一种基于贝叶斯网络的系统测量节点优化配置方法与流程
本发明涉及复杂系统控制及故障诊断领域,具体地说是一种基于贝叶斯网络的系统测量节点优化配置方法。
背景技术:
故障诊断是保证系统可靠运行的关键,故障诊断是通过测点对系统的关键变量进行检测获得变量的故障信息,根据故障信息确定系统的故障征兆。而系统在进行故障诊断时,往往要求使用尽可能少的测点获得尽可能多的故障信息,满足对故障的最大的诊断能力,即测点的优化配置是关键。对于航天器姿态控制系统这样的大型复杂系统来说,为保证其长期可靠运行,需要为其配置测点获取故障信息,最大化测点的故障诊断能力。在实际工程中为了得到尽可能多的信息,往往需要配置很多传感器,但这样的配置存在一定的盲目性且还会造成资源的浪费,在资源成本限制下,测点的优化配置就显得尤为重要。
技术实现要素:
针对现有技术的不足,本发明提供一种基于贝叶斯网络的系统测量节点优化配置方法,解决了航天器等复杂系统在进行故障诊断时测点配置方案的诊断能力及成本问题。
本发明为实现上述目的所采用的技术方案是:
一种基于贝叶斯网络的系统测量节点优化配置方法,包括以下步骤:
步骤1:建立系统的贝叶斯网络模型;
步骤2:根据贝叶斯网络模型计算故障节点和测量节点间的互信息矩阵;
步骤3:根据故障节点和测量节点间的互信息矩阵计算测点对故障节点诊断的贡献度,确定综合诊断能力指标;
步骤4:根据测点对故障节点诊断的贡献度及测点成本和测点数量限制描述优化问题;
步骤5:应用改进的离散二进制粒子群算法进行优化处理,得出测点的优化配置结果。
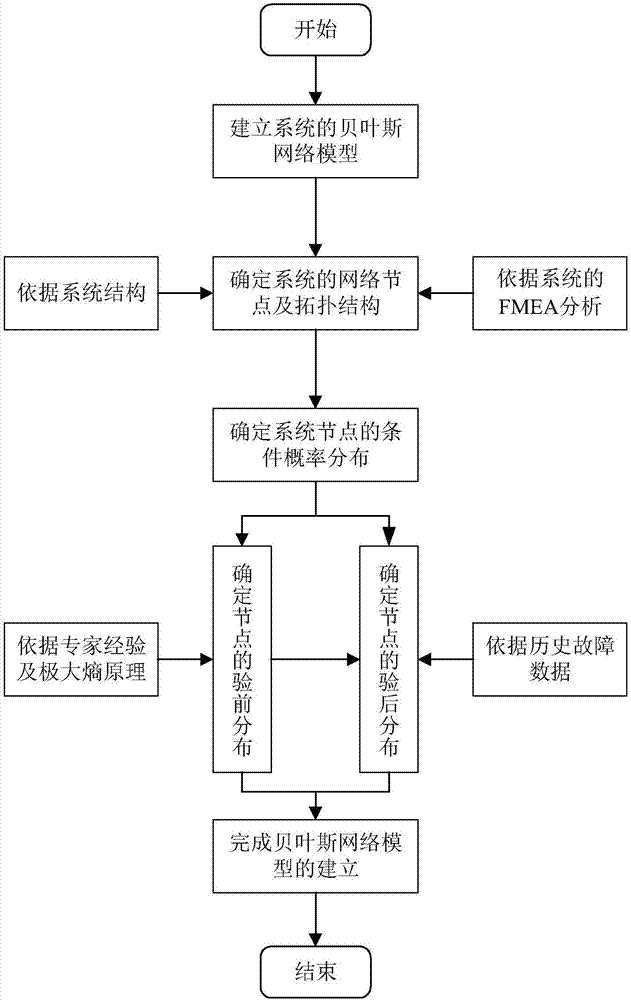
所述建立系统的贝叶斯网络模型包括以下过程:
步骤1:根据系统的结构及故障模式对系统进行故障模式与理象分析,确定贝叶斯网络的节点及贝叶斯网络的拓扑结构;
步骤2:在贝叶斯网络的拓扑结构基础上,根据极大熵方法确定节点的验前分布;
步骤3:根据历史故障数据及专家经验确定节点参数值,即节点的条件概率分布,完成贝叶斯网络模型建立。
所述根据极大熵方法确定节点的验前分布过程为:
HB(a*,b*)=max(HB(a,b))
a≥0,b≥0
a/(a+b)=p0
其中,a为极大熵的验前分布参数;b为极大熵的验前分步参数;p为概率参数;a*和b*分别为参数a和b的最优值;Beta()为贝塔分布;dp为对概率参数p进行求导;HB为极大熵符号;p0为概率参数p的均值。
所述节点的条件概率分布为:
其中,π(p)为验前分布;p(D|p)为样本数据;π(p|D)为节点的条件概率分布;D为样本数据;dp为对参数p进行求导;p为概率参数。
所述故障节点和测量节点间的互信息矩阵为:
其中,I为故障节点和测量节点间的互信息矩阵;Iij为故障节点i和测量节点j之间的互信息;m为故障节点的数量;n为测量节点的数量;P为故障节点的概率值;fi=1表示为故障节点i处于故障状态,fi=0表示为故障节点i处于正常状态;sj=1表示为配置测量节点j,sj=0表示为不配置测量节点j。
所述故障节点诊断的贡献度为:
Esj=(G-Gsj)/G
G=trace(T)
T=(ITI)T
其中,Esj为故障节点诊断的贡献度;Gsj是根据测点组中去掉第j个测点后的互信息矩阵的特征值的和;G为矩阵所有特征值的和;T为诊断信息矩阵;ITI记为矩阵TT,TT为m×m的满秩矩阵。
