一种基于CUDA的ProResVLC编码的制作方法
本发明涉及一种基于cuda的proresvlc编码。
背景技术:
prores是apple定义的一种视频压缩标准。在prores标准中,一个slice包含8个16×16宏块(macroblock,以下简称mb),每个mb分为4个8×8的块,这样一个slice共有32个8×8的块。
vlc编码(变长编码variablelengthcoding)主要指对8×8块的dct系数进行编码。
不同于其他的视频压缩标准,prores对dct系数进行编码并不是以8×8块的顺序进行的,而是如图1中的encodeslice(id×)流程图所示,先编码所有8×8块的dc系数,再编码所有块的第一个ac系数,然后是所有块的第二个ac系数,以此类推,ac系数编码需要计算当前非零ac系数和前一个非零ac系数之间的值为0的系数个数。
这种编码方式意味着在一个slice内部所有dct系数编码具有较强的相关性。因此通常情况下会采用如图1所示的slice并行方式进行cuda(由nvidia推出的并行计算架构)实现。
然而这个方式的并行度并不高。例如对于一个1920×1080的视频序列,每帧共有1020个slice,这意味着采用前述的slice并行算法最多就只能有1020个线程并行。而对于一块高端gpu,最多可并行处理16384线程,则gpu利用率只有6.25%,而且每个线程的运算量大,需要编码8×8×32=2048个系数。
技术实现要素:
本发明的目的在于克服现有技术中的不足而提供一种基于cuda的proresvlc编码。
为实现上述目的,一方面,本发明提供的一种基于cuda的proresvlc编码,对8×8块的dct系数进行编码,每32个线程编码一个slice的所有8×8块,每一个线程编码一个8×8块的两个dct系数。
优选地,每一个线程编码一个8×8块的一个dc系数和一个ac系数,或每一个线程编码一个8×8块的两个ac系数。
优选地,具体算法步骤包括:
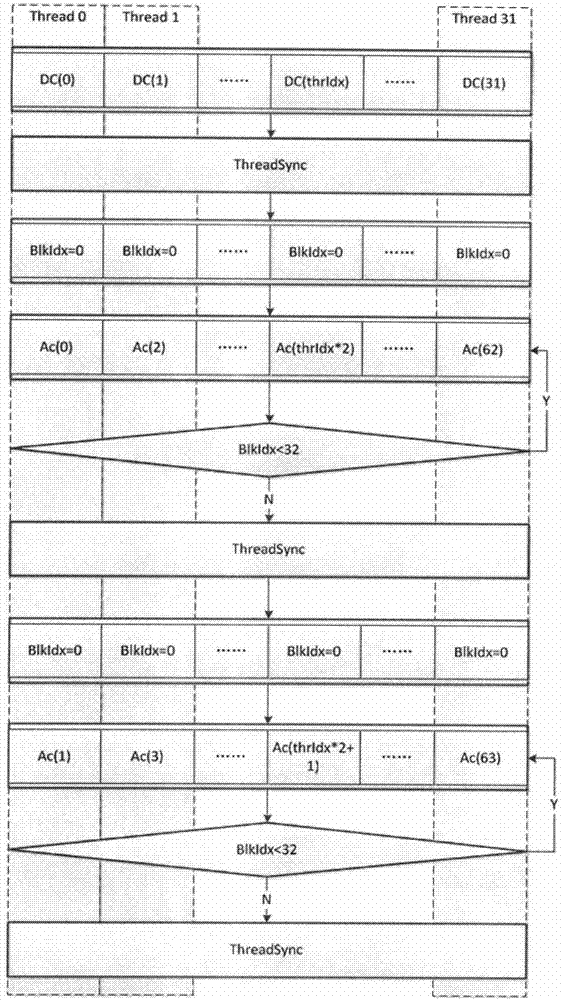
在一个slice中,一个线程独立编码一个8×8块的dc系数,在一个slice中包含32个8×8块,共采用32个线程;
32个线程同步处理;
第thridx个线程,当thridx大于0时编码所有8×8块的第2×thridx个ac系数;
32个线程同步处理;
第thridx个线程编码所有8×8块的第2×thridx+1个ac系数;
32个线程同步处理;
第thridx个线程编码第thridx+1线程的前两个非零系数。
根据本发明提供的一种基于cuda的proresvlc编码,对原有算法进行了分解,采用系数级并行优化方式,每32个线程处理一个slice的算法,每个线程编码两个dct系数,对于一个1920×1080视频序列而言,需要1020×32=32640个线程并行,对于一块高端gpu而言,远大于其能够并行的线程数,使得gpu可以满负载运行,从而提高了vlc编码的速度。
附图说明
图1是现有的以prores标准对dct系数进行编码的编码流程示意图;
图2是本发明一实施例的一种基于cuda的proresvlc编码的编码流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
请参阅图2,本发明一实施例提供了一种基于cuda的proresvlc编码,对8×8块的dct系数进行编码,每32个线程编码一个slice的所有8×8块,每一个线程编码一个8×8块的两个dct系数。
其中,每一个线程编码一个8×8块的一个dc系数和一个ac系数,或每一个线程编码一个8×8块的两个ac系数。
具体地,本实施例的算法对原有算法进行分解,采用系数级并行优化方式处理,具体包括如下步骤:
步骤1:由于dc系数之间没有相关性,因此可以单独编码,在一个slice中,一个线程独立编码一个8×8块的dc系数,在一个slice中包含32个8×8块,共采用32个线程;
步骤2:32个线程同步处理;
步骤3:第thridx个线程,当thridx大于0时编码所有8×8块的第2×thridx个ac系数,在这一步中,前两个非零系数编码时由于需要用到之前系数的信息,暂时不编码,其他系数可正常编码;
步骤4:32个线程同步处理;
步骤5:第thridx个线程编码所有8×8块的第2×thridx+1个ac系数;
步骤6:32个线程同步处理;
步骤7:第thridx个线程编码第thridx+1线程的前两个非零系数,即步骤3留下来的前两个ac系数。
本发明提供的这种基于cuda的proresvlc编码,对原有算法进行了分解,采用系数级并行优化方式,每32个线程处理一个slice的算法,每个线程编码两个dct系数,对于一个1920×1080视频序列而言,需要1020×32=32640个线程并行,对于一块高端gpu而言,远大于其能够并行的线程数,使得gpu可以满负载运行,从而提高了vlc编码的速度。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!