直播客户端语音处理系统及其处理方法与流程
本发明涉及直播平台技术领域,具体涉及一种直播客户端语音处理系统及其处理方法。
背景技术:
随着智能终端的多屏化发展,人们对“即时”与“互动”的需求越来越高。中国社交视频的直播社区的活跃用户正在不断发展壮大中。巨大的市场同时也面临着如火如荼的同行竞争,如何增强主播与用户之间的互动,吸引用户的关注,从而减少用户的流失,是直播行业很长一段时间将要面临的一道难题。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的在于提供一种增强主播与用户之间互动的直播客户端语音处理系统。
为达到以上目的,本发明采取的技术方案是:一种直播客户端语音处理系统,包括:
声音采集模块,其用于采集用户输入的语音;
特效加载模块,其用于加载特效文件;
音频混音模块,其用于接收所述声音采集模块输出的语音和特效加载模块加载的特效文件,并对所述声音采集模块输出的语音和特效加载模块加载的特效文件采样,并得到采样数据,所述音频混音模块还将所述采样数据进行叠加混合得到混合音频数据;以及
音频输出模块,其用于接收并发送所述混合音频数据至声音播放设备。
在上述技术方案的基础上,所述声音采集模块还包括变调开关和硬件处理模块,所述变调开关用于开启和关闭变调功能,所述硬件处理模块用于判断所述直播客户端语音处理系统是否支持硬件处理变调,所述直播客户端语音处理系统还包括系统API和软件API以及调用所述系统API或软件API进行变调处理的调用模块;若所述变调开关关闭变调功能,所述音频混音模块接收所述语音;若所述变调开关开启变调功能,则所述硬件处理模块进一步判断所述直播客户端语音处理系统是否支持硬件处理变调,若是则所述调用模块调用所述系统API进行变调处理;若否则所述调用模块调用软件API进行变调处理。
在上述技术方案的基础上,所述特效加载模块加载多路特效文件,所述音频混音模块包括多路开关,所述多路开关用于开启和关闭所述声音采集模块输出的语音和每一路特效文件的输入;所述音频混音模块还包括归一化模块,所述归一化模块用于将所述声音采集模块输出的语音的采样率和每一路特效文件的采样率转换为相同,所述音频混音模块还包括通道加权模块,所述通道加权模块用于调节所述声音采集模块输出的语音的增益大小和每一路特效文件的增益大小,并通过加权法得到所述混合音频数据。
在上述技术方案的基础上,所述音频输出模块还包括音频限幅模块,所述音频限幅模块用于限制所述混合音频数据的幅度。
与此同时,本发明还提供一种增强主播与用户之间互动的处理语音的方法。
为达到以上目的,本发明采取的技术方案是:一种利用上述直播客户端语音处理系统处理语音的方法,包括以下步骤:
声音采集模块采集用户输入的语音,特效加载模块加载特效文件;
音频混音模块接收声音采集模块输出的语音和特效加载模块加载的特效文件,并对声音采集模块输出的语音和特效加载模块加载的特效文件采样得到采样数据,音频混音模块再将采样数据叠加混合得到混合音频数据;
音频输出模块接收并发送混合音频数据到声音播放设备。
在上述技术方案的基础上,所述直播客户端语音处理系统还包括系统API和软件API,在声音采集模块采集用户输入的语音后并且在得到混合音频数据前,开启变调功能,并进一步判断所述直播客户端语音处理系统是否支持硬件处理变调;若支持,调用系统API进行变调;若不支持,调用软件API进行变调。
在上述技术方案的基础上,所述特效加载模块加载多路特效文件,然后将所述声音采集模块输出的语音的采样率和每一路特效文件的采样率转换为相同,再调节所述声音采集模块输出的语音的增益大小和每一路特效文件的增益大小,并通过加权法得到所述混合音频数据。