所述根据贡献度及测点成本和数量描述优化问题过程为:
将故障节点诊断的贡献度、测点成本和测点数量限制转化为一个目标函数:
其中,为故障节点诊断的贡献度;为测点成本;为测点数量限制;Q是一个惩罚因子,其取值为一个充分大的正数;N为限制的测点数量;D为行向量,其元素都为1;xi为优化问题的解,即测点配置情况;minf(xi)为优化问题。
所述改进的离散二进制粒子群算法为:
步骤1:初始化粒子群,计算粒子的初始位置和初始速度;
步骤2:计算目标函数值,确定个体最优值和全体最优值,并根据粒子群算法的速度更新算法更新粒子速度值;
步骤3:根据迭代次数更新粒子的位置值,如果当前迭代次数小于预设参数,则采用具有全局搜索能力的粒子位置更新算法,否则采用具有局部搜索能力的粒子位置更新算法。
所述粒子的初始位置为:
所述粒子的初始速度为:
vid=vmin+rand()(vmax-vmin)
粒子群算法的速度更新算法为:
vid=ω·vid+c1·rand()·(pid-xid)+c2·rand()·(pgd-xid)
具有全局搜索能力的粒子位置更新算法为:
具有局部搜索能力的粒子位置更新算法为:
当vid≤0时,
当vid>0时,
其中,vmax为速度的最大限制值;vmin为速度的最小限制值;rand()是一个随机数,从区间[0,1]的统一分布中随机产生;i为粒子群的粒子数;d为粒子群的维数,表示系统的可配置测点总数;w为惯性权重,用于平衡算法全局搜索和局部搜索能力;c1和c2表示加速常数,也能起到平衡算法全局搜索与局部搜索能力的作用;s(vid)表示位置xid取1的概率;xid为粒子当前位置;vid为粒子当前速度;pid为粒子当前个体最优值;pgd为粒子当前全体最优值;exp()为指数函数。
所述预设参数为:
cys=r*M
其中,cys为预设参数;r为比例参数;M为最大迭代次数。
本发明具有以下有益效果及优点:
1.本发明考虑了在满足约束条件下的传感器优化配置问题,更符合实际工程应用。
2.本发明同时考虑了测点的故障诊断能力和测量成本问题,然后通过改进的优化算法进行优化处理,从而找到系统最佳的测量节点配置方案。
附图说明
图1为本发明的方法流程图;
图2为本发明的建立系统贝叶斯网络模型的流程图;
图3为本发明的优化问题描述的流程图;
图4为本发明的改进的离散二进制粒子群优化算法流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步的详细说明。
如图1所示为本发明的方法流程图。
步骤1:建立系统的贝叶斯网络模型,包括确定贝叶斯网络的拓扑结构及确定贝叶斯网络的条件概率分布:
首先,根据系统的结构及故障模式对系统进行故障模式与理象分析(FMEA),以此确定贝叶斯网络的节点及贝叶斯网络的拓扑结构,即表示节点间连接关系的有向无环图。
然后,在建立好的贝叶斯网络拓扑结构的基础上,首先根据极大熵方法确定节点的验前分布,然后再根据历史故障数据及专家经验确定节点参数值即节点的条件概率分布。
步骤2:根据贝叶斯网络计算故障节点和测量节点间的互信息矩阵:
在系统配置测量节点时,为了提高对故障的有效诊断能力,需要考虑测点对故障的诊断能力。在贝叶斯网络中测量节点提供的关于故障节点的信息量越大,故障节点变量自身的不确定性改变程度越大。互信息越大,测点能够提供的故障节点的信息量也越大,对故障的诊断能力也越大,这时能更有效地实现系统的故障诊断。
