一种监测交互式网络电视IPTV用户状态的方法及装置与流程
本发明涉及交互式网络电视数据分析与处理的技术领域,特别涉及一种监测交互式网络电视iptv用户状态的方法及装置。
背景技术:
随着国内固网运营商的业务转型,交互式网络电视(iptv,internetprotocoltelevision)业务已呈现出快速增长的态势。尽管网络运营商也在重点采集、监测网络传输参数,但是iptv业务在网络传输中仍会受到干扰,产生的不利影响主要表现在用户感知恶化,例如卡顿花屏等。
目前,处理分析iptv数据的方法很大程度上是依据各大机顶盒产商设计的(mos,meanopinionscore)值模型进行评判,但各产商模型之间缺乏统一标准,结果难以验证。因此,对于运营商而言,目前无法及时、准确的确定出iptv系统中的各用户的状态,使得在iptv系统中出现感知恶化的用户时,难以及时对iptv系统进行网络优化,影响用户体验。
技术实现要素:
本发明实施例的目的在于提供一种监测交互式网络电视iptv用户状态的方法及装置,能使运营商及时、准确的确定出iptv系统中的各用户的状态,使得在iptv系统中出现感知恶化的用户时,及时对iptv系统进行网络优化,提升用户体验。
为了达到上述目的,本发明的实施例提供了一种监测交互式网络电视iptv用户状态的方法,包括:
获取各iptv用户的节目观看数据;其中,节目观看数据包括多条观看记录,每条观看记录包括多个第一数值型指标;
根据每个iptv用户的每条观看记录中的多个第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录;
根据每个iptv用户的多条观看记录中的质差记录,确定出每个iptv用户的状态。
其中,根据每个iptv用户的每条观看记录中的多个第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录的步骤,包括:
检测iptv用户的每条观看记录中的多个第一数值型指标的数值,是否与质差记录模型中的质差指标的阈值匹配;
若iptv用户的观看记录中的多个第一数值型指标的数值与质差记录模型中的质差指标的阈值匹配,则确定该观看记录为质差记录。
其中,质差记录模型为f1=f(q1′>φ1,q2′>φ2,...,qi′>φi),i=q′,其中,f1表示质差记录模型,q1′表示质差记录模型中的第一个质差指标,φ1表示第一个质差指标的阈值,q2′表示质差记录模型中的第二个质差指标,φ2表示第二个质差指标的阈值,qi′表示质差记录模型中的第i个质差指标,φi表示第i个质差指标的阈值,q′表示质差记录模型中质差指标的数量。
其中,根据每个iptv用户的多条观看记录中的质差记录,确定出每个iptv用户的状态的步骤,包括:
根据iptv用户的多条观看记录中的质差记录,确定iptv用户的每条观看记录的质差记录分布的标记;
根据iptv用户的每条观看记录的质差记录分布的标记,通过质差用户模型
若f2的值为1,则确定该iptv用户为质差用户;
若f2的值为0,则确定该iptv用户为非质差用户。
其中,根据iptv用户的多条观看记录中的质差记录,确定iptv用户的每条观看记录的质差记录分布的标记的步骤,包括:
通过公式
其中,在根据每个iptv用户的每条观看记录中的多个第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录的步骤之前,方法还包括:
根据预先得到的多个质差用户的观看记录所包含的多个第二数值型指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,根据预先得到的多个质差用户的观看记录所包含的多个第二数值型指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的步骤,包括:
根据每个预先得到的质差用户的多个第二数值型指标,得到每个预先得到的质差用户的指标相关性矩阵;
根据每个预先得到的质差用户的指标相关性矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标;
从每个预先得到的质差用户的每个聚类的指标变量所包含的第二数值型指标中,筛选出每个预先得到的质差用户的每个聚类的代表指标;
根据筛选出的代表指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,根据每个预先得到的质差用户的多个第二数值型指标,得到每个预先得到的质差用户的指标相关性矩阵的步骤,包括:
对每个预先得到的质差用户的多个第二数值型指标进行标准化处理,得到每个预先得到的质差用户的多个标准化数值型指标;
计算每个预先得到的质差用户的每两个标准化数值型指标之间的相关性,得到每个预先得到的质差用户的指标相关性矩阵。
其中,对每个预先得到的质差用户的多个第二数值型指标进行标准化处理,得到每个预先得到的质差用户的多个标准化数值型指标的步骤,包括:
通过公式
其中,计算每个预先得到的质差用户的每两个标准化数值型指标之间的相关性,得到每个预先得到的质差用户的指标相关性矩阵的步骤,包括:
通过公式
通过公式r=(rij)计算得到每个预先得到的质差用户的指标相关性矩阵;其中,r表示预先得到的质差用户的指标相关性矩阵。
其中,根据每个预先得到的质差用户的指标相关性矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标的步骤,包括:
确定每个预先得到的质差用户的指标相关性矩阵中各行互不相同;
根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的每两个第二数值型指标之间的相似性距离,得到每个预先得到的质差用户的相似性距离矩阵;
通过r型聚类法,根据每个预先得到的质差用户的相似性距离矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的每两个第二数值型指标之间的相似性距离,得到每个预先得到的质差用户的相似性距离矩阵的步骤,包括:
通过公式sij=1-rij计算得到每两个第二数值型指标之间的相似性距离;其中,sij表示第i个第二数值型指标与第j个第二数值型指标之间的相似性距离;
通过公式
其中,方法还包括:
根据每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标,绘制每个预先得到的质差用户的聚类结果谱系图,并展现绘制的聚类结果谱系图。
其中,确定每个预先得到的质差用户的指标相关性矩阵中各行互不相同的步骤,包括:
判断指标相关性矩阵中是否存在相同的多个行;
若指标相关性矩阵中存在相同的多个行,则根据在操作界面接收到的删除指令,将多个行删除至一个行,并删除被删除行对应的第二数值型指标,使指标相关性矩阵中各行互不相同。
