一种网络web站点信息收集方法及装置与流程
本发明涉及网络技术领域,特别是涉及一种网络web站点信息收集方法及装置。
背景技术:
目前,随着网络与信息技术的发展,尤其是互联网的广泛普及和应用,如电子政务、电子商务、网络办公、网络媒体以及虚拟社区的出现,正深刻影响人类生活、工作的方式。与此同时,信息安全的重要性也在不断提升。
在对Web站点进行渗透过程中,首先需要对该站点的信息进行收集,这样就能够有针对性的对站点进行精准打击。对站点的架构、所使用的中间件和部署方式等信息收集的越多对成功渗透目标的几率就越高,所以对web站点的信息收集在渗透测试过程中至关重要。然而目前要收集站点相关的信息都是人工来进行信息收集,收集工作量非常大,工作效率较低,也需要大量人力成本。
技术实现要素:
本发明的目的是提供一种网络web站点信息收集方法及装置,以实现自动收集web站点信息,节省人力成本。
为解决上述技术问题,本发明提供一种网络web站点信息收集方法,该方法包括:
对web站点进行检测,获取web站点的IP地址;
对所述IP地址进行端口扫描,获取所述IP地址对应的端口信息;
将所述端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件。
优选的,对web站点进行检测,获取web站点的IP地址,包括:
判断web站点的URL地址是否合法,若是,获取web站点的IP地址。
优选的,所述对web站点进行检测,获取web站点的IP地址之后,还包括:
查询web站点的域名信息;所述域名信息包括web站点的注册信息和子域名信息。
优选的,所述方法还包括:
采用网络爬虫工具对web站点进行信息抓取,得到web站点的URL地址使用的开发框架信息。
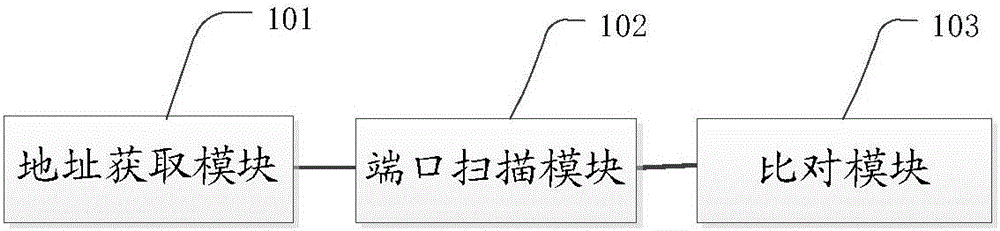
本发明还提供一种网络web站点信息收集装置,该装置包括:
地址获取模块,用于对web站点进行检测,获取web站点的IP地址;
端口扫描模块,用于对所述IP地址进行端口扫描,获取所述IP地址对应的端口信息;
比对模块,用于将所述端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件。
优选的,所述IP地址获取模块,用于对web站点进行检测,获取web站点的IP地址,包括:
所述地址获取模块,用于判断web站点的URL地址是否合法,若是,获取web站点的IP地址。
优选的,所述装置还包括:
查询模块,用于查询web站点的域名信息;所述域名信息包括web站点的注册信息和子域名信息。
优选的,所述装置还包括:
爬虫模块,用于采用网络爬虫工具对web站点进行信息抓取,得到web站点的URL地址使用的开发框架信息。
本发明所提供的一种网络web站点信息收集方法及装置,对web站点进行检测,获取web站点的IP地址;对所述IP地址进行端口扫描,获取所述IP地址对应的端口信息;将所述端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件。可见,不仅获取了web站点的IP地址信息,而且通过端口扫描获取端口信息,并通过指纹库中信息比对来获得web站点的操作系统和中间件,如此自动获取了IP地址信息、端口信息、操作系统和中间件这些多类信息,获取的信息量很多,也极大的提高站点的参透效率,也不需要大量人工来进行信息收集,如此实现自动收集web站点信息,节省人力成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明所提供的一种网络web站点信息收集方法的流程图;
图2为本发明所提供的一种网络web站点信息收集装置的结构示意图。
具体实施方式
本发明的核心是提供一种网络web站点信息收集方法及装置,以实现自动收集web站点信息,提升工作效率。
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参考图1,图1为本发明所提供的一种网络web站点信息收集方法的流程图,该方法包括:
S11:对web站点进行检测,获取web站点的IP地址;
S12:对IP地址进行端口扫描,获取IP地址对应的端口信息;
