一种用于执行散列函数的设备以及方法与流程
本发明要求2012年1月17日由华南(Nan Hua)等人递交的发明名称为“具有有限资源的优良通用散列函数的设计”的第13/351,704号美国非临时专利申请案以及2011年2月3日由华南(Nan Hua)等人递交的发明名称为“具有有限资源的优良通用散列函数”的第61/439,234号美国临时专利申请案的在先申请优先权,所述两个在先申请的内容以全文引入的方式并入本文本中。
关于由联邦政府赞助的研发的声明
不适用。
微缩胶片附录参考
不适用。
技术领域
无
背景技术:
执行散列函数来将非随机(或不那么随机)的值转换成均匀分布的随机数。散列函数是网络连接中的重要函数。基于散列的算法在网络中,例如,在相对更加关键和高速的组件或装置中,越来越多地被提议和部署。有些散列函数是使用软件执行的,例如鲍勃﹒詹金散列(Bob Jenkin's hash)和穆哈散列(Murmurhash)。其它散列函数是使用硬件执行的,例如循环冗余检查(CRC),H3(具有固定种子)以及皮尔逊(Pearson)和巴兹散列(Buzhash)。网络连接装置的性能越来越依赖于概率算法或数据结构。所述算法或数据结构可能会遇到不正常的情况,这样的情况会造成问题,并且不能接受的是,使路由器等网络组件或装置变慢。例如,如果在多个路由器上触发,所述有问题的情况有时候会引起网络故障。所述算法和数据结构使用散列函数来将相对稀疏的输入集合转换或减少成更加密集且更加易管理的集合,这些集合可在网络中得到更好的存储或处理。使用这些散列函数,能够避免至少大量的引起网络故障或性能降低的不正常情况。
技术实现要素:
在一个实施例中,本发明包含,包括串联耦合且用于实施散列函数的多个级,其中所述级包括多个XOR阵列以及一个或一个以上包括多个并联门的替代盒(S盒)。
在另一实施例中,本发明包含一种设备,其包括多个并联耦合的XOR门,多个耦合到所述XOR门的输入位,以及多个耦合到所述XOR门的输出位,其中所述XOR门用于执行所述输入位变成所述输出位的线性混合函数,作为非密码编译的散列函数的一个级。
在另一实施例中,本发明包含一种设备,其包括多个并联布置的S盒,多个耦合到所述S盒的输入位以及多个耦合到所述S盒的输出位,其中所述S盒用于执行所述输入位变成所述输出位的置换以及非线性混合函数,作为非密码编译散列函数的一个级。
在又一实施例中,本发明包含一种通过一个设备执行的方法,所述方法包括使用在非密码编译散列函数架构中串联耦合的多个XOR阵列,混合多个输入位以提供多个输出位,以及使用在非密码编译散列函数架构中与所述XOR阵列串联耦合的多个S盒阵列,提供多个输入位变成多个输出位的置换。
从结合附图和所附权利要求书进行的以下详细描述将更清楚地理解这些和其它特征。
附图说明
为了更完整地理解本发明,现在参考以下结合附图和详细描述进行的简要描述,其中相同参考标号表示相同部分。
图1是散列函数架构的实施例的示意图。
图2是XOR阵列的实施例的示意图。
图3是S盒阵列的实施例的示意图。
图4是置换方案的实施例的示意图。
图5是散列函数方法的实施例的流程图。
图6是网络单元的实施例的示意图。
图7是通用计算机系统的实施例的示意图。
图8是S盒阵列的实施例的示意图。
具体实施方式