其中,在确定每个预先得到的质差用户的指标相关性矩阵中各行互不相同的步骤之后,方法还包括:
通过多维标度法,根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的距离矩阵,并根据每个预先得到的质差用户的距离矩阵,绘制每个预先得到的质差用户的多维标度图;
展现绘制的多维标度图,并根据在操作界面接收到的修改指令,修改每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,通过多维标度法,根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的距离矩阵的步骤,包括:
通过公式
通过公式h=(hij)计算得到预先得到的质差用户的距离矩阵;其中,h表示预先得到的质差用户的距离矩阵。
其中,从每个预先得到的质差用户的每个聚类的指标变量所包含的第二数值型指标中,筛选出每个预先得到的质差用户的每个聚类的代表指标的步骤,包括:
给每个预先得到的质差用户的每个聚类的指标变量建立因子分析模型;
通过因子分析方法,根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型,得到每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵;
根据预设的特征根的累计方差贡献率的阈值,以及每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵,确定出每个预先得到的质差用户的每个聚类的指标变量的公共因子数量;
对每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵进行正交旋转,并根据每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,计算出每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度;
根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度,以及每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,给每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型;
根据每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型,从每个预先得到的质差用户的每个聚类的指标变量包含的第二数值型指标中筛选出相关性贡献度最高的第二数值型指标,并将该第二数值型指标作为该聚类的代表指标。
其中,根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度,以及每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,给每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型的步骤,包括:
通过公式
通过公式
其中,根据筛选出的代表指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的步骤,包括:
根据每个预先得到的质差用户的每个聚类的代表指标,统计每个第二数值型指标被筛选为代表指标的次数;
根据统计得到的次数,按照次数从高至低的顺序,对被筛选为代表指标的第二数值型指标进行排序;
根据在操作界面接收到的选择指令,从被筛选为代表指标的第二数值型指标中筛选出质差记录模型中的质差指标;
根据筛选出的质差指标,获取质差记录模型中质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,根据筛选出的质差指标,获取质差记录模型中质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的步骤,包括:
将质差记录模型中质差指标的阈值设为第一预设值,并根据筛选出的质差指标以及设为第一预设值的质差指标的阈值构成的质差记录模型,确定每个预先得到的质差用户的每条观看记录的质差记录分布的标记;
根据每个预先得到的质差用户的每条观看记录的质差记录分布的标记,统计每个预先得到的质差用户的质差记录数量,并根据每个预先得到的质差用户的质差记录数量,计算每个预先得到的质差用户的质差记录占每个预先得到的质差用户的观看记录的数量的比值;
将质差用户模型中的质差记录占观看记录的数量的比重的阈值设为第二预设值,并确定每个预先得到的质差用户的比值大于或等于第二预设值;
控制质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型从多个第一用户和/或多个第二用户中筛选出质差用户;其中,第一用户的类型为无质差用户,第二用户的类型为质差用户;
获取质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型筛选质差用户的准确率,若准确率达到第三预设值,则将第一预设值作为质差指标的阈值,并将第二预设值作为质差记录占观看记录的数量的比重的阈值;
若准确率未达到第三预设值,则调整第二预设值的大小,并根据调整后的第二预设值,调整第一预设值,直至质差指标的阈值为调整后的第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为调整后的第二预设值的质差用户模型筛选质差用户准确率达到第三预设值,并将调整后的第一预设值作为质差指标的阈值,以及将调整后的第二预设值作为质差记录占观看记录的数量的比重的阈值。
其中,根据筛选出的质差指标以及设为第一预设值的质差指标的阈值构成的质差记录模型,确定每个预先得到的质差用户的每条观看记录的质差记录分布的标记的步骤,包括:
若预先得到的质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值匹配,则将该观看记录的质差记录分布的标记设为1;
若预先得到的质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值不匹配,则将该观看记录的质差记录分布的标记设为0。
其中,确定每个预先得到的质差用户的比值大于或等于第二预设值的步骤,包括:
判断预先得到的质差用户的比值是否大于或等于第二预设值;
若预先得到的质差用户的比值小于第二预设值,则调整第一预设值,直至预先得到的质差用户的比值大于或等于第二预设值。
本发明的实施例还提供了一种监测交互式网络电视iptv用户状态的装置,包括:
第一获取模块,用于获取各iptv用户的节目观看数据;其中,节目观看数据包括多条观看记录,每条观看记录包括多个第一数值型指标;
筛选模块,用于根据每个iptv用户的每条观看记录中的多个第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录;
确定模块,用于根据每个iptv用户的多条观看记录中的质差记录,确定出每个iptv用户的状态。
本发明的上述方案至少包括以下有益效果:
在本发明的实施例中,通过根据各iptv用户的多条观看记录中的第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录,并根据筛选出的质差记录,确定出每个iptv用户的状态,解决了运营商无法及时、准确的确定出iptv系统中的各用户的状态,使得在iptv系统中出现感知恶化的用户时,难以及时对iptv系统进行网络优化,影响用户体验的问题,达到了使运营商及时、准确的确定出iptv系统中的各用户的状态,且在iptv系统中出现感知恶化的用户时,能及时对iptv系统进行网络优化,提升用户体验的效果。
附图说明
图1为本发明第一实施例中监测交互式网络电视iptv用户状态的方法的流程图;
图2为本发明第一实施例中获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的流程图;
图3为本发明第一实施例中的具体实例中对质差用户进行精细化分析的流程图;
图4为本发明第一实施例中的具体实例中绘制的聚类结果谱系图;
图5为本发明第一实施例中的具体实例中绘制的多维标度图;
图6为本发明第二实施例中监测交互式网络电视iptv用户状态的装置的结构示意图;
图7为本发明第三实施例中iptv数据分析架构的示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
第一实施例
如图1所示,本发明的第一实施例提供了一种监测交互式网络电视iptv用户状态的方法,该方法包括:
步骤101,获取各iptv用户的节目观看数据。
其中,节目观看数据包括多条观看记录,每条观看记录包括多个第一数值型指标,且各第一数值型指标互不相同。具体的,该第一数值型指标可以为码率(avg-bit-rate)、组播缓冲下溢次数(multi-abend-numbers)、延时(df)、单播缓冲下溢次数(vod-abend-numbers)、丢包因子(mlr)、请求次数(req-numbers)、抖动(jitter)、切换时间(acc-avr-time)、可用率(can-use-rate)、单播申请失败总次数(vod-fail-numbers)、下溢次数(abend-numbers)、总的播放错误次数(play-error-numbers)、播放时长(play-time)或上溢次数(overflow-numbers)等。
步骤102,根据每个iptv用户的每条观看记录中的多个第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录。
其中,上述质差记录是指用户在观看节目的过程中,感觉节目质量恶化(例如卡顿花屏等)时的观看记录。
在本发明的第一实施例中,可通过检测iptv用户的每条观看记录中的多个第一数值型指标的数值,是否与质差记录模型中的质差指标的阈值匹配的方式,筛选出每个iptv用户的多条观看记录中的质差记录。具体的,若检测出iptv用户的观看记录中的多个第一数值型指标的数值与质差记录模型中的质差指标的阈值匹配,则确定该观看记录为质差记录。其中,质差记录模型为f1=f(q1′>φ1,q2′>φ2,...,qi′>φi),i=q′,其中,f1表示质差记录模型,q1′表示质差记录模型中的第一个质差指标,φ1表示第一个质差指标的阈值,q2′表示质差记录模型中的第二个质差指标,φ2表示第二个质差指标的阈值,qi′表示质差记录模型中的第i个质差指标,φi表示第i个质差指标的阈值,q′表示质差记录模型中质差指标的数量,f是指各质差指标进行组合排列的关系。
需要说明的是,质差记录模型中的各质差指标互不相同,且与第一数值型指标类似,可以为码率(avg-bit-rate)、组播缓冲下溢次数(multi-abend-numbers)、延时(df)、单播缓冲下溢次数(vod-abend-numbers)、丢包因子(mlr)、请求次数(req-numbers)、抖动(jitter)、切换时间(acc-avr-time)、可用率(can-use-rate)、单播申请失败总次数(vod-fail-numbers)、下溢次数(abend-numbers)、总的播放错误次数(play-error-numbers)、播放时长(play-time)或上溢次数(overflow-numbers)等。在此,以一具体例子进一步阐述上述步骤102,例如,质差记录模型中包括两个质差指标,分别为抖动(用q1′表示)和延时(用q2′表示),质差记录模型q1′>φ1表示抖动大于4,q2′>φ2表示延时大于10,此时,若iptv用户的观看记录中的多个第一数值型指标中的抖动的数值为5和延时的数值为12,则认为该条观看记录为质差记录。
步骤103,根据每个iptv用户的多条观看记录中的质差记录,确定出每个iptv用户的状态。
在本发明的第一实施例中,步骤103的具体实现方式为:首先根据iptv用户的多条观看记录中的质差记录,确定iptv用户的每条观看记录的质差记录分布的标记,具体可通过公式
其中,质差用户是指在观看节目的过程中,感觉节目质量恶化(例如卡顿花屏等)的iptv用户,相应的,非质差用户是指在观看节目的过程中,感觉节目质量优良的iptv用户。
需要说明的是,在本发明的第一实施例中,确定出的质差用户可以为卡顿花屏的质差用户,当然也可以是其他类型的质差用户。其确定出的质差用户类型主要取决于质差记录模型中各个质差指标的类型。具体的,若质差记录模型中各个质差指标是用于评判卡顿花屏的质差用户的,那么确定出的质差用户类型便为卡顿花屏的质差用户,类似的,若质差记录模型中各个质差指标是用于评判其他类型的质差用户的,那么确定出的质差用户类型便为其他类型的质差用户。
在本发明的第一实施例中,通过根据各iptv用户的多条观看记录中的第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录,并根据筛选出的质差记录,确定出每个iptv用户的状态,解决了运营商无法及时、准确的确定出iptv系统中的各用户的状态,使得在iptv系统中出现感知恶化的用户时,难以及时对iptv系统进行网络优化,影响用户体验的问题,达到了使运营商及时、准确的确定出iptv系统中的各用户的状态,且在iptv系统中出现感知恶化的用户时,能及时对iptv系统进行网络优化,提升用户体验的效果。
