盗号行为的判断系统、负载调度方法和装置与流程
本申请涉及互联网技术领域,尤其涉及一种盗号行为的判断方法、装置和系统,以及一种负载调度方法和装置。
背景技术:
在互联网技术领域中,所谓盗号,一般是指盗取用户的用户账号和密码;盗号行为,则是指盗取用户账号和密码的行为;反盗号,是指发现盗号行为并对盗号行为进行中断或者阻止的业务。
盗号行为,往往是由黑客发起的。黑客通过伪装成用户,向服务器发送包含通过非法手段获取的用户账号和密码的身份验证请求,可以使得服务器对于用户账号和密码进行验证;进一步地,黑客可以将验证通过的用户账号和密码(黑客可以修改密码)作为正确的用户账号和密码进行保存,从而达到盗号的目的。
互联网数据中心(Internet Data Center,IDC)预计,2016年全球网民用户数将达到32亿,用户爆发式的增长给网络安全,尤其是用户账号和密码安全提出了挑战,反盗号,也变得越来越重要。
现有技术中,有方案提出可以根据服务器的访问日志的一些统计特征,来判断请求进行用户账号和密码验证的请求方是否存在盗号行为。具体的判断逻辑,可以由某个服务器来执行。然而,服务器的访问日志的数量巨大(很可能是TB级别的),而反盗号又是一种实时性要求很高的业务,如何保证根据访问日志来判断盗号行为的实时性,是目前亟待解决的问题。
技术实现要素:
本申请实施例提供一种盗号行为的判断系统、方法和装置,用以解决现有技术存在的如何保证反盗号的实时性的问题。
本申请实施例还提供一种负载调度方法和装置。
本申请实施例采用下述技术方案:
一种盗号行为的判断系统,包括:分布式日志收集系统、发布订阅消息系统和分布式实时计算系统,其中:
分布式日志收集系统,用于采集服务器的特定访问日志,并发送给发布订阅消息系统;其中,所述特定访问日志,为与用户名和密码验证请求相关的访问日志;
分布式消息订阅系统,用于接收分布式日志收集系统发送的特定访问日志并将接收到的特定访问日志,转化为包含所述特定访问日志的数据的数据流;
分布式实时计算系统,包含若干流式实时分布式计算节点;
所述若干实时分布式计算节点,用于从所述分布式消息订阅系统获取包含所述特定访问日志的数据的数据流;并根据所述数据流,执行指定的任务;所述指定的任务包括:根据预先设置的盗号行为判断方法和所述数据流,判断所述特定访问日志所对应的验证请求方是否存在盗号行为。
一种盗号行为的判断方法,包括:
流式实时分布式计算节点获取根据服务器的特定访问日志生成的数据流;其中,所述特定访问日志,为与用户名和密码验证请求相关的访问日志;
根据所述数据流和预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为。
一种盗号行为的判断装置,包括:
数据流获取单元,用于获取根据服务器的特定访问日志生成的数据流;
判断单元,用于根据所述数据流和预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为。
一种负载调度方法,包括:
主节点预测流式分布式计算系统中的若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载;
当根据预测出的所述总负载,确定出所述若干流式分布式计算节点中,至少有两个流式分布式计算节点在所述任务执行周期内的负载不均衡时,在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度;
其中,第一流式分布式计算节点和第二流式分布式计算节点满足:第一流式分布式计算节点的所述总负载,小于所述第二流式分布式计算节点的所述总负载;
第一任务和第二任务满足:第一任务在所述任务执行周期内为所述第一流式分布式计算节点带来的负载,小于第二任务在所述任务执行周期内为所述第二流式分布式计算节点带来的负载。
一种负载调度装置,包括:
预测单元,用于预测流式分布式计算系统中的若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载;
调度单元,用于当根据预测单元预测出的所述总负载,确定出所述若干流式分布式计算节点中,至少有两个流式分布式计算节点在所述任务执行周期内的负载不均衡时,在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度;
其中,第一流式分布式计算节点和第二流式分布式计算节点满足:第一流式分布式计算节点的所述总负载,小于所述第二流式分布式计算节点的所述总负载;
第一任务和第二任务满足:第一任务在所述任务执行周期内为所述第一流式分布式计算节点带来的负载,小于第二任务在所述任务执行周期内为所述第二流式分布式计算节点带来的负载。
本申请实施例采用的上述至少一个技术方案能够达到以下有益效果:
由于可以由流式实时分布式计算节点根据与用户名和密码验证请求相关的访问日志对应的数据流,以及预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为,因此,实现了对访问日志采用大数据流式计算的方式,而大数据流式计算的方式能够保证高吞吐量和低延迟,因此,可以保证反盗号的实时性。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例提供的一种盗号行为的判断系统的结构示意图;
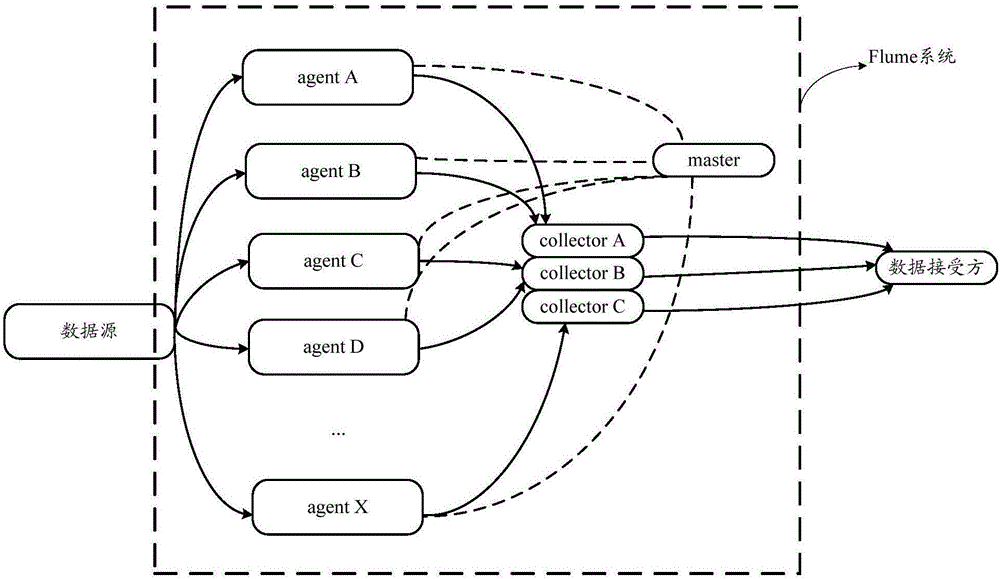
图2为一种典型的Flume系统11的具体结构示意图;
图3为Flume系统11的基于配置的自动日志收集部署功能的实现流程图;
图4为批量计算的示意图;
图5为流式计算的示意图;
图6为Zookeeper与运行有Nimbus的主节点、运行有Supervisor的从节点的关系示意图;
图7为本申请实施例中实现实时负载均衡算法的4个子模块的示意图;
图8为本申请实施例提供的一种盗号行为的判断方法的实现流程图;
图9为本申请实施例提供的一种盗号行为的判断装置的具体结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
以下结合附图,详细说明本申请各实施例提供的技术方案。
实施例1
为解决现有技术存在的如何保证反盗号的实时性的问题,本申请实施例首先提供一种盗号行为的判断系统。该系统的具体结构示意图如图1所示,自顶向下依次包括:
日志采集和发布层。位于该层中的,主要是图1中所示的Flume系统11和Kafka系统12。
分布式实时计算层。位于该层中的,主要是图1中所示的Storm系统13。
运算结果入库层。位于该层中的,主要是存储器14。
输出接口层。位于该层中的,主要是数据输出接口15。
以下对图1中所示的各个部分进行详细介绍。
1、数据源
数据源,可以是指保存有待收集的服务器日志的各个服务器。
其中,这里所说的服务器,可以是网络中任意的能够允许服务器日志被收集的服务器。这里所说的服务器日志,主要是指由用户对服务器进行访问而触发服务器生成的访问日志。一般地,一条访问日志中,可以包含访问方(用户)的IP地址、被访问方(服务器)的IP地址,访问发生的时间、访问方在访问被访问方时所执行的具体操作,等等。针对访问方在访问被访问方时执行的具体操作,比如可以但不限于包括:访问方对被访问方数据库的数据进行增、删或改,或者访问方请求被访问方对用户账号和密码进行验证,等等。
考虑到收集服务器日志的目的,是为了后续根据服务器日志判断是否存在盗号行为,因此,为了避免对服务器日志不加区分地收集,会导致收集与盗号行为无关的服务器日志会浪费处理资源的问题,本申请实施例中,可以将收集对象确定为“与用户名和密码验证请求相关的访问日志”。其中,这里所说的与用户名和密码验证请求相关的访问日志,一般是指服务器在接收到包含用户账号和密码的身份验证请求后生成的与该身份验证请求有关的日志。这样的日志中,一般会包含身份验证请求的发送方的IP地址、接收该身份验证请求的服务器IP地址、接收到该身份验证请求的时间、请求验证的用户账号和密码的信息,以及验证结果(成功或失败)等等。在不同的服务器中,这样的访问日志可以有相同的名称(如命名为checksso),或者有相同的类型信息。
本申请实施例中,从数据源收集服务器的访问日志的方式,可以是日志采集层向作为数据源的服务器,发送访问日志收集请求,该请求中可以包含服务器期望获取的访问日志的类型或者特征(该特征比如可以是checksso)。作为数据源的服务器在接收到访问日志收集请求后,根据该请求,向日志采集层发送相应的访问日志。
在实际中,作为数据源的不同服务器,有可能会采用不同的访问日志发送方式。本申请实施例中,为使得日志采集层能够兼容不同的访问日志发送方式,在日志采集层,具体可以采用Flume系统11来采集访问日志。
以下对Flume系统11如何收集访问日志,以及如何兼容不同的访问日志发送方式,进行详细介绍。
2、Flume系统11
Flume系统11是一个分布式、可靠和高可用的实现海量日志聚合的系统。Flume系统11支持用户定制各类数据发送方(即前文所述的数据源);同时,Flume系统11提供对数据(如收集到的访问日志)进行简单处理和备份,并发送给各种数据接受方(可定制)的能力。
一种典型的Flume系统11的具体结构示意图,如图2所示。由图2可知,Flume系统11采用分层结构,不同分层中包含的节点,分别为agent、collector和master。其中,agent和collector,都可以有三个属性,分别为:source、channel和sink。source是数据来源;channel是将数据从source处获取到之后,在发送给sink前的所采用的数据存储方式;sink是数据去向。这三个属性的值,可以根据实际需求定义。Flume系统11使用两个组件:Master和Node。通过在Master shell或web中对Node进行配置,可以决定Node在Flume系统11中是作为agent还是collector。
