一种基于内容流行度与节点级别匹配的缓存方法与流程
本发明涉及无线通信技术领域,具体涉及一种基于内容流行度与节点级别匹配的缓存方法。
背景技术:
内容中心网络(Content Centric Networking,CCN)是一个基于内容的通信架构,其特点在于用户关注内容本身而不是内容所在位置,因此其更加适应于当前互联网应用所主导的内容的分发和获取。网内缓存技术在CCN中扮演着重要的角色,目前,针对CCN的网内缓存,主要为了解决提高缓存的有效性和减小缓存冗余的问题。现有的缓存方法主要在于以下几个方面:概率缓存模型;通过评估节点的特性(如位置、重要性、缓存能力大小等),选择部分节点来缓存内容;考虑内容的特性(如生存时间、流行度等),对于内容选择性缓存;验证节点的重要性和内容流行度之间存在的关联性。
但是,概率缓存模型由于简单,一般将其作为基础研究;而其它现有的缓存方法设计或单一地考虑一部分节点(如:介数中心性大的节点)或者一部分内容(如:流行度高的内容),并没有考虑全体节点与内容的有效利用。由于网内缓存资源没有能更好地有效利用,使得网内仍存在一定的内容冗余,且网内内容多样性有待提高。虽然目前的研究的确探究了节点重要性与内容之间的联系,却没有给出明确具体的关联值。
技术实现要素:
针对现有技术存在的缺陷,本发明提供了一种基于内容流行度和节点级别匹配的缓存方法,有效利用内容中心网络中缓存空间,使得缓存冗余得以减小。
为实现上述目的,本发明提供了一种内容流行度和节点级别匹配的缓存方法,包括:
步骤S1、当用户发出请求时,将节点信息及当前请求内容流行度的等级加入到兴趣包负载字段中,用户节点根据FIB(路由转发表)转发兴趣包;
步骤S2、根据FIB向内容源转发兴趣包,当转发路径上节点j接收到兴趣包时,记录节点j的三个参数--距离用户跳数、介数中心性、替换率,并且以三元组向量的形式添加至兴趣包中;
步骤S3、当有数据包返回响应兴趣包时,利用灰度关联方法评估转发路径上节点的缓存性能并将节点进行分级,从而确定节点所属级别;
步骤S4、将内容流行度与节点级别的匹配概率添加至数据包,对数据包进行扩展;
步骤S5、当接收到数据包时,按照数据包携带的各节点匹配概率缓存节点缓存数据。
其中,步骤S4中内容流行度与节点级别的匹配概率通过以下公式得到:
其中,为一个分段函数,其中为节点缓存性能隶属级数,k为当前请求的内容流行度等级,K为内容流行度所划分的总级数,k′代表流行内容与非流行内容的分界。
作为进一步优选的,步骤S3)中利用灰度关联方法评估转发路径的缓存性能并将节点进行分级包括以下步骤:
步骤301、从用户发出请求兴趣包至其被响应,兴趣包被转发经过n个节点,经过节点被标记为j(1≤j≤n),考虑节点距离用户的跳数、介数中心性、替换率三个参数,对于经过的第n个节点,其节点距离用户的跳数、介数中心性和替换率分别用Hn′,Bn′和Rn′符号标记表示,其信息矩阵表示为:
每一个参数具有不同的取值范围及性质,需要将每个参数的取值范围标准化为1,过程表示为:
其中,X可以取为节点距离用户的跳数H、介数中心性B或者替换率R,得到新的信息矩阵为:
步骤302、定义L级节点参考序列,根据每一个参数的特点,定义L级节点的参考序列为
步骤303、计算L级的灰色关联系数,可表示为
其中,μ是关联系数,变化范围从0到1;
步骤304、计算每个级别的关联度,对于L级别,关联度可以通过如下公式计算:
其中,aX代表各参数的权重;
步骤305、确定节点缓存性能隶属级数表示为:
其中步骤301中,节点距离用户的跳数用来衡量内容缓存时的链路增益,Hj用来表示节点j距离用户的跳数,Hj越小,获得内容的时延越小。
