一种改进型路由器别名过滤方法与流程
本发明属于网络网络拓扑发现技术领域,更为具体地讲,涉及一种识别处理拓扑发现中别名路由识别的方法。
背景技术:
目前对于网络拓扑发现技术的研究比较多,其中基于traceroute的网络拓扑测量由于不需要测量者具有特殊权限在大规模网络拓扑测量中得到广泛应用.使得基于traceroute的拓扑测量方式己经很大程度上取代了过去的基于SNMP协议(Simple Network Management Protocol,简单网络管理协议)的拓扑测量方式,成为目前网络拓扑测量方法的主流。
Traceroute通过发送一份TTL字段(Time to Live,IP报文生成时间)为1的IP(Internet Protocol)数据报给目的主机。处理这份数据报的第一个路由器将TTL值减1,丢弃该数据报,并用自己的IP地址作为源IP发回一份超时ICMP(Internet Control Messages Protocol,网间控制报文协议)报文。这样就得到了该路径中的第一个路由器的地址。然后Traceroute程序发送一份TTL值为2的数据报,这样我们就可以得到第二个路由器的地址。继续这个过程直至该数据报到达目的主机可以得到源到目的经过的所有路由器的IP地址。采用多方向多探测源就可以利用得到的多条traceroute路径分析出整个网络的拓扑结构。然而,由于一个路由器往往具有多个IP地址,如果不分析出traceroute路径中属于同一路由器的不同IP地址,分析出的拓扑结构与实际情况是有很大差别的。别名解析(Alias Resolution)就是一种找出属于同一台路由器的IP地址集合的技术.
现有别名解析技术分为基于分析和基于探测两大类。基于分析的别名解析技术又有基于DNS的分析,基于图论的分析和基于对称路由的分析等。基于DNS的分析是指基于现有DNS配置规范,如果两个IP地址具有相同DNS域名,则两IP地址互为别名关系;常见的基于探测的技术有UDP高端口探测,ICMP报文探测,TCP报文探测。几种探测方式的原理相似,如想确定IP地址x和y是否是同一个路由器的两个IP地址,探测端向x发送一个使接收端产生异常的探测报文,x收到报文后返回异常,如果探测端收到的异常报文源IP为y,则x和y是同一路由器的两个不同IP地址,即互为别名关系。如果不是,则探测端再对y发送探测报文,若返回异常报文为x,则x和y互为别名关系,如果两次探测收到的异常报文都和探测报文目的IP相同,则两地址不为别名关系。
常见的,基于traceroute路径的拓扑分析需要处理三种别名关系:
对称别名:两条traceroute路径中存在对称路段情况,具体情形如图1所示
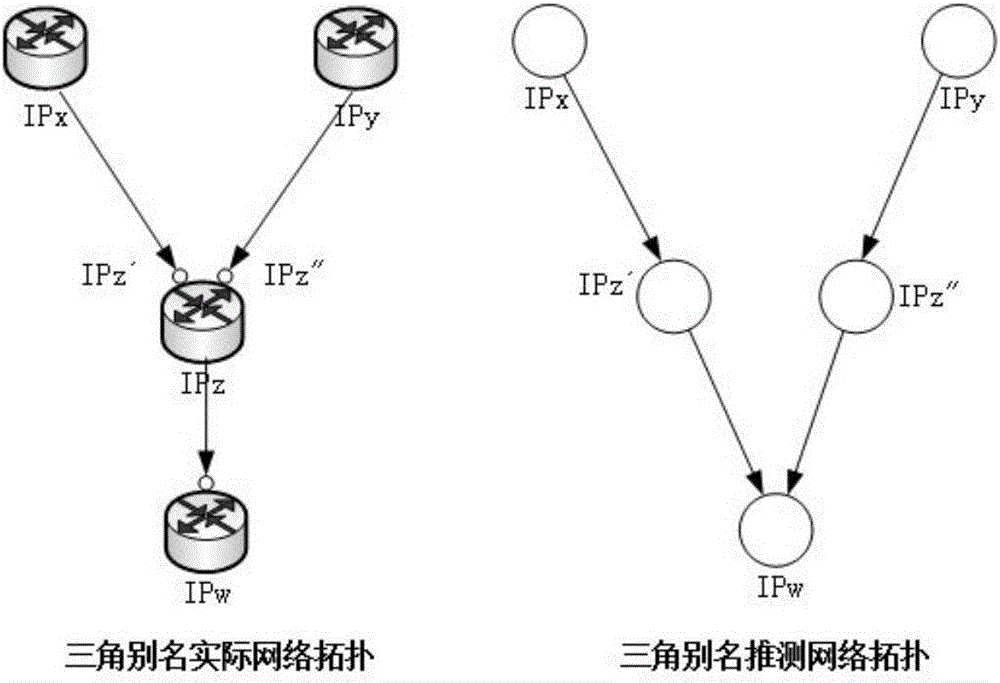
三角别名:两条traceroute路径存在相同后继情况,具体情形如图2所示
平行别名:两条平行traceroute路径存在别名情况,具体情形如图3所示
由于本发明主要针对三角别名算法进行改进,所以这里重点分析三角别名的实际情况。实际网络拓扑结构中,存在的三角关系又可以分为两种情况:
第一种如图2所示,IPx和IPy分别是两个路由器的IP地址,它们与同一个IP为IPz的路由器相连,在正向traceroute的两条路径中,表现为两个互异的IP地址后继为相同的IP地址。
