助听器的基于原位优化的能力的制作方法
本发明提供一种新型助听器系统,其有利于确定助听器系统用户的听力能力和针对改善的听力能力对助听器的调整。该调整可基于其它助听器系统的用户的所确定的听力能力。
背景技术:
现今的助听器通常具有信号处理器和许多不同的信号处理算法,其中每个算法定制用于特定用户偏好和声音环境的特定类别。各种信号处理算法的信号处理参数通常在药剂师办公室中的初始适配区段期间确定并通过激活所需算法及将算法参数设置在助听器的非易失存储器区和/或传输所需算法及算法参数设定至非易失存储器区而编程到助听器中。
通常,相比于与听觉损失相关的全部细微差别,听力矫正专家在给每个患者适配助听器上花费的时间是非常有限的。存在诊断规程,其将优化前述助听器参数,从而最大化患者将摆脱其听觉仪器的益处。遗憾地,进行这些规程所需要的时间对于听觉矫正专家而言是禁止的且相反地他们常常诉诸于带有最小个性化的自动适配规程。这导致病人对听觉矫正专家的若干回访,或者病人放弃且认定听觉仪器更多是负担而非益处且仪器最终不被使用。
另一个重要挑战是适配规程基于由助听器制造商限定的参数模型。该模型可基于例如响度知觉、耳蜗压缩建模和/或可听度阈值偏移。这意味着解空间和可能的助听器构造受限于设计科学家想到关于听觉损失他们所知道内容,或基本上该听力模型在预测个体患者的听力能力中有多好。
从若干研究中知道,通常使用的听觉损失模型根本上错误的。例如,如果助听器适配以精确地补偿在耳蜗中压缩的模型式损失,则声音将不舒服地大,这指示模型有瑕疵。模型失效的另一个示例为当借助类似或接近于同一听力图尝试适配听觉受损对象时,却有不同水平的认知;这里,执行对象越得益于音节压缩,然而执行患者从该压缩中较长时间常数受益较多就越低。挑战在于助听器的优化基于调整据信借助听众能力校正的模型,但实际上不是这样。
另外,即使揭示改变数据属性的新知识,参数模型也不具有改变根本特性的性能。
技术实现要素:
原位适配系统
为了获得助听器系统的用户的具有改善的听力能力,提供一种助听器系统,该助听器系统利于其用户的听力能力的确定及形成原位适配(in situ fitting)系统的一部分,所述原位适配系统具有至少一个服务器,配置成调整用于改善的其用户听力能力的助听器系统的助听器信号处理参数。
因此,本发明提供配置成在助听器系统正常使用期间调整多个助听器系统的助听器信号处理参数的原位适配系统,其包括
至少一个服务器,与所述多个助听器系统互连,
所述多个助听器系统,所述助听器系统的每个包括
助听器,所述助听器具有
麦克风,用于响应于在所述麦克风处从声音环境接收的声音信号来提供音频信号,
处理器,配置成成根据信号处理算法来处理所述音频信号,从而产生听觉损失补偿音频信号,其中所述为所述信号处理算法Fn的一组处理参数
输出换能器,其用于基于所述听觉损失补偿音频信号向所述助听器系统的用户提供输出信号,以及
服务器接口,配置成与所述至少一个服务器通信,
能力检测器,对于所述多个助听器系统中的每个,所述能力检测器与所述多个助听器系统中各自的一个相关联,并且配置成确定所述相关联的助听器系统的用户的听力能力,并且其中
所述至少一个服务器配置成:
基于所述多个助听器系统的多个用户的已确定的听力能力,确定所述多个助听器系统中的一个的助听器的所述信号处理参数n、中的一个的值,以及
将关于所述确定值的信息传输到所述助听器,并且其中
所述助听器的处理器配置成在接收所述信息时将所述信号处理参数n、设置成所述已确定的值。
关于信号处理参数值的信息可以以适用于传输到讨论中助听器的控制信号的形式来传输,控制信号在助听器中编码且随后在通过助听器接收时控制助听器以设置信号处理参数为所确定的值。该信息可为编码成适用于传输到助听器的形式的所确定值自身。
原位适配系统在各自助听器正常使用期间(即,在助听器佩戴在用户耳朵的助听器预定位置时)执行助听器信号处理参数n和的调整和根据佩戴助听器的各自用户的个体听觉损失执行听觉损失补偿。该调整响应一个或多个用户的听力能力而执行,所述损失听力能力由各自配置成确定听力能力(其涉及用户能够听到和响应由用户佩戴的助听器接收的声音有多大程度)的一个或多个能力检测器来确定。
原位适配系统可配置成借助信号处理算法的函数库在助听器系统中至少一个信号处理参数的自动调整,其中为信号处理算法Fn的一组信号处理参数可能包括控制用于实行的一个或多个算法的选择的指数参数n的自动调整,例如,噪音压缩算法可选择用于在噪音环境中实行且可不选择用于在安静环境中实行。因此n也为信号处理参数且可通过原位适配系统自动调整。
原位适配系统包括用于其功能需要的计算功率和存储器资源的供给的至少一个服务器。例如,至少一个服务器可包括多个助听器系统的能力检测器或与多个助听器系统关联的能力检测器,且可配置成从多个助听器系统接收涉及其用户听力能力的数据且可配置成基于所接收的数据确定用户听力能力和为了改善听力能力响应所确定的用户听力能力来确定多个助听器系统的助听器的信号处理参数。
至少一个服务器可驻留在为原位适配系统的正确功能性提供所需要计算资源的云计算网络和/或网格计算网络和/或计算网络的另一形式中。
双声道助听器
助听器系统可包括带有两个助听器的双声道助听器系统,一个用于助听器系统用户的右耳且一个用于助听器系统用户的左耳。
因此,助听器系统可包括带有用于响应在第二麦克风接收的声音信号的第二音频输入信号的供给的第二麦克风的第二助听器,
配置成以根据第二信号处理算法处理第二音频输入信号以产生第二听觉损失补偿音频信号的第二处理器,和