在上述技术方案的基础上,所述音频输出模块还包括音频限幅模块,所述音频限幅模块限制所述混合音频数据的幅度。
与现有技术相比,本发明的优点在于:
(1)本发明的直播客户端语音处理系统包括声音采集模块、特效加载模块和音频混音模块,音频混音模块将声音采集模块采集主播的语音和特效加载模块加载的特效文件叠加混合,能够很好的改善直播氛围,增强了主播与用户之间的互动。
(2)本发明中的声音采集模块还包括变调开关和硬件处理模块,直播客户端语音处理系统还包括系统API和软件API以及调用系统API或软件API进行变调处理的调用模块,本发明可利用变调开关、硬件处理模块、系统API、软件API和调用模块对声音采集模块采集的语音进行变调处理,变调后的语音更具有娱乐性,进一步的增强了主播与用户之间的互动。
附图说明
图1为本发明中直播客户端语音处理系统的结构示意图;
图2为本发明中处理语音的方法的流程图;
图3为本发明中混音处理的步骤的流程图;
图4为本发明中处理语音的方法加入变调步骤的流程图;
图5为本发明中变调步骤的流程图。
具体实施方式
以下结合附图对本发明作进一步详细说明。
参见图1所示,本发明提供一种直播客户端语音处理系统,其包括声音采集模块、特效加载模块、音频混音模块和音频输出模块。
其中,声音采集模块用于采集用户输入的语音,本发明中声音采集模块主要是用来采集主播的Mic(Microphone,麦克风)声音。
特效加载模块用于加载特效文件,特效文件可以是掌声,笑声等文件,特效文件的单个时长和文件个数没有限制。这样当主播在讲完一段话后,会有观众鼓掌或者观众大笑的背景音效,增强了主播与用户之间的互动。
音频混音模块用于接收语音和特效文件,并对语音和特效文件采样得到采样数据,然后音频混音模块再将采样数据进行叠加混合得到混合音频数据。
由于音频混合只能处理PCM(Pulse Code Modulation,脉冲编码调制)、LPCM(线性脉冲编码调制)格式的音频数据,如果原始的特效文件是这两类格式,便不需要音频解码。如果原始的特效文件是其他格式,例如是MP3,M4A格式,就需要进行音频格式的转换。故本发明还包括特效文件格式转换模块,利用特效文件格式转换模块来将特效文件转换成为音频混音模块支持的格式。
音频混音模块还包括多路开关,多路开关用于开启和关闭声音采集模块输出的语音和每一路特效文件的输入。即本发明可以通过多路开关来随意组合特效文件,从而方便达到满意的效果。音频混音模块还包括归一化模块,归一化模块用于将声音采集模块输出的语音的采样率和每一路特效文件的采样率转换为相同的采样率,音频混音模块还包括通道加权模块,通道加权模块用于调节声音采集模块输出的语音的增益大小和每一路特效文件的增益大小,并通过加权法得到混合音频数据。
本发明中的音频混音模块还包括音频限幅模块,音频限幅模块可以对混合音频数据进行幅度限制,避免混合音频数据的幅度过高而产生高音啸叫。具体的,音频限幅模块设置有幅度最大值和幅度最小值,当混合音频数据的幅度小于幅度最小值时,音频限幅模块工作使最后输出的混合音频数据的幅度为幅度最小值;当混合音频数据的幅度大于幅度最大值时,音频限幅模块工作使最后输出的混合音频数据的幅度为幅度最大值;而当混合音频数据的幅度位于幅度最大值和幅度最小值之间时,则最后输出的是混合音频数据幅度的实际值。
音频输出模块用于接收并发送混合音频数据到声音播放设备,声音播放设备通常为扬声器或者耳机。