除agent、collector和master外,Flume系统11还可以包括storage节点(图2中未示出),该storage节点可以是一个普通文件(file),也可以是Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)、基于Hadoop的数据仓库HIVE或HBase等。
在Flume系统11中,agent用于将来自数据源的数据(如前文所说的访问日志)发送给collector;collector用于将来自于不同agent的数据进行数据汇总后,加载到storage中;storage用于对collector发送来的数据进行保存;master用于理协调agent和collector的配置等信息,是Flume系统11中的由其他节点构成的集群的控制器。
agent和collector从什么地方获取数据,将数据保存在什么地方,以及将数据发送到何处,都可以根据定义agent和collector的source、channel和sink来指定。
针对Flume系统11支持用户定制各类数据发送方的实现方式而言,具体地,用户可以根据数据源所采用的数据发送方式,在进行agent的属性source的定义时,定义agent针对不同数据源的数据接收方式。比如定义数据接收方式为基于Avro的通信方式,或者基于Thrift的通信方式,等。其中,Avro,是一个基于二进制数据传输高性能的中间件;Thrift,是facebook开发用做系统内各语言之间的远程过程调用协议(Remote Procedure Call Protocol,RPC)通信的工具。
具体地,在实际应用中,用于定义agent的属性source的一段代码如下:
#定义源格式
a1.sources.r2.type=spooldir
a1.sources.r2.spoolDir=/data0/data/flume/source/data
a1.sources.r2.decodeErrorPolicy=IGNORE
a1.sources.r2.inputCharset=GB2312
a1.sources.r2.deletePolicy=immediate
a1.sources.r2.batchSize=1000
a1.sources.r2.deserializer.maxLineLength=1048576
针对Flume系统11支持用户定制管道(channel)的类型的实现方式而言,具体地,用户可以根据实际需要,在定义agent(或collector)的属性channel时,对用于保存数据的介质类型,为文件(File)或者存储器(Memery)等进行定义。
具体地,在实际应用中,用于定义agent的属性channel的一段代码如下:
#定义管道类型
a1.channels.c2.type=file
a1.channels.c2.checkpointDir=/data0/data/flume/channel/ck
a1.channels.c2.dataDirs=/data0/data/flume/channel/data
a1.channels.c2.capacity=200000000
a1.channels.c2.keep-alive=30
a1.channels.c2.write-timeout=30
a1.channels.c2.checkpoint-timeout=600
针对Flume系统11支持用户定制数据接受方的实现方式而言,具体地,用户在定义collector(也可能是agent)的属性sink时,可以定义接收数据的目标地址,该目标地址比如可以是HDFS或Kafak等数据接受方的地址。
#定义目标格式
a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.producer.type=sync
a1.sinks.k2.topic=mykafka
a1.sinks.k2.brokerList=10.13.0.104:9092
a1.sinks.k2.requiredAcks=1
a1.sinks.k2.batchSize=20
本申请实施例中,为了使得Flume系统11能够兼容不同数据源采用的数据发送方式,开发了Flume系统11的基于配置的自动日志收集部署功能。
该功能的具体实现方式如图3所示,包括如下步骤:
步骤31,在对Flume系统11执行初始化前,判断是否需要新增agent;若是,则执行步骤32;若否,则执行步骤35;
步骤32,配置待新增的agent的source、channel和sink;