用Iij表示第j个测量节点Sj对第i个故障节点Fi的诊断能力,可以用矩阵I来描述贝叶斯网络中所有测量节点对所有故障节点一一对应的诊断能力,将I称为故障节点和测量节点间的互信息矩阵,表示如下:
其中
式中P表示为概率,fi、sj分别为故障节点和测量节点的具体状态。
步骤3:计算测点对故障诊断的贡献度:
根据故障节点和测量节点间的互信息矩阵确定综合诊断能力指标,即计算测点对故障节点诊断的贡献度。
要保证故障的可识别性就是要求各故障节点对测点的概率影响是互不相同的,即要求故障-测点的互信息矩阵的行向量相互独立。将ITI记为矩阵TT,该矩阵为一m×m的满秩矩阵,并称矩阵T为诊断信息矩阵。此时故障节点信息与测点信息完全包含在诊断信息矩阵T中,因此可以通过提取矩阵T的特征值来达到测点优化的目的。诊断信息矩阵的迹trace(T)代表了矩阵所有特征值的和,也即测点组对所有偏差源的诊断能力总和。因此在测量节点的优化中将诊断信息矩阵的迹作为待选测点的评价指标,也称为综合诊断能力指标,所以以G=trace(T)为目标函数,定义第j个测点对故障节点综合诊断能力的贡献度为综合诊断能力指标:
Esj=(G-Gsj)/G (3)
G=trace(T)
T=(ITI)T (4)
其中Gsj是根据测点组中去掉第j个测点后的互信息矩阵的特征值的和。
步骤4:根据测点贡献度及测点成本和数量描述优化问题:
同时考虑测点的贡献度及成本,将其转化为优化算法待求的目标函数,通过选择最佳的测点配置方案,使得测点对故障的诊断能力最大,同时所需的测点配置成本最小。
步骤5,应用改进的离散二进制粒子群算法进行优化处理,得出测点的优化配置结果:
标准粒子群算法适用在连续搜索空间进行计算,而对于离散的搜索空间,其不能直接加以应用,必须对标准粒子群算法改进。即采用离散二进制粒子群算法来优化离散二进制空间的问题。
如图2所示为本发明的建立系统贝叶斯网络模型的流程图。
首先,根据系统的结构及故障模式对系统进行故障模式与理象分析(FMEA),以此确定贝叶斯网络的节点及贝叶斯网络的拓扑结构,即表示节点间连接关系的有向无环图。
然后,在建立好的贝叶斯网络拓扑结构的基础上,首先根据极大熵方法确定节点的验前分布,然后再根据历史故障数据及专家经验确定节点参数值即节点的条件概率分布。
在确定条件概率分布前需要确定节点的验前分布,本发明采用极大熵的方法确定验前分布。在实际工程应用中,由于网络中的节点都是两态的,所以通常取取Beta(p;a,b)分布作为网络中节点的验前分布。根据专家经验确定参数p的均值p0,然后根据极大熵算法确定参数a和b的最优值a*和b*,从而确定节点的验前分布。
HB(a*,b*)=max(HB(a,b))
a≥0,b≥0
a/(a+b)=p0 (5)
其中
在确定了节点的验前分布后,本发明应用贝叶斯方法,将已经计算获得的验前分布与历史故障样本信息相结合,以此得到节点的验后分布,具体操作如下所示:
其中,π(p)表示验前分布,p(D|p)表示样本数据,π(p|D)而表示验后分布。
如图3所示为本发明的优化问题描述的流程图。