其中,在本发明的第一实施例中,在步骤102之前,上述方法还包括:根据预先得到的多个质差用户的观看记录所包含的多个第二数值型指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的步骤。
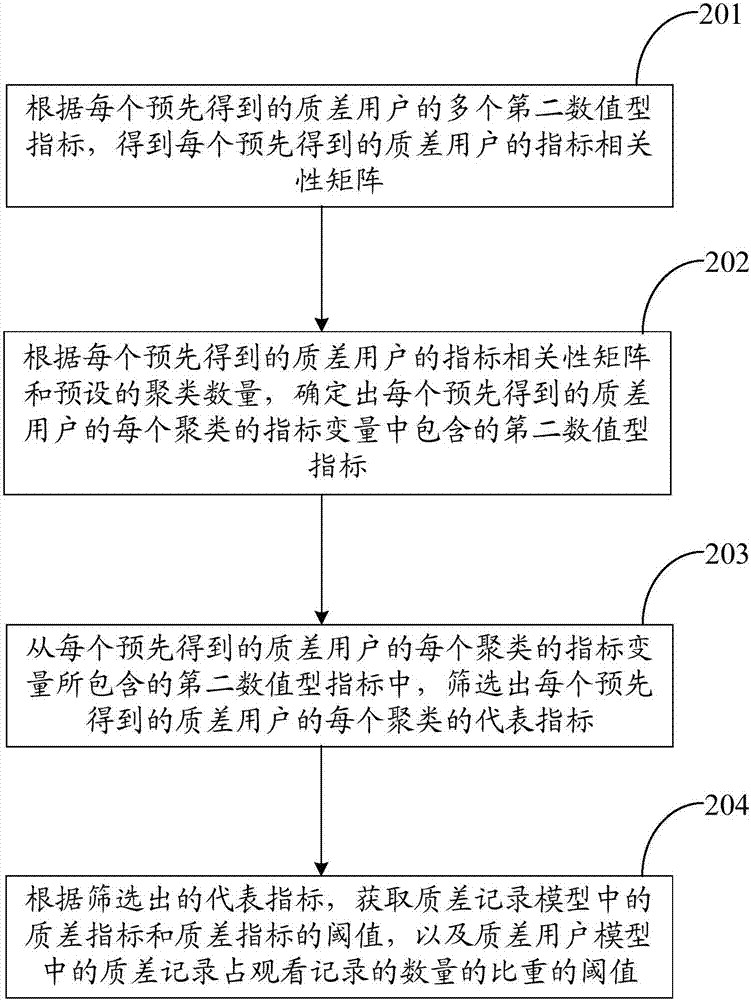
如图2所示,根据预先得到的多个质差用户的观看记录所包含的多个第二数值型指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的步骤包括:
步骤201,根据每个预先得到的质差用户的多个第二数值型指标,得到每个预先得到的质差用户的指标相关性矩阵。
其中,上述多个第二数值型指标互不相同,且与第一数值型指标类似,可以为码率(avg-bit-rate)、组播缓冲下溢次数(multi-abend-numbers)、延时(df)、单播缓冲下溢次数(vod-abend-numbers)、丢包因子(mlr)、请求次数(req-numbers)、抖动(jitter)、切换时间(acc-avr-time)、可用率(can-use-rate)、单播申请失败总次数(vod-fail-numbers)、下溢次数(abend-numbers)、总的播放错误次数(play-error-numbers)、播放时长(play-time)或上溢次数(overflow-numbers)等。
步骤202,根据每个预先得到的质差用户的指标相关性矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
步骤203,从每个预先得到的质差用户的每个聚类的指标变量所包含的第二数值型指标中,筛选出每个预先得到的质差用户的每个聚类的代表指标。
步骤204,根据筛选出的代表指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
可选的,在本发明的第一实施例中,上述步骤201的具体包括如下步骤:
第一步,对每个预先得到的质差用户的多个第二数值型指标进行标准化处理,得到每个预先得到的质差用户的多个标准化数值型指标。
具体的,可通过公式
第二步,计算每个预先得到的质差用户的每两个标准化数值型指标之间的相关性,得到每个预先得到的质差用户的指标相关性矩阵。
具体的,可通过公式
可选的,在本发明的第一实施例中,上述步骤202的具体包括如下步骤:
第一步,确定每个预先得到的质差用户的指标相关性矩阵中各行互不相同。
其中,第一步的具体实现方式为:判断指标相关性矩阵中是否存在相同的多个行(即,判断是否存在重复行),并若指标相关性矩阵中存在相同的多个行,则根据在操作界面接收到的删除指令,将多个行删除至一个行,并删除被删除行对应的第二数值型指标,使指标相关性矩阵中各行互不相同。其中,删除指令可由管理员根据自己的经验在操作界面输入,其直接指示删除哪些行。
第二步,根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的每两个第二数值型指标之间的相似性距离,得到每个预先得到的质差用户的相似性距离矩阵。
其中,可通过公式sij=1-rij计算得到每两个第二数值型指标之间的相似性距离,紧接着通过公式
第三步,通过r型聚类法,根据每个预先得到的质差用户的相似性距离矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,可具体通过r型离差平方和(ward)聚类法,根据每个预先得到的质差用户的相似性距离矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,ward法包括类中离差平方和距离计算公式和类间离差平方和距离计算公式。其中,类中离差平方和距离计算公式为:
需要说明的是,在确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标之后,上述方法还包括:根据每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标,绘制每个预先得到的质差用户的聚类结果谱系图,并展现绘制的聚类结果谱系图的步骤,从而便于管理员可快速、清楚的知道每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
需要进一步说明的是,在确定每个预先得到的质差用户的指标相关性矩阵中各行互不相同之后,上述方法还包括如下步骤:
第一步,通过多维标度法,根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的距离矩阵,并根据每个预先得到的质差用户的距离矩阵,绘制每个预先得到的质差用户的多维标度图。
其中,可通过公式
第二步,展现绘制的多维标度图,并根据在操作界面接收到的修改指令,修改每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
在本发明的第一实施例中,若管理员根据多维标度图,发现之前确定出的每个(或某个)预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标不准确的话,管理员可通过在操作界面输入修改指令的方式,修改每个(或某个)预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
可选的,在本发明的第一实施例中,上述步骤203的具体包括如下步骤:
第一步,给每个预先得到的质差用户的每个聚类的指标变量建立因子分析模型。
具体的,每个聚类的指标变量的
第二步,通过因子分析方法,根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型,得到每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵。
其中,第二步的具体实现方式为:首先计算每个聚类中各第二数值型指标间的相关系数矩阵rt,然后计算rt的特征值
第三步,根据预设的特征根的累计方差贡献率的阈值,以及每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵,确定出每个预先得到的质差用户的每个聚类的指标变量的公共因子数量。
其中,可选择
第四步,对每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵进行正交旋转,并根据每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,计算出每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度。