具体而言,在定义agent的source时,可以以数据源所采用的数据发送方式为依据,从而定义出于该数据发送方式相匹配的数据接收方式。
步骤33,在新增的agent的source、channel和sink配置完毕后,将配置完毕的source、channel和sink,发送至用于部署待新增的该agent的设备,以使得该设备根据配置完毕的source、channel和sink,配置agent,从而达到在Flume系统11中新增agent的目的;
步骤33执行完毕后,执行步骤34;
步骤34,触发所有agent启动。
上述步骤,可以是由master执行的;或者,也可以是由Flume系统11中其他不同于master和agent的节点来实现的。针对后一种情况,步骤34中还可以包括:触发master启动。
通过根据提供访问日志的数据源对访问日志的发送方式,来配置agent所采用的数据接收方式,可以实现使Flume系统11能够兼容不同的数据源,从而实现agent从不同的数据源获取访问日志。
3、Kafka系统12
Kafka系统12,是Linkedin所支持的一款开源的、分布式的、高吞吐量的发布订阅消息系统,可以有效地处理互联网中活跃的流式数据,如网站的页面浏览量、用户访问频率、访问统计、好友动态等。在本申请实施例中,Flume系统11采集到的访问日志,可以提供给Kafka系统12,进而由Kafka系统12将访问日志转化为包含访问日志中的数据的数据流后,提供给访问日志的订阅方。该订阅方,具体而言比如是图1中所示的Storm系统13。其中,数据流,是指只能以事先规定好的顺序被读取一次或少数几次的数据的有序序列。
Kafka系统12中,一般通过Zookeeper实现对订阅方和代理的全局状态信息的管理及其对代理进行负载均衡。
由于Kafka系统,已经是比较成熟的相关技术,本申请实施例对其不再进行详细介绍。
4、Storm系统13
Storm系统13,用于订阅并获取Kafka系统12保存的访问日志对应的数据流,并根据所述数据流,判断访问日志对应的发送验证请求的验证方是否存在盗号行为。
以下对Storm系统13功能的实现方式进行详细介绍。
Storm系统13,是Twitter支持开发的一款分布式的、开源的、实时的、主从式大数据流式计算系统。以下对批量计算和流式计算进行对比说明:
图4所示为批量计算的示意图。如图4所示,采用批量计算,首先进行数据的存储,然后再对存储的静态数据进行集中计算。Hadoop是典型的大数据批量计算架构,具体地,在该架构中,由HDFS分布式文件系统负责静态数据的存储,并通过MapReduce将计算逻辑分配到各数据节点进行数据计算。
图5所示为流式计算的示意图。如图5所示,流式计算中,无法确定数据的到来时刻和到来顺序,也无法将全部数据存储起来。因此,不再进行流式数据(数据流)的存储,而是当数据流到来后在内存中直接进行数据的实时计算。数据在任务拓扑中被计算后,任务拓扑输出有价值的计算结果。
流式计算和批量计算分别适用于不同的大数据应用场景:对于先存储后计算、实时性要求不高,同时,数据的准确性、全面性更为重要的应用场景、批量计算模式更合适;对于无需先存储,可以直接进行数据计算,实时性要求很严格,但数据的精确度要求稍微宽松的应用场景,流式计算具有明显优势。
Storm系统13,就是一种采用流式计算的系统。考虑到Storm系统13能够满足实时性要求较高的场景的需求,因此,本申请实施例中,采用Storm系统13来对数据流形式的访问日志进行处理。
基于Storm系统13,任何一个计算任务,都可以通过配置进程级别Worker,线程级别Executor,任务界别Task三级并行度实现高性能计算。同时Storm支持动态调整运行时的三级并行度,这一为接下来要说明的实时负载均衡算法提供基础。
在介绍该实时负载均衡算法前,先对Storm系统13的一些基本情况进行简单说明。
Storm系统13中,主要有两类节点:主节点和工作节点。主节点上运行一个叫“Nimbus”的守护进程,Nimbus负责将任务分配给工作节点并进行故障监测。每个工作节点上运行一个叫“Supervisor”的进程,Supervisor根据Nimbus的委派,在必要时启动或者关闭工作进程。每个工作进程,执行的是被称为“Topology(具体含义见后文)”的工作任务的一个子集。一个运行中的Topology,由很多运行在很多工作节点上的工作进程组成。本申请实施例中,针对反盗号这一业务而言,Nimbus可以将“判断数据流形式的访问日志(与用户名和密码验证请求相关的访问日志)所对应的验证请求方是否存在盗号行为”的任务的子集,分配给若干个运行有Supervisor的子节点来执行,以使得子节点在接收到数据流时能够执行该任务的子集(也称执行任务),从而实现根据所述数据流和预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为。这里所说的数据流形式的访问日志,是指Kafka系统12将访问日志进行转化得到的、包含访问日志的数据的数据流。