首先应理解,尽管下文提供一个或一个以上实施例的说明性实施方案,但可使用任何数目的技术,不管是当前已知还是现有的,来实施所揭示的系统和/或方法。本发明决不应限于下文所说明的所述说明性实施方案、图式和技术,包含本文所说明并描述的示范性设计和实施方案,而是可在所附权利要求书的范围以及其均等物的完整范围内修改。
当前可用的散列函数,例如,在网络连接中使用的散列函数,不能够提供足够的随机性,可能不适用于成本足够低的实施方案,或者两种情况都有。本文中所揭示的是提供改进的非密码编译散列函数的系统和方法,所述散列函数可能是通用的散列函数并且可以使用有限的片上资源。所述改进的散列函数可能基于串联级或XOR阵列的块及/或S盒阵列来提供改进的随机性性能。如下文所详细描述,所述散列函数架构可包括一系列级,所述级可包括XOR阵列及/或S盒。所述改进的散列函数可提供改进的随机性,例如,与当前可用的散列函数相比更接近均匀分布,且因此可提供更好的网络性能。所述改进的散列函数还可提供比当前可用的散列函数成本更低的实施方案。
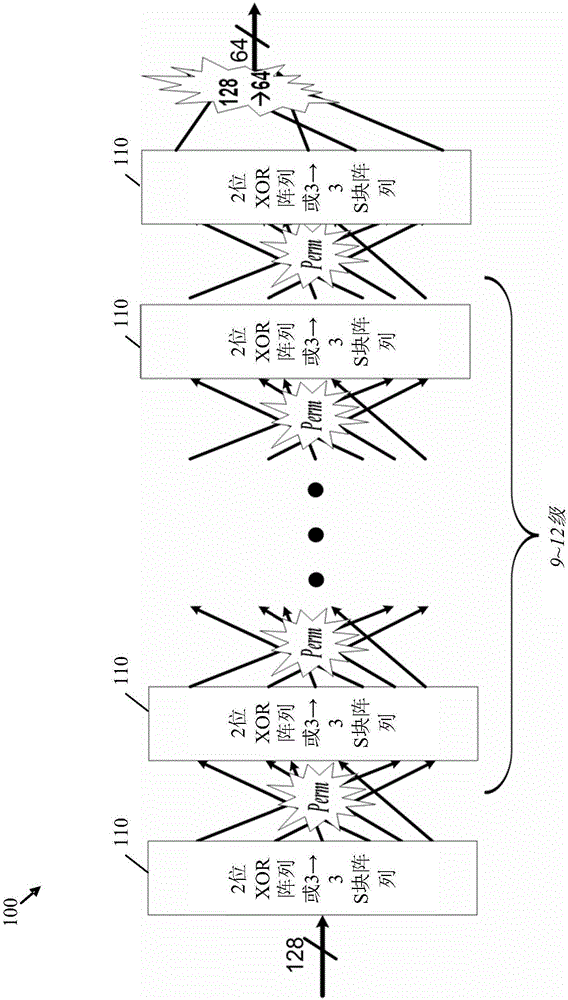
图1说明散列函数架构100的实施例,可执行所述散列函数架构100来获得改进的随机性。所述散列函数架构100可使用硬件,或者在一些实施例中,使用硬件和软件两者来执行。就硬件实施方案来说,可以用相对低的成本执行所述散列函数架构100。如图1所示,所述散列函数架构100可包括可能是串联耦合的多个级110。所述散列函数架构100可具有比输入位更少数目的最终输出位。可通过所述串联中的第一级110接收所述输入位,并且可通过所述串联中的最后级110转发所述输出位。例如,所述散列函数架构100可具有大约128个输入位和大约64个最终输出位。在其它实施例中,所述散列函数架构100可能具有不同数目的输入位及/或最终输出位,其中最终输出位的数目可能小于输入位的数目。
所述散列函数架构100还可具有有限数目的级110。例如,所述散列函数架构100可能具有大约12个可串联耦合的级110。在其它实施例中,级的数目可在大约9个级和大约12个级之间变化。级110的数目有限,所以可以实现可行的硬件实施方案,例如使用专用集成电路(ASIC)来实施。因为级的数目有限,所以还可限制级110的串联的总处理时间或延迟,其中每个级110可引入一个循环的延迟。相对于级110的一个循环的延迟,级110之间的电线或链路(连接)延迟可能非常小或可忽略不计。因此,在12个级的情况下,总延迟可能限于所述一个循环的延迟的大约12倍。
如下文所描述,每个所述级110可包括大约一个门,这个门可能是线性XOR阵列或非线性S盒阵列,并且所述散列函数架构100可能不包括任一所述级110中的反馈。此类特征可简化所述散列函数架构100的设计。例如,所述级110可包括串联的XOR阵列和S盒阵列的确定组合。每个级110可处理许多输入位并且提供相应数目的输出位。除了串联中的第一级110,每个级110的输入位可能是所述串联中的先前的级110的输出位的置换。因而,除了所述串联中的最后级110,每个级110的输出位可能被置换(例如,重新分配或重新混合)并且随后作为输入位提供给接下来的级110。