用于基于第二听觉损失补偿音频信号提供第二声学输出信号的第二输出换能器。
第二助听器的电路系统优选同一于第一助听器的电路系统,不同的是这一事实:因为第二助听器通常经调整补偿与第一助听器补偿的听觉损失不同的听觉损失;通常,双声道听觉损失针对两耳不同。
原位适配系统可配置成使用处理算法的函数库来自动调整第二处理器的至少一个信号处理参数其中为信号处理算法Fn的一组信号处理参数包括控制用于实行的一个或多个算法的选择的指数参数n的值,例如,噪音压缩算法可选择用于在噪音环境中实行且可不选择用于在安静环境中实行。
在双声道助听器系统中,重要的是,第一信号处理器和第二信号处理器的信号处理算法以协同方式选择。因为声音环境特征可在用户的两耳显著地不同,将经常发生的是在用户两耳声音环境的类别的独立确定不同,且这可引起在助听器中声音的不希望的不同信号处理。因此,优选地第一处理器和第二处理器的信号处理算法基于相同信号选择,诸如在助听器系统的手持式设备接收的声音信号,或在右耳和在左耳接收的两个声音信号,或在手持式设备接收的声音信号和在左耳接收的信号及在右耳接收的信号的组合,等。
原位适配系统的工作的示例
例如,用户听力能力涉及用户理解讲话的可靠性。与用户使用的助听器系统关联的能力检测器可例如驻留在服务器中且由助听器系统的助听器接收的声音连同由用户说出的讲话可传输到驻留在服务器中的能力检测器,且能力检测器可配置成讲话识别且用于在用户助听器从另一个人接收的讲话的情况下评估用户讲话且提供反映用户讲话适配内容的程度的能力值。
例如,在正常听觉的人将会容易理解来自另一个人讲话的情况下,由助听器系统用户讲出的单词“对不起”、“原谅我”、“什么”等或者在非英语中对应的单词的频率检测指向低听力能力值。
能力检测器可依赖对给定外部讲话表征的可信响应的统计模型。例如,能力检测器可计算对给定输入的每个响应的可信度。然后,原位适配系统的能力检测器和其它部分可测量用户的响应。如果用户的响应高度可信,则然后他/她很可能理解了输入。所获得的信息也可用于适应信号处理使得可信度最大化。
能力检测器可包括用于识别由助听器系统用户所讲出单词的语音识别,以便区分用户讲话与由助听器接收的其它人的讲话。
用户的助听器系统的助听器可具有当助听器由用户佩戴在助听器工作位置时对准嘴的麦克风方向阵列以便用户讲话与其它人的讲话的空间上的区分。
助听器可具有驻留在用户耳道中的麦克风,当助听器由用户佩戴在助听器的工作位置时,所述麦克风用于接收来自用户骨传导讲话以便区分用户讲话与其它人的讲话。
通常,助听器系统的助听器可具有配置成记录用户自身语音的麦克风系统且其中能力检测器配置成基于用户的讲话和可能地来自声音环境的声音确定助听器系统用户的听力能力。
听力能力可涉及从讲话的接收起用户的响应时间且任选地至少一个服务器可配置成以确定用于具有改善的讲话可听度的至少一个增益值。
听力能力可涉及用户的讲话理解且任选地至少一个服务器可配置成以确定用于具有改善的讲话理解的信号处理参数。
为了用户能力的确定,能力检测器基于用户及其它用户的先前能力可将当前用户对讲话的响应与统计模型联系。
多个助听器系统的一个或多个助听器系统可包括到达方向检测器,配置成在包括到达方向检测器的助听器系统的一个助听器处声音到达方向的确定。优选地,到达方向确定为相对于助听器系统用户向前看方向的角度。例如,如果声音从位于助听器系统用户向前看方向的源头到达,则到达方向为零度(0°)。任选地,包括到达方向检测器的助听器系统还包括配置成助听器系统用户观看方向的确定的方位传感器。
能力检测器可配置成声音所确定到达方向与用户向前看方向的比较。
例如,能力检测器可配置成确定从声音到达直到用户朝向所确定的声音到达方向改变他或她的向前看方向的时间;例如,确定为朝向0°的声音到达方向的变化;或确定从声音到达直到朝向所确定的声音到达方向的观看方向改变的时间借助方位传感器检测。
至少一个服务器可配置成基于所述比较的包括到达方向检测器的助听器的信号处理参数值的确定,和传输信号处理参数值到带有包括达到方向检测器的助听器的助听器系统,且其中包括到达方向检测器的助听器的处理器配置成将信号处理参数调整为所接收的值,例如,在所接收讲话的频率增加增益,由此用于响应来自另一个方向的讲话的时间比向前看方向减少。
网络
助听器系统和至少一个服务器可通过带有它们各自通信接口的有线网络或无线网络传输数据到彼此且从彼此接收数据。网络的示例包括互联网、局域网(LAN)、无线LAN、广域网(WAN)和个域网(PAN),单独或以任何组合。然而,网络可包括另一个类型网络或由另一个类型网络构成。
手持式设备
多个助听器系统的至少一个助听器系统可包括手持式设备,其与助听器系统的助听器通信地耦合且配置成将助听器与至少一个服务器互连。手持式设备可经由蓝牙网络(诸如蓝牙LE网络)以在助听器领域熟知的方式例如与助听器系统的助听器通信,且手持式设备可经由在智能手机领域中熟知的互联网或其它网络例如与至少一个服务器通信。这样,助听器系统和至少一个服务器可通过手持式设备传输数据到彼此且从彼此接收数据,且助听器系统具有手持式设备的进一步通信资源和计算性能。
手持式设备可为或包括笔记本式计算机、个人数字助理(PDA)、便携式多媒体播放器(PMP)、平板计算机(PC)、GPS接收器、移动电话、智能电话,例如,例如带有GPS接收器和日历系统等的Iphone、安卓手机和windows手机等,或能够与至少一个服务器和助听器通信的任何其它便携式设备。
