一种基于全站扫描的网站安全监测方法与流程
本发明属于计算机网络安全技术领域,具体的涉及一种基于全站扫描的网站安全监测方法。
背景技术:
随着我国国民经济和社会信息化进程的全面加快,互联网已经成为人们工作和生活不可或缺的部分。越来越多的政府机关、银行、企事业等单位为了适应社会的发展,树立自身良好的形象,扩大社会影响,提升工作效率,均建立起自己的门户网站。然而,由于网站是处于互联网这样一个相对开放的环境中,各类网页应用系统的复杂性和多样性导致系统漏洞层出不穷,病毒木马和恶意代码网上肆虐,黑客入侵和篡改网站的安全事件时有发生,甚至有的篡改网站的事件直接升级成政治事件,严重危及国家安全和人民利益。
传统网站安全防护技术已经不能满足目前安全需求,事前发现问题也显得越来越重要,因此,亟需一种能够高效准确、合理地对网站安全性进行监测的方法。
技术实现要素:
本发明针对现有技术存在由于网站是处于互联网这样一个相对开放的环境中,各类网页应用系统的复杂性和多样性导致系统漏洞层出不穷,病毒木马和恶意代码网上肆虐,黑客入侵和篡改网站的安全事件时有发生,甚至有的篡改网站的事件直接升级成政治事件,严重危及国家安全和人民利益等问题,提出一种基于全站扫描的网站安全监测方法。
本发明的技术方案是:一种基于全站扫描的网站安全监测方法,包括任务调度模块、内存管理模块、DNS缓存模块、WEB网页异步下载模块和内容识别检测模块,包括以下步骤:
步骤一:从监测任务表中取出要检测的任务网站属性,包括url地址、调度频率;
步骤二:根据url中,利用DNS缓存技术,取出url对应的网络地址;
步骤三:构造HTTP请求,向服务建立连接,并发送请求,获取其状态;
步骤四:如果状态存在异常,则进行报警;
步骤五:向服务器构造HTTP请求,并下载网页页面;
步骤六:利用网页快速分析算法,对网页内容进行分析,并过滤掉不必要的标签和内容;
步骤七:利用内容编码识别算法,对网页内容进行编码识别,并对网页内容进行转码;
步骤八:利用中英文分词识别算法,对转码后的内容进行中文分词;
步骤九:对于网页分析结果,利用暗链识别技术,对网页中存在的超链接进行分析,如果是暗链,则进行报警;
步骤十:对于网页内容,利用错别字识别技术,对网页中的内容进行分析,如果存在错别字,则进行报警。
所述的基于全站扫描的网站安全监测方法,所述网页快速分析算法的步骤为:
步骤201:查看当前字符,如果该字符属于空格或者换行符,则跳过这些字符;
步骤202:如果是转义字符,则跳过这些转义字符;
步骤203:如果不是’<’符号,则将其当做正文存入,否则转到第四步;
步骤204:如果是注释,则跳过所有注释,否则转到步骤205步;
步骤205:如果是a、link、base、frame、iframe、title、meta、img、style标签的任意一种,则对其标签的属性进行分析,如果是a标签,则采用Sunday算法取出a标签之间的内容;
步骤206:直接跳过其它标签;
步骤207:如果已经到文件结尾,则退出,否则回到步骤201。
所述的基于全站扫描的网站安全监测方法,所述编码识别算法的具体步骤为:
步骤301:获取http回应头中的编码;
步骤302:获取html页面的编码;
步骤303:如果在步骤301和步骤302中获取的编码任意一个为空,则取非空的编码集;如果两者不同,则转至第五步;
步骤304:根据非空的编码集,对html已经获取到的内容做转码,如果转码成功,则结束否,则转至步骤305;
步骤305:清空编码集,并调用自编写的python编码判断模块接口对该网页内容进行判断,获取该内容的编码,并转至步骤304,如果失败,则编码识别不成功。
所述的基于全站扫描的网站安全监测方法,所述中英文分词算法的具体步骤为:
步骤401:从要分词的字符串最右边匹配过的位置开始,判断第一个字的长度(utf-8编码);
步骤402:如果该字符是英文字符或者asscii字符,则表明该字符串将是一个英文单词;否则转到步骤404;
步骤403:如果前面已经有识别的英文字符,并且该字符是空格或者非ascii字符,则视为本次英文单词的结束,否则继续向后匹配;
