一种基于延时的链路故障诊断方法与流程
本发明属于网络故障诊断技术领域,尤其涉及一种基于延时的链路故障诊断方法。
背景技术:
统计表明,链路故障在网络故障总量中约占有80%的比重,因此,链路故障是网络中最常发生的故障之一。除了导致链路不通的故障,链路故障多种多样,比如以下情况。网卡等网络硬件故障,或网络驱动程序故障会导致的网络风暴造成链路质量下降。蠕虫病毒的影响导致网速变慢,通过e-mail散发的蠕虫病毒对网络速度的影响越来越严重,危害性极大。不恰当的设备配置,比如网络两端的工作模式配置不一致,一端是双攻模式,另外一端是半双工模式,从而导致丢包。也有可能是最大传输单元配置不一致导致丢包。过多的网络流量,由蠕虫病毒、网络攻击等引起的突发流量超过端口最大速率导致丢包或者延时增加。由此可见以上故障主要会导致丢包率或者网络延时增加,为了提高网络的吞吐量,快速的找到故障链路对于精确定位故障原因具有重要意义。定位链路质量故障需要解决两个问题,一是用什么方法来得到链路质量,二是用何种方法来定位故障。最容易想到的检测链路质量的方法就是通过广播的方式,每一个节点都向邻居节点发送数据包,就能得到所有链路的链路质量。这种方法被称为为bap(broadcast-basedactiveprobing)。而kyu-hankim等人的ear(efficientandaccuratelink-qualitymonitor)算法采用passivemonitoring和activemonitoring结合的方式来检测无线网的链路质量。对于有足够包的链路,只要监听mac层包的到达情况。而对于包不够的链路主动发送数据包统计到达情况用以计算链路质量。并将linkcost和capacity作为链路质量的判断标准,虽然与广播的方式相比已经大大减少了通信量,但是为了获得网络的capacity和linkcost仍然需要足够多的数据包。由于延时和丢包率是端到端统计量,链路质量又可以通过探测的方式获取。探测是一系列的测试事务,可以是ping,traceroutes也可是是http请求,探测的失败或者成功依赖于被探测部件的状态。探测通常用于获取端到端统计量,比如延时、吞吐量、丢包率。上述只解决了得到链路质量的问题,为了定位链路故障最容易想到的方式是得到每一条链路的质量,再根据阀值确定该条链路是否发生故障。与传统的故障诊断方法相比,自适应探测的方法在故障诊断过程中只需少量的通信量。而且能自适应的选择探测来推断当前的网络状况,并且他能通过选择在问题范围内的探测,将问题逐渐缩小。主动探测除了可以灵活的设计探测包来满足探测需要之外,还可以发送少量的探测来定位发生故障的部件。为了防止探测包影响网络原本的状况,发出的探测需要尽量的少。
现有的故障诊断方法大多诊断网络的连通性,无法诊断由于链路误码等原因造成的链路质量下降,以及频繁丢包的情况,链路质量差。
技术实现要素:
本发明的目的在于提供一种基于延时的链路故障诊断方法,旨在解决诊断由于链路误码等原因造成的链路质量下降,以及频繁丢包的问题。
本发明是这样实现的,一种基于延时的链路故障诊断方法,所述基于延时的链路故障诊断方法包括:探测站的选择、故障探测、故障定位三个阶段;采用自适应探测的方法诊断故障链路,选取一部分探测来探测网络中是否有延时太大的链路,然后在故障定位阶段,进一步选取探测来定位故障链路。
进一步,将链路的一端既不是探测站,又没有k条独立路径通过的链路称为阴影链路。所述探测站的选择问题就变为选择节点加入到探测站集合中,直到网络中没有阴影链路。
进一步,所述故障探测阶段具体包括:
链路集合l=(l1,…,ln)以及探测集合t={t1,t2,…,tr},依赖矩阵表示为:
其中,一行代表一个探测,一列代表一个节点,n1和n2是探测站;
从可得的探测集合中选择探测,待探测链路集合s,探测集合x,将网络中所有链路加入集合s中,探测集合x赋值为空,根据公式:
定义的依赖矩阵每次都选择能够探测到最多待探测链路的探测,然后将选择的探测中包含的链路从待探测集合s中去掉,重复上述步骤,直到待探测链路集合为空集。
进一步,所述故障探测阶段包括:
进一步,所述故障定位阶段分为结果分析和选择探测。首先要分析结果时根据公式
本发明提供的基于延时的链路故障诊断方法,能准确定位故障链路,且产生较少的通信量。本发明具体分析了失败探测的延时范围,以及如何用自适应探测的方法来诊断链路质量故障,并给出了实验结果,本发明的算法平均每条链路所需的探测数为1,而bap算法平均每条链路的所需的探测数为10;本发明故障定位阶段的通信量为2000bit/sec,而如果是每个节点都像邻居节点发包通信量为13000bit/sec。实验结果表明结果表明本发明既能诊断故障链路,又能在故障诊断过程中大大减少了发出的探测数量,减小了故障诊断发出的探测对网络的影响。
附图说明
图1是本发明实施例提供的基于延时的链路故障诊断方法流程图。
图2是本发明实施例提供的基于延时的链路诊断算法示意图;
图中:a故障探测阶段;b故障定位阶段。
图3是本发明实施例提供的当节点1为探测站时的示意图。
图4是本发明实施例提供的从网络拓扑到依赖矩阵的映射示意图;
图中:a网络拓扑图;b依赖矩阵。
图5是本发明实施例提供的基于延时的链路故障诊断节点模型示意图。
图6是本发明实施例提供的net模块进程模型示意图。
图7是本发明实施例提供的通信量变化示意图。
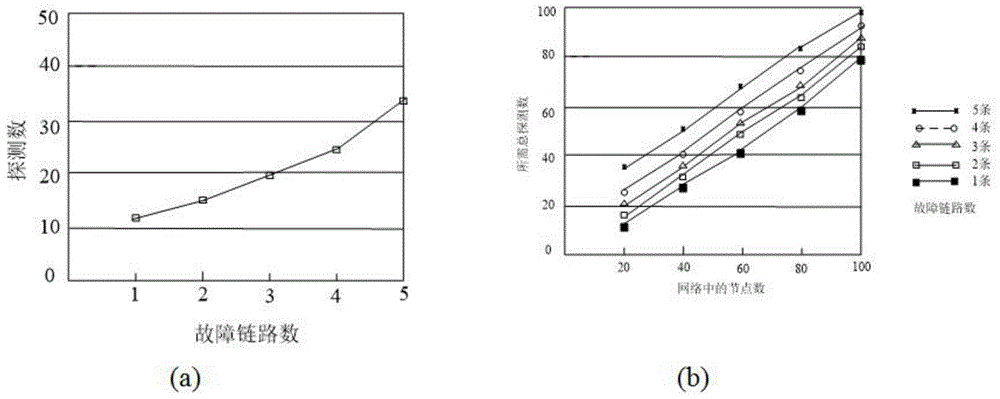
图8是本发明实施例提供的不同节点数以及不同故障数所需探测数示意图。
图9是本发明实施例提供的不同链路的平均探测数示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例的基于延时的链路故障诊断方法包括以下步骤:
s101:选择节点加入到探测站集合中,直到网络中没有阴影链路;
s102:故障探测阶段选出的探测集合要能探测到网络中所有链路,一旦有某条链路发生故障,探测集合要能发现这个故障;
s103:在故障定位阶段分析结果时首先判断标准来判断失败探测和成功探测,失败的探测说明该探测上必包含一条故障链路,成功的探测说明该探测上的链路都没有发生故障。
下面结合具体实施例对本发明的应用原理作进一步的描述。
1、基本概念
链路故障主要表现为丢包率和延时增加。当网络上的一个或多个数据包无法到达目的节点时丢包发生,丢包率用丢包数与发包数的百分比来衡量,通常在吞吐量范围内测试,发包数越大丢包率测量越准确,因此统计丢包率需要足够的数据包。而使用探测的方法,主动发送过多的数据包会影响网络性能,所以采用延时来判断链路质量。
延时公式描述了从源节点到目的节点路径上的每个节点的延时。
dnodal=dproc+dqueue+dtrans+ddrop(1)
为了简化网络延时的分析,包延时被分为一系列的节点延时,每个节点延时是到达这个节点时间与到达下一节点的时间之差。延时公式将节点延时又划分为四个部分,处理延迟、排队延迟、传输延时、传播延迟,更加便于研究。
