用于图像和视频编码的自适应二进制化器选择的制作方法
本申请总体涉及数据压缩,且具体地涉及用于图像和视频编码中的自适应二进制化器选择的方法和设备。
背景技术:
在通信和计算机联网中使用数据压缩来高效地存储、发送和复制信息。数据压缩在图像、音频和视频的编码中得到了具体应用。常见的图像压缩格式包括JPEG、TIFF和PNG。新开发的视频编码标准是ITU-T H.265/HEVC标准。其他视频编码格式包括由Google公司开发的VP8和VP9格式。对所有这些标准和格式的演进正在积极开发中。
所有这些图像和视频编码标准和格式基于预测编码,预测编码创建对要编码的数据的预测,然后对预测中的误差(通常称为残差)进行编码以作为比特流发送给解码器。然后,解码器进行相同的预测,并通过从比特流中解码出的重构误差来对其进行调整。编码器处对误差的无损数据压缩经常包括误差的频谱变换以创建变换域系数的块。这通常伴随着有损量化。在解码器处执行相反操作以重构误差/残差。在许多编码方案,通常使用二进制算术编码(BAC)对该数据加上用于做出预测的边信息(例如,帧内编码模式或帧间编码运动矢量)进行编码。这意味着可能需要对数据(这里称为“符号”)的非二进制部分进行二进制化,以创建用于BAC引擎进行编码的二进制数据流。在一些编码器/解码器中,可以使用多级算术编码器而不是二进制算术编码器,在这种情况下,二进制化器被嵌入在多级算术编码器内。
在现有的编码方案中,二进制化器由标准规定。例如,在H.265/HEVC中,二进制化方案(CABAC)与上下文建模非常紧密地结合在一起。在VP8/VP9中,使用预定义的编码树来执行对“令牌”(对已量化系数的幅度进行信号通知的符号)的二进制化。
附图说明
作为示例,参考示出了本发明的示例实施例的附图,在附图中:
图1A以简化框图的形式示出了使用二进制化器和二进制算术编码器对视频进行编码的编码器;
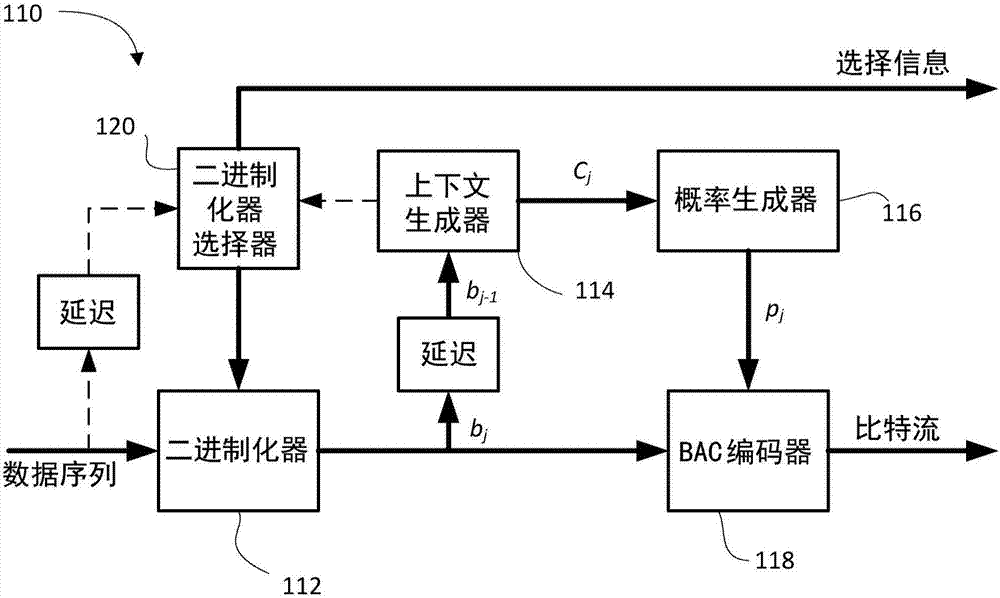
图1B以简化框图的形式示出了具有二进制化器选择器和二进制算术编码器的示例编码器;
图2A以简化框图的形式示出了使用逆二进制化器和二进制算术解码器对视频进行解码的解码器;
图2B以简化框图的形式示出了具有二进制化器选择器和二进制算术解码器的示例解码器;
图3A以简化框图的形式示出了使用二进制化器和多级算术编码器对视频进行编码的编码器;
图3B以简化框图的形式示出了具有二进制化器选择器和多级算术编码器的示例编码器;
图4A以简化框图的形式示出了使用逆二进制化器和多级算术解码器对视频进行解码的解码器;
图4B以简化框图的形式示出了具有二进制化器选择器和多级算术解码器的示例解码器;
图5以图表方式示出了用于VP8和VP9中的令牌的示例编码树;
图6以图表方式示出了用于令牌的已修改编码树的示例;
图7A以流程图形式示出了使用二进制化器选择对图像进行编码的示例过程;
图7B以流程图形式示出了使用二进制化器选择对比特流进行解码以重构图像的示例过程;
图8以框图形式示出了使用自适应二进制化器选择的编码器的示例;
图9以框图形式示出了使用自适应二进制化器选择的解码器的示例;
图10以流程图形式示出了使用自适应二进制化器选择来对图像进行编码的示例过程;
图11以流程图形式示出了用于使用自适应二进制化器选择来对比特流进行解码以重构图像的示例过程;
图12示出了编码器的示例实施例的简化框图;以及
图13示出了解码器的示例实施例的简化框图。
在不同的附图中已使用类似的附图标记来表示类似的组件。
具体实施方式
本申请描述了用于对图像和/或视频进行编码和解码的方法和编码器/解码器。
在第一方案中,本申请描述了一种在视频或图像解码器中从比特流中解码出图像的方法,所述比特流具有针对块组的首部信息,所述解码器具有用于将比特流转换为二进制码(bin)序列的算术解码器,所述解码器具有将二进制码转换为符号的缺省二进制化器。该方法包括:从比特流中获得首部信息;根据所述首部信息确定关于针对所述块组的二进制码序列要使用已修改二进制化器而不是所述缺省二进制化器;以及使用所述已修改二进制化器对所述二进制码序列进行逆二进制化,以从所述二进制码序列中重构符号序列。
