一种提前确定HEVC合并和跳过编码模式的方法与流程
本发明属于视频图像压缩编码技术领域,具体涉及一种提前确定HEVC合并和跳过编码模式的方法。
背景技术:
高效率视频编码(High Efficiency Video Coding,HEVC)以编码树单元(Coding Tree Unit,CTU)为基本处理单元,一个CTU可以只包含一个编码单元(Coding Unit,CU)或者以四叉树的形式向下划分成四个大小相等的CU。进一步地,每个大小为2N×2N(N可为8、16、32)的CU可以继续划分成四个大小都为N×N的CU。在整个四叉树形式的CTU划分结构中,作为叶子节点的CU给出了CTU中某个正方形区域的预测模式,即:帧内(Intra)、帧间(Inter)、略过(Skip)或者合并(Merge)模式。取决于预测模式,CU可以划分成一个、二个或四个预测单元(Prediction Unit,PU)。对帧内编码,有两种可选的PU划分方式;对帧间编码,有八种可选的PU划分方式;对合并模式,则只有一种PU划分方式。
合并模式是HEVC新引入的一种模式,当一个预测单元被编码成合并模式,则它和与其空间或时间相邻的块共享相同的运动信息,从而能有效地减少花费在编码运动信息方面所需的码率代价。HEVC将Skip模式视作Merge模式的一个特例,在这种模式下,只有Skip标志和相应的合并块索引被编码。
HEVC编码器以穷举的方式确定CU划分结构、预测模式和PU划分方式,对于帧间编码CU,编码器按预设的顺序依次测试Skip/Merge模式、不作PU划分、上下或左右划分等情况下的率失真代价,以最小化率失真代价函数为目标确定上述项目。
HEVC能取得比H.264等早先的视频压缩标准更好的编码效率和性能,主要原因在于它采用了上述复杂的编码单元、预测单元和变换单元划分结构,以及以穷举的方式求解不同划分结构和编码模式时的率失真函数最优解。然而,“测试所有的可能性,选择其中最优的”这样一种编码框架同时引入了非常大的计算代价。根据前述的测试顺序,对于某个最终以Skip或者Merge模式编码的CU,若能在完成Skip/Merge模式下的率失真代价计算后即能提早判定Skip/Merge模式为该编码单元的最佳编码模式,则后续的帧间模式、帧内模式和CU递归划分过程等都可以省略,从而极大地减少编码器的计算复杂度。
为了减少编码器花费在模式决策上的计算代价,文献[1]“Early Merge Mode Decision Based on Motion Estimation and Hierarchical Depth Correlation for HEVC”(Pan等,IEEE Trans.Broadcasting,2014.2)公开了一种提早确定编码单元的编码模式为合并模式的方法,将编码单元划分成两大类:层次深度为0的根编码单元和层次大于0的子编码单元。对根编码单元,根据全零块信息和运动估计信息来决定是否提早确定其为合并模式,对于子编码单元则利用根编码单元和子编码单元之间的相关性提早确定合并模式是否为最优模式。文献[2]“A Novel Fast CU Encoding Scheme Based on Spatiotemporal Encoding Parameters for HEVC Inter Coding”(Ahn等,IEEE Trans.Circuits Syst.Video Technol.,2015.3)公开了一种提早确定编码单元为Skip模式和快速确定当前编码单元是否需要继续向下划分的方法。
技术实现要素:
本发明提供了一种提前确定HEVC合并和跳过编码模式的方法,用以减少HEVC编码器花费在确定编码树单元的划分结构和编码模式上的计算代价,从而降低HEVC编码器的计算复杂度。
一种提前确定HEVC合并和跳过编码模式的方法,如下:
对于当前编码单元,通过计算确定其在合并模式下的最佳候选运动参数,并记录该最佳候选运动参数对应的率失真代价Jmerge以及预测残差绝对值之和Smerge;同理通过计算确定其在跳过模式下的最佳候选运动参数,并记录该最佳候选运动参数对应的率失真代价Jskip以及预测残差绝对值之和Sskip;
判断以下条件:Jskip<Jmerge且Sskip<Tskip,Tskip为对应当前QP和N的阈值;
若成立,则提前判定当前编码单元的编码模式为跳过模式,并使其跳过后续的预测单元划分以及其它编码模式的率失真代价测试;
若不成立,则进一步判断以下条件:Smerge<Tmerge,Tmerge为对应当前QP和N的阈值;QP为量化参数,N为编码单元的尺寸;
若是,则提前判定当前编码单元的编码模式为合并模式,并使其跳过后续的预测单元划分以及其它编码模式的率失真代价测试;
若否,则使当前编码单元继续HEVC编码标准规定后续的预测单元划分以及其它编码模式的率失真代价测试。
所述步骤(1)的具体实现过程为:首先确定当前编码单元在合并模式下的候选运动参数集合,该候选运动参数集合由与当前编码单元空间或时间相邻且已编码的各预测单元的运动参数组成;然后在合并模式下计算各候选运动参数对应的运动补偿图像和预测残差,并通过对预测残差进行二维离散余弦变换和量化处理计算出各候选运动参数对应的率失真代价和预测残差绝对值之和,以最小化率失真代价为准则从候选运动参数集合中选取最佳的候选运动参数,并记录该最佳候选运动参数对应的率失真代价Jmerge以及预测残差绝对值之和Smerge;
同理确定当前编码单元在跳过模式下的候选运动参数集合,该候选运动参数集合由与当前编码单元空间或时间相邻且已编码的各预测单元的运动参数组成;然后在跳过模式下计算各候选运动参数对应的运动补偿图像和预测残差,并通过对预测残差进行二维离散余弦变换和量化处理计算出各候选运动参数对应的率失真代价和预测残差绝对值之和,以最小化率失真代价为准则从候选运动参数集合中选取最佳的候选运动参数,并记录该最佳候选运动参数对应的率失真代价Jskip以及预测残差绝对值之和Sskip。
所述阈值Tskip的确定方法如下:
首先以设定的量化参数QP,采用HEVC编码器对输入的测试视频进行编码,对于所有N×N大小的编码单元,记录其中以跳过模式编码的编码单元对应的预测残差绝对值之和,组成观测样本集合{K+};记录其中以非跳过模式编码的编码单元对应的预测残差绝对值之和,组成观测样本集合{K-};
取满足以下条件前提下预测残差绝对值之和Si的最小值作为阈值Tskip;
p(Si|K-)P(K-)>p(Si|K+)P(K+)
其中:Si为第i个编码单元对应的预测残差绝对值之和,p(Si|K+)表示Si相对于观测样本集合{K+}的分布密度,p(Si|K-)表示Si相对于观测样本集合{K-}的分布密度,P(K+)为以跳过模式编码的编码单元在所有N×N大小的编码单元中所占的比例,P(K-)为以非跳过模式编码的编码单元在所有N×N大小的编码单元中所占的比例且P(K-)=1-P(K+),i为自然数且1≤i≤m,m为所有N×N大小的编码单元数量;
依据上述,遍历所有可能的量化参数QP以及尺寸N,得到每一组确定的QP和N对应的阈值Tskip。
所述阈值Tmerge的确定方法如下:
首先以设定的量化参数QP,采用HEVC编码器对输入的测试视频进行编码,对于所有N×N大小的编码单元,记录其中以合并模式编码的编码单元对应的预测残差绝对值之和,组成观测样本集合{M+};记录其中以非合并模式编码的编码单元对应的预测残差绝对值之和,组成观测样本集合{M-};
取满足以下条件前提下预测残差绝对值之和Si的最小值作为阈值Tmerge;
p(Si|M-)P(M-)>p(Si|M+)P(M+)
其中:Si为第i个编码单元对应的预测残差绝对值之和,p(Si|M+)表示Si相对于观测样本集合{M+}的分布密度,p(Si|M-)表示Si相对于观测样本集合{M-}的分布密度,P(M+)为以合并模式编码的编码单元在所有N×N大小的编码单元中所占的比例,P(M-)为以非合并模式编码的编码单元在所有N×N大小的编码单元中所占的比例且P(M-)=1-P(M+),i为自然数且1≤i≤m,m为所有N×N大小的编码单元数量;
依据上述,遍历所有可能的量化参数QP以及尺寸N,得到每一组确定的QP和N对应的阈值Tmerge。
所述的预测残差绝对值之和Si相对于观测样本集合{L}的分布密度p(Si|L)的计算方法如下,其中L=K+、K-、M+或M-;
首先,确定观测样本集合{L}的各分界点A0,A1,…,Am+1,其中A0=0,Ai-Ai-1=d,Am+1大于等于观测样本集合{L}中的最大值且小于该最大值+d;d为预设的组距;
然后,根据以下公式计算分布密度p(Si|L):
其中:Ci为观测样本集合{L}中落在区间[Ai,Ai+1)的样本数目。
所述量化参数QP的取值范围为0~51的整数,所述编码单元的尺寸N=8、16、32或64。
本发明在测试了编码单元以Skip和Merge模式编码后,如果较优的模式对应的编码块残差绝对值之和小于一个预设的阈值,则忽略HEVC标准后续的Inter和Intra模式,以及预测单元划分过程,提前确定编码块的编码模式为Skip和Merge中的较优者,从而能以较少的性能损失换取HEVC编码器计算复杂度的极大降低。
附图说明
图1为本发明提前确定HEVC合并和跳过编码模式的方法流程示意图。
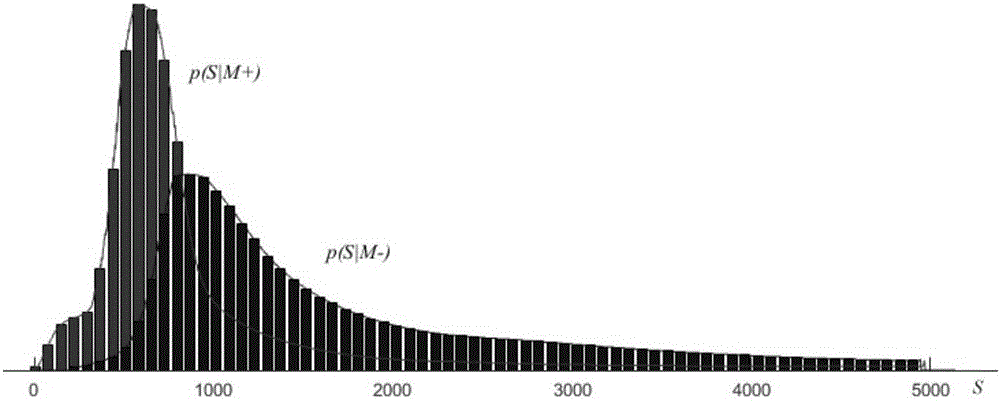
图2为16×16编码块的预测残差绝对值之和的条件概率密度分布示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
如图1所示,本发明提前确定HEVC合并和跳过编码模式的方法流程可以包括:
步骤101,对于输入的编码单元,计算当前编码单元在合并模式下对应最佳候选运动参数的率失真代价,记录编码单元的残差绝对值之和。具体地,候选的运动参数分别来自于与当前预测单元在空间和时间域相邻的预测单元,编码器分别计算对应各个候选运动参数的运动补偿图像和预测残差,对预测残差进行二维离散余弦变换和量化处理,计算如下的率失真代价:
J=D+λR
其中:D是以原始图像和重建图像之间的误差表示的编码失真,R是表示当前编码块所需的比特数,λ是由量化参数QP确定的乘数。编码器以最小化率失真代价函数J为准则,从候选集合中选取最佳的运动参数,记对应的率失真代价为合并模式下的率失真代价Jmerge,且记录对应的经运动补偿后的预测残差绝对值之和为Smerge。
步骤102,计算当前编码单元在SKIP模式下的率失真代价Jskip,且计算和记录对应的预测残差绝对值之和Sskip。
步骤103,判断Jskip<Jmerge?若是,则执行步骤104,否则转步骤105。