助听器接口
多个助听器系统的至少一个助听器系统可具有带有用于与广域网(诸如互联网)连接的接口的助听器。
多个助听器系统的至少一个助听器系统可具有通过移动受话器网络(诸如GSM、IS-95、UMTS、CDMA-2000等)访问广域网的助听器。
多个助听器系统的至少一个助听器系统可具有助听器,其包括用于在助听器和手持式设备及任选地助听器系统的其它部分(例如,包括助听器系统的另一个助听器)之间的数据和/或控制信号的传输的数据接口。
数据接口可为有线接口(例如,USB接口)或无线接口(诸如蓝牙接口,例如,蓝牙低功耗接口)。
助听器可包括用于从手持式设备及可能地其它音频信号源接收音频信号的音频接口。
音频接口可为有线接口或无线接口。数据接口和音频接口可组合到单个接口,如USB接口,蓝牙接口等。
助听器可例如具有用于在助听器和手持式设备之间传感器信号和控制信号的交换的蓝牙低功耗数据接口和用于在助听器和手持式设备之间的音频信号的交换的有线音频接口。
手持式设备接口
手持式设备具有用于与有线网络或无线网络连接的接口,通过所述有线网络或无线网络手持式设备和至少一个服务器可传输数据到彼此且从彼此接收数据。如上述,网络的示例包括互联网、局域网(LAN)、无线LAN、广域网(WAN)和个域网(PAN),单独或以任何组合。然而,网络可包括另一个类型网络或由另一个类型网络构成。
手持式设备可通过移动受话器网络(诸如,GSM、IS-95、UMTS、CDMA-2000等)访问网络。
通过网络(例如互联网),手持式设备可访问由用户用于通信和用于涉及用户的时间管理和通信信息的存储的电子时间管理和通信工具。该工具和所存储的信息通常驻留在至少一个服务器通过网络访问的遥控器上。
能力模型
至少一个服务器可基于多个助听器系统的多个用户的所确定的听力能力访问能力模型,且其中至少一个服务器配置成基于助听器系统用户的所确定听力能力和能力模型确定助听器的信号处理参数值。
能力模式可包括选自用户听力图、年龄、性别、种族和母语构成的组的至少一个用户参数使得基于模型确定的信号处理参数可针对不同用户参数值变化。
能力模型可包括听觉损失模型,例如,在EP 287 858A1中所述的听力损失模型的一个。
能力模型可包括各种声音环境类别使得基于模型确定的信号处理参数可针对不同声音环境类别变化。
至少一个服务器可配置成基于听力能力确定和任选地其它用户涉及的数据(诸如,用户听力图和/或年龄和/或性别和/或种族和/或母语等)及任选地声音环境类别形成能力模型。
能力模型可包括贝叶斯统计模型、神经网络、数据聚类、支持向量机等。
初始适配和随后的更新
当助听器第一次适配到用户时,助听器可基于原位适配系统的能力模型针对用户最大听力能力进行调整。在使用助听器一段时间(例如,一天)时,信号处理参数可通过原位适配系统的至少一个服务器响应自最新信号数理参数调整以来使用期间的能力确定及响应能力模型的可能更新(例如,响应从多个助听器系统接收的能力确定)而调整。
能力检测器
能力确定在助听器系统的正常使用期间执行。至少一个服务器可配置成基于所接收的能力确定更新能力模型。能力确定可在使用期间频繁地执行,例如每小时一次,例如每10分钟一次,例如每5分钟一次,例如每2分钟一次,例如每分钟一次。
助听器可包括助听器系统的能力检测器,或助听器的能力检测器的一部分,且在使用期间可例如每小时一次、每10分钟一次,或每5分钟一次,或每2分钟一次,或每分钟一次传输所确定能力的数据到至少一个服务器。
多个助听器系统的至少一个助听器系统可具有手持式设备,其与至少一个助听器系统的助听器互连且包括配置成助听器系统用户的听力能力的确定的助听器系统的能力检测器。
能力检测器或能力检测器的部分可驻留远离助听器系统,与至少一个服务器互连;或,形成至少一个服务器的一部分,从而从在至少一个服务器中可用的计算资源和互连网络受益。例如,至少一个服务器可包括多个助听器系统的全部能力检测器。
位置检测器
助听器可包括配置成确定助听器的地理位置的位置检测器且至少一个服务器可配置成助听器和包括助听器的助听器系统的地理位置的记录,和结合地理位置在能力模型中。
多个助听器系统的至少一个助听器系统可具有手持式设备,其与至少一个助听器系统的助听器互连且包括配置成确定助听器系统的地理位置的位置检测器,且至少一个服务器可配置成助听器系统的地理位置的记录和结合地理位置在能力模型中。
相比于在助听器中可用的有限计算资源和功率,驻留在手持式设备中的位置检测器从在手持式设备中通常可用的较大计算资源和功率供应获益。
为了确定助听器系统的地理位置和任选地助听器系统的速度,位置检测器可包括GPS接收器、日历系统、WIFI网络接口、移动网络电话接口的至少一个。
当助听器系统在建筑物内时,由GPS接收器接收的信号的信号强度显著降低,且因此关于GPS信号强度的信息可由位置检测器使用以确定助听器系统是否在建筑物内。
关于例如由GPS接收器确定的移动速度的信息可由位置检测器使用以确定助听器系统在运输车辆(诸如,在汽车中)内。
在有用的GPS信号的缺失下,位置检测器可基于助听器系统可连接的WIFI网络的邮编地址或基于从在移动电话领域中熟知的各种GSM发射器可能接收的信号通过三角测量确定助听器系统的地理位置。另外,位置检测器可配置成访问用户的日历系统以获得关于用户预期去处的信息,例如,会议室、办公室、食堂、餐厅、家等,并且从而包括这种信息在地理位置的确定中。因此,来自用户日历系统的信息可替代或补充关于通过其它方式(例如,通过GPS接收器)确定的地理位置的信息。