其中,首先可通过公式λ2=λ1(u)t对初等载荷矩阵进行正交旋转,λ2表示旋转后的初等载荷矩阵,其中λ1(u)为λ1前u列,t为正交矩阵,旋转后的载荷因子为
第五步,根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度,以及每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,给每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型。
其中,可通过公式
第六步,根据每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型,从每个预先得到的质差用户的每个聚类的指标变量包含的第二数值型指标中筛选出相关性贡献度最高的第二数值型指标,并将该第二数值型指标作为该聚类的代表指标。
可选的,在本发明的第一实施例中,上述步骤204的具体包括如下步骤:
第一步,根据每个预先得到的质差用户的每个聚类的代表指标,统计每个第二数值型指标被筛选为代表指标的次数。
第二步,根据统计得到的次数,按照次数从高至低的顺序,对被筛选为代表指标的第二数值型指标进行排序。
第三步,根据在操作界面接收到的选择指令,从被筛选为代表指标的第二数值型指标中筛选出质差记录模型中的质差指标。
其中,管理员可根据自己的经验输入选择指令,该选择指令指示选择能够反映网络状况的质差指标。
第四步,根据筛选出的质差指标,获取质差记录模型中质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,第四步的具体实现方式为:
首先,将质差记录模型中质差指标的阈值设为第一预设值(其中,若质差记录模型中包括多个质差指标,则每个质差指标都对应一个第一预设值,且各预设值可互不相同),并根据筛选出的质差指标以及设为第一预设值的质差指标的阈值构成的质差记录模型,确定每个预先得到的质差用户的每条观看记录的质差记录分布的标记。其中,若预先得到的质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值匹配,则将该观看记录的质差记录分布的标记设为1;若预先得到的质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值不匹配,则将该观看记录的质差记录分布的标记设为0;
其次,根据每个预先得到的质差用户的每条观看记录的质差记录分布的标记,统计每个预先得到的质差用户的质差记录数量,并根据每个预先得到的质差用户的质差记录数量,计算每个预先得到的质差用户的质差记录占每个预先得到的质差用户的观看记录的数量的比值;
其次,将质差用户模型中的质差记录占观看记录的数量的比重的阈值设为第二预设值,并确定每个预先得到的质差用户的比值大于或等于第二预设值。其中,确定每个预先得到的质差用户的比值大于或等于第二预设值的步骤包括:判断预先得到的质差用户的比值是否大于或等于第二预设值;若预先得到的质差用户的比值小于第二预设值,则调整第一预设值,直至预先得到的质差用户的比值大于或等于第二预设值。
其次,控制质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型从多个第一用户和/或多个第二用户中筛选出质差用户;其中,第一用户的类型为无质差用户,第二用户的类型为质差用户;
其次,获取质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型筛选质差用户的准确率,若准确率达到第三预设值(例如70%),则将第一预设值作为质差指标的阈值,并将第二预设值作为质差记录占观看记录的数量的比重的阈值;
其次,若准确率未达到第三预设值,则调整第二预设值的大小,并根据调整后的第二预设值,调整第一预设值,直至质差指标的阈值为调整后的第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为调整后的第二预设值的质差用户模型筛选质差用户准确率达到第三预设值,并将调整后的第一预设值作为质差指标的阈值,以及将调整后的第二预设值作为质差记录占观看记录的数量的比重的阈值。
在本发明的实施例中,以一具体实例进一步阐述上述获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值的步骤。
在该实例中,以卡顿花屏的质差用户为例,且以一个卡顿花屏的质差用户为例进行精细化分析,其中,该质差用户有32条观看记录,且该质差用户的第二数值型指标的维度为23。如图3所示,那么对该质差用户进行精细化分析的步骤如下:
步骤301,根据质差用户的多个第二数值型指标,得到指标相关性矩阵。
其中,上述多个第二数值型指标互不相同,且与第一数值型指标类似,可以为码率(avg-bit-rate)、组播缓冲下溢次数(multi-abend-numbers)、延时(df)、单播缓冲下溢次数(vod-abend-numbers)、丢包因子(mlr)、请求次数(req-numbers)、抖动(jitter)、切换时间(acc-avr-time)、可用率(can-use-rate)、单播申请失败总次数(vod-fail-numbers)、下溢次数(abend-numbers)、总的播放错误次数(play-error-numbers)、播放时长(play-time)或上溢次数(overflow-numbers)等。
步骤302,根据指标相关性矩阵和预设的聚类数量,确定出每个聚类的指标变量中包含的第二数值型指标。
步骤303,从每个聚类的指标变量所包含的第二数值型指标中,筛选出每个聚类的代表指标。
步骤304,根据筛选出的代表指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
可选的,在本发明的第一实施例中,上述步骤301的具体包括如下步骤:
第一步,对多个第二数值型指标进行标准化处理,得到多个标准化数值型指标。
具体的,可通过公式
第二步,计算每两个标准化数值型指标之间的相关性,得到指标相关性矩阵。
具体的,可通过公式
可选的,在本发明的第一实施例中,上述步骤302的具体包括如下步骤:
第一步,确定质差用户的指标相关性矩阵中各行互不相同。
其中,第一步的具体实现方式为:判断指标相关性矩阵中是否存在相同的多个行(即,判断是否存在重复行),并若指标相关性矩阵中存在相同的多个行,则根据在操作界面接收到的删除指令,将多个行删除至一个行,并删除被删除行对应的第二数值型指标,使指标相关性矩阵中各行互不相同。其中,删除指令可由管理员根据自己的经验在操作界面输入,其直接指示删除哪些行。
第二步,根据质差用户的指标相关性矩阵,计算质差用户的每两个第二数值型指标之间的相似性距离,得到质差用户的相似性距离矩阵。