为了进一步增强主播与用户之间的互动,本发明中的声音采集模块还包括变调开关和硬件处理模块,变调开关用于开启和关闭变调功能,硬件处理模块用于判断直播客户端语音处理系统是否支持硬件处理变调。直播客户端语音处理系统还包括系统API(Application Programming Interface,应用程序编程接口)和软件API以及调用系统API或软件API进行变调处理的调用模块。具体的变调过程如下:若变调开关关闭变调功能,则由音频混音模块接收语音。若变调开关开启变调功能,则硬件处理模块进一步判断直播客户端语音处理系统是否支持硬件处理变调,若是则调用模块调用系统API进行变调处理。若否则调用模块调用软件API进行变调处理。声音采集模块将变调后的语音输出给音频混音模块,然后音频混音模块再将变调后的语音和特效文件进行叠加混合。变调后的语音娱乐性更好,能够使主播与观众更好的互动。
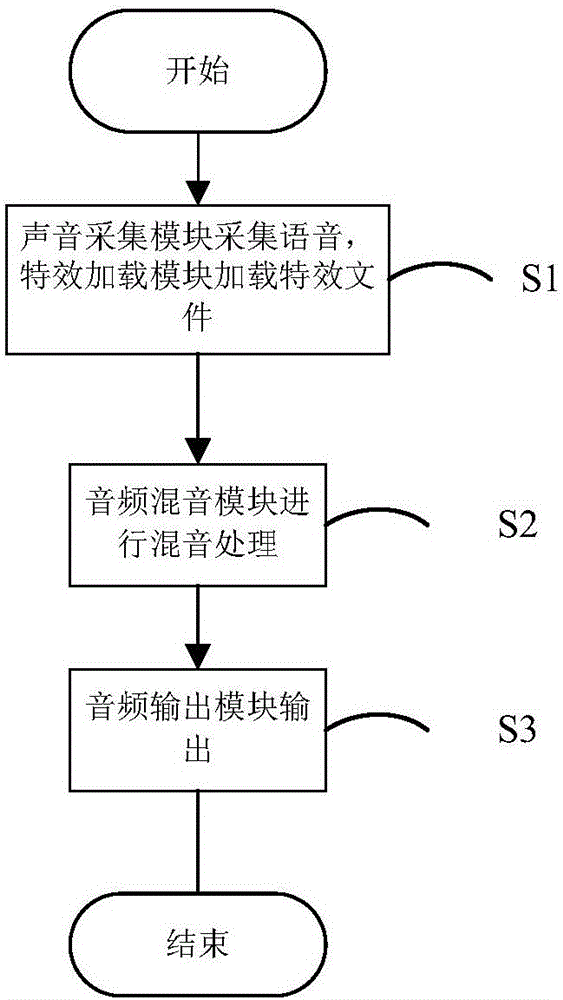
实施例一,参见图2所示,本发明还提供一种利用上述直播客户端语音处理系统处理语音的方法,包括以下步骤:
S1:声音采集模块采集用户输入的语音,特效加载模块加载特效文件。
S2:音频混音模块接收声音采集模块输出的语音和特效加载模块加载的特效文件,并对声音采集模块输出的语音和特效加载模块加载的特效文件采样得到采样数据,音频混音模块再将采样数据叠加混合得到混合音频数据。
参见图3所示,为了得到较好的混音效果,本发明中混音处理的步骤包括:
S21:音频混音模块通过多路开关开启和关闭声音采集模块输出的语音和每一路特效文件的输入。
S22:音频混音模块对输入的语音和特效文件采样得到采样数据,并利用归一化模块将声音采集模块输出的语音的采样率和每一路特效文件的采样率转换为相同的采样率。
S23:音频混音模块利用通道加权模块调节声音采集模块输出的语音的增益大小和每一路特效文件的增益大小,并通过加权法得到混合音频数据。
混合音频数据输出可利用下面的公式进行计算:
混合音频数据输出=通道1*增益1+通道2*增益2+…+通道n*增益n。
S24:音频混音模块利用音频限幅模块限制混合音频数据的幅度。
音频限幅模块可以对混合音频数据进行幅度限制,避免混合音频数据的幅度过高而产生高音啸叫。
S3:音频输出模块接收并发送混合音频数据到声音播放设备。
实施例2,参见图4所示,为了更好的增加主播和观众之间的互动,还可以对声音采集模块采集的语音进行变调处理,然后再与特效文件叠加混合得到混合音频数据,其包括如下步骤:
S1’:声音采集模块采集用户输入的语音并对其进行变调处理,特效加载模块加载特效文件。
本发明中的声音采集模块还包括变调开关和硬件处理模块,直播客户端语音处理系统还包括系统API和软件API以及调用系统API或软件API进行变调处理的调用模块。参见图5所示对声音采集模块采集的语音进行变调的步骤包括:
S11’:变调开关开启变调功能。
S12’:硬件处理模块进一步判断直播客户端语音处理系统是否支持硬件处理变调,若支持,执行步骤S13’,若不支持,执行步骤S14’。
S13’:调用模块调用系统API对语音进行变调处理,然后执行步骤S15’。
S14’:调用模块调用软件API对语音进行变调处理,然后执行步骤S15’。
S15’:声音采集模块发送语音至音频混音模块。
S2’:音频混音模块接收声音采集模块输出的语音和特效加载模块加载的特效文件,并对声音采集模块输出的语音和特效加载模块加载的特效文件采样得到采样数据,音频混音模块再将采样数据叠加混合得到混合音频数据。
混音处理的步骤与实施例1中相同。
S3’:音频输出模块接收并发送混合音频数据到声音播放设备。
本发明不局限于上述实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围之内。本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!