本申请实施例中,针对单个子节点而言,它可以采用下述方式,实现根据所述数据流和预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为:
比如,子节点可以在接收到数据流形式的、与用户名和密码验证请求相关的访问日志后,可以从所述与用户名和密码验证请求相关的访问日志中,确定验证失败的验证请求对应的访问日志;从验证失败的验证请求对应的访问日志中,获取验证请求方的IP地址;确定获取到的IP地址中重复出现的IP地址在获取到的所有IP地址中的占比;若确定出的占比中,存在大于预设占比阈值的占比,则可以确定大于预设占比阈值的占比对应的验证请求方,为可能存在盗号行为的验证请求方。本申请实施例中,子节点还可以采用其他方法判断验证请求方是否存在盗号行为,此处不再一一列举。
Nimbus和Supervisor之间所有的协调工作,是通过Zookeeper的集群来实现的。Zookeeper与运行有Nimbus的主节点、运行有Supervisor的子节点的关系示意图如图6所示。
此外需要介绍的是:
Topology,是Storm系统13中运行的一个应用程序。
Spout:是在Topology的运行过程中获取数据流并输出给Bolt的组件,输出给Bolt的数据流,可称为源数据流。通常情况下Spout会从外部数据源(如前文所述的Kafka系统12)处获取数据流。
Bolt:是在一个Topology中接受数据流然后执行处理的组件(该组件相当于子节点)。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。
其中,Spout和Bolt,均可以运行在Storm系统13的子节点上。也就是说,Storm系统13的子节点可以通过Spout,实现获取数据流;通过Bolt,则可以实现根据获取到的数据流完成计算任务。
Tuple:Spout向Bolt进行一次消息传递的基本单元,也是构成源数据流的基本单元。
Stream:源源不断传递的Tuple就组成了Stream。
Storm系统13中,待处理的数据流,可以每次以单个Tuple的形式,发送给Bolt进行处理(也相当于发送给子节点进行处理)。具体而言,是由Spout产生并向Bolt发射一个Tuple。子节点根据该Tuple来执行计算任务,根据该Tuple来执行计算任务所耗费的时间,可以称为一个任务执行周期。Spout发射的该Tuple,可称为源Tuple。Spout发射源Tuple时,可以为源Tuple指定一个message id,这个message id可以是任意的对象(object)。多个源Tuple可以共用一个message id,表示这多个源Tuple是对应于同一数据单元,如对应于Storm系统13订阅的所有访问日志构成的数据集合。
基于上述对Storm系统13的基本情况的介绍,以下说明本申请实施例针对Storm系统13中的子节点提供的实时负载均衡算法。
由于在互联网中,服务器的访问压力是有波峰波谷的,从而在不同时段需要处理的数据量(如访问日志的数据量)差别很大,如何做到动态的依据当前需求调整运算资源,需要一套高效的实时负载均衡算法。区别于离线集群的负载均衡策略,采用流式计算的Storm系统13由于不知道任务的计算量,也不会有任务结束的时刻,因此Storm系统13只能通过一系列预测的手段,来预测子节点的负载并根据预测结果进行任务迁移,资源增减,最终实现各子节点负载近似,并且不会出现超载的情况。
为了实现实时负载均衡算法,本申请实施例中采用如图7所示的4个子模块,它们分别是:集群信息模块,负载检测模块,资源均衡模块和任务迁移模块。以下对该些模块的功能进行介绍:
1)集群信息模块,用于接收Storm系统13中的用于执行任务Task(由任务子集构成)的N个子节点分别发送的、子节点在单个任务执行周期(一般是指处理单个Tuple的周期,这里的该周期,后称为T0)内执行的各个任务给子节点带来的实际负载(后称历史负载),其中,i为子节点的编号,取值范围为[1,N],N为Storm系统13中当前用于执行任务Task的子节点的数量;j为子节点所执行的任务的编号。其中,由于N个子节点均是执行Task的子节点,因此,N个子节点所执行的任务,一般都会包括Task(也即包括Task的任务子集,本申请实施例在语言描述上对此不进行区分),除此之外,N个子节点可能执行不同于Task的其他任务的任务子集。