其中,可通过公式sij=1-rij计算得到每两个第二数值型指标之间的相似性距离,紧接着通过公式
第三步,通过r型聚类法,根据质差用户的相似性距离矩阵和预设的聚类数量,确定出质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,可具体通过r型离差平方和(ward)聚类法,根据质差用户的相似性距离矩阵和预设的聚类数量(例如5),确定出质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,ward法包括类中离差平方和距离计算公式和类间离差平方和距离计算公式。其中,类中离差平方和距离计算公式为:
需要说明的是,在确定出质差用户的每个聚类的指标变量中包含的第二数值型指标之后,上述方法还包括:根据质差用户的每个聚类的指标变量中包含的第二数值型指标,绘制质差用户的聚类结果谱系图,并展现绘制的聚类结果谱系图的步骤,从而便于管理员可快速、清楚的知道质差用户的每个聚类的指标变量中包含的第二数值型指标。其中,绘制的聚类结果谱系图如图4所示,图4中横坐标轴中的1表示avg-bit-rate,2表示df,3表示multi-abend-numbers,4表示jitter,5表示can-use-rate,6表示abend-numbers,7表示play-time,8表示vod-abend-numbers,9表示req-numbers,10表示acc-avr-time,11表示vod-fail-numbers,12表示play-error-numbers,13表示mlr,14表示overflow-numbers。且从图4中可看出,abend-numbers、vod-abend-numbers、multi-abend-numbers可分为第一类;play-error-numbers、mlr可分为第二类;avg-bit-rate、df、jitter可分为第三类;overflow-numbers单独可分为第四类,req-numbers等剩余第二数值型指标可分为第五类。
需要进一步说明的是,在确定质差用户的指标相关性矩阵中各行互不相同之后,上述方法还包括如下步骤:
第一步,通过多维标度法,根据质差用户的指标相关性矩阵,计算质差用户的距离矩阵,并根据质差用户的距离矩阵,绘制质差用户的多维标度图。
其中,可通过公式
第二步,展现绘制的多维标度图,并根据在操作界面接收到的修改指令,修改质差用户的每个聚类的指标变量中包含的第二数值型指标。
在本发明的第一实施例中,若管理员根据多维标度图,发现之前确定出的质差用户的每个聚类的指标变量中包含的第二数值型指标不准确的话,管理员可通过在操作界面输入修改指令的方式,修改质差用户的每个聚类的指标变量中包含的第二数值型指标。
可选的,在本发明的第一实施例中,上述步骤303的具体包括如下步骤:
第一步,给质差用户的每个聚类的指标变量建立因子分析模型。
具体的,每个聚类的指标变量的
第二步,通过因子分析方法,根据质差用户的每个聚类的指标变量的因子分析模型,得到质差用户的每个聚类的指标变量的初等载荷矩阵。
其中,第二步的具体实现方式为:首先计算每个聚类中各第二数值型指标间的相关系数矩阵rt,然后计算rt的特征值
第三步,根据预设的特征根的累计方差贡献率的阈值,以及质差用户的每个聚类的指标变量的初等载荷矩阵,确定出质差用户的每个聚类的指标变量的公共因子数量。
其中,可选择
第四步,对质差用户的每个聚类的指标变量的初等载荷矩阵进行正交旋转,并根据质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,计算出质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度。
其中,首先可通过公式λ2=λ1(u)t对初等载荷矩阵进行正交旋转,λ2表示旋转后的初等载荷矩阵,其中λ1(u)为λ1前u列,t为正交矩阵,旋转后的载荷因子为
第五步,根据质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度,以及质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,给质差用户的每个聚类的指标变量建立相关性贡献度模型。
其中,可通过公式
第六步,根据质差用户的每个聚类的指标变量建立相关性贡献度模型,从质差用户的每个聚类的指标变量包含的第二数值型指标中筛选出相关性贡献度最高的第二数值型指标,并将该第二数值型指标作为该聚类的代表指标。
可选的,在本发明的第一实施例中,上述步骤304的具体包括如下步骤:
第一步,根据质差用户的每个聚类的代表指标,统计每个第二数值型指标被筛选为代表指标的次数。
第二步,根据统计得到的次数,按照次数从高至低的顺序,对被筛选为代表指标的第二数值型指标进行排序。
第三步,根据在操作界面接收到的选择指令,从被筛选为代表指标的第二数值型指标中筛选出质差记录模型中的质差指标。
其中,管理员可根据自己的经验输入选择指令,该选择指令指示选择能够反映网络状况的质差指标。
第四步,根据筛选出的质差指标,获取质差记录模型中质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,第四步的具体实现方式为:
首先,将质差记录模型中质差指标的阈值设为第一预设值(其中,若质差记录模型中包括多个质差指标,则每个质差指标都对应一个第一预设值,且各预设值可互不相同),并根据筛选出的质差指标以及设为第一预设值的质差指标的阈值构成的质差记录模型,确定质差用户的每条观看记录的质差记录分布的标记。其中,若质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值匹配,则将该观看记录的质差记录分布的标记设为1;若质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值不匹配,则将该观看记录的质差记录分布的标记设为0;
其次,根据质差用户的每条观看记录的质差记录分布的标记,统计质差用户的质差记录数量,并根据质差用户的质差记录数量,计算质差用户的质差记录占质差用户的观看记录的数量的比值;
其次,将质差用户模型中的质差记录占观看记录的数量的比重的阈值设为第二预设值,并确定质差用户的比值大于或等于第二预设值。其中,确定质差用户的比值大于或等于第二预设值的步骤包括:判断质差用户的比值是否大于或等于第二预设值;若质差用户的比值小于第二预设值,则调整第一预设值,直至质差用户的比值大于或等于第二预设值。
其次,控制质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型从多个第一用户和/或多个第二用户中筛选出质差用户;其中,第一用户的类型为无质差用户,第二用户的类型为质差用户;