在另一方案中,本申请描述一种在图像或视频编码器内对图像进行编码以生成编码数据的比特流的方法,所述图像具有块组,所述编码器具有将二进制码转换为编码数据的比特流的算术编码器,所述编码器具有将符号变换为二进制码的缺省二进制化器。该方法包括:针对所述块组,确定要使用已修改二进制化器而不是所述缺省二进制化器来对所述块组内的符号序列进行二进制化;使用所述已修改二进制化器来对所述符号序列进行二进制化以生成二进制码序列;使用所述算术编码器对所述二进制码序列进行算术编码以生成编码数据的比特流;以及在所述比特流中插入对要关于所述二进制码序列使用所述已修改二进制化器而不是所述缺省二进制化器进行指示的首部信息。
在又一方案中,本申请描述了一种在视频或图像解码器中从比特流中解码出图像的方法,所述解码器具有用于将比特流转换为二进制码的算术解码器,且所述解码器具有基于与符号字母表相关联的概率分布来构建的二进制化器。该方法包括:使用所述二进制化器对二进制码序列进行逆二进制化,以产生重构符号,所述二进制码序列是从所述比特流中算术解码出的,且对应于来自符号字母表的编码符号;基于所述重构符号更新所述概率分布,以产生已更新概率分布;以及基于所述已更新概率分布来确定已更新二进制化器,以用于对第二符号序列进行逆二进制化来产生第二重构符号。
在又一方案中,本申请描述了一种在图像或视频编码器内对图像进行编码以生成编码数据的比特流的方法,所述编码器具有将二进制码转换为所述编码数据的比特流的算术编码器,且所述编码器具有基于与符号字母表相关联的概率分布来构建的二进制化器。该方法包括:使用所述二进制化器对来自所述图像的符号进行二进制化,以产生二进制码序列对所述二进制码序列进行算术编码,以产生所述比特流;基于所述符号更新所述概率分布,以产生已更新概率分布;以及基于所述已更新概率分布来确定已更新二进制化器,所述已更新二进制化器用于在对第二符号进行二进制化时使用以产生第二二进制码序列。
在又一方案中,本申请描述了配置为实现这种编码和解码的方法的编码器和解码器。
在又一方案中,本申请描述了存储计算机可执行程序指令的非瞬时计算机可读介质,所述计算机可执行程序指令在被执行时将处理器配置为执行所描述的编码和/或解码的方法。
本领域普通技术人员将通过结合附图阅读以下示例的描述,来理解本申请的其他方面和特征。
将会理解,本申请的一些方案不限于图像或视频编码,并且在一些实施例中可以应用于一般的数据压缩。
在下面的描述中,参考用于视频编码的H.264/AVC标准、H.265/HEVC标准、VP8格式、VP9格式等描述一些示例实施例。本领域的普通技术人员将理解,本申请不限于那些视频编码标准和格式,而是可以应用于其它视频编码/解码标准和格式,包括可能的未来标准、多视点编码标准、可分级视频编码标准、3D视频编码标准和可重配置视频编码标准。类似地,就参考具体图像编码标准和格式而言,将理解,所描述的过程和设备可结合其他标准(包括未来的标准)来实现。
在随后的描述中,当提到视频或图像时,术语帧、图片、切片(slice)、分片(tile)、量化组和矩形切片组可以在某种程度上互换使用。本领域技术人员将理解,图片或帧可以包含一个或多个切片或片段。在一些情形中,一系列帧/图片可称为“序列”。其他术语可在其他视频或图像编码标准中使用。还将认识到,取决于可应用的图像或视频编码标准的具体要求或术语,某些编码/解码操作可以逐帧执行,而一些操作逐切片执行,一些操作逐图片执行,一些操作逐分片执行,还有一些操作逐矩形切片组执行等。在任何特定实施例中,适用的图像或视频编码标准可以确定是否关于帧和/或切片和/或图片和/或分片和/或矩形切片组等来执行以下描述的操作,视情况而定。相应地,根据本公开,本领域普通技术人员将理解,本文描述的特定操作或过程以及对帧、切片、图片、分片、矩形切片组的特定引用对于给定实施例是否适用于帧、切片、图片、分片、矩形切片组、或者其中的一些或全部。其还适用于编码树单元、编码单元、预测单元、变换单元、量化组等,这些将通过以下描述而变得清楚。