针对历史负载的含义,具体而言:比如,表示子节点1所执行的编号为2的任务为子节点1带来的负载,若子节点1所执行的任务共有M个,则是子节点1在T0的总负载。根据历史负载本申请实施例中,采用统计预测方法(如灰色预测方法或移动平均算法等),预测各个子节点在下一个任务执行周期(后称T1)的各个任务分别为子节点带来的负载Fij(可称为预测负载Fij)。由于统计预测方法已是现有技术中比较成熟的技术,此处不再赘述。
需要说明的是,针对每个子节点,均可以预测该子节点在K个任务执行周期分别执行第j个任务而承受的预测负载(即共K个预测负载);而后,可以从这K个预测负载中选取一个最大值,作为预测出的该子节点在T1执行第j个任务所承受的预测负载Fij。K越小短期精度越高,越大长期精度越高。集群信息模块在预测出各个子节点的预测负载Fij后,将各个子节点的预测负载Fij发送给负载检测模块。
2)负载检测模块,用于依据集群信息模块提供的数据,判断Storm系统13在T1内是否可能发生过载。具体地,若假设用于执行任务的N个子节点分别执行M个任务,那么,若则说明过载,否则说明不过载。其中,C为过载系数,一般为0.7;Q为所述用于执行任务Task的N个子节点的额定负载之和。若判断结果为过载,则向资源均衡模块提交增加资源申请(此情况不是本申请的关注重点,后文不再进行介绍);若判断结果为不过载,则遍历所述用于执行任务R的N个子节点在T1的预测负载Fij,若得到的遍历结果为存在两个子节点,满足在T1的预测总负载之差的绝对值大于或等于不均衡阈值,即,存在(其中,x、y为子节点的编号,取值范围均为[1,N],且x≠y),则说明子节点的预测总负载不均衡,从而向资源均衡模块提交均衡申请。
3)资源均衡模块,用于接收负载检测模块提交的申请,并在接收到的申请为均衡申请时,执行预设的均衡算法。
具体的,该预设的均衡算法如下:
假设用于执行任务Task的N个子节点中各个子节点在T1内均执行M个任务,那么,计算N个子节点中各个子节点在T1的预测总负载并根据计算结果,按照各个子节点的负载由大至小的顺序,对各个子节点进行排序。假设从子节点的编号来看,排序后的子节点的编号排序依次为:1、2、3…、N,那么,按照“将负载最大的子节点与负载最小的子节点划分到一个节点组合,将负载次大的子节点与负载次小的子节点划分到一个节点组合,以此类推”的方式,将第1个子节点和第N个子节点划分到第1个节点组合中,将第2个子节点和第N-1个子节点划分到第2个节点组合中,以此类推。若N为偶数,则可以得到N/2个节点组合。
针对划分得到的每个节点组合,分别执行下述操作:
针对该节点组合中的负载较小的那个子节点(为便于描述,后称第一子节点),从第一子节点预计在T1会运行的任务中,随机选取一个任务(假设为任务A);
确定随机选取的该任务在T1为第一子节点带来的预测负载(为便于描述,后称该预测负载为第一预测负载);
针对该节点组合中负载较大的那个子节点(为便于描述,后称第二子节点),从第二子节点预计在T1会运行的任务中,选取一个满足预定条件的任务,具体而言,选取在T1为第二子节点带来的预测负载(为便于描述,后称该预测负载为第二预测负载)大于第一预测负载的任务(假设为任务B);
判断第一预测负载和第二预测负载的差值的绝对值,是否小于第一子节点和第二子节点各自在T1的预测总负载的差值的绝对值,若判断结果为是,则说明,若在T1内,将第一子节点预计执行的任务A调整给第二子节点来执行,并将第二子节点预计执行的任务B调整给第一子节点来执行,不会造成第一子节点和第二子节点在T1内各自的总负载之差过大,也就是不会造成负载调整过剩。在判断结果为是时,将第一子节点和第二子节点构成的组合,确定为目标节点组合。目标节点组合,即为可能需要进行任务调整的组合。
本申请实施例中,遍历所有划分得到的节点组合,可以确定出各个目标节点组合。
针对确定出的各个目标组合,对目标组合中子节点预计在T1执行的任务进行交换。
比如,以前文所述的第一子节点和第二子节点构成的组合为例,若该组合被选取作为目标节点组合,则可以对第一子节点中的任务A和第二子节点B中的任务B进行交换。由于第一子节点在T1的预测总负载小于第二子节点在T1的预测总负载,而任务B在T1为第二子节点带来的预测负载大于任务A在T1为第一子节点带来的预测负载,因此,将一个带来较大预测负载的任务B,调度给预测总负载较小的第一子节点,而将一个带来较小预测负载的任务A,调度给预测总负载较大的第二子节点,一般来说,会使得第一子节点和第二子节点在T1的预测总负载变得均衡,从而达到本申请所要达到的负载均衡的目的。
本申请实施例中,资源均衡模块在执行预设的均衡算法后,可以将目标节点组合的信息,以及目标节点组合中待交换的任务的信息,发送给任务迁移模块,由任务迁移模块来实施任务调度操作。具体地,资源均衡模块在执行预设的均衡算法后,可以根据目标节点组合的信息,以及目标节点组合中待交换的任务的信息,生成包含这两个信息的资源调度任务,并将资源调度任务发送给任务迁移模块。