另外,当用户在建筑物(例如,高层建筑物)内时,GPS信号可缺失或如此微弱以致于地理位置不能通过GPS接收器确定。然后,来自日历系统关于用户去处的信息可用于提供关于地理位置的信息,或来自日历系统的信息可补充关于助听器位于的地理位置信息,例如,特定会议室的指示可提供关于在高层建筑物中哪一层的信息。关于高度的信息通常不可得自GPS接收器。
当地理位置不能另行确定,例如,当GPS接收器不能提供地理位置时,位置检测器可自动使用来自日历系统的信息。
声音环境检测器
多个助听器系统的至少一个助听器系统可具有声音环境检测器,其与所述至少一个助听器系统关联且配置成基于由各自助听器系统接收(例如,从助听器系统的一个助听器或从助听器系统的两个助听器)的声音信号的包围各自助听器系统的声音环境的确定。例如,声音环境检测器可确定包围各自助听器的声音环境的类别,诸如讲话、絮叨讲话、餐厅擦咔声、音乐、交通噪音等。
助听器系统的助听器可包括声音环境检测器;或声音环境检测器的一部分。
多个助听器系统的至少一个助听器系统可具有手持式设备,其与至少一个助听器系统的助听器互连且包括与助听器系统关联的声音环境检测器或助听器系统的声音环境检测器。相比于在助听器中可用的有限计算资源和功率,驻留在手持式设备的声音环境检测器从通常在手持式设备中可用的较大计算资源和功率供应受益。
助听器系统的声音环境检测器可配置成以传输关于所确定的声音环境的信息(例如,关于声音环境的所确定类别的信息)到至少一个服务器。
声音环境检测器或声音环境检测器的一部分可驻留远离助听器系统,与至少一个服务器互连;或形成至少一个服务器的一部分,从而从在至少一个服务器和连接网络中可用的大量计算资源中受益。例如,至少一个服务器可包括多个助听器系统的全部声音环境检测器。
至少一个服务器可配置成基于由声音环境检测器确定的助听器系统的声音环境的类别确定助听器系统的助听器的信号处理参数值,和用于信号处理参数值到助听器的传输,且其中助听器的处理器可配置成将信号处理参数调整为用于在所确定声音环境中具有改善的听力能力的所接收值。
声音环境检测器可配置成基于由助听器系统接收的声音,且任选地基于由位置检测器确定的助听器系统的所确定地理位置,且任选地基于选自数据、一天中的时间、助听器系统的速度和经GPS接收器接收的信号的信号强度构成的组的至少一个参数,来确定包围多个助听器系统的特定助听器系统的声音环境的类别。
在没有关于地理位置的信息(例如来自GPS和日历系统的)对位置检测器可用的事件中,声音环境检测器可基于所接收的声音信号以常规方式归类声音环境;或者例如先前在适配节段期间,或当状况发生时,助听器可设置成以用户选择的模式操作。
例如,由于交通、人数等的重复变化,在特定地理位置(诸如城市广场)的声音环境年复一年以类似方式在每年中和/或日复一日以类似方式在一天中以重复方式改变,且此类变化可通过允许声音环境检测器在确定声音的类别中将所述数据和/或一天中时间包括在内而加以考虑。
所获得的分类结果可在助听器中利用以自动选择助听器的信号处理特征,例如,自动切换到用于讨论中环境类别的最合适信号处理算法和参数。此类助听器将能够为个体助听器用户在声音环境的各种类别中自动保持最佳声音质量和/或讲话可理解性。
对于带有双声道助听器的助听器系统,声音环境检测器可配置成基于在两个助听器均接收的声音信号和任选地助听器系统的地理位置确定包围助听器系统的用户的声音环境的类别。
助听器系统可配置成将信号处理参数连同GPS数据传输到至少一个服务器以便并入在能力模型中,例如以便在各种地理位置的助听器信号处理参数值与其它助听器系统用户的分享。
因此,助听器系统可配置成例如基于听觉曲线相似性和/或年龄和/或种族和/或耳朵尺寸等及能力模型在当前地理位置从至少一个服务器检索助听器信号处理参数值。
用户接口
助听器系统的至少一个可具有包括用户接口的助听器,所述用户接口允许包括助听器的助听器系统的用户作出至少一个信号处理参数的调整。
多个助听器系统的至少一个助听器系统可具有手持式设备,其与至少一个助听器系统的助听器互连且包括允许包括助听器的助听器系统的用户作出至少一个信号处理参数的调整的用户接口。相比于在助听器中可用的有限计算资源和功率,驻留在手持式设备中的用户接口从在手持式设备中通常可用的较大计算资源和功率供应中受益。
用户可不满足于由至少一个服务器执行的参数值的自动选择且可使用用户接口执行信号处理参数的调整,例如,用户可将信号处理算法的当前选择改变为另一个信号处理算法,例如,用户可从方向性信号处理算法切换到全方位信号处理算法;或用户可调整参数值,例如,容积。
原位适配系统可配置成在信号处理参数值的确定中用户调整的结合,例如至少一个服务器可配置成记录由助听器系统的用户作出的至少一个信号处理参数的调整,且结合所述调整在能力模型中。
原位适配系统的至少一个服务器可配置成记录由助听器系统的用户作出的调整,且响应所记录调整基于学习的算法(例如,贝叶斯增量偏好启发)修改至少一个信号处理参数的θ的自动调整,使得下次相同听力条件(例如,相同声音环境)被检测到时,执行经修改的自动调整。
对于关于贝叶斯的原理和贝叶斯推理的更多信息,参考David J.C.Mackay的“信息理论、推理和学习的算法”,剑桥大学出版社,2003年(“Information Theory,Inference,and Learning Algorithms”,Cambridge University Press,2003)。