步骤404:从本字节开始向后回退一个字的长度,作为一个汉字,同时在词库中匹配以前已经匹配成功的长度,如果匹配成功,则继续向后回退,如果有未识别的字符,则将未识别的字符串放入到词语队列,否则视为不匹配,转向步骤405;
步骤406:如果匹配不成功,如果之前有英文字符,则视为该英文字符已经结束;同时将该字加入未识别字符队列;并将已识别的词语放入到分词队列中;
步骤407:更改分词位置,如果已到开头,则此次分词结束,否则转到步骤401。
所述的基于全站扫描的网站安全监测方法,所述DNS缓存技术的过程主要为:将域名进行hash计算,并在hash链表中查找是否存在,如果存在,是否DNS解析失败或者该DNS地址已经过期,如果是的话,则对该域名进行解析,并将解析后的地址放入到hash链表中去;否则直接取出该域名的Internet地址。
所述的基于全站扫描的网站安全监测方法,所述任务调度模块,用于对状态检测和内容检测进行任务调度,以便于网站监测在特定的周期内能够完成。
所述的基于全站扫描的网站安全监测方法,所述内存管理模块,对于所有的url扫描任务所需要的内存进行提前分配和序列化,以便于内存的快速申请和统一管理。
所述的基于全站扫描的网站安全监测方法,所述DNS缓存模块,对于要请求的url进行DNS地址缓存,提高其解析速度。
所述的基于全站扫描的网站安全监测方法,所述WEB网页异步下载模块,对于各种不同传输方式的网页进行快速下载。
所述的基于全站扫描的网站安全监测方法,所述内容识别检测模块,主要包括网页内容编码识别、中英文分词、暗链识别、错别字识别和敏感词识别。
本发明的有益效果是:1 、本发明采用程序在启动时,会根据本机IP地址和计算能力去任务总调度节点获取的要监测的站点范围;同时获取每个站点的检测频率。程序启动之后,根据每个站点的检测频率设置超时时间,如果当前时间大于超时时间,则开始进行任务调度。为了加快网站DNS解析速度,我们实现了自己的DNS解析系统。主要实现方式是,首先将域名进行hash计算,并在hash链表中查找是否存在,如果存在,是否DNS解析失败或者该DNS地址已经过期,如果是的话,则对该域名进行解析,并将解析后的地址放入到hash链表中去;否则直接取出该域名的Internet地址;加快了DNS的解析速度。
2、本发明采用异步下载技术,充分利用计算机资源,在操作系统最大打开文件数的情况下,保持每台服务器日监测5000站点的监测能力。快速的html分析技术。一般的html分析一般是通过分析所有标签建立dom树,既浪费内存又耗费计算资源,而我们的实现方式是,采用快速的标签匹配技术,过滤掉不需要分析的标签,既节省了内存,又加快了html分析速度。准确的html页面编码分析判断能力,一般的html页面编码仅仅是通过页面中的meta标签或者服务器返回的页面编码,这样是完全不准确的;我们的实现方式是,采用meta标签、服务器编码返回值、以及本地编码判断程序进行判断,极大的提高了页面编码识别准确率。强大的中文分词技术。一般的中文分词都是仅仅分析已知的中文词汇,而对于未知的词汇,如日期、英文单词等分析的情况并不理想,我们的实现方式是,对于已知的中文词汇,我们能在正确区分的基础上,对于不能识别的词汇,如日期等等,则把这些未知词汇组合到一块,很好的解决了这个问题。
附图说明
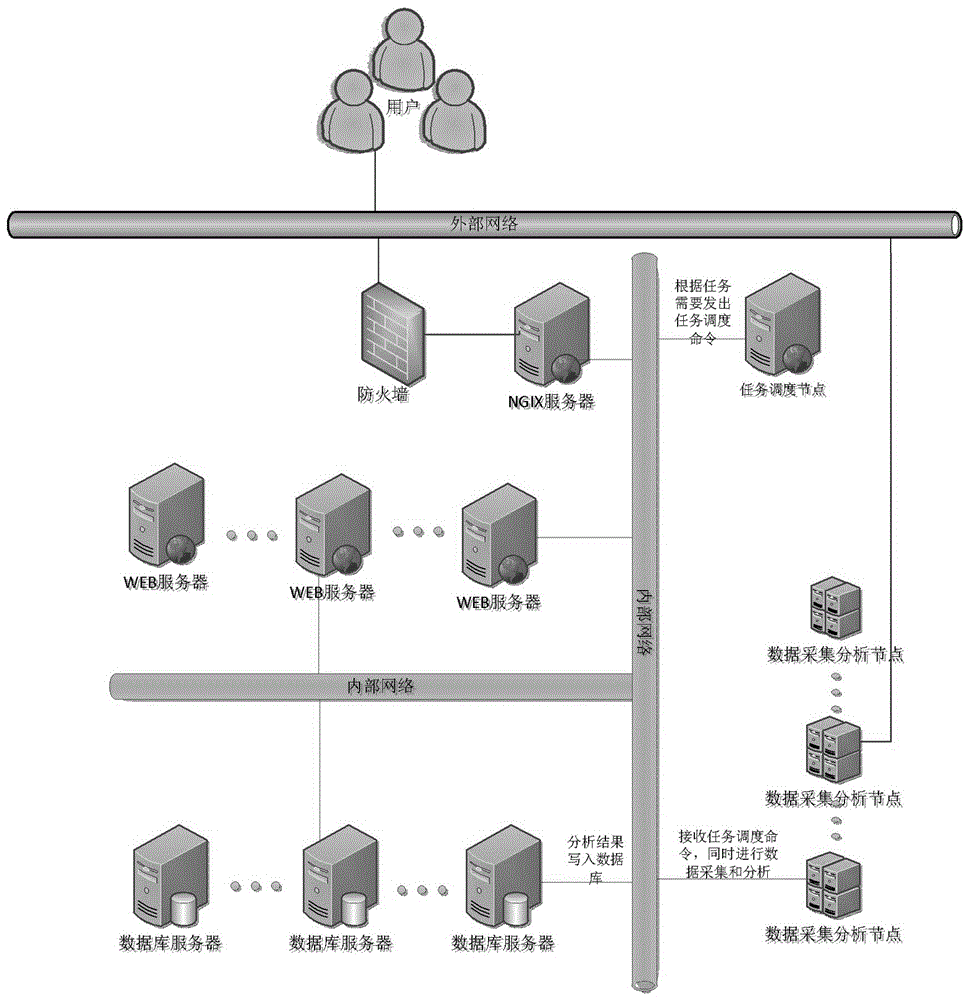
图1为网站监测方法流程示意图;
图2为服务器构成示意图;
图3为任务检测调度模块整体流程示意图;
图4为内部存储管理模块整体功能流程示意图;
图5为DNS缓存模块整体流程示意图;
图6为WEB异步下载模块整体流程示意图;
图7为暗链识别过程示意图;
图8为错别字识别过程示意图。
具体实施方式