第二种如图4所示,IPx和IPy分别是两个路由器的IP地址,他们通过一个二层交换机连接,交换机后继为一个路由器,其IP地址为IPz。
现有别名过滤技术在处理三角别名时,对上面两种情况并未加以区分。首先,认为两条traceroute路径中具有相同后继的两个IP地址是别名关系为大概率事件,对分析得到的可能别名关系进行探测验证得到最终实际网络的别名关系结果。
但是,对三角别名情况的细分可能是一种相对复杂的方法,但是在别名探测整体效率的提高上是具有一定意义的。
技术实现要素:
本发明针对以上问题,通过细分三角别名的两种情况,提出一种改进型路由器别名过滤方法:融入DNS(domain name system)和IP分析的三角别名判定。
本发明依据DNS和IP地址信息将具有三角关系的IP地址集分为别名关系,潜在别名关系和待定集合三类,首先,依据对DNS信息的分析分离出确定的别名关系,一定程度减少了后续探测规模提高别名解析效率。其次,在对未判定为别名关系的IP地址集处理中,先对潜在别名关系集中的IP地址优先进行别名解析,如果其中两个IP地址是别名关系,则将他们为同一个地址集合并以两个IP地址中任意一个作为此集合代表,如果不是,则将两IP地址加入非别名关系地址集合。经过对潜在别名关系地址集优先进行别名解析,相对随机探测能以较大概率找到别名关系的IP地址集,减小对后续处理时的探测规模。处理流程图如图5所示,处理步骤如下:
Step1:遍历获得的所有traceroute路径,将具有相同后继节点的IP地址及对应域名放入一个集合里,记为ni,得到n1,n2···nn等一系列集合,设N=n1∪n2∪n3···∪nn。
Step2:对N里的每个子集合ni进行域名分析,将ni里具有相同域名的IP地址构成新集合,记为bi,取删除ni里除x以外所有和bi相同的元素。集合bi内的任意两个IP地址互为别名关系,所有bi构成别名关系集合B。
Step3:对于ni的每个子集合,将子集合里包含相同网络号的IP地址加入新集合,记为ci,ci内的元素间互为别名关系为大概率事件,对ci内的元素优先探测。C=c1∪c2∪···则为潜在别名集合。
Step4:对于C里每个子集合的子集合ci,对集合内的任意两个元素进行实际网络别名探测验证,即对ci里任意两个IP地址进行TCP报文探测,对具有别名关系的IP地址形成新集合b'i,取删除ni里除x以外与b'i相同的元素,b'i里的元素具有别名关系,加入关系集合B。
Step5:对剩余ni里的元素进行TCP报文探测,将获得的别名关系加入集合B。至此,完成对所有三角关系的别名分析。
Step6:返回别名关系集合B。
本发明的有益效果是:
经过对DNS分析的别名判定和相同网络号的IP地址集进行优先探测,可以大幅度减少后续别名探测的次数。提高探测效率。在探测的目标网络规模较大时,效率的提高往往比较显著。
附图说明
图1是对称别名的示意图;
图2是三角别名的示意图;
图3是平行别名的示意图;
图4是带二层交换设备的三角别名示意图;
图5是别名解析整体流程示意图。
具体实施方式
下面结合附图5对使用本发明的整个别名解析算法进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
这里算法的输入设定为已获得的traceroute数据,输出是一系列的别名关系IP地址集合。