其次,获取质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型筛选质差用户的准确率,若准确率达到第三预设值(例如70%),则将第一预设值作为质差指标的阈值,并将第二预设值作为质差记录占观看记录的数量的比重的阈值;
其次,若准确率未达到第三预设值,则调整第二预设值的大小,并根据调整后的第二预设值,调整第一预设值,直至质差指标的阈值为调整后的第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为调整后的第二预设值的质差用户模型筛选质差用户准确率达到第三预设值,并将调整后的第一预设值作为质差指标的阈值,以及将调整后的第二预设值作为质差记录占观看记录的数量的比重的阈值。
需要说明的是,在本发明的第一实施例中,使用本发明的方法对5465个无质差用户进行判断筛选时,误判率仅为6.8%,但对59个卡顿花屏的质差用户的预测准确率高达66.1%。此外,本发明的方法不仅通过多维标度法、r型ward聚类法实现对用户观看记录数据的高维指标进行联合聚类,还通过逆向因子分析法从指标中选举出代表指标以实现有效降维。统计代表指标并筛选出质差指标后,根据质差指标排列组合建立质差记录模型和质差用户模型,并不断迭代优化质差记录模型和质差用户模型的参数(即质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值),使其准确率与误判率满足要求。
第二实施例
如图6所示,本发明的第二实施例提供了一种监测交互式网络电视iptv用户状态的装置,包括:
第一获取模块601,用于获取各iptv用户的节目观看数据;其中,节目观看数据包括多条观看记录,每条观看记录包括多个第一数值型指标;
筛选模块602,用于根据每个iptv用户的每条观看记录中的多个第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录;
确定模块603,用于根据每个iptv用户的多条观看记录中的质差记录,确定出每个iptv用户的状态。
其中,筛选模块602包括:
第一筛选单元,用于检测iptv用户的每条观看记录中的多个第一数值型指标的数值,是否与质差记录模型中的质差指标的阈值匹配,并若iptv用户的观看记录中的多个第一数值型指标的数值与质差记录模型中的质差指标的阈值匹配,则触发第二筛选单元;
第二筛选单元,用于根据第一筛选单元的触发,确定该观看记录为质差记录。
其中,质差记录模型为f1=f(q1′>φ1,q2′>φ2,...,qi′>φi),i=q′,其中,f1表示质差记录模型,q1′表示质差记录模型中的第一个质差指标,φ1表示第一个质差指标的阈值,q2′表示质差记录模型中的第二个质差指标,φ2表示第二个质差指标的阈值,qi′表示质差记录模型中的第i个质差指标,φi表示第i个质差指标的阈值,q′表示质差记录模型中质差指标的数量。
其中,确定模块603包括:
第三筛选单元,用于根据iptv用户的多条观看记录中的质差记录,确定iptv用户的每条观看记录的质差记录分布的标记;
第四筛选单元,用于根据iptv用户的每条观看记录的质差记录分布的标记,通过质差用户模型
第五筛选单元,用于若f2的值为1,则确定该iptv用户为质差用户;若f2的值为0,则确定该iptv用户为非质差用户。
其中,
第三筛选单元,还用于通过公式
其中,装置还包括:
第二获取模块,用于根据预先得到的多个质差用户的观看记录所包含的多个第二数值型指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,在本发明的第二实施例中,上述第二获取模块的功能可通过一iptv分析系统实现。
其中,第二获取模块包括:
第一获取单元,用于根据每个预先得到的质差用户的多个第二数值型指标,得到每个预先得到的质差用户的指标相关性矩阵;
第二获取单元,用于根据每个预先得到的质差用户的指标相关性矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标;
第三获取单元,用于从每个预先得到的质差用户的每个聚类的指标变量所包含的第二数值型指标中,筛选出每个预先得到的质差用户的每个聚类的代表指标;
第四获取单元,用于根据筛选出的代表指标,获取质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,第一获取单元包括:
第一获取子单元,用于对每个预先得到的质差用户的多个第二数值型指标进行标准化处理,得到每个预先得到的质差用户的多个标准化数值型指标;
第二获取子单元,用于计算每个预先得到的质差用户的每两个标准化数值型指标之间的相关性,得到每个预先得到的质差用户的指标相关性矩阵。
其中,
第一获取子单元,还用于通过公式
其中,
第二获取子单元,还用于通过公式
第二获取子单元,还用于通过公式r=(rij)计算得到每个预先得到的质差用户的指标相关性矩阵;其中,r表示预先得到的质差用户的指标相关性矩阵。
其中,第二获取单元包括:
第三获取子单元,用于确定每个预先得到的质差用户的指标相关性矩阵中各行互不相同;
第四获取子单元,用于根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的每两个第二数值型指标之间的相似性距离,得到每个预先得到的质差用户的相似性距离矩阵;
第五获取子单元,用于通过r型聚类法,根据每个预先得到的质差用户的相似性距离矩阵和预设的聚类数量,确定出每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,
第四获取子单元,还用于通过公式sij=1-rij计算得到每两个第二数值型指标之间的相似性距离;其中,sij表示第i个第二数值型指标与第j个第二数值型指标之间的相似性距离;
第四获取子单元,还用于通过公式
其中,装置还包括:
第一绘制模块,用于根据每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标,绘制每个预先得到的质差用户的聚类结果谱系图,并展现绘制的聚类结果谱系图。
其中,
第三获取子单元,还用于判断指标相关性矩阵中是否存在相同的多个行,并若指标相关性矩阵中存在相同的多个行,则根据在操作界面接收到的删除指令,将多个行删除至一个行,并删除被删除行对应的第二数值型指标,使指标相关性矩阵中各行互不相同。
其中,装置还包括:
第二绘制模块,用于通过多维标度法,根据每个预先得到的质差用户的指标相关性矩阵,计算每个预先得到的质差用户的距离矩阵,并根据每个预先得到的质差用户的距离矩阵,绘制每个预先得到的质差用户的多维标度图;
修改模块,用于展现绘制的多维标度图,并根据在操作界面接收到的修改指令,修改每个预先得到的质差用户的每个聚类的指标变量中包含的第二数值型指标。