节点处理延迟是一个节点用于处理包的时间。这个时间包括错误检查,用于读取数据包报头的时间,和用于基于所述目标地址查找连接到下一个节点链路的时间。尽管该部分延时看起来复杂,相对于在延迟方程中其他部分而言处理延迟通常是可以忽略不计。
排队延迟是在一个节点的队列中等待其他包被发送的时间。如果该节点是一个高速路由器每个输出链路都有一个队列,一个包只等待要被发送到相同链路的其他包。
排队延时又与传输延时相关
dqueue=dtrans*lqueue(2)
其中,lqueue是队列的平均长度。平均队列长度取决于负载因子,即所尝试的链路的传输速率与链路最大传输速率的比值。当负载因数小于1/2时,平均队列长度通常小于1。当负载因数超过1,队列长度的增长没有上限。
传输延迟dtrans是把整个包送入通信媒体所需要的时间。它可以由下面的等式来计算。
dtrans=l/r(3)
这里,l是分组的长度,以位为单位,r是在单位时间内的比特传输速率。
传播延迟dprop是,信号通过传输介质从一个节点传输到另一个节点的时间。它可以使用以下公式来计算。
dprop=distance/s(4)
这里,distance是从该节点到下一个节点的距离,s是介质的传播速度。
对于使用无线电广播链路,一个信号传播速度接近光速的速度。对于铜和光纤链路,传播速度是
由此可见网络延时由数据所经过的跳数(也就是网络延时的不确定性主要由所经过的路由器的个数和路由器的处理时延引起的。
传播延时和传输延时是固定不变的部分,而处理延时和排队延时反映了网络延时的变化的部分。传播延时和传输延时主要反映了路径中链路的各种属性,即组成路径的各条链路的带宽、长度、介质等;处理延时和排队延时主要由包在网络转发节点中的排队造成,反映了网络的拥塞程度。由此可见线路本身的故障会导致延时的固定部分增加,而拥塞会导致延时的可变部分增加。
为了利用网络延时来诊断链路故障,首先要确定一条失败的探测它的延时满足什么样的条件。
bij等人bij,wuq,liz(2003)measurementandanalysisofinternetdelaybottlenecks.chinjcomput26:406-416]通过对caid组织授权的海量样本数据进行多次采样并做分析后得到结论端到端延时呈现多峰分布,两个峰值的范围在[20,50],[75,100]。
而lic等人lic,zhaoh,zhangx,yuans(2008)researchonthecharacteristicbehaviorofinternetdominantdelay.actaelectronicasinica36:1063-1067.]对internet中遍布全球的47个节点之间的2117条路径进行一个月的测量的基础上,测得其平均延时为196.96ms,其中固有延时平均160.74ms,动态延时的平均值为36.22ms。
由于可见不同规模的网络延时有所差别,很难用一个统一的阀值去定义一条失败的探测。因此在定位故障之前需要一个学习过程来定义阀值。
很容易想到采用平均延时的方式来定义探测是否失败。给定探测结果集d=(d1,…,dn)以及每条探测对应的长度li:
其中
其中di0是未发生故障时第i个端到端探测的延时,li0是未发生故障时第i个端到端探测的长度。
2定位链路故障的方法
2.1自适应探测
自适应探测的流程图如图1所示,自适应探测探测用于故障定位有三个主要步骤:探测站的选择、故障探测、故障定位。