节点介数中心性用来衡量节点的内容分发能力。内容缓存在介数中心性大的节点上,能加快其分发速度。节点j的介数中心性可以表示为:
公式中δs,t代表从节点s到节点t的最短径数目(即最短路由转发路径数目),δs,t,j代表从节点s到节点t的最短径中途经节点j的路径数目,U代表网络中节点的集合。
节点替换率用来衡量节点的缓存负载,对于节点j,替换率的计算公式为:
其中,Cj是节点j的缓存空间大小,Sj(ci)和M分别是节点j被替换的内容ci的大小和个数,其中i取整数,为缓存替换内容的计数。
作为进一步优选的,其中步骤S4)中,内容的流行程度分为K个流行度级别,网络中被请求的内容属于流行度级别k的概率pk以下公式:
pk=c/(k)α,k=1,…,K (13)
其中,α≠1,且均为常数。
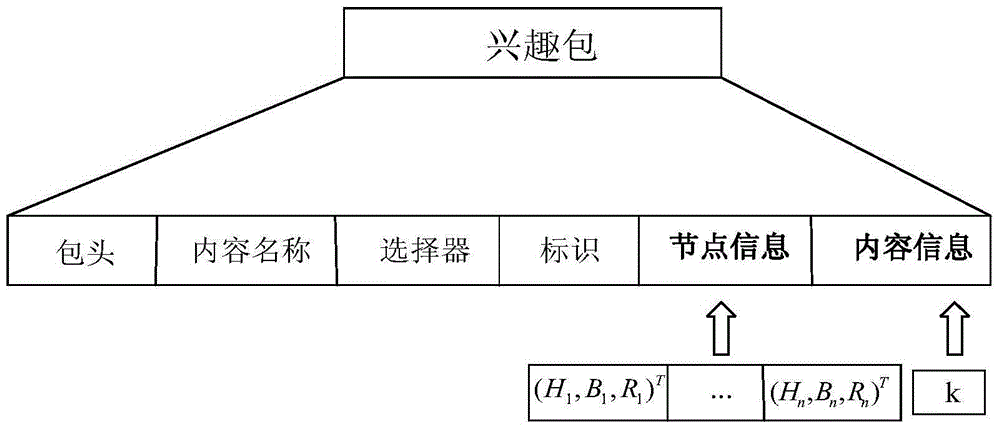
进一步优选地,兴趣包的封装格式为包头、内容名称、选择器、标识、节点信息和内容信息。
进一步优选地,数据包的封装格式为包头、内容名称、签名、签名信息、数据和缓存概率。
由上述技术方案可知,本发明提供一种基于内容流行度和节点级别匹配的缓存方法,通过选取节点距离用户跳数、节点替换率、节点介数中心性三个参数,综合以上参数对节点缓存性能进行评估,根据节点缓存性能的不同对节点分级别,将流行度高的内容以较大概率缓存在性能较好的节点上以保证热门内容的高命中率和较小的内容获取时延,同时降低次流行内容副本在高性能节点上的缓存冗余,减小这些高性能节点的无效缓存;同时,次流行的内容则以较高概率缓存在性能次优的节点上,提高次流行内容的网内命中率,并通过增加副本数量的方式,降低了这类内容的获取时延,同时提升了网内缓存内容的多样性。
与现有技术相比,本发明的优点在于:1、解决了内容中心网络中缓存空间得不到有效利用的问题,使得缓存冗余得以减小;2、解决了现有缓存策略中单一考虑某类节点或某些内容的问题,使得所有节点的缓存空间,以及所有内容都能在网络中得到有效利用,减小网内冗余;3、在内容流行度与节点级别匹配过程中,在一部分节点上提高了次流行内容的缓存概率,减小这部分内容的获取时延,同时提升了网内内容的多样性;4、流行度高的内容以较大概率缓存在缓存性能为第一级别的节点上,所设计的匹配概率减小了流行度高内容不必要的缓存替换,使得缓存命中率及缓存内容获取时延都将获得较大的性能提升。
附图说明
图1是本发明的兴趣包的封装格式;
图2是本发明的数据包的封装格式;
图3是本发明的基于内容流行度与节点级别匹配缓存方法流程图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
图3示出了本发明一实施例提供的一种基于内容流行度与节点级别匹配缓存方法流程图,如图所示,该方法包括如下步骤:
步骤S1、当用户发出兴趣请求,将节点信息及当前请求内容流行度的等级k加入到兴趣包负载字段中,用户节点根据FIB(路由转发表设置路由向内容源转发兴趣包)转发兴趣包。
步骤S2、当转发路径上节点j接收到兴趣包时,记录节点j的三个参数--距离用户跳数、介数中心性、替换率,并且以三元组向量的形式被添加至兴趣包中。兴趣包的封装格式如图1。
步骤S3、当有数据包返回响应兴趣包时,利用灰度关联方法评估转发路径上节点的缓存性能并将节点进行分级,从而节点所属级别即可确定。
步骤S4、将内容流行度与节点级别的匹配概率添加至数据包,对数据包进行扩展。数据包的封装格式为图2。
步骤S5、当接收到数据包时,按照数据包携带的各节点匹配概率缓存节点缓存数据。
下面通过具体的实施例对上述方法步骤S3和S4进行详细说明。
1、基于灰度关联方法将节点分级
