实现快速插入;
数据提取器,用于结合云端服务器部署的URL队列和网页提取的URL,利用查询探测算法采取模式匹配输入形成新的URL传给网页提取器;
搜索控制器,根据搜索策略对不同网络爬取目标设置不同的提取深度,对于符合提取的网页内容,将页面存入云存储子系统的页面库中,等待索引模块的结构化;
网页提取器,用于以多线程并行的方式根据http协议抓取网页;
状态日志,用于根据时间戳以纯文本形式来记录爬取的对象、时刻、当前系统并发连接数、系统CPU的状态信息,进一步可用于服务器性能瓶颈的研究分析;
所述的ETL集群用于将数据从来源端经过抽取、转换、装载到目的端,包括:
抽取模块,用于通过ETL库表抽取的方式,从各种原始的业务系统中读取数据;
转换模块,用于按照预设规则将抽取出的数据进行转换,采用异步数据加载并以文件方式处理,使本来异构的数据格式统一;
装载模块,用于将转换完的数据按照增量或全部导入数据仓库中。
所述的云分析子系统包括云编辑模块和云转码模块:
云编辑模块利用轻量级的多样化的编辑工具对文字、图片、纯音频、视音频进行加工制作;多样化的编辑工具采用统一用户管理,并且只要是用统一客户端登录云服务器,则不管利用什么工具(手机、平板、PC)都能立即调出该客户端内的所有存储数据,包括保存的资源、编辑内容以及作业完成进度。
云转码模块用于完成视频编解码的转换,以流的形式打开视频文件,获取视频流机器编码格式,从视频流中读取视频的帧数据,并根据获得的编码信息对视频的帧数据进行解码还原成原始数据,再对原始数据进行编码压缩,形成目标编码格式的帧数。
如图2所示,一种一体化的融媒体云生产发布方法,包括以下步骤:
S1.开发者通过Docker引擎构建Docker镜像和Docker容器,并进行保存;
S2.测试环境子系统对Docker镜像和Docker容器进行测试,测试通过后将Docker镜像和Docker容器推送给云平台部署子系统;
S3.云平台部署子系统在云端服务器上对测试环境子系统推送的Docker镜像进行部署;
S4.云采集子系统获取网络数据,并将采集到的数据存保存到云存储子系统中;
S5.云分析子系统对云存储子系统中保存的数据进行加工制作;
S6.云发布子系统用于对加工制作后的数据进行发布。
所述的步骤S1包括以下子步骤:
S11.开发者通过Docker引擎构建Docker镜像,所述的Docker镜像包含一个运行在Apache上的Web应用程序和其使用的Ubuntu操作系统,Web应用程序包括种子URL、URL队列、安装包和协议;
S12.开发者通过Docker引擎根据创建Docker容器,所述的创建Docker容器包括Web应用程序运行所需的所有环境;
S13.Docker引擎将Docker镜像和Docker容器进行保存,并传输给测试环境子系统。
所述的步骤S4包括以下步骤:
S41.爬虫集群初始化运行参数;
该运行参数包括爬虫使用的最大线程数量、初始种子网站、种子队列、爬虫爬取最大深度大小、主题描述及其提取频率、词库路径和内容分析使用参数;
S42.爬虫集群将部署在云端服务器的种子URL和从网页提取的URL存至URL数据库,自动重复检测新加添的URL并实现快速插入,按照种子队列选取相对应的主题网页用作一系列目标信息的初始位置网页;
S43.ETL集群将爬虫集群提取的数据从来源端经过抽取、转换后装载到目的端;
S44.将提取的网页存入云存储子系统的页面库中,页面库分析所提取的网页,提取关键字段形成索引并根据生成的索引地址快速定位融媒体内容的物理地址,同时将融媒体内容元数据描述、文稿内容抽取出来作为发布的主要标签字段。
所述的步骤S5包括步骤:
S51.获取云存储系统的中的数据;
S52.采用统一用户管理的多样化编辑工具对文字、图片、纯音频、视音频进行加工制作;
S53.针对视频文件,以流的形式打开视频文件,获取视频流机器编码格式,从视频流中读取视频的帧数据,根据获得的编码信息对视频的帧数据进行解码还原成原始数据,再对原始数据进行编码压缩,从而形成目标编码格式的帧数据。
实施例一,如图3所示,本发明在具体应用时,包括以下步骤:
S1001.开发者通过Docker在本地进行包含应用程序和服务的容器开发,然后集成到连续的一体化和部署工作流中:
A1、开发者将代码push到Docker仓库中,持续集成(CI)工具取得最新代码,构建Docker镜像并启动Docker容器进行测试;
A2、测试通过后将镜像打标签并push到私有镜像Registry;
A3、持续集成(CI)工具通知持续部署(CD)工具;
A4、持续部署(CD)工具在云端服务器上进行基于容器的部署;
A5、测试没有问题后进行容器的切换;
S002.爬虫集群初始化运行参数,所述的运行参数有爬虫使用的最大线程数量、初始种子网站、种子队列、爬虫爬取最大深度大小、主题描述及其提取频率、词库路径和内容分析使用参数;
S003.URL控制器将云平台部署的种子URL和从网页提取的URL存至URL数据库,自动重复检测新加添的URL并实现快速插入,按照种子队列选取相对应的主题网页用作一系列目标信息的初始位置网页;
S004.ETL集群将爬取数据从来源端经过抽取、转换、装载到目的端:
B1、从各种原始的业务系统中读取数据,采用的是ETL库表抽取策略,即将数据库中的指定列的值存入目标文件中;
B2、按照预先设计好的规则将抽取出的数据进行转换,采用异步数据加载以文件方式处理策略,使本来异构的数据格式能统一起来:具体而言,
首先,提取出正常返回的日期、长度、页面类型、页面内容信息,为了确保页面内容信息完整性,对于内容较多的长页面采取分块读取再拼接的策略;
然后,启动数据分析器用于解析已经保存的网页内容信息,分析策略包括检索内容相关度分析和链接相关度分析;
B3、将转换完的数据按照增量或全部导入数据仓库中;
S005.将步骤S4提取的网页存入云存储子系统的页面库中,页面库分析所提取的网页,提取关键字段形成索引并根据生成的索引地址快速定位融媒体内容的物理地址,同时将融媒体内容元数据描述、文稿内容抽取出来作为发布的主要标签字段;
S006:云编辑模块获取云存储系统的中的数据,其中采用统一用户管理的多样化编辑工具对文字、图片、纯音频、视音频进行加工制作;
S007.针对视频文件,云转码模块以流的形式打开视频文件,获取视频流机器编码格式,从视频流中读取视频的帧数据,根据获得的编码信息对视频的帧数据进行解码还原成原始数据,再对原始数据进行编码压缩,从而形成目标编码格式的帧数据。
S008:云分发服务器收到处理完成的发布任务,调相应发布渠道的接口将任务发布到相应的渠道。
- 还没有人留言评论。精彩留言会获得点赞!