这样,原位适配系统使得可有效地学习在涉及各种听力条件的信号处理参数的所需调整和个性化、随时间变化的、非线性和随机的校正性用户调整之间的复杂关系。
能力模型的形成和/或调整可包括贝叶斯机器学习和/或神经网络和/或数据聚类等。
助听器的类型
助听器可为配置成成头部配戴的且连同头部偏移位置和方位的任何类型,诸如BTE、RIE、ITE、ITC、CIC等助听器。
GPS
贯穿本公开,术语GPS接收器用于指代任何卫星导航系统的卫星信号的接收器,所述卫星导航系统提供在地球上或近于地球的任何地方的位置信息和时间信息,诸如由美国政府维持且任何人借助GPS接收器可自由访问且通常指代“GPS系统”的卫星导航系统,俄罗斯的全球导航卫星系统(GLONASS),欧盟伽利略导航系统,中国北斗导航系统,印度区域导航20卫星系统等,且还包括扩增的GPS,诸如StarFire、Omnistar、印度GPS型静地轨道增强导航(GAGAN)、欧洲地球静止导航重叠服务(EGNOS)、日本多功能卫星增强系统(MSAS)等。在增强的GPS中,地基参考站的网络测量GPS卫星信号的细微变化,校正消息发送到播送校正消息返回地球的GPS系统卫星,其中增强的可GPS定位的接收器使用校正同时计算它们位置以改善精度。国际民航组织(ICAO)称这类系统为卫星型增强系统(SBAS)。
方位传感器
助听器还可包括一个或多个方位传感器,诸如陀螺仪(例如MEMS回转仪)、倾斜传感器、滚珠开关等,所述方位传感器配置成输出用于佩戴助听器的用户的头部的方位的确定的信号,例如,一次或多次头部偏转、头部前倾、头部转动或它们的组合,例如斜倾或倾斜。
日历系统
贯穿本公开,日历系统为给用户提供带有通过网络(诸如互联网)可访问的数据的日历的电子版本的系统。熟知的日历系统包括,例如,摩斯拉太阳鸟(Mozilla Sunbird)、Windows实况日历、谷歌日历、带有交换服务器的微软Outlook等。
倾斜
贯穿本公开,单词“倾斜”表示当用户站立或坐下时从头部正常竖直位置的角度偏离。因此,在站立或坐下的人的头部的静止位置中,倾斜为0°,而在仰面躺下的人的头部的静止位置中,倾斜为90°。信号处理函数库和参数
信号处理算法可包括在信号处理算法中每个执行特定子任务的多个子算法或子程式。例如,信号处理算法可包括不同信号处理子程式,诸如选频滤波、单个或多通道压缩、自适应反馈消除、讲话检测和降噪等。
而且,信号处理算法、子算法或子程式的若干区别选择可集合在一起以形成用户能够根据他或她的偏好在其间选择的两个、三个、四个、五个或更多不同预置听力程序。
信号处理算法将具有一个或若干涉及的算法参数。这些算法参数可通常划分成许多较小参数组,其中每个此类算法参数组涉及信号处理算法的特定部分或特定子程式。这些参数组控制它们各自算法或子程式的某些特征,诸如滤波器的转角频率和斜率、压缩器算法的压缩阈值和比率、滤波器系数,包括自适应滤波器系数,自适应反馈消除算法的自适应速率和探测信号特征等。
算法参数的值优选地在各自信号处理算法或子程式的实行期间立即地存储在处理工具的非易失数据存储器区,诸如数据RAM区。算法参数的初始值存储在非易失存储器区(诸如EEPROM/闪速存储器区或有后备电池的RAM存储器区)以允许这些算法参数在功率供应中断(通常由用户的助听器电池的移除或替换或者“打开/关闭”开关的操纵而导致)期间保留。
信号处理实施
在新助听器系统中信号处理可通过专用硬件执行或在信号处理器中执行,或在专用硬件和一个或多个信号处理器的组合中执行。
如本文所用,术语“处理器”、“信号处理器”、“控制器”、“系统”等意指在实行中涉及CPU的实体,或是硬件、硬件及软件的组合、或是软件。
例如,“处理器”、“信号处理器”、“控制器”、“系统”等可为但不限于在处理器上运行的进程、处理器、对象、可执行文件、实行线程和/或程序。
举例来说,术语“处理器”、“信号处理器”、“控制器”、“系统”等指代在处理器和硬件处理器这两者上运行的应用程序。一个或多个“处理器”、“信号处理器”、“控制器”、“系统”等或任何它们的组合可驻留在实行处理和/或线程中,且一个或多个“处理器”、“信号处理器”、“控制器”、“系统”等或任何它们的组合可位于一个硬件处理器上,与其它硬件电路系统的组合也是可能的,和/或分布在两个或多个硬件处理器之间,与其它硬件电路系统的组合也是可能的。
另外,处理器(或类似术语)可为能够执行信号处理的任何组件或者任何组件的组合。例如,信号处理器可为ASIC处理器,FPGA处理器、通用处理器、微处理器、电路组件或集成电路。
附图说明
附图展示实施例的设计和实用性,其中相同元件由共同的参考号指示。这些附图不必要成比例绘制。为了更好理解上述和其它优点及对象是如何获得的,将提出实施例的更具体说明,其在附图中展示。这些附图仅描绘典型实施例且因此不应认为限制其范围。
图1示意性地示出原位适配系统,
图2示意性地展示原位适配系统的助听器系统的助听器,
图3示意性地展示用于原位适配系统的助听器系统的助听器的初始适配的适配系统,以及
图4示出助听器系统,其具有带有方位传感器的单个助听器和带有GPS接收器、声音环境检测器及用户接口的手持设备。
具体实施方式
各种示例性实施例参考附图在下文进行描述。应当注意,附图未按比例绘制且贯穿附图相同结构或功能由同样的参考号表示。另外应当注意,附图仅旨在有利于实施例的描述。附图非旨在作为所要求发明的详尽性描述或作为对所要求发明的范围的限制。此外,所展示实施例不需要具有所展示的全部方面或优点。连同特定实施例描述的方面或优点不必要限制该实施例且可在即使未展示或未如此明确描述的任何其它实施例中实践。