步骤104,判断块内残差绝对值之和Sskip是否小于一个预设的阈值Tskip,Sskip<Tskip?若是,转步骤106,否则继续步骤105的条件测试。
步骤105,判断块内残差绝对值之和Smerge是否小于一个预设的阈值Tmerge,Smerge<Tmerge?若是,则转步骤107,否则转108。
步骤106,对被步骤104判定为符合条件Sskip<Tskip的编码单元,跳过后续的PU划分和其它编码模式的率失真代价测试,提前判定该编码单元的编码模式为SKIP。
步骤107,对被步骤105判定为符合条件Smerge<Tmerge的编码单元,跳过后续的PU划分和其它编码模式的率失真代价测试,提早判定该编码单元的编码模式为MERGE。
步骤108,对于不符合步骤104和105条件的编码块,进行后续的PU块划分和INTER、INTRA模式下的率失真代价测试,确定最佳的PU划分结构、编码模式和对应的率失真代价。
上述方法中,步骤105所述的阈值Tmerge以学习的方法确定,具体地,N×N大小的编码单元,对每一个可能的QP值有一个对应的阈值,这些阈值保存在一个以N和QP值为索引的表格中。
计算表格中的一个表项的方法为:以相应的QP值,采用HEVC编码器对输入的测试视频进行编码,将N×N大小的编码单元的编码模式视作随机事件,且将事件的样本空间设为:{CU以MERGE模式编码,CU以非MERGE模式编码}。记CU以MERGE模式编码为事件M+,CU以非MERGE模式编码为事件M-。在编码器的编码过程中容易得到以MERGE模式编码的那些CU的块内残差绝对值之和的分布,以及以非MERGE模式编码的那些CU的块内残差绝对值之和的分布,分别记p(S|M+)和p(S|M-)为上述两类事件S值的条件概率密度;计算S值相对于总体的条件概率密度,如下:
首先,对样本集合{L}中的观测样本进行排序,以预设的组距d确定每组的分界点A0,A1,...,AK,其中A0=0,Ai-Ai-1=d,AK大于等于样本集合中的最大值且小于该最大值加上组距的和值;
统计样本集合{L}中落在每组区间[Ai,Ai+1)的样本数目,记作Ci;
按下式计算样本对应总体的密度分布:
其中:L代表类别M+和M-中的一个;图2所示了HEVC参考模型编码器对大量测试视频实验所得的16×16编码块的S值的条件概率密度。
由贝叶斯公式,编码块的两个状态M+和M-的后验概率为:
其中:P(M+)和P(M-)分别是状态M+和M-的先验概率,P(S)是一个用于归一化的因子;通过统计以合并模式编码的编码单元在所有N×N大小的编码单元中所占的比例计算P(M+),按下式计算P(M-):
P(M-)=1-P(M+)
采用基于最小错误率的贝叶斯决策规则:如果下式成立,则把预测残差绝对值之和为S的编码块的编码模式判定为MERGE。
p(S|M+)P(M+)>p(S|M-)P(M-)
由参考模型编码器对测试视频实验所得的N×N编码块以MERGE模式和非MERGE模式编码的编码块的S值的条件概率密度,及先验概率P(M+)和P(M-),取满足下式的最小的S值作为阈值Tmerge。
p(Si|M-)P(M-)>p(Si|M+)P(M+)
与Tmerge的求取类似,可得阈值Tskip。
量化参数QP的取值范围为0到51的整数,N可为8、16、32或64。对每个可能的QP值,N×N大小的编码单元对应两个阈值Tskip和Tmerge,这些阈值被保存在两个表格中,它们分别以N和QP为索引,一个保存对应的Tskip,另一个保存对应的Tmerge。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!