实施例1:结合图1-图8,一种基于全站扫描的网站安全监测方法,包括任务调度模块、内存管理模块、DNS缓存模块、WEB网页异步下载模块和内容识别检测模块,包括以下步骤:步骤一:从监测任务表中取出要检测的任务网站属性,包括url地址、调度频率;步骤二:根据url中,利用DNS缓存技术,取出url对应的网络地址;步骤三:构造HTTP请求,向服务建立连接,并发送请求,获取其状态;步骤四:如果状态存在异常,则进行报警;步骤五:向服务器构造HTTP请求,并下载网页页面;步骤六:利用网页快速分析算法,对网页内容进行分析,并过滤掉不必要的标签和内容;步骤七:利用内容编码识别算法,对网页内容进行编码识别,并对网页内容进行转码;步骤八:利用中英文分词识别算法,对转码后的内容进行中文分词;步骤九:对于网页分析结果,利用暗链识别技术,对网页中存在的超链接进行分析,如果是暗链,则进行报警;步骤十:对于网页内容,利用错别字识别技术,对网页中的内容进行分析,如果存在错别字,则进行报警。
网页快速分析算法的步骤为:步骤201:查看当前字符,如果该字符属于空格或者换行符,则跳过这些字符;步骤202:如果是转义字符,则跳过这些转义字符;步骤203:如果不是’<’符号,则将其当做正文存入,否则转到第四步;步骤204:如果是注释,则跳过所有注释,否则转到步骤205步;步骤205:如果是a、link、base、frame、iframe、title、meta、img、style标签的任意一种,则对其标签的属性进行分析,如果是a标签,则采用Sunday算法取出a标签之间的内容;步骤206:直接跳过其它标签;步骤207:如果已经到文件结尾,则退出,否则回到步骤201。
编码识别算法的具体步骤为:步骤301:获取http回应头中的编码;步骤302:获取html页面的编码;步骤303:如果在步骤301和步骤302中获取的编码任意一个为空,则取非空的编码集;如果两者不同,则转至第五步;步骤304:根据非空的编码集,对html已经获取到的内容做转码,如果转码成功,则结束否,则转至步骤305;步骤305:清空编码集,并调用自编写的python编码判断模块接口对该网页内容进行判断,获取该内容的编码,并转至步骤304,如果失败,则编码识别不成功。
中英文分词算法的具体步骤为:步骤401:从要分词的字符串最右边匹配过的位置开始,判断第一个字的长度(utf-8编码);步骤402:如果该字符是英文字符或者asscii字符,则表明该字符串将是一个英文单词;否则转到步骤404;
步骤403:如果前面已经有识别的英文字符,并且该字符是空格或者非ascii字符,则视为本次英文单词的结束。否则继续向后匹配;步骤404:从本字节开始向后回退一个字的长度,作为一个汉字,同时在词库中匹配以前已经匹配成功的长度,如果匹配成功,则继续向后回退,如果有未识别的字符,则将未识别的字符串放入到词语队列,否则视为不匹配,转向步骤405;步骤406:如果匹配不成功,如果之前有英文字符,则视为该英文字符已经结束;同时将该字加入未识别字符队列;并将已识别的词语放入到分词队列中;步骤407:更改分词位置,如果已到开头,则此次分词结束,否则转到步骤401。
DNS缓存技术的过程主要为:将域名进行hash计算,并在hash链表中查找是否存在,如果存在,是否DNS解析失败或者该DNS地址已经过期,如果是的话,则对该域名进行解析,并将解析后的地址放入到hash链表中去;否则直接取出该域名的Internet地址。
任务调度模块,用于对状态检测和内容检测进行任务调度,以便于网站监测在特定的周期内能够完成。内存管理模块,对于所有的url扫描任务所需要的内存进行提前分配和序列化,以便于内存的快速申请和统一管理。DNS缓存模块,对于要请求的url进行DNS地址缓存,提高其解析速度。WEB网页异步下载模块,对于各种不同传输方式的网页进行快速下载。内容识别检测模块,主要包括网页内容编码识别、中英文分词、暗链识别、错别字识别和敏感词识别。
WEB异步下载模块,主要包括基于事件通知的异步I/O技术和基于线程池的WEB页面下载模块。
基于事件通知的异步I/O技术:很明显,基于阻塞的I/O或者基于轮询的I/O技术不能满足该网站监测方法的要求:尽可能快的完成I/O操作和任务调度工作,从而使每个工作机尽可能的任务最大化。
从linux2.6版本之后,linux引进了基于事件通知的epoll,主要有以下三个优点:
1、 支持一个进程打开大数目的socket描述符(FD);
select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是2048。对于那些需要支持的上万连接数目的IM服务器来说显然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的 Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。不过 epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
2、IO效率不随FD数目增加而线性下降;
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是"活跃"的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个"伪"AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的---比如一个高速LAN环境,epoll并不比select/poll有什么效率,相反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
3、使用mmap加速内核与用户空间的消息传递
这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。
由此可见,在该网站监测方法中使用epoll接口是最好的结果。如何使用epoll也是一项很重要的工作。
在该网站监测方法中,在建立连接之后,先构建该站点需要的相关任务信息,并将该指针传递给epoll,然后等待事件通知,并根据通知类型和站点属性进行相应的操作。
在多线程环境下,同时操作epoll会引起不可预知的错误。因此,在该网站监测方法中的解决方法就是在每次加入epoll时,加入EPOLL_ONESHOT标志,在epoll完成事件通知之后,自动从监控队列中删除。
基于线程池的WEB页面下载模块:a)线程池技术:数据传统处理方式为每个任务创建一个独立的工作者线程后台处理数据,当数据处理结束后,该 工作者线程也随即结束,而后该线程被系统销毁。 而线程池模式则在第一次数据处理前一次性创建指定数目的线程,这些线程不断地从数据列表(本例中可以看作任务列表)中读取数据单元并处理,处理一个数据后接着读取下一个数据再处理,直到系统退出或者数据处理过程全部结 束这些线程才被销毁。为了验证这两种方式对性能的影响,现在假设数据处理 量为 N ,数据处理总耗时为T,单个数据处理时间为△tp (time process ),单个线程的创建和销毁时间分别为△tc (time create )和△tt (time terminate), 线程池中的线程个数为 a,由此得出未采用数据池的传统数据处理方式的总耗时为:
T(传统模式) = N*(△tc+ △tp+ △tt)
而采用线程池的数据处理模型时,则数据处理的总耗时T为:
T(线程池模式)= a*△tc + N*△tp + a*△tt
假设采用线程池模式带来的时间优化度为△T,则:
△T = T(传统模式)-T(线程池模式)
得出:
△T=(N-a)*(△tc + △tt)
由此可以看出,当 N>a 时,线程池模式提高系统性能,而当 N<a 时,线 程池模式降低系统性能。在实际情况中,由于受到 CPU 处理能力和系统资源 的制约,线程池中合理的线程数一般分布在 0-30 之间,我们设置该线程池的数目为物理机的CPU内核数乘以2。
b)Web页面下载技术:WEB服务端传送页面有两种方式:基于总大小和chunk方式的。
如何识别这两种方式?在http回应头中会有transfer-encoding 和 content-length这两个字段的标志。我们根据这两个标志来判断页面的传输方式。同时将该信息存储到epoll属性结构体中。
A.基于总大小的传输方式