所述散列函数架构100的设计方法可能基于多个准则。一个准则是将所述输入信号或位适当混合到所述第一以及剩余的级110中。因此,可提供所述输入位中的适当量的熵值,其可能例如在每级110及/或级110之间的输入位中均匀分布或者可能并不在其中均匀分布。举例来说,媒体接入控制(MAC)地址可能是大约48个位,其中第一或顶部的大约24个位可用来指示装置的制造商。MAC地址的这种部分或地址空间可能被稀疏地填充,并且各家公司可以用相对较小数目的网络装置制造商标准化。因此,最高位(例如,24位)可能比剩余位或低位更加可预测,所述剩余位或低位可在确定混合所有位时予以考虑。合适的散列函数可用于恰当且有效地混合输入位(在每个级110),且因此提供改进的(大体上随机的)最终输出(来自最后级110)。有效或改进的散列函数可例如尽可能使用可用的(硬件)资源,建立输入位的大体混合。
提供适当散列函数的另一准则是使用可逆的映射。可逆的映射可包括大约相同数目的输入位和输出位。使用可逆的映射可允许更多时间来在输出位中混合输入位的熵值。例如,如果在散列函数中很早就产生了冲突,可能会失去熵值而没有机会将此熵值混合到其它位中。在每个步骤使用可逆的映射可保证减少熵值损失或没有熵值损失,且因此减少算法诱导的冲突或没有算法诱导的冲突。这可以提高将均匀输入映射成均匀输出的几率,因为可能使用了输出空间的每个部分。
通常,基于散列函数的硬件可以直接控制位级上的值,并且可以使用例如相较于可平行布置的软件散列函数更加简单的组成块。在硬件中,位可对应于电线,且因此打乱处于固定模式下的一个值的多个位可通过将表示所述值的电线向不同的位置布线实现。例如整数乘法和加法的相对复杂的操作可能成本过高,而不能包含在硬件散列函数中。可恰当地组织例如XOR的逐位操作来混合所述位,其中可以并行执行操作。可以按区域(涉及门和电线的数目)和时序测量硬件散列性能,所述区域和时序可能取决于例如在最长的路径上(完整数目的级110)从输入位到输出位的电线长度和门的数目。
在散列函数架构100中,可串联布置级110来执行位混合以及置换序列的交替。此设计可能类似于密钥位不在每一轮回合并的密码编译的替代-置换网络。可将每个组件设计为可逆的,例如,以便避免偏压和失去输入熵值。另外,在每轮回中(级110)可提高或最大化效益成本比率。足够数目的轮回(级110)可用以获得足够的或大量的位混合。
可通过用随机观察模式放置门来组成很大的混合函数。然而,这种布置可包含非可逆的组件。代替地,可使用线性功能(XOR阵列),其可能是容易可逆的。线性函数还可提供相对充分的混合,但这种函数可能不会引起任何崩溃(avalanche)。所述崩溃性质可在每个输出位是每个输入位的非线性混合时实现。另外,组成很大的单个级来同时混合所有的输入位(例如,大约128个输入位)可能有相当高的成本。代替地,由于单个混合函数的大小可能至少是将要混合的位的数目的三次方,因此可使用相对低成本的轮回(级110)以较小批量(少于输入位的总数目)来对位进行混合。作为交换,可能需要多个轮回来将所有输入位(例如,128位)彻底混合进所有输出位(例如,64位)中。
使用多个轮回或级110并且在(轮回)的小型群集中混合位来代替使用一个很大的混合级,可以用低很多的成本来获得相对优良的崩溃性质。因而,可在轮回之间置换所述位,例如,使得位可与不同的位混合(在不同轮回)。以很小的成本使用某种非线性混合(S盒阵列),可在许多轮回中重复操作,以便以相对低的成本获得大体上完整的崩溃。每个混合轮回或级110可对应于线性XOR阵列或非线性S盒阵列。通过在级110之间恰当地分布以及安排电线,使用很大的位置换函数的有效的硬件实施方案,可实现置换轮回。下文中描述关于执行散列函数架构100的特征的更多细节。