S13:将端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件。
可见,该方法不仅获取了web站点的IP地址信息,而且通过端口扫描获取端口信息,并通过指纹库中信息比对来获得web站点的操作系统和中间件,如此自动获取了IP地址信息、端口信息、操作系统和中间件这些多类信息,获取的信息量很多,也极大的提高站点的参透效率,也不需要大量人工来进行信息收集,如此实现自动收集web站点信息,节省人力成本。
基于上述方法,具体的,对web站点进行检测,获取web站点的IP地址的过程具体为:判断web站点的URL地址是否合法,若是,获取web站点的IP地址。
进一步的,对web站点进行检测,获取web站点的IP地址之后,还包括:查询web站点的域名信息;域名信息包括web站点的注册信息和子域名信息。
进一步的,所述方法还包括:采用网络爬虫工具对web站点进行信息抓取,得到web站点的URL地址使用的开发框架信息。
具体的,步骤S13的过程具体为:将端口信息和端口指纹库中的指纹信息进行比对,查找出与端口信息对应的指纹信息,从指纹信息中获取web站点使用的操作系统和采用的中间件。这里的指纹信息即为端口指纹信息,指纹信息中包含有web站点使用的操作系统和采用的中间件,从指纹信息中就能获取web站点使用的操作系统和采用的中间件。web站点使用的操作系统和采用的中间件均为web站点的服务信息。中间件就是一类连接软件组件和应用的计算机软件,它包括一组服务;中间件位于客户机/服务器的操作系统之上,管理计算机资源和网络通讯,是连接两个独立应用程序或独立系统的软件;相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍能交换信息;通过中间件,应用程序可以工作于多平台或OS环境。网络爬虫工具就是网络爬虫软件,包括Scrapy爬虫工具、PyRailgun爬虫工具或者QuickRecon爬虫工具。
本方法可以对站点进行多方面的信息收集,包括站点域名、子域名注册信息,主机、开放端口、服务信息,http服务器信息等方面进行信息的准确采集,实现从站点主机信息收集、端口信息收集、服务信息收集、域名信息收集、web应用信息收集等。本方法可以不受防火墙和IDS的影响,正确的收集到关于该站点的信息。本方法在进行站点信息收集的过程中对带宽的占用很少,不会产生危险的分片报文影响正常的网络运行。本方法可以帮助很多信息系统,包括业务系统、门户网站等,建立站点信息收集系统,帮助管理员更好的理解站点信息,可以嵌入到其他渗透测试系统中,为渗透测试提供前期的信息收集服务。
基于本方法,具体流程如下:
1、通过对目标web站点进行扫描,发现主机信息,包括该主机的IP地址和操作系统信息;
其中,输入目标web地址,根据该web地址获取站点whois信息,解析输入的目标地址,判断该目标地址是否合法,获取目标站点的IP地址信息;
2、通过对目标地址的IP地址进行端口扫描,确定目标地址开放的端口信息;
其中,根据目标地址获取该地址的操作系统信息,端口信息,还获取该目标地址使用的开发框架、采用的中间件信息;
3、通过收集到的端口信息与指纹库中的指纹信息进行对比,确定目标使用的操作系统以及采用的中间件;
其中,根据获取到的端口信息与端口指纹库中的信息进行对比,收集该站点的服务开放信息即操作系统以及中间件;
4、通过对该站点的域名信息进行收集,包含该站点的注册信息和子域名信息;
5、采用自动化的web站点爬虫,收集该站点的目录结构信息,发现该站点采用的中间件信息。
其中,根据提供的web站点入口地址,查找robot.txt文件,根据该文件对站点进行初级抓取,根据站点首页进行页面链接收集,通过抓取站点链接进行目录结构信息遍历。
图2为本发明所提供的一种网络web站点信息收集装置的结构示意图,该装置包括:
地址获取模块101,用于对web站点进行检测,获取web站点的IP地址;
端口扫描模块102,用于对IP地址进行端口扫描,获取IP地址对应的端口信息;
比对模块103,用于将端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件。