1、探测站的选择:选择一些位置来放置探测站。探测站是配备发送探测以及分析探测结果的节点,所有可用的探测都从探测站发出。探测站只能在有限的节点上配备。在探测站的选择阶段,需要用最少的探测站保证网络中所有节点都能被探测站发出的探测检测到。假设网络中出现故障的节点最多有k个,除了探测站之外每个节点都有可能发生错误。为了保证除了探测站之外的节点都能被发出的探测覆盖到,每个节点最少需要k条经过它的独立路径。因为如果网络中的k-1个错误都发生在经过某一个节点x的路径上,那么必须保证还有一条路径能够探测到这个节点的情况。
2、故障探测:即探测集合的选择,故障探测阶段选出的探测集合要能覆盖网络中所有节点,一旦有某个部件发生故障,探测集合要能发现这个故障。要找出最少的探测个数来覆盖所有节点,这是一个最小覆盖集合问题,它是一个np难问题。
3、故障定位:故障定位阶段需要根据探测结果发出更多的探测来确定那些状态未知的节点是否发生故障。故障定位阶段又涉及到探测集合的选择,以及探测结果分析。探测集合的选择也是一个np难的问题,在探测结果分析阶段,考虑到由于丢包等原因造成的探测结果的不确定性。
2.2用自适应探测来定位故障链路
为了减少故障诊断过程中的发包数,采用自适应探测来定位故障链路,用自适应探测来定位故障链路,首先是选择探测站,然后在探测阶段定期发送一些端到端探测来探测网络中的延时情况,如果发现有延时超出阀值的,开始故障定位阶段,逐步缩小故障范围直到找到故障。
如图2所示:在故障探测阶段,图(a)发送探测p1->n2,p1->n1->n4->n5->n6以及探测p2->n6->n3->n2->n7来探测网络中是否有链路发生故障。得到的探测结果p1到n5之间的延时超过阀值,表明此时有链路发生了故障,分析结果发现有可能是路径p1->n1->n4->n5上的一条或者多条链路发生了故障,开始故障定位阶段,进一步发送探测来定位故障链路。
如图2(b),在故障定位阶段发送p1->n1以及p1->n1->n4来定位故障。得到的探测结果p1->n1的延时没有超过阀值,而p1->n1->n4的延时超过阀值,就可以断定是链路(n1,n4)发生了故障导致延时增加。
2.2.1探测站的选择
用自适应探测来定位链路故障节点变为链路。
定理1:假定至多k条故障链路的ip一致路由模型,当且仅当有k条独立的路径通过每一条链路时探测站能定位任意k条链路故障。
在ip一致路由模型中,如果从两个不同的探测站向同一目的地址发出的探测中有一个共同节点,那么两条探测路径中,从公共节点向后的所有节点都相同。后面所述的内容都是假定本发明所述的网络环境是在ip一致路由模型中。
为了判断是通过一个节点的两条路径否是相互独立,只要比较两条路径的前驱节点,如果不同就是相互独立的。
图3中的示例解释了该定理:在图3中,节点1是探测站,在至多有2条链路故障的情况下,假设链路l(1,3),l(3,8)发生故障,导致p1,p3延时过大,探测站1只能再发出探测p2,推断出l(1,3)故障,无法推断出l(3,8)的状态。即l(3,8)的状态被l(1,3)遮蔽了。为了保证l(3,8)的状态也能被探测到,必须有其他不经过l(1,3)的探测,比如增加一个探测站9,从9到3发出探测,从9到6再发出探测,9到3的探测失败,而9到6的探测成功,由此推断出l(3,8)发生故障。
将链路的一端既不是探测站,又没有k条独立路径通过的链路称为阴影链路。探测站的选择问题就变为选择节点加入到探测站集合中,直到网络中没有阴影链路。
不管是采用随机选择法,贪心算法,还是将探测站的选择问题映射为最小碰撞集,只需要将算法中的满足条件改为定理1。
以随机选择算法为例,每次都随机的选择一个节点加入到探测站集合中,直到网络中没有阴影链路。
