量子教与学搜索机制的中继选择方法与流程
本发明涉及一种通过对中继选择的组合目标使用量子教与学搜索机制来实现的均衡考虑最大平均网络效益和公平性折中的量子教与学搜索机制的中继选择方法。
背景技术:
中继是两个交换中心之间的一条传输通路。协作与中继是未来无线网络关键技术之一,受到学术界与工业界的广泛重视。由于中继节点的存在,中继协作网络中继选择技术变得更加复杂。在中继协作网络中,往往存在多个候选中继节点,如何合理有效地从候选中继节点中选择合适的中继节点参与协作通信,对提高协作通信网络的系统容量、网络能量效率及用户间公平性,降低数据传输的能耗和接收的误比特率等都有重要的意义。
在多用户场景下,确定选择哪些中继节点参与协作通信,使网络信噪比或者能量效率最大化,同时尽量减少网络消耗的功率,延长网络生存时间的研究非常重要。由于中继选择是NP-hard问题,算法复杂度为指数级别,很难在短时间内求出最优解。因此,改进经典的人工智能方法,设计新的中继选择方案,在保证性能接近穷尽搜索得到的解的同时降低算法复杂度,具有较重要的意义。Sharma Sushant等在《IEEE/ACM Transactions on Networking》上发表的“An optimal algorithm for relay node assignment in cooperative Ad Hoc networks”提出了以最大网络效益为目标的单目标函数的中继选择方案,利用最优多项式时间算法进行求解,没有综合考虑网络效益和公平性。Juan Wang等在第三次国际IMCCC会议上发表的“Multiple relay selection scheme based on artificial bee colony algorithm”提出了用人工蜂群算法解决多用户中继选择单目标函数最大化问题,提高了求解精度,但也没有综合考虑网络效益和公平性。因此该专利提出基于量子教与学搜索机制的中继选择方法,均衡考虑最大平均网络效益和公平性折中,可解决组合目标最大化问题,所设计的中继选择方法具有收敛速度快,吞吐量大的优点,应用范围广。
技术实现要素:
本发明的目的在于针对现有中继选择方法的不足提供一种均衡考虑最大平均网络效益和公平性折中的通过把最大平均网络效益和公平性加权构造出线性加权的目标函数,以此得出有效的量子教与学搜索机制的中继选择方法。
本发明是通过如下技术方案来实现的,主要包括以下步骤:
步骤一,建立多用户中继系统模型,多用户中继系统模型中有N个用户,即N个发送接收对负责发送和接收信号,有M个候选中继进行协作传输。通常M大于N。
在中继转发信号的过程中,采用译码转发方式。一帧分为两个时隙:TS1和TS2。在时隙TS1,第i个源节点SN i向第i个目的节点DN i和第i个候选中继节点RN i发送信号。在TS2,RN i向DN i发送信号,其中DN i对TS1和TS2接收的信号进行最大比合并(MRC)。TS1中,在RN i和DN i,SN j(j≠i)发送的信号会对SN i发送的信号产生干扰。TS1中,在DN i,RN j(j≠i)发送的信号会对RN i发送的信号产生干扰。TS1中,SN i到RN j的信道状态信息为SN i到DN j的信道状态信息为时隙TS2中,RN i到DN j的信道状态信息为对于每个用户,SN i的发送功率为RN j的发送功率为
在时隙TS 1,SN i发送信号其中zi表示要发送的信号,通常为归一化信号,即E|zi|2=1。SN i端的消耗的功率为DN i端接收的信号为
其中w为平均功率为η的高斯白噪声。因此,SN-DN链路的信号干扰噪声比(SINR)为:
RN i接收的信号为:
因此,SN-RN链路的SINR为:
在TS2,RN i接收并解码信号,进而将解码的信号(zi′和z′j)进行转发,因而DN i端接收的信号为:
因此,RN-DN链路的SINR为:
对于中继译码转发方式(DF),发送端到接收端的总吞吐量为:
其中W为系统可用带宽,γi为用户i的SINR。
最大平均网络效益为:
其中r=[r1,r2,...,rN]为中继选择方案,ri(i=1,2,…,N)代表第i个用户的中继选择,并且规定每一个中继节点(RN)至多能帮助一个SN-DN传输对。
表示中继网络公平性的目标函数为:
则最大网络效益和公平性的组合目标函数为
max{λUMPF(r)+(1-λ)UMAR(r)}
其中λ为权值,0≤λ≤1。
步骤二,初始化班级,有H个量子学员,班级中第i个量子学员的第t代的状态可以表示为其中h=1,2,…,H,n=1,2,…,N。
对所有量子学员的成绩进行评价,选出成绩最高的量子学员为量子教师,其第t代量子状态为
将第h个量子学员状态映射为整数解,对于第n维变量,映射规则如下:首先令其中,ln是第n(n=1,2,…,N)维变量的下界,un是第n维变量的上界。因为多用户中继选择是一个整数优化问题,要把实数解映射为整数解,映射规则为表示对的向上取整函数,则映射为整数解把代入成绩评价函数计算出相应的成绩,其也是的成绩。成绩评价的过程如下:首先确定一个RN至多能帮助一个SN-DN传输对,如果一个RN帮助超过一个SN-DN传输对,则成绩为0。如果满足一个RN至多能帮助一个SN-DN传输对,计算SN-RN链路的SINR为RN-DN链路的SINR为SN-DN链路的SINR为利用公式计算出发送端到接收端的总的吞吐量,利用成绩评价函数计算其成绩。则第t代第h个量子学员的成绩通过如下的成绩评价函数计算
步骤三,
教阶段,量子学员的量子态演化过程就是量子学员的学习更新过程。
“教”阶段第h(h=1,2,…,H)个量子学员的第n个量子旋转角和量子位的更新方程如下:
其中,n=1,2,…,N,abs(.)表示绝对值函数,是第t+1代“教”阶段的一个量子旋转角,ξ1、ξ2和为[0,1]间的均匀随机数,是均值为0方差为1的高斯随机数,表示量子学员量子位的均值。
“教”阶段完成后,第h个量子学员学习后的量子状态为根据前述映射规则把量子状态映射为整数解根据成绩评价函数计算出的成绩。
每个学员根据学习前和学习后的成绩进行对比,根据贪婪策略选择量子学员状态,对于第h个量子学员,若的成绩大于的成绩,则
步骤四:“学”阶段,对每一个量子学员,在班级中随机选取一个学习对象,量子学员通过分析自己和所选择量子学员的成绩差异进行成绩调整,采用如下公式对第h(h=1,2,…,H)个量子学员的量子旋转角与量子位进行更新:
其中n=1,2,…,N,sign(.)表示符号函数,第t+1代“学”阶段的一个量子旋转角,j代表随机选中的量子学员的标号,ξ3和为[0,1]间的均匀随机数,是均值为0方差为1的高斯随机数。
步骤五:对于新的量子学员需要根据前述映射规则将其映射为整数解根据成绩评价函数计算出相应的成绩。根据贪婪策略选择量子学员状态,若的成绩大于的成绩,则
步骤六:从更新后的量子学员(h=1,2,…,H)中找到成绩最好的量子学员作为新的量子教师
步骤七:如果学习没有终止(通常由预先设定的最大迭代次数决定),返回步骤三,否则,终止迭代,输出量子教师的量子态并将其映射为整数,得到中继选择方案。
本发明均衡考虑到中继协作网络中继选择过程最大平均网络效益和公平性的问题,求解中继选择方法,得到目标解。与现有技术相比,本发明充分考虑了中继协作网络中继选择过程中最大平均网络效益和公平性的目标,具有以下优点:
(1)本发明解决了整数规划的中继选择问题,并设计新颖的基于量子教与学算法的中继选择方法作为演进策略,所设计的方法具有收敛速度快,收敛精度高的优点。
(2)相对于现有的单目标中继算法,本发明提出一种权重组合的方法来解决目标的优化问题,既可以解决单目标优化(λ=0或λ=1)问题,也可以解决组合目标优化问题(0<λ<1)。
(3)相对于现有的中继算法,量子教与学算法的中继选择方法在相同的功率,相同的中继数目以及迭代次数情况下,吞吐量优于传统算法。
附图说明
图1中继协作网络量子教与学搜索机制的中继选择方法示意图。