结合本发明提到的方法,整个别名解析过程分为以下几个步骤进行:
Step1:登陆分布在日本的四个planetlab节点作为探测点,依次为:planet1.pnl.nitech.ac.jp,planetlab4.goto.info.waseda.ac.jp,planet2.pnl.nitech.ac.jp,pl1.sos.info.hiroshima-cu.ac.jp。
Step2:选定美国境内5个节点作为被探测的对象节点,分别为pl2.ucs.indiana.edu,pl1.ucs.indiana.edu,pl1.cs.montana.edu,planetlab1.cs.purdue.edu,planetlab1.cs.purdue.edu。
Step3:四个节点分别上传针对5个被探测对象的探测程序。
Step4:每个探测节点运行探测程序,程序对5个被探测IP地址执行traceroute命令,分别生成一个追踪结果文件,在本地下载4个探测节点的生成文件作为别名分析源数据。
Step5:对所有追踪文件进行处理,将路径中所有节点(每个节点为<IP地址,DNS>的键值对)存入一个节点集合A,除去相同节点(这里IP地址和主机名都相同的情况称作两节点相同)。程序分析得集合A的元素个数为39个。
Step6:遍历4个源数据文件里的每条路径,得到具有相同后继节点的IP地址集合,其中,集合元素个数大于等于2的共有三个,分别记为n1=={128.10.127.250,192.5.40.9},n2={192.105.205.193,192.105.205.193},n3={150.99.76.231,150.99.64.29,150.99.89.179,150.99.82.103,150.99.89.201}(这里只显示节点键值,即IP地址)。
Step7:对于任意ni(1≤i≤3),比较ni里的所有元素,找出具有相同主机名(或dns)的节点,这些节点构成一个别名集合Bi。所有依据DNS形成的别名集合Bi共同组成别名集合B=B1∪B2∪···∪Bn。这里由于节点数较少,并未找到相同域名的节点对。此步跳过。
Step8:对于任意ni,比较ni里的所有元素,找出具有相同网络号的节点,这些节点构成一个潜在别名集合Ci,每个ni对应产生一个Ci,这里得到三个Ci,C2={192.105.205.193,192.105.205.203},C3={150.99.89.179,150.99.89.201}(这里只显示节点键值,即IP地址),所有Ci的集合为潜在别名集合C。
Step9:对Ci(1≤i≤3)里的元素在planetlab上进行别名验证,验证结果为C3={150.99.89.179,150.99.89.201}(这里只显示节点键值,即IP地址)存在别名关系,这里将验证的别名关系记为B(n+1),并入别名关系集合B。
Step10:返回别名关系集合B。
在本次试验中,如果按照现有三角别名处理方法,将具有相同后继的IP地址记为别名关系并进行验证,则本例需进行的探测次数为:次,作为对比,本算法在程序处理中进行了两次别名探测,得到一对别名关系,则在后续处理过程这两个IP地址当作一个地址来处理,则后续探测次数为:次,算法一共进行探测次数为:16+2=18次。则探测效率提高为:(24-18)/24*100%=25%。
- 还没有人留言评论。精彩留言会获得点赞!