在开始接受html页面之前,会根据回应头存储相应的总大小,并将每次接受的字节数初始化。每次有数据到来时,接收相应的数据并存储到文件中去,并更新接受字节总数,如果已经达到总大小,则停止接收,并关闭socket。
B.基于chunked的传输方式
Chunked编码是http协议的一种编码方式,Chunked编码使用若干个Chunk串连而成,由一个标明长度为0的chunk标示结束。每个Chunk分为头部和正文两部分,头部内容指定下一段正文的字符总数(十六进制的数字)和数量单位(一般不写),正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为0的Chunk中的内容是称为footer的内容,是一些附加的Header信息。
根据此协议,我们在每次传输前,先获取该chunk的大小,然后从web服务器中获取chunk大小的字节数即可。然而比较困难的是我们采用的的是epoll的异步方式传输,因此我们要应对每次传输过程中该chunk大小的字节不能取完的状况;为此我们提前申请一块内存对本次传输进行关联,存储该次的相关属性。
分词效果举例:通过上述算法,对两段文字(一个是新闻段落,一个是英文段落)进行分词,效果如下:
(一)中文新闻段落举例:
这一刻,整个甲骨文球馆都沉默了。要知道在这之前,骑士的三分球是24投5中糟糕的一塌糊涂,而厄文命中这个三分的方式,是运球之后直接出手,在库里面前用库里最擅长的一招杀死比赛,厄文证明了自己在关键时刻,绝不仅仅只当一个看客,这个球命中过后,勇士全队都崩溃了,胜负再也没有产生悬念,骑士最终93-89赢得胜利,大比分4-3夺得总冠军。
分词结果:
这一刻/,/整个/甲骨文/球馆/都/沉默了/。/要知道/在这之前/,/骑士/的/三分球/是/24/投/5/中/糟糕/的/一塌糊涂/,/而/厄文/命中/这个/三分/的/方式/,/是/运球/之后/直接/出手/,/在/库里/面前/用/库里/最擅长/的/一招/杀死/比赛/,/厄文/证明了/自己/在/关键时刻/,/绝/不仅仅/只当/一个/看客/,/这个/球/命中/过后/,/勇士/全队/都/崩溃了/,/胜负/再也没有/产生/悬念/,/骑士/最终/93-89/赢得/胜利/,/大比分/4-3/夺得/总冠军/。/
(二)英文段落举例:
Dad loved to play the mandolin for his family he knew we enjoyed singing, and hearing him play. He was like that. If he could give pleasure to others, he would, especially his family. He was always there, sacrificing his time and efforts to see that his family had enough in their life. I had to mature into a man and have children of my own before I realized how much he had sacrificed.
分词结果:
Dad/loved/to/play/the/mandolin/for/his/family/he/knew/we/enjoyed/singing/and/hearing/him/play/He/was/like/that/If/he/could/give/pleasure/to/others/he/would/especially/his/family/He/was/always/there/sacrificing/his/time/and/efforts/to/see/that/his/family/had/enough/in/their/life/I/had/to/mature/into/a/man/and/have/children/of/my/own/before/I/realized/how/much/he/had/sacrificed。
- 还没有人留言评论。精彩留言会获得点赞!