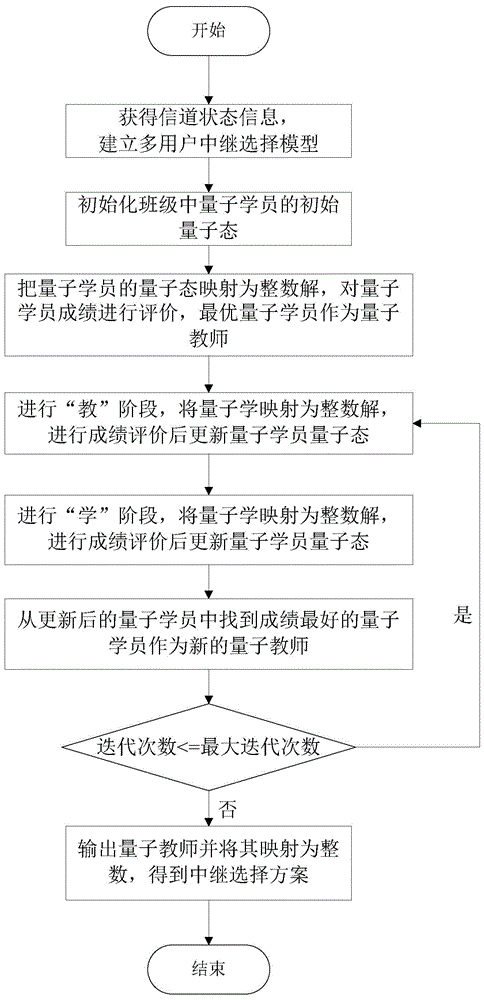
图2量子教与学搜索机制流程图。
图3为目标函数λ=0时,量子教与学中继选择方法和人工蜂群中继选择方法的吞吐量随功率变化的曲线。
图4为目标函数λ=0时,量子教与学中继选择方法和人工蜂群中继选择方法的吞吐量随迭代次数变化的曲线。
图5为目标函数λ=0时,量子教与学中继选择方法和人工蜂群中继选择方法的吞吐量随中继节点个数变化的曲线。
图6为目标函数λ=0.5时,量子教与学中继选择方法的吞吐量随功率变化的曲线。
图7为目标函数λ=0.5时,量子教与学中继选择方法的吞吐量随迭代次数变化的曲线。
图8为目标函数λ=0.5时,量子教与学中继选择方法的吞吐量随中继节点个数变化的曲线。
图9为目标函数λ=1时,量子教与学中继选择方法和人工蜂群中继选择方法的吞吐量随功率变化的曲线。
图10为目标函数λ=1时,量子教与学中继选择方法和人工蜂群中继选择方法的吞吐量随迭代次数变化的曲线。
图11为目标函数λ=1时,量子教与学中继选择方法和人工蜂群中继选择方法的吞吐量随中继节点个数变化的曲线。
具体实施方式
下面结合附图对本发明做进一步描述。
(1)多用户中继系统中有N个用户,即N个发送接收对负责发送和接收信号,有M个候选中继进行协作传输,一般M大于N。根据负责中继选择的中心控制器获得所有信道状态信息,建立多用户中继选择模型,确定最大网络效益和公平性的组合目标函数为max{λUMPF(r)+(1-λ)UMAR(r)},其中λ为权值,0≤λ≤1,最大平均网络效益为:其中r=[r1,r2,...,rN]为中继选择方案,ri(i=1,2,…,N)代表第i个用户的中继选择,并且规定每一个中继节点(RN)至多能帮助一个SN-DN传输对,其中W为系统可用带宽,γi为用户i的SINR;表示中继网络公平性的目标函数为:
(2)初始化班级,有H个量子学员,班级中第i个量子学员的第t代的状态可以表示为其中h=1,2,…,H,n=1,2,…,N。
(3)对所有量子学员的成绩进行评价,选出成绩最高的量子学员为量子教师,其第t代量子状态为
将第h个量子学员状态映射为整数解,对于第n维变量,映射规则如下:首先令其中,ln是第n(n=1,2,…,N)维变量的下界,un是第n维变量的上界。因为多用户中继选择是一个整数优化问题,要把实数解映射为整数解。映射规则为表示对的向上取整函数,则映射为整数解把代入成绩评价函数计算出相应的成绩,其也是的成绩。成绩评价的过程如下:首先确定一个RN至多能帮助一个SN-DN传输对,如果一个RN帮助超过一个SN-DN传输对,则成绩为0。如果满足一个RN至多能帮助一个SN-DN传输对,计算SN-RN链路的SINR为RN-DN链路的SINR为SN-DN链路的SINR为利用公式计算出发送端到接收端的总的吞吐量,利用成绩评价函数计算其成绩。则第t代第h个量子学员的成绩通过如下的成绩评价函数计算
(4)进行“教”阶段。
“教”阶段第h(h=1,2,…,H)个量子学员的第n个量子旋转角和量子位的更新方程如下:
其中,n=1,2,…,N,abs(.)表示绝对值函数,是第t+1代“教”阶段的一个量子旋转角,ξ1、ξ2和为[0,1]间的均匀随机数,是均值为0方差为1的高斯随机数,表示量子学员量子位的均值。
“教”阶段完成后,第h个量子学员学习后的量子状态为根据前述映射规则把量子状态映射为整数解根据成绩评价函数计算出的成绩。
每个学员根据学习前和学习后的成绩进行对比,根据贪婪策略选择量子学员状态,对于第h个量子学员,若的成绩大于的成绩,则
(5)进行“学”阶段。
“学”阶段,对每一个量子学员,在班级中随机选取一个学习对象,量子学员通过分析自己和所选择量子学员的成绩差异进行成绩调整,采用如下公式对第h(h=1,2,…,H)个量子学员的量子旋转角与量子位进行更新:
其中n=1,2,…,N,sign(.)表示符号函数,第t+1代“学”阶段的一个量子旋转角,j代表随机选中的量子学员的标号,ξ3和为[0,1]间的均匀随机数,是均值为0方差为1的高斯随机数。
对于新的量子学员需要根据前述映射规则将其映射为整数解根据成绩评价函数计算出相应的成绩。根据贪婪策略选择量子学员状态,若的成绩大于的成绩,则
(6)从更新后的量子学员中找到成绩最好的量子学员作为新的量子教师
(7)判断学习是否终止,如果学习没有终止(根据设定的最大迭代次数决定),返回步骤(4),否则,算法终止,输出量子教师并将其映射为整数,作为中继选择方法。
仿真中假设中继协作网络的信道带宽为10MHz,N=10,M=20,节点分布在D×D的范围内,D=100m,SN的功率20W,在图4、图7和图10中RN的功率设为18W,在图5、图8和图11中RN的功率设为10W,所有节点的高斯白噪声功率为10-3W。SN和DN的距离在[25,35]m范围内均匀分布。为了便于比较所提出的量子教与学方法(QTLBO)与已有人工蜂群方法(ABCO)的优劣,群体规模和终止迭代次数都设置为相同,群体规模为H=20,最大迭代次数为500次,所有结果是200次仿真的平均。人工蜂群算法的中继选择方法的其他参数设置参考文献“Multiple relay selection scheme based on artificial bee colony algorithm”。
图3为目标函数λ=0的情况。在λ=0的情况下,求解目标变为单目标问题,只考虑了最大平均网络效益。由仿真结果可以明显得知量子教与学算法在单目标的情况下随着RN功率的增大,吞吐量明显高于人工蜂群方法。
图4为目标函数λ=0的情况。在λ=0的情况下,由仿真结果可以明显得知量子教与学算法在单目标的情况下随着迭代次数的增加,吞吐量明显高于人工蜂群方法。同时,随着迭代次数的增加,量子教与学方法的收敛速度明显优于人工蜂群方法。
图5为目标函数λ=0的情况。在λ=0的情况下,求解目标变为单目标问题,只考虑了最大平均网络效益。由仿真结果可以明显得知量子教与学方法在单目标的情况下随着中继数目的增加,吞吐量明显高于人工蜂群方法。量子教与学方法在单目标问题下性能明显优于人工蜂群方法。
图6为目标函数λ=0.5的情况。在λ=0.5的情况下,目标函数为组合目标求解问题,考虑了最大平均网络效益和公平性。图为量子教与学中继选择方法的吞吐量随RN的功率变化而变化的仿真结果。
图7为目标函数λ=0.5的情况。在λ=0.5的情况下,目标函数为组合目标求解问题,考虑了最大平均网络效益和公平性。可以看出,随着迭代次数的增加,量子教与学搜索机制的收敛速度快,收敛精度高。
图8为目标函数λ=0.5的情况。在λ=0.5的情况下,目标函数变为组合目标求解问题,考虑了最大平均网络效益和公平性。图为量子教与学中继选择方法的吞吐量随中继数目变化而变化的仿真结果。可以看出,随着中继数目的增加,系统的吞吐量不断的增大。
图9为目标函数λ=1的情况。在λ=1的情况下,目标函数变为单目标求解问题,只考虑了公平性。比较量子教与学方法与人工蜂群方法随RN功率变化吞吐量的变化。由仿真结果可以明显得知量子教与学方法在单目标求解的情况下随着RN功率的增大,吞吐量明显高于人工蜂群方法。
图10为目标函数λ=1的情况。在λ=1的情况下,目标函数变为单目标求解问题,只考虑了公平性。由仿真结果可以明显得知量子教与学算法在单目标要求的情况下随着迭代次数的增加,吞吐量明显高于人工蜂群方法。同时,随着迭代次数的增加,量子教与学方法的收敛速度明显优于人工蜂群方法。
图11为目标函数λ=1的情况。在λ=1的情况下,目标函数变为单目标求解问题,只考虑了公平性。由仿真结果可以明显得知量子教与学算法在单目标的情况下随着中继数目的增加,吞吐量明显高于人工蜂群算法。量子教与学方法在单目标问题下性能明显优于人工蜂群方法。
以上内容是结合具体的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!