图2说明XOR阵列200的一个实施例,所述XOR阵列200可用作所述散列函数架构110中的一个或一个以上级110。所述XOR阵列200实质上可使用硬件执行。所述XOR阵列200可包括多个XOR门210,这些门可如图2所示并联布置。所述XOR阵列可能是可混合输入位的相对简单的电路。如图2所示,所述XOR门210可能是3位输入XOR门或2位输入XOR门。具体而言,所述XOR阵列200可包括大约一个3位输入XOR门210以及多个剩余的2位输入XOR门210。XOR门210的总数可能取决于为对应于所述XOR阵列200的级分配的输入位的数目,所述级例如是所述散列函数架构中的级110。
XOR阵列可为输入矩阵(X)执行实质上稀疏的可逆矩阵乘法,以便获得输出矩阵(Y)。所述输入矩阵对应于输入位并且所述输出矩阵对应于输出位。图2中还展示所述XOR阵列200操作的等效矩阵表示。所述XOR阵列200操作可对应于在相邻的输入位(输入[0]、输入[1]、…、输入[n-1],其中n是表示XOR门210的总数的整数)上执行所述XOR函数。每个XOR阵列200中(在每个级110中)可使用一个3位输入XOR门210,以便获得可能是可逆的映射。如果在所述XOR阵列200中仅使用2位输入XOR门210,那么任何所得的XOR门210组合可能是非可逆的。如果在所述XOR阵列200中使用一个1位输入XOR门(也被称为电线),那么可能在较低程度上混合相应的输入位,这可能导致可能推进到所述散列函数架构中的最后级的混合不良。
所述XOR阵列200可能不具有任何崩溃性质,但可能具有很低的成本并且可(为所述成本)有效混合位。使用更多3位输入XOR门可允许更密集的矩阵,但门大小可能加倍(达到大约2x或所述大小的两倍)并且门延迟也可能增长大约60%。由于可能需要更多非相邻的位,所以布线的复杂性也可能增长。从使用2位输入XOR门而不是3位输入XOR门的两个较小级,可能实现类似成本并且可能更好的混合。
XOR阵列可相对快速传播位变化但可能不提供非线性。仅使用XOR阵列组成的散列函数可能具有弱崩溃性质,弱随机性能并且可能易受攻击损坏。避免此缺陷的一个方式是使用非线性的块对块置换,在密码编译环境中被称为S盒。图3说明S盒阵列300的一个实施例,所述S盒阵列300可用作散列函数架构110中的一个或一个以上级110。所述S盒阵列300实质上可使用硬件执行。所述S盒阵列300可包括多个S盒310,在本文中也称为S块,其可如图3所示并联布置。
n→n S盒可认为是值0-2n的置换函数,其可获得n位值并且返回n位值。忽略执行考虑,例如,通过选择合适的输入值(输入位)置换,单个128→128S盒可用于所述散列函数并且可获得大体上优良的散列。然而,组成这种S盒可能是不实际的或者实质上可能是困难的。因此,一系列更简单的实施方案可用来近似非线性。然而,在密码编译应用中使用的典型S盒可能很大,例如,至少6→6且有时8→8。
在所述S盒阵列300中,所述S盒310可使用两个选项——直接组合逻辑和存储器中的至少一者来执行。使用逻辑执行S盒310可能具有一个优点,就是可以比使用存储器查询大体上更快地获得结果(输出)。使用逻辑的不足之处可能是大小。例如,对于相对较大的S盒,在所述S盒中需要的门数目可能很多。在相对较短的时间内如果需要所述结果(输出),例如,对于时间紧急的应用,可能需要相对较小的S盒。如果需要较大的S盒,那么可以忍受存储器查询实施方案的实质上较大的延迟。