而贪心算法则是,每次都将能使阴影链路数最少的节点选入探测站集合,直到网络中没有阴影链路。
2.2.2探测阶段
选定探测站以后就能得到一个可选择的探测集合,只不过当用于诊断链路故障时,依赖矩阵应当用来表示探测和链路之间的关系[12],而非探测和节点的关系。
给定一个链路集合l=(l1,…,ln)以及探测集合t={t1,t2,…,tr},依赖矩阵表示为:
其中,一行代表一个探测,一列代表一个节点,一个依赖矩阵的例子,其中n1和n2是探测站。
探测阶段即从可得的探测集合中选择一些探测,故障探测阶段选出的探测集合要能探测到网络中所有链路,一旦有某条链路发生故障,探测集合要能发现这个故障。要找出最少的探测个数来探测所有链路,这是一个最小覆盖集合问题。
最小覆盖集合问题:
已知:一个有限集e,一个由e的子集组成的集合c,一个整数k;
问题:是否存在一个个数为k的集合
它是一个np难问题。最典型的解决最小覆盖集合的方法是贪心算法。定义一个待探测链路集合s,一个探测集合x,算法一开始将网络中所有链路加入集合s中,探测集合x赋值为空。贪心算法根据公式(5-7)定义的依赖矩阵每次都选择能够探测到最多待探测链路的探测,然后将选择的探测中包含的链路从待探测集合s中去掉,重复上述步骤,直到待探测链路集合为空集。比如图4节中,三条探测都能探测到两条链路,那么按照顺序选择探测p15,下一轮中选择p24,待探测集合还剩l2,l6,然后把探测p16选入探测集合中,此时待探测集合为空,并得到一个探测集合d={p15,p24,p16}。
伪代码如下所示:
2.3.3定位阶段
(1)探测结果分析
在故障定位阶段分析结果时首先根据公式(5)的判断标准来判断失败探测和成功探测。由于本发明假定是在静态路由无噪声的情况,因此失败的探测说明该探测上必包含一条故障链路,而成功的探测说明该探测上的链路都没有发生故障。定义三个集合,完好链路、可疑链路、故障链路。那么就可以将失败的探测路径上包含的链路加入可疑链路集合中,将成功的探测路径上包含的链路加入完好链路集合中,如果一条失败的探测中只含有一条可疑链路,那么该链路就是故障链路。
(2)进一步选择探测
当还有链路的状态不能确定时,即可疑节点集合中还有节点时,还需进一步选择探测定位故障链路。这一阶段的探测选择与故障探测阶段的探测选择相似,只是所要探测的链路变为可疑链路集合中的链路。且需要注意所选的链路不能包含故障链路。仅需将上一节中的可得的探测集合availableprobes去掉包含故障节点的探测,并且将待探测集合s初始化为本节中的可疑节点集合。
下面结合仿真实验对本发明的应用效果作详细的描述。
1仿真实现
仿真在opnet平台上实现,网络模型中采用的节点模型如图5所示,app_gen模块产生数据包,net模块负责转发包以及故障诊断,sink模块销毁收到的数据包,其中app_gen和sink模块的进程模型都由opnet库提供。pt_0、pt_1、pt_2、pt_3,是发信机,pt_0、pt_1、pt_2、pt_3是收信机。收信机和发信机也由opnet库提供,收发信机模拟发包和收包过程,提供差错检验、计算延时等功能。
图6是inet模块的进程模型。inet模块主要有三个功能,1、拓扑发现,用于得到网络拓扑图,以及邻居节点的对应发信机。2、路由功能,3、故障诊断功能。
在拓扑发现部分,在仿真开始时让每一个节点都向他的邻居节点发送hello包,当邻居收到hello包之后更新网络拓扑,当所有节点收到来自邻居节点的hello包并跟新拓扑之后就能得到一个完整的网络拓扑图。