同时考虑测点的贡献度及成本,将其转化为优化算法待求的目标函数,考虑d个测点的配置成本及贡献度分别为csj(j=1,2,...,d),Esj(j=1,2,...,d),通过选择最佳的测点配置方案,使得测点对故障的诊断能力最大,同时所需的测点配置成本最小。设变量
则考虑测点贡献度、测点成本及实际中所需测点数量限制条件的测点优化配置问题可表示为:
应用离散二进制粒子群算法解决测点优化配置问题的关键是如何编码。这里用xi表示第i个粒子的取值,每一个粒子取值xi表示成优化问题的一个解。xi=[xi1,xi2,...,xid],d表示粒子的维数,在这里代表可配置测点总数。xij的值表示第i个粒子的测点j的配置情况,其值取值为0或1。如果xij=1表示第i个粒子的j点将配置测点,否则j点不配置测点。
本发明将上述优化模型进行转化,得到如下优化问题的目标函数,即粒子更新的适应度函数:
其中,Q是一个惩罚因子,其取值为一个充分大的正数。D为d维的行向量,其元素都为1。N为实际中限制配置的测点的数量。这里求目标函数的最小值即可。
粒子的位置由下式初始化:
粒子的初始速度vij按下式随机初始化:
vid=vmin+rand()(vmax-vmin) (15)
其中vmax和vmin表示速度的最大最小限制值。其值决定粒子在一次迭代中最大的移动距离。若较大,搜索能力增强,但是粒子容易飞过最优解。较小时,开发能力增强,但是容易陷入局部最优,应根据实际情况适当取值。
如图4所示为本发明的改进的离散二进制粒子群优化算法流程图。
标准粒子群算法适用在连续搜索空间进行计算,而对于离散的搜索空间,其不能直接加以应用,必须对标准粒子群算法改进。即采用离散二进制粒子群算法来优化离散二进制空间的问题。粒子群算法的速度更新公式为:
vid=ω·vid+c1·rand()·(pid-xid)+c2·rand()·(pgd-xid) (16)
其中,i为粒子群的粒子数;d为粒子群的维数,在本发明中表示系统的可配置测点总数。其值取得太小容易导致求出的解是局部最优,取得太大会增加搜索时间,导致收敛速度变慢,一般取为20比较合适;w为惯性权重,它起到平衡算法全局搜索和局部搜索能力的作用。一个大的惯性权重有利于全局搜索,而一个小的惯性权重则有利于局部搜索。为获得较好的优化效果,要求其值从1.4到0.4线性递减;c1和c2表示加速常数,也能起到平衡算法全局搜索与局部搜索能力的作用。一般要求c1=c2并且范围在0和4之间,实际应用时通常都取为2;rand()是一个随机数,从区间[0,1]的统一分布中随机产生。
离散二进制粒子群算法的速度更新公式与原始的粒子群算法相同。而粒子位置更新公式不同。为了表示速度的值是二进制位取1的概率,速度的值被映射到区间[0,1],表示为:
这里s(vid)表示位置xid取1的概率,粒子通过式(12)更新它的位值:
而改进后的粒子群位置更新公式。速度的映射公式更改为:
而粒子的位值更新公式更改为:
当vid≤0时,
当vid>0时,
本发明在迭代搜索前期使用式(17)和式(18)所示的粒子位置更新公式,保证算法的全局搜索能力。而在迭代搜索后期使用式(19)、式(20)及式(21)所示的粒子位置更新公式,保证算法的局部搜索能力。这样做可以保证解得全局性及算法的快速收敛性。本发明采用此改进的离散二进制粒子群算法解决测点的优化配置问题。
- 还没有人留言评论。精彩留言会获得点赞!