可以提供非线性的很小的S盒是3→3S盒,其可用作一个或一个以上S盒310。在多个可能的置换中,可以选择随后的置换函数(及其同构等效物):
{0,1,...,7}→{1,4,7,5,2,0,3,6}
以上也展示了所选择的置换的硬件实施方案(使用门)。图3中还展示所选择的置换的所选择的置换函数以及相应的硬件实施方案(使用门)。所选择的S盒310可提供实质上优良的非线性的性质,包含随机分布的输入,交换任何一个位或者两个位,以及交换所有的三个输出位,概率大约为50%。然而,当同时交换所有三个输入位时,可确定地(且不随机)交换所有三个输出位。实际上,可通过一个相对较大的门,例如图3中所示的AOI222门,来处理相对复杂的此门大约可能与2位输入XOR门的大小相同。使用此门,可仅通过大约三个相对较大的门以及大约三个反相器来执行所述S盒310。总的来说,3→3S盒阵列(S盒阵列300)的成本可稍微大于XOR阵列(XOR阵列200)的成本。S盒阵列300还可包括至少一个2→2S盒310。
为了比较,可如下表示4→4S盒的实例:
此4→4S盒可比所述3→3S盒获得更好的非线性,但可能具有实质上较高的成本。所述AOI2222门可能在某些标准单元库中可用,但可能不能够使用单个较大门来计算上述Qc。使用较大S盒(比3→3S盒310大)的可能选项可能是使用多个门,其可导致在区域及时序方面的实质上较大的成本。使用3→3S盒310作为S盒阵列300的组成元件可能是单元成本及混合能力之间的折衷。
在每个级任意置换状态位可能是需要的。理想地,使用任意128位P盒来获得所述散列函数架构级(例如,级110)之间的置换可能是合乎需要的。然而,这样的话所需要的空间(space或room)可能比(例如芯片上)可供使用的空间要多。在数据路径相对较长或较宽的情况下,就电线延迟来说,从一端(第一级)到另一端(最后级)的距离可能很大。由于所述级之间的交叉电线的成本,执行输入位的任意置换也可能是困难的。由于集成电路是在层中构造的,为了交换两条电线,可能需要垂直地跨越层的垂直连接。在硅中布置任意置换实质上比仅仅从一组门一直连接到下一组门需要更多区域。通过约束所述散列函数架构中的置换,不用很大成本就可实现品质相对优良的置换。
在一个实施例中,为了限制交叉电线成本(级之间的),可在每个级向多个群组随机指配输入电线,例如,每群组使用相同数目的输入及输出电线。在一个群组内(每级),一个输入点(输入位对应于一个级)可随机连接到一个输出点(输出位对应于一个先前级),并且下一个输入点随机连接到下一个输出点,直到覆盖所有点。以此方式继续,可在相应群组中将输入位的集合旋转(重定向或重配置)成所述群组中的输出位。要针对每个群组进行此操作,可能每群组需要两个层,例如,一个电线层,其中位下移,以及另一个电线层,其中位上移。图4说明3群组置换方案400,其可在散列函数架构100的每个级之间执行。所述3群组置换方案400可包括对应于三个群组的第一旋转410,第二旋转420,以及第三旋转430。所述三个旋转在单独层中展示。还展示了由所述三个旋转的组合引起的实际组合的置换440。在一些实施例中,每级可使用这种置换的大约两个层级。