4)任务迁移模块,用于接收负载均衡模块发送的资源调度任务,并执行资源调度任务。具体地,若资源调度任务中包含目标节点组合的信息,以及目标节点组合中待交换的任务的信息,则任务迁移模块执行资源调度任务的具体过程,包括:根据目标节点组合的信息(比如可以是构成目标节点的子节点的ID),确定构成目标节点组合的子节点;根据目标节点组合中待交换的任务的信息,确定构成目标节点组合的子节点的待交换的任务;将待交换的任务进行调度。
比如,以第一子节点和第二子节点构成的目标节点组合为例,若待交换的任务,为第一子节点预计在T1执行的任务A,和第二子节点预计在T1执行的任务B,那么,任务迁移模块在T1到来时,将任务B调度给第一子节点执行,将任务A调度给第二子节点执行。
本申请实施例中,上述集群信息模块,负载检测模块,资源均衡模块和任务迁移模块,可以设置在Storm系统13的主节点中,或者,可以设置在Zookeeper中。
5、存储器14
存储器14,用于保存Storm系统13的运算结果。具体地,Storm系统13在根据数据流和预先设置的盗号行为判断方法,判断访问日志所对应的验证请求方存在盗号行为后,可以将存在盗号行为的验证请求方的信息(如IP地址等),以及用于表示验证请求方存在盗号行为的标记,保存在存储器14中。
6、数据输出接口15
数据输出接口15,用于访问存储器14所保存的数据的访问入口。数据调用方通过调用数据输出接口15,可以访问存储器14所保存的数据。
比如,数据调用方通过调用该数据输出接口15,可以访问存储器14所保存的数据,从而确定存在盗号行为的验证请求方的信息。当确定出的存在盗号行为的验证请求方的信息,为验证请求方的IP地址时,可以执行:根据存在盗号行为的验证请求方的IP地址,对从该IP地址发送出的用于验证用户账号和密码的验证请求进行拦截,从而保证用户账号和密码的安全,达到反盗号的目标。
采用本申请实施例提供的上述系统,由于可以由流式实时分布式计算节点根据与用户名和密码验证请求相关的访问日志对应的数据流,以及预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为,因此,实现了对访问日志采用大数据流式计算的方式,而大数据流式计算的方式能够保证高吞吐量和低延迟,因此,可以保证反盗号的实时性。
实施例2
出于与上述系统相同的发明构思,本申请实施例还提供一种盗号行为的判断方法,该方法包括如图8所示的下述步骤:
步骤81,流式实时分布式计算节点获取根据服务器的特定访问日志生成的数据流;其中,所述特定访问日志,为与用户名和密码验证请求相关的访问日志;
比如,步骤81的具体实现方式可以包括:获取Flume系统根据采集的所述特定访问日志生成的数据流。其中,所述Flume系统中的代理agent节点的source属性,是根据所述服务器的数据发送方式配置的。
步骤82,流式实时分布式计算节点根据所述数据流和预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为。
可选的,所述数据流,可以包含至少两个数组tuple,不同tuple对应不同的任务执行周期;则,为了实现不同流式实时分布式计算节点的负载均衡,本申请实施例提供的该方法还可以包括:
主节点预测所述若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载;
当主节点根据预测出的所述总负载,确定出所述若干流式分布式计算节点中,至少有两个流式分布式计算节点在所述任务执行周期内的负载不均衡时,在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度;
其中,第一流式分布式计算节点和第二流式分布式计算节点满足:第一流式分布式计算节点的所述总负载,小于所述第二流式分布式计算节点的所述总负载;
第一任务和第二任务满足:第一任务在所述任务执行周期内为所述第一流式分布式计算节点带来的负载,小于第二任务在所述任务执行周期内为所述第二流式分布式计算节点带来的负载。
可选的,主节点在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度,具体可以包括:
根据所述若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载,对所述若干流式分布式计算节点进行排序;
根据排序结果,确定由两个流式分布式计算节点构成的各个目标节点组合;
在所述任务执行周期到来时,按照将目标节点组合中的第一流式分布式计算节点的第一任务和目标节点组合中第二流式分布式节点的第二任务进行交换的方式,对所述各个目标节点组合所包含的流式分布式计算节点在所述任务执行周期内执行的任务进行调度。
这里所说的主节点,为与所述流式实时分布式计算节点同属同一流式分布式计算系统的主节点。