路由功能首先根据dijkstra算法找到下一跳节点,然后找到下一跳节点对应的发信机,将数据包从net模块转发到对应的发信机。dijkstra算法是利用最短路径的最优子结构,主要思想是对源结点首先从与其他相邻结点中选择一条距离最短的节点v,将该节点v加入结果集r,并根据节点v来更新源节点到其他节点的距离。算法开始前初始化源节点到各个目的节点到达最短距离,算法开始后会逐渐找到最短路径节点并更新最短路径距离,直至所有的目的节点都找到最短距离路径序列。
故障诊断功能由send,receive,stat_lost,revise,send_probe四个状态完成。send状态是在故障探测阶段发送探测包,receive状态是接收数据包并转发,stat_lost状态是得到探测包的延时,如果在这一状态发现网络中有故障链路就转到revise状态分析探测结果并选择新的探测来定位故障,然后转到send_probe状态发送故障定位阶段的数据包。
另外仿真中定义了两种数据包,一种是hello包。另一种是pkt包。hello包有两个字段,包类型和源地址。pkt包有四个字段,包类型、源地址、目的地址、跳数。
还定义了链路模型,链路模型支持pkt包和hello包,数据速率为1024bit/s,其他默认。
2实验结果
仿真过程中平均节点度设为4、对不同故障节点数以及总节点数进行仿真,将发送的平均探测数作为评价指标。设定仿真一开始就发生了故障。因此故障探测阶段只发送一次探测就转到故障定位阶段。
如图7所示是20个节点1个故障时整个仿真过程中通信量变化示意图,10s处通信量很大大是因为每个节点都像邻居节点发包来得到网络拓扑,20秒是故障探测阶段,30秒以后故障定位阶段开始,不断发包缩小故障范围,直到140s找到故障链路,仿真结束不再发包。由图可知整个仿真过程中由故障诊断系统主动发出的探测包通信量始终在一个较低的范围内。
如图8(a)所示是网络中有20个节点时时,定位不同故障链路数所需的总探测数。图8(a)的结果表明当故障链路数增加时,定位故障链路所需的探测总数也随之增加。图8(b)是不同节点总述定位链路故障所需探测总数,结果表明当节点总数增加时,定位链路故障所需探测总数也增加。
图9从左到右依次是本发明的算法所有链路、bap算法的所有链路、ear算法的不同链路所需的平均探测数。ear算法利用网络中已有的通信量来检测每条链路的链路质量,由图可知,通信量不同的链路所需发出的探测数不同,通信量低的链路主要通过发出主动探测来得到链路质量,发出数据包多的链路主要通过被动探测来获得链路质量。仅比较ear算法发出的主动探测部分与bap算法、本发明的算法进行比较。尽管ear算法与bap算法相比已经通过监听网络中已有的通信量减少了主动发出的探测,但是其算法的核心仍然需要足够量的发往邻居节点的包。对比图中的可知本发明的算法平均每条链路所需的探测数大约为1,与ear算法相比大大减少了发出的探测数。这是由于本发明中的算法不需要对每一条链路都检测链路质量,只需通过少数端到端探测找到链路质量较差的链路。
除了链路的连通性以外,链路质量故障在网络故障总量中约占有很大的比重,通过分析发现链路质量故障定位可以使用探测的方法,且自适应探测能减少通信量,本发明具体分析了失败探测的延时范围,以及如何用自适应探测的方法来诊断链路质量故障,并给出了实验结果,结果表明本发明方既能诊断故障链路,又能在故障诊断过程中大大减少了发出的探测数量,减小了故障诊断发出的探测对网络的影响。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!