通常,密码编译散列函数可执行一些散列关键字的预处理,使得对手要强制冲突更加困难。例如,在多个当前使用的散列函数中,可将输入的长度附加到所述输入自身,例如,作为最终块的一部分,这有时被叫做“增白”(whitening)。所述散列函数架构100可能不包括所述增白步骤。然而,在一些实施例中,所述增白步骤可在实施过程中作为成本/收益折衷的一部分而包含在所述架构中或者被排除。散列函数架构100的一个特征可能是提供比输入值或者输入位具有更少位的结果(或者输出)。这可使用非可逆的最终步骤或者级实现。如果在所述级一直到最终级中实现了充分混合,则所有的所得输出位可能是同样重要的。因此,选择所得输出位的任何集合可能差不多同样优良。更加复杂的最终步骤可用于密码编译散列函数,以便模糊内部状态。为了减少成本,这种最终步骤可能不包含在散列函数架构100中。在不利环境中,可使用后处理器隐藏内部状态或者细节来加强或更好地稳固所述散列函数架构。
图5说明散列函数方法500的一个实施例,所述散列函数方法500可使用散列函数架构100执行。可执行散列函数方法500来用很低的成本(例如,硬件成本)获得改进的随机性。在块510,可使用多个XOR阵列混合多个输入位以提供多个输出位。所述输出位可携带多个值,用于混合所述输入位中的值的多个相应组合。如所述散列函数架构100中所描述,所述XOR阵列可依次布置,例如连续地、通过S盒阵列分离或两者都用。在块520,可使用多个S盒阵列提供多个输入位向多个输出位的置换。所述S盒阵列可为所述输入位变成所述输出位提供非线性混合。这可引起相对优良的崩溃性质。如所述散列函数架构100中所描述的,所述S盒阵列可依次布置,例如,连续地、通过XOR阵列分离或两者都用。S盒阵列的数目可能小于XOR阵列的数目。在块530,多个随机指配的输入位以及输出位群组可在多个相应的级之间旋转,例如,来获得足够的置换并且限制旋转所需的层,且因此限制实施方案的大小和成本。例如,每级可旋转大约三个群组,所述每级可能需要大约两个层。可执行所述方法500,直到覆盖了所述散列架构的所有级,随后所述方法500可结束。
图6说明网络单元600的一个实施例,所述网络单元600可位于网络中或者位于与网络连通或在网络内的任何组件中。所述网络单元600可以是通过网络传输数据或者与网络交换数据的任何装置。例如,所述网络单元600可以是网络相关联的路由器或服务器。所述网络单元600可包括一个或一个以上进入端口或者单元610,其耦合到接收器(Rx)612,用于从其它网络组件接收信号和帧/数据。所述网络单元600可包括逻辑单元620来确定向哪些网络组件发送数据。逻辑单元620可使用硬件、软件或两者执行。所述网络单元600还可包括一个或一个以上外出端口或单元630,其耦合到发射器(Tx)632,用于向其它网络组件发射信号和帧/数据。接收器612、逻辑单元620以及发射器632也可以执行或支持所述散列函数方法500和所述散列函数架构100。例如,所述网络单元600或所述逻辑单元620可包括所述散列函数架构100。所述网络单元600的组件可如图6所示布置。
上文所描述的网络组件可以在任何通用的网络组件上执行,例如,具有足够处理能力、存储器资源以及网络吞吐能力的计算机或网络组件,以便处理放置在其上的必要工作量。图7说明适用于执行本文中所揭示的组件的一个或一个以上实施例的典型、通用的网络组件700。所述网络组件700包含与存储器装置通信的处理器702(其可被称作中央处理单元或CPU),所述存储器装置包含辅助存储装置704、只读存储器(ROM)706、随机存取存储器(RAM)708、输入/输出(I/O)装置710以及网络连接装置712。所述处理器702可实施为一个或一个以上CPU芯片或者可以是一个或一个以上专用集成电路(ASIC)及/或数字信号处理器(DSP)的一部分。