现将参考附图在下文更完整地描述原位适配系统,其中示出各种类型原位适配系统。原位适配系统可以未在附图中示出的不同形式实施且不应理解为限制如本文所述的实施例和示例。
图1
图1示意性展示原位适配系统100,配置成在助听器系统的正常使用期间(即在助听器系统由它们各自用户佩戴时)调整多个助听器系统的信号处理参数从而提供听觉损失补偿声音信号给用户。
原位适配系统100包括多个助听器系统10,所述助听器系统10的每个由多个用户(用户A、用户B,…,用户N)的各自一个佩戴,且所述助听器系统10的每个包括带有第一助听器12A和第二助听器12B的双声道助听器系统10,所述第一助听器12A执行用户一个耳朵的听觉损失补偿,所述第二助听器12B执行用户另一个耳朵的听觉损失补偿。形成原位适配系统100一部分的助听器系统10的一些可具有单个单声道助听器12(未示出)。
助听器系统10的每个还包括手持式设备30,其给助听器系统10提供用于助听器系统10的助听器12A、助听器12B通过一个或多个网络120与一个或多个服务器110互连的网络接口。
服务器110通过在计算机网络领域(诸如在云计算、网格计算领域等中)中熟知的一个或多个网络120互连。
服务器110互连且配置成为了包括助听器的助听器系统10的用户的具有改善的听力能力确定通过一个或多个网络120与服务器110互连的助听器12A、助听器12B的信号处理参数值。
用户的助听器系统10的助听器12A、助听器12B的信号处理参数值的确定基于用户的所确定听力能力。助听器系统10的能力检测器(未示出)配置成确定用户的听力能力。能力检测器可驻留在助听器系统10的助听器12A、助听器12B的一个中,或在手持式设备30中,或在服务器110的一个中,或者能力检测器的部分可驻留在助听器系统10的助听器12A、助听器12B和手持式设备30和一个或多个服务器110的一个或多个中。能力检测器传输关于用户的所确定听力能力的信息到一个或多个服务器110且一个或多个服务器基于传输的信息确定一个或多个助听器系统10的一个或两个助听器12A、助听器12B的一个或多个处理参数值。为了获得助听器(其接受所确定的信号处理参数值并调整信号处理参数为所接收的值)的用户的具有改善的听力能力,一个或多个服务器110通过一个或多个网络110传输所确定的一个或多个信号处理参数值到各自助听器。
在展示的原位适配系统100中,服务器110的至少一个基于多个助听器系统的多个用户的所确定听力能力访问统计能力模型(未示出),且至少一个服务器110配置成基于助听器系统10的用户的所确定听力能力和能力模型确定助听器12A、助听器12B的信号处理参数值。
能力模型可包括从由用户听力图、年龄、性别、种族、高度和母语构成的组中选择的至少一个用户参数。
能力模型可包括听觉损失模型,例如,在EP 2871 858A1中所述的听觉损失模型的一个。
能力模型可包括各种声音环境类别使得基于模型确定的信号处理参数可针对不同声音环境类别变化。
展示的原位适配系统100具有声音环境检测器,配置成基于由各自个体助听器系统10接收的声音信号(例如,来自各自助听器系统10的一个助听器12A、助听器12B;或来自各自助听器系统10的两个助听器12A、12B)确定包围个体助听器系统10的声音环境。例如,声音环境检测器可确定包围各自助听器的声音环境的类别,诸如讲话、絮叨讲话、餐厅擦咔声、音乐、交通噪音等。
助听器系统10的助听器12A、助听器12B可包括配置成包围讨论中的助听器12A、助听器12B的声音环境的确定的声音环境检测器的部分。
多个助听器系统的至少一个助听器系统10可具有手持式设备30,其与至少一个助听器系统10的助听器12A、助听器12B互连且包括配置成确定包围讨论中的助听器12A、助听器12B的声音环境的声音环境检测器的部分。相比于在助听器12A、助听器12B中可用的有限计算资源和功率,驻留在手持式设备30的声音环境检测器的部分从通常在手持式设备30中可用的较大计算资源和功率供应中受益。
驻留在助听器系统10的声音环境检测器的一部分可配置成传输关于所确定的声音环境的信息(例如,关于声音环境的所确定类别的信息)到至少一个服务器110。
声音环境检测器或声音环境检测器的一部分可驻留远离助听器系统10,与至少一个服务器110互连;或,形成至少一个服务器110的部分,从而从在至少一个服务器110和互连网络120中可用的大量计算资源受益。例如,至少一个服务器110可包括原位适配系统100的声音环境检测器的全部部分。
至少一个服务器110可配置成基于由声音环境检测器确定的助听器系统10的声音环境的类别确定助听器系统10的助听器12A、助听器12B的信号处理参数值,和用于传输信号处理参数值到助听器12A、助听器12B,且为了在确定的声音环境中具有改善的助听器系统10的用户的听力能力,助听器12A、助听器12B的处理器可配置成调整信号处理参数为所接收的值。
至少一个服务器可配置成基于听力能力确定和任选地其它用户涉及的数据(诸如听力图和/或年龄和/或性别和/或种族和/或高度和/或母语等)及任选地声音环境类别形成能力模型。
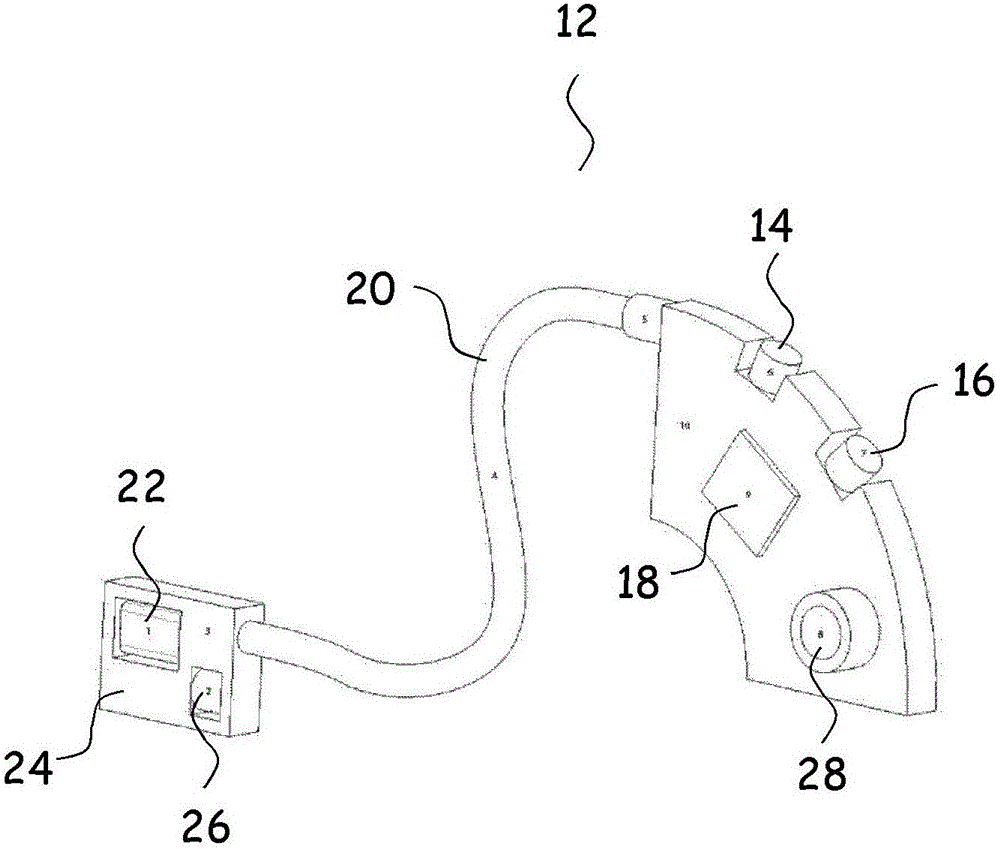
图2