当给定多个影响因素,灰色关联方法得出的灰色关联度可以决定参考序列及一系列对比序列之间的关联程度。在评估节点性能时,通过选取合适的节点缓存性能参考序列,对转发路径上的节点缓存性能进行评估及分级,具体过程分为5步:
301)从用户发出请求兴趣包至其被响应(无论是服务器还是中间节点),兴趣包被转发经过n个节点,经过节点被标记为j(1≤j≤n),考虑节点距离用户的跳数、介数中心性、替换率三个参数。
其中,节点距离用户的跳数用来衡量内容缓存时的链路增益,Hj用来表示节点j距离用户的跳数。Hj越小,获得内容的时延越小。
节点介数中心性用来衡量节点的内容分发能力。内容缓存在介数中心性大的节点上,能加快其分发速度。节点j的介数中心性可以表示为:
公式中δs,t代表从节点s到节点t的最短径数目(即最短路由转发路径数目),δs,t,j代表从节点s到节点t的最短径中途经节点j的路径数目,U代表网络中节点的集合。
节点替换率用来衡量节点的缓存负载。在CCN中,同请求内容相比,缓存空间大小是有限的,当缓存达到极限时,需要发生缓存替换来缓存新内容。当缓存替换频繁发生时,即使很流行的内容也会被很快替换出去。对于节点j,替换率的计算公式为:
其中,Cj是节点j的缓存空间大小,Sj(ci)和M分别是节点j被替换的内容ci的大小和个数,其中i取整数,为缓存替换内容的计数。
如对于经过的第n个节点,Hn′,Bn′和Rn′分别代表其跳数、介数中心性和替换率。所以灰度关联方法中的信息矩阵表示为:
每一个参数具有不同的取值范围及性质,需要将每个参数的取值范围标准化为1。过程表示为:
其中,X可以取为节点距离用户跳数H、介数中心性B或者替换率R,我们得到新的信息矩阵为:
302)定义L级节点参考序列。我们给出的参考序列是每一级的理想序列,根据每一个参数的特点,定义L级节点的参考序列为本发明中选取L∈{1,2},将节点总共分为两级。
303)计算L级的灰色关联系数,可表示为
其中,μ是关联系数,变化范围从0到1。本发明中选取μ=0.5。
304)计算每个级别的关联度。对于L级别,关联度可以通过如下公式计算:
其中,aX代表各参数的权重。
305)决定节点的所属级别表示为:
2、内容流行度与节点级别的匹配概率的算法
用户发出请求,兴趣包沿着转发路径记录转发节点的距离用户跳数、介数中心性、替换率,当有数据包响应时,在命中节点或服务器完成上述基于灰度关联方法评估节点缓存性能及分级。当节点缓存性能隶属级数确定了,本发明定义了内容流行度与节点级别的匹配概率。
根据互联网用户请求流量的分布特点确定,网内内容根据其被请求的次数,划分出流行度等级,本发明将内容的流行程度分为K个流行度级别,假设网络中被请求的内容属于流行度级别k的概率pk服从Zipf分布,即
pk=c/(k)α,k=1,…,K (25)
其中,α≠1,且均为常数。由公式可知,pk会随着k值的增大而减小,级别k=1代表内容流行程度最高。
定义内容流行度与节点级别的匹配概率
本发明中将设置为一个分段函数,其中为节点缓存性能隶属级数,k为当前请求的内容流行度,K为内容流行度所划分的总级数,k′代表流行内容与非流行内容的分界。
可见,本发明的基于内容流行度和节点级别匹配的缓存策略,适用于内容中心无线网络,实现了内容流行度与节点级别的匹配,评估转发路径上每个节点的缓存性能,从节点距离用户的跳数、介数中心性、替换率三个参数方面来综合评价节点缓存性能,其中选用灰度关联方法来评估同时并将节点进行分级。利用本发明设计的内容流行度与节点级别的匹配概率,节点对内容做出缓存决策。
本发明的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!