辅助存储装置704通常由一个或一个以上磁盘驱动器或可擦除可编程ROM(EPROM)组成,且用于非易失性数据存储。辅助存储装置704可用于存储程序,当选择此些程序来执行时,将所述程序加载到RAM 708中。ROM 706用于存储在程序执行期间读取的指令以及可能的数据。ROM 706是非易失性存储器装置,其通常具有与辅助存储装置704的较大存储器容量相比较小的存储器容量。RAM 708用于存储易失性数据且可能用于存储指令。对ROM 706和RAM 708两者的存取通常比对辅助存储装置704的存取快。
揭示至少一个实施例,且所属领域的技术人员对所述实施例和/或所述实施例的特征的变化、组合和/或修改在本发明的范围内。因组合、整合和/或省略所述实施例的特征而产生的替代实施例也在本发明的范围内。在明确陈述数值范围或限制的情况下,应将此些表达范围或限制理解为包含属于明确陈述的范围或限制内的类似量值的重复范围或限制(例如,从约1到约10包含2、3、4等;大于0.10包含0.11、0.12、0.13等)。举例来说,每当揭示具有下限Rl和上限Ru的数值范围时,具体揭示的是属于所述范围的任何数字。明确地说,具体揭示的是在所述范围内的以下数字:R=Rl+k*(Ru-Rl),其中k是用1%增量的从1%到100%变化的变量,即,k是1%、2%、3%、4%、5%、…、50%、51%、52%、…、95%、96%、97%、98%、99%或者100%。此外,还特定揭示由如上文所定义的两个R数字定义的任何数值范围。相对于权利要求的任一元素使用术语“任选地”意味着所述元素是需要的,或者所述元素是不需要的,两种替代方案均在所述权利要求的范围内。使用例如包括、包含和具有等较广术语应被理解为提供对例如由……组成、基本上由……组成以及大体上由……组成等较窄术语的支持。因此,保护范围不受上文所陈述的描述限制,而是由所附权利要求书界定,所述范围包含所附权利要求书的标的物的所有均等物。每一和每个权利要求作为进一步揭示内容并入说明书中,且所附权利要求书是本发明的实施例。所述揭示内容中的参考的论述并不是承认其为现有技术,尤其是具有在本申请案的在先申请优先权日期之后的公开日期的任何参考。本发明中所引用的所有专利、专利申请案和公开案的揭示内容特此以引用的方式并入本文本中,其提供补充本发明的示范性、程序性或其它细节。
虽然本发明中已提供若干实施例,但应理解,在不脱离本发明的精神或范围的情况下,所揭示的系统和方法可用许多其它特定形式来体现。本实例应被视为说明性的而非限制性的,且本发明不限于本文所给出的细节。举例来说,各种元件或组件可在另一系统中组合或集成,或某些特征可省略或不实施。
另外,在不脱离本发明的范围的情况下,各种实施例中描述和说明为离散或单独的技术、系统、子系统和方法可与其它系统、模块、技术或方法组合或整合。展示或论述为彼此耦合或直接耦合或通信的其它项目也可用电方式、机械方式或其它方式通过某一接口、装置或中间组件间接地耦合或通信。改变、替代和更改的其它实例可由所属领域的技术人员确定,且可在不脱离本文所揭示的精神和范围的情况下作出。
- 还没有人留言评论。精彩留言会获得点赞!