图2示意性地展示将在用户的耳廓200后佩戴的包括BTE助听器外壳(未示出——外壁已经移除以使得内部部分可见)的BTE助听器12。BTE外壳(未示出)容纳用于转换声音信号为麦克风音频声音信号的前麦克风14和后麦克风16,用于滤波各自麦克风音频声音信号的可选预滤波器(未示出),用于转换各自麦克风音频声音信号为各自数字麦克风音频声音信号(其输入到配置成以基于输入的数字音频声音信号产生听觉损失补偿输出信号的信号处理器18)的A/D转换器(未示出)。
听觉损失补偿输出信号通过包含在声音信号传输构件20中的电线传输到用于转换听觉损失补偿输出信号为用于朝向用户的耳膜传输的声学输出信号及包含在耳机24中的接收器22,所述耳机24成形用于(未示出)舒适地定位在用户的耳道中以使声音信号传输构件紧固和保留在用户耳道中其预定位置中,如在BTE助听器领域中熟知的。
耳机24也夹持一个麦克风26,当耳机定位在用户耳道中耳机预定位置时所述麦克风26定位用于耳道壁的邻接,以便利用语音到麦克风26的骨传导接收用户自身语音。麦克风26连接到A/D转换器(未示出)和可选的在BTE外壳12中的预滤波器(未示出),互连电线(不可见)容纳在声音传输构件20中。
BTE助听器12由电池28供电。
信号处理器18配置成实行存储在连接至信号处理器18的非易失存储器(未示出)中的信号处理算法的函数库的许多不同信号处理算法。每个信号处理算法或它们的组合调控为特定用户偏好和声音环境特定类别。为一组信号处理算法Fn的信号处理参数
各种信号处理算法的信号处理参数的初始设置通常在药剂师办公室中在初始适配节段期间确定且通过激活所需算法和设置算法参数在助听器的非易失存储器区中和/或传输所需算法和算法参数设置到非易失存储器区而编程到助听器中。随后,在图1中示出的原位适配系统配置成借助信号处理算法的函数库在助听器12中自动调整的至少一个信号处理参数
信号处理器18的各种功能在上面公开且在下面详细公开。
图3
图3示出在用户耳朵后(即,在耳廓200后)带有BTE外壳60的在其工作位置中的助听器12。如所示,助听器12可具有臂64,其为柔性的且预定定位于耳廓200内,例如围绕在耳屏及对耳屏后的耳甲隆起的圆周且邻近对耳轮且至少部分地由用于保留耳机24在用户外耳内的耳机24预定位置的对耳轮覆盖。为了容易适配臂到在耳廓200中臂的预定位置中,臂在制造期间可预形成,优选地成带有比对耳轮曲率稍大的曲率的弓形形状。耳机25也可容纳用于进来声音的接收及对应输出信号的供给的定位在耳道入口的麦克风,所述对应输出信号可与来自容纳在BTE外壳60中的一个或多个麦克风的输出信号结合。
图3另外原理性地展示适配仪器70及其与网络120(诸如网络120)的无线互连,和原位适配系统100的形成部分。
涉及助听器12的硬件和/或软件构造的数据可无线地传输至适配仪器70,例如显示在适配仪器70的显示器上以便适配仪器70的操作者核实,及在助听器的构造不同于预定情况时的事件中可能的校正动作。
适配仪器70配置成根据从原位适配系统100的一个或多个服务器接收的信息(例如,基于能力模型的最新更新的适配参数新值)执行助听器12的初始适配。由此,适配仪器70鉴于所接收的信息(诸如听力图,年龄、类似用户的能力等)选择最大化用户的预测听力能力的参数。
图4
图4示意性地展示助听器系统10的组件和电路系统,所述助听器系统10形成在图1中示出的原位适配系统100的部分且具有带有方位传感器44的第一助听器12A(例如,用于左耳的)、第二助听器12B(例如,用于右耳),和带有GPS接收器42、声音环境检测器34及用户接口38的手持式设备30。
助听器12A、助听器12B可为任何类型的助听器,诸如BTE、RIE、ITC、CIC等助听器。
展示的助听器12A、助听器12B的每个包括连接到各自A/D转换器(未示出)的前麦克风14和后麦克风16,所述A/D转换器用于响应在包围助听器系统10的用户的声音环境中在麦克风14、麦克风16接收的声音信号的各自数字输入信号的供给。数字输入信号输入到听觉损失处理器18,其配置成以根据从信号处理算法的函数库选择的信号处理算法处理数字输入信号以产生听觉损失补偿输出信号。听觉损失补偿输出信号按路线发送到用于转换听觉损失补偿输出信号为朝向用户耳膜发射的声学输出信号的D/A转换器(未示出)和接收器22。
助听器系统10还包括手持式设备30,例如智能电话,有利于在助听器12A、助听器12B和原位适配系统100的至少一个服务器110之间的数据传输。所展示的助听器12A、助听器12B与手持式设备30借助例如用于在助听器12和手持式设备30之间传感器数据和控制信号交换的蓝牙低功耗接口互连。所展示的手持式设备30为还具有用于与移动受话器网络连接的移动受话器50接口(诸如GSM接口)以及在智能电话领域中熟知的WIFI接口48的智能电话。手持式设备30通过网络借助WIFI接口48和/或在WAN领域中熟知的移动受话器接口50与网络120及至少一个服务器110互连。
助听器12A包括用于用户听力能力的确定的能力检测器40。能力检测器40连接到定位用于接受用户自身讲话的麦克风26,例如,如在图2中所示与耳道壁邻近以便接受用户的骨传导讲话。能力检测器40也连接到一个或多个方位传感器44,诸如陀螺仪(例如MEMS回转仪)、倾斜传感器、滚珠开关等,所示方位传感器44配置成输出用于确定佩戴助听器的用户的头部的方位的信号,例如一次或多次头部偏转、头部前倾、头部转动或它们的组合,例如斜倾,即当用户站立或者坐下时,从头部正常竖直位置偏离的角度。例如在静止位置中,站立或坐下的人的头部的斜倾为0°,且在静止位置中,躺着的人的头部的斜倾为90°。