主节点对流式实时分布式计算节点的负载进行调度的方式,具体可以参见实施例1中的相关描述,此处不再展开进行详细说明。
由于采用上述方法,可以由流式实时分布式计算节点根据与用户名和密码验证请求相关的访问日志对应的数据流,以及预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为,因此,实现了对访问日志采用大数据流式计算的方式,而大数据流式计算的方式能够保证高吞吐量和低延迟,因此,可以保证反盗号的实时性。
出于与上述方法相同的发明构思,本申请实施例还提供一种盗号行为的判断装置,该装置包括如图9所示的下述功能单元:
数据流获取单元91,用于获取根据服务器的特定访问日志生成的数据流;其中,所述特定访问日志,为与用户名和密码验证请求相关的访问日志;
判断单元92,用于根据所述数据流和预先设置的盗号行为判断方法,判断所述特定访问日志所对应的验证请求方是否存在盗号行为。
出于与上述方法相同的发明构思,本申请实施例还提供一种负载调度方法和装置,方法包括步骤:
1、主节点预测流式分布式计算系统中的若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载;
2、当根据预测出的所述总负载,确定出所述若干流式分布式计算节点中,至少有两个流式分布式计算节点在所述任务执行周期内的负载不均衡时,在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度。
其中,第一流式分布式计算节点和第二流式分布式计算节点满足:第一流式分布式计算节点的所述总负载,小于所述第二流式分布式计算节点的所述总负载;
第一任务和第二任务满足:第一任务在所述任务执行周期内为所述第一流式分布式计算节点带来的负载,小于第二任务在所述任务执行周期内为所述第二流式分布式计算节点带来的负载。
可选的,主节点在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度,具体可以包括:
所述主节点根据所述若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载,对所述若干流式分布式计算节点进行排序;
根据排序结果,确定由两个流式分布式计算节点构成的各个目标节点组合;
在所述任务执行周期到来时,按照将目标节点组合中的第一流式分布式计算节点的第一任务和目标节点组合中第二流式分布式节点的第二任务进行交换的方式,对所述各个目标节点组合所包含的流式分布式计算节点在所述任务执行周期内执行的任务进行调度。
主节点对流式实时分布式计算节点的负载进行调度的方式,具体可以参见实施例1中的相关描述,此处不再展开进行详细说明。
此外,本申请实施例还提供一种负载调度装置,包括:
预测单元,用于预测流式分布式计算系统中的若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载;
调度单元,用于当根据预测单元预测出的所述总负载,确定出所述若干流式分布式计算节点中,至少有两个流式分布式计算节点在所述任务执行周期内的负载不均衡时,在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度。
其中,第一流式分布式计算节点和第二流式分布式计算节点满足:第一流式分布式计算节点的所述总负载,小于所述第二流式分布式计算节点的所述总负载;
第一任务和第二任务满足:第一任务在所述任务执行周期内为所述第一流式分布式计算节点带来的负载,小于第二任务在所述任务执行周期内为所述第二流式分布式计算节点带来的负载。
针对调度单元而言,在一种实施方式中,调度单元在所述任务执行周期到来时,按照将第一流式分布式计算节点的第一任务和第二流式分布式节点的第二任务进行交换的方式,对所述若干流式分布式计算节点所执行的任务进行调度,具体可以包括:
根据所述若干流式分布式计算节点各自在将要到来的任务执行周期内的总负载,对所述若干流式分布式计算节点进行排序;
根据排序结果,确定由两个流式分布式计算节点构成的各个目标节点组合;
在所述任务执行周期到来时,按照将目标节点组合中的第一流式分布式计算节点的第一任务和目标节点组合中第二流式分布式节点的第二任务进行交换的方式,对所述各个目标节点组合所包含的流式分布式计算节点在所述任务执行周期内执行的任务进行调度。
采用本申请实施例提供的上述负载调度方法,由于可以实现将预测负载相对较大的子节点预计要运行的、带来较大负载的任务,调度给预测负载相对小的子节点;并将所述的预测负载相对较小的子节点预计要运行的、带来较小负载的任务,调度给预测负载相对大的子节点,从而可以在一定程度上达到调整子节点负载均衡性的目的。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!