可见,该装置不仅获取了web站点的IP地址信息,而且通过端口扫描获取端口信息,并通过指纹库中信息比对来获得web站点的操作系统和中间件,如此自动获取了IP地址信息、端口信息、操作系统和中间件这些多类信息,获取的信息量很多,也极大的提高站点的参透效率,也不需要大量人工来进行信息收集,如此实现自动收集web站点信息,节省人力成本。
基于上述装置,具体的,IP地址获取模块,用于对web站点进行检测,获取web站点的IP地址,具体包括:用于判断web站点的URL地址是否合法,若是,获取web站点的IP地址。
进一步的,所述装置还包括:
查询模块,用于查询web站点的域名信息;域名信息包括web站点的注册信息和子域名信息。
进一步的,所述装置还包括:
爬虫模块,用于采用网络爬虫工具对web站点进行信息抓取,得到web站点的URL地址使用的开发框架信息。
具体的,比对模块,用于将端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件,具体包括:用于将端口信息和端口指纹库中的指纹信息进行比对,查找出与端口信息对应的指纹信息,从指纹信息中获取web站点使用的操作系统和采用的中间件。这里的指纹信息即为端口指纹信息,指纹信息中包含有web站点使用的操作系统和采用的中间件,从指纹信息中就能获取web站点使用的操作系统和采用的中间件。web站点使用的操作系统和采用的中间件均为web站点的服务信息。
本装置可以对站点进行多方面的信息收集,包括站点域名、子域名注册信息,主机、开放端口、服务信息,http服务器信息等方面进行信息的准确采集,通过自动化调用多个模块相互配合,实现从站点主机信息收集、端口信息收集、服务信息收集、域名信息收集、web应用信息收集等。本装置可以不受防火墙和IDS的影响,正确的收集到关于该站点的信息。本装置在进行站点信息收集的过程中对带宽的占用很少,不会产生危险的分片报文影响正常的网络运行。本装置可以帮助很多信息系统,包括业务系统、门户网站等,建立站点信息收集系统,帮助管理员更好的理解站点信息,可以作为第三方模块嵌入到其他渗透测试系统中,为渗透测试提供前期的信息收集服务。
基于本装置,具体过程如下:
1、地址获取模块通过对目标web站点进行扫描,发现主机信息,包括该主机的IP地址和操作系统信息;其中,输入目标web地址,根据该web地址获取站点whois信息,解析输入的目标地址,判断该目标地址是否合法,获取目标站点的IP地址信息;
2、端口扫描模块通过对目标地址的IP地址进行端口扫描,确定目标地址开放的端口信息;其中,根据目标地址获取该地址的操作系统信息,端口信息,还获取该目标地址使用的开发框架、采用的中间件信息;
3、比对模块通过收集到的端口信息与指纹库中的指纹信息进行对比,确定目标使用的操作系统以及采用的中间件;其中,根据获取到的端口信息与端口指纹库中的信息进行对比,收集该站点的服务开放信息即操作系统以及中间件;
4、查询模块通过对该站点的域名信息进行收集,包含该站点的注册信息和子域名信息;
5、爬虫模块采用自动化的web站点爬虫,收集该站点的目录结构信息,发现该站点采用的中间件信息。其中,根据提供的web站点入口地址,查找robot.txt文件,根据该文件对站点进行初级抓取,根据站点首页进行页面链接收集,通过抓取站点链接进行目录结构信息遍历。
综上,本发明所提供的一种网络web站点信息收集方法及装置,对web站点进行检测,获取web站点的IP地址;对IP地址进行端口扫描,获取IP地址对应的端口信息;将端口信息与端口指纹库中的指纹信息进行比对,确定web站点使用的操作系统以及采用的中间件。可见,不仅获取了web站点的IP地址信息,而且通过端口扫描获取端口信息,并通过指纹库中信息比对来获得web站点的操作系统和中间件,如此自动获取了IP地址信息、端口信息、操作系统和中间件这些多类信息,获取的信息量很多,也极大的提高站点的参透效率,也不需要大量人工来进行信息收集,如此实现自动收集web站点信息,节省人力成本。
以上对本发明所提供的一种网络web站点信息收集方法及装置进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!