能力检测器40配置成讲话的检测及由用户说出的单词的识别且指示用户在理解来自其它人的讲话的困难度,诸如“对不起”、“原谅我”、“什么”等或者在非英语的其它语言中对应单词。在来自另一个人的被正常听觉的人容易理解的讲话情况下,由助听器系统用户说出的此类单词的频率检测,指向低听力能力值。能力检测器40配置成传输涉及此类单词的检测的数据和关于响应接收讲话的用户计时的数据到至少一个服务器,且至少一个服务器基于接收的数据及能力模型确定用于用户具有改善的听力能力的一个或多个信号处理参数,由此,可能带有与讨论中用户的听觉损失类似的听觉损失的助听器系统其它用户的所获得的听力能力包括在讨论中用户的助听器的信号处理参数的确定中。
能力检测器包括到达方向检测器,配置成在助听器12的声音到达方向的确定。
能力检测器配置成比较声音到达所确定的方向和从讲话到达直到用户朝向由方位传感器44指示的所确定讲话到达的方向改变他或她的观看方向的时间。能力检测器40配置成传输涉及响应讲话的接收的确定的用户反应时间或用户反应的缺失的数据到至少一个服务器且至少一个服务器基于所接收数据和能力模型确定用于用户的具有改善的听力能力的一个或多个信号处理参数,由此,可能带有与讨论中用户的听觉损失类似的听觉损失的助听器系统其它用户的所获得的听力能力包括在讨论中用户的助听器的信号处理参数的确定中。至少一个服务器可例如增加在所接收讲话的频率的增益使得用于对来自非观看方向的其它方向的讲话的反应的时间减少。例如为了执行滤波,至少一个服务器也可调整复杂增益值。
手持式设备30包括声音环境检测器34,其用于确定包围助听器系统10用户的声音环境的类别。声音环境类别的确定基于由手持式设备中麦克风32采样的声音信号。基于类别的确定,声音环境检测器34提供输出36到至少一个服务器以便确定适用于讨论中声音环境类别的信号处理参数值和/或信号处理算法。
因此,原位适配系统自动将助听器信号处理器18切换到用于讨论中声音环境的最适合的一个或多个算法,由此最佳声音质量和/或讲话可理解性在各种声音环境中保持。处理器18的信号处理算法可执行各种形式的降噪和动态范围压缩以及一系列其它信号处理任务。
声音环境检测器34从通常在手持式设备30中可用的计算资源和功率供应中受益,所述计算资源和功率供应比在助听器12中可用的资源和功率供应大。手持式设备30和/或助听器系统10的全部或至少一些也可从由网络120和至少一个服务器110使得可用的资源中受益。
声音环境检测器34将当前声音环境归类到一组环境类别中,诸如,讲话、絮叨讲话、餐厅擦咔声、音乐、交通噪音等。
至少一个服务器传输服务器参数控制信号52A、服务器参数控制信号52B到助听器12A、助听器12B的每个,关于确定的一个或多个信号处理参数和/或信号处理算法的信息将由各自信号处理器18A、18B响应服务器参数控制信号52A、服务器参数控制信号52B从信号处理算法和参数的可用函数库中选择。信号处理参数的示例包括:降噪量、增益量和HF增益量、控制对应信号算法是否选择用于实行的算法控制参数、滤波器的转角频率和斜率、压缩器算法的压缩阈值和比率、滤波器系数,包括自适应滤波器系数,自适应反馈消除算法的自适应速率和探测信号特征等。
手持式设备30包括带有配置成确定助听器系统10的地理位置的GPS接收器的位置检测器42。在有用的GPS信号缺失下,所展示的助听器系统10的位置可确定为WIFI网络访问点的地址或基于从智能电话领域中熟知的各种GSM发射器接收的信号通过三角测量确定。
手持式设备30配置成通过WIFI接口48和/或移动受话器接口50传输所确定的声音环境类别和地理位置到至少一个服务器。至少一个服务器配置成记录地理位置以及在各自地理位置的声音环境的确定类别。记录可在有规律的时间区段和/或在各记录之间有某些地理距离和/或由某些事件触发(例如,声音环境类别的偏移,信号处理的改变,诸如信号处理程序的改变,信号处理参数的改变,借助用户接口进入的用户命令等)而执行。记录的数据包括在能力模型中。
当助听器系统10位于带有特定类别声音环境记录的地理位置区域内时,至少一个服务器配置成增加当前声音环境为声音环境的各自先前记录的类别的可能性。
手持式设备30也配置成例如通过WiFi接口48和/或移动受话器接口50访问用户的日历系统以获得关于用户去处的信息,例如,会议室、办公室、食堂、餐厅、家等,并且包括这些信息在声音环境类别的确定中。来自用户日历系统的信息可替代或补充关于由GPS接收器确定并传输到至少一个服务器的地理位置的信息。
另外,当用户在建筑物(例如高层建筑物)内时,GPS信号可缺失或如此微弱使得地理位置不能由GPS接收器确定。来自日历系统关于用户去处的信息然后可用于提供关于地理位置的信息,或来自日历系统的信息可补充关于地理位置的信息,例如特定会议室的指示可提供关于在高层建筑物中楼层的信息。关于高度的信息通常在GPS接收器上不可用。
关于用户头部的方位的信息也传输到至少一个服务器以包括在能力模型中且形成用于助听器12的信号处理参数和/或算法的确定的基础。
虽然已经示出和描述具体实施例,但应理解它们不旨在限制所要求的发明,且对本领域技术人员显而易见的是在不偏离所要求发明的精神和范围可作出各种改变和修改。因此,说明书和附图应认为是例示性的而非限定性意涵。要求的发明旨在涵盖替代、修改和等同物。
- 还没有人留言评论。精彩留言会获得点赞!