其中,第二绘制模块包括:
第一绘制单元,用于通过公式
第二绘制单元,用于通过公式h=(hij)计算得到预先得到的质差用户的距离矩阵;其中,h表示预先得到的质差用户的距离矩阵。
其中,第三获取单元包括:
第六获取子单元,用于给每个预先得到的质差用户的每个聚类的指标变量建立因子分析模型;
第七获取子单元,用于通过因子分析方法,根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型,得到每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵;
第八获取子单元,用于根据预设的特征根的累计方差贡献率的阈值,以及每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵,确定出每个预先得到的质差用户的每个聚类的指标变量的公共因子数量;
第九获取子单元,用于对每个预先得到的质差用户的每个聚类的指标变量的初等载荷矩阵进行正交旋转,并根据每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,计算出每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度;
第十获取子单元,用于根据每个预先得到的质差用户的每个聚类的指标变量的因子分析模型中各公共因子的方差贡献度,以及每个预先得到的质差用户的每个聚类的指标变量的旋转后的初等载荷矩阵中的载荷因子,给每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型;
第十一获取子单元,用于根据每个预先得到的质差用户的每个聚类的指标变量建立相关性贡献度模型,从每个预先得到的质差用户的每个聚类的指标变量包含的第二数值型指标中筛选出相关性贡献度最高的第二数值型指标,并将该第二数值型指标作为该聚类的代表指标。
其中,
第十获取子单元,还用于通过公式
第十获取子单元,还用于通过公式
其中,第四获取单元包括:
第十二获取子单元,用于根据每个预先得到的质差用户的每个聚类的代表指标,统计每个第二数值型指标被筛选为代表指标的次数;
第十三获取子单元,用于根据统计得到的次数,按照次数从高至低的顺序,对被筛选为代表指标的第二数值型指标进行排序;
第十四获取子单元,用于根据在操作界面接收到的选择指令,从被筛选为代表指标的第二数值型指标中筛选出质差记录模型中的质差指标;
第十五获取子单元,用于根据筛选出的质差指标,获取质差记录模型中质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
其中,
第十五获取子单元,还用于将质差记录模型中质差指标的阈值设为第一预设值,并根据筛选出的质差指标以及设为第一预设值的质差指标的阈值构成的质差记录模型,确定每个预先得到的质差用户的每条观看记录的质差记录分布的标记;
第十五获取子单元,还用于根据每个预先得到的质差用户的每条观看记录的质差记录分布的标记,统计每个预先得到的质差用户的质差记录数量,并根据每个预先得到的质差用户的质差记录数量,计算每个预先得到的质差用户的质差记录占每个预先得到的质差用户的观看记录的数量的比值;
第十五获取子单元,还用于将质差用户模型中的质差记录占观看记录的数量的比重的阈值设为第二预设值,并确定每个预先得到的质差用户的比值大于或等于第二预设值;
第十五获取子单元,还用于控制质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型从多个第一用户和/或多个第二用户中筛选出质差用户;其中,第一用户的类型为无质差用户,第二用户的类型为质差用户;
第十五获取子单元,还用于获取质差指标的阈值为第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为第二预设值的质差用户模型筛选质差用户的准确率,若准确率达到第三预设值,则将第一预设值作为质差指标的阈值,并将第二预设值作为质差记录占观看记录的数量的比重的阈值;
第十五获取子单元,还用于若准确率未达到第三预设值,则调整第二预设值的大小,并根据调整后的第二预设值,调整第一预设值,直至质差指标的阈值为调整后的第一预设值的质差记录模型,以及质差记录占观看记录的数量的比重的阈值设为调整后的第二预设值的质差用户模型筛选质差用户准确率达到第三预设值,并将调整后的第一预设值作为质差指标的阈值,以及将调整后的第二预设值作为质差记录占观看记录的数量的比重的阈值。
其中,
第十五获取子单元,还用于若预先得到的质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值匹配,则将该观看记录的质差记录分布的标记设为1;
第十五获取子单元,还用于若预先得到的质差用户的观看记录中的第二数值型指标的数值,与质差记录模型中设为第一预设值的质差指标的阈值不匹配,则将该观看记录的质差记录分布的标记设为0。
其中,
第十五获取子单元,还用于判断预先得到的质差用户的比值是否大于或等于第二预设值,并若预先得到的质差用户的比值小于第二预设值,则调整第一预设值,直至预先得到的质差用户的比值大于或等于第二预设值。
在本发明的第二实施例中,通过根据各iptv用户的多条观看记录中的第一数值型指标,筛选出每个iptv用户的多条观看记录中的质差记录,并根据筛选出的质差记录,确定出每个iptv用户的状态,解决了运营商无法及时、准确的确定出iptv系统中的各用户的状态,使得在iptv系统中出现感知恶化的用户时,难以及时对iptv系统进行网络优化,影响用户体验的问题,达到了使运营商及时、准确的确定出iptv系统中的各用户的状态,且在iptv系统中出现感知恶化的用户时,能及时对iptv系统进行网络优化,提升用户体验的效果。
需要说明的是,本发明第二实施例提供的监测交互式网络电视iptv用户状态的装置是应用上述监测交互式网络电视iptv用户状态的方法的装置,即上述方法的所有实施例均适用于该装置,且均能达到相同或相似的有益效果。
第三实施例
如图7所示,本发明的第三实施例提供了一种iptv数据分析架构,包括:数据获取模块701、探针模块702、iptv服务质量保障系统(iqas)以及iptv分析系统704。其中,数据获取模块701用于抓取质差用户观看节目时的网络包,其可通过一libpacp模块实现;探针模块702用于解析所抓取的网络包,并上报给iqas703,使得iptv分析系统704可从iqas703中获取质差用户的数据进行分析,确定出质差记录模型中的质差指标和质差指标的阈值,以及质差用户模型中的质差记录占观看记录的数量的比重的阈值。
以上是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!