在下面的描述中,描述了涉及来自VP8和VP9的示例二进制化器(特别是用于令牌的编码树)的示例实施例。将会理解,VP8和VP9中的令牌是“符号”的一个示例,并且本申请不限于“令牌”。还将理解,尽管本申请的示例实现可以涉及VP8、VP9或该格式的演进,但是其不限于这样的编码方案。还将会理解,本申请可以应用于除了编码树之外且除了本文所描述的特定编码树之外的二进制化器。
在本申请中,术语“和/或”旨在覆盖列出元素的所有可能组合和子组合,包括列出元素的单独的任意一个、任意子组合或所有元素,而不是必须排除附加元素。
在本申请中,短语“...或...中的至少一个”旨在覆盖列出元素的任意一个或多个,包括列出元素的单独的任意一个、任意子组合或所有元素,而不是必须排除任何附加元素,且不是必须要求所有元素。
现在参考图1A,图1A以简化框图的形式示出了用于对视频进行编码的编码器10。该示例编码器涉及上下文建模之前的二进制化。换言之,针对被二进制化的二进制码而不是针对输入数据序列的预二进制化符号来确定上下文。
编码器10包括二进制化器12,二进制化器12将输入数据符号序列(其可包括已经通过其它编码处理(包括频谱变换、量化、预测操作等)生成的数据)转换成二进制码序列b1,b2,…bj-1,bj…。
编码器10还包括上下文生成器14。为了编码二进制码bj,上下文生成器14根据编码历史(例如,bj-1bj-2…和可用的边信息,如,bj在变换块的位置)确定上下文Cj。概率生成器16然后根据Cj和编码历史bj-1bj-2…确定pj,例如,出现在相同上下文下Cj下的已编码二进制符号。
给定针对bj的上下文Ci,二进制算术编码(BAC)编码器18基于所确定的概率pj对bj进行编码。BAC编码器18输出算术编码数据的比特流。换言之,BAC编码器18依赖特定于所确定的针对正被编码的二进制码的上下文的概率。在一些实施例中,例如H.265/HEVC,二进制化与上下文模型密切相关。例如,H.265/HEVC规定将量化的变换系数二进制化为符号比特、重要性系数标记、大于1标记等。这些二进制语法元素中的每一个可具有其自己的定义上下文模型,用于确定上下文,且因此用于确定与由BAC用于编码的语法元素相关联的概率(在H.265/HEVC的情况下,其是上下文自适应的)。
图2A以简化框图的形式示出了对应于图1A的示例编码器10的示例解码器50。示例解码器50包括BAC解码器52。BAC解码器52接收用于解码比特流的概率pj。概率pj由概率生成器56提供,并且特定于由上下文生成器54指定的上下文Cj。将会理解,上下文建模、上下文的确定以及概率确定与在对应的编码器10中执行的相同,以使得解码器50能够精确地解码比特流。逆二进制化器58基于由BAC解码器52输出的已解码的二进制码序列来重构符号序列。
本申请还可以适用于多级算术编码(MAC)的情况。这种类型的编码处理由来自字母表的符号形成的序列,该字母表的基数(cardinality)大于2。在MAC中,使用二叉搜索树来表示A,其中,A中的每个符号对应于二叉搜索树中独一的叶子。由此,为了编码和解码A中的符号a,对由从根到与a相对应的叶子的分支组成的路径进行编码和解码。要注意,可以采用约定来标记左分支“0”和右分支“1”,或采用任何其他约定来用{0,1}中的元素标记分支。观察到字母表A的二叉搜索树表示是MAC的一部分。因此,可将MAC与针对原始序列所设计的上下文模型一起使用。
现在参考图3A,图3A以简化框图的形式示出了用于对视频进行编码的编码器30。编码器30包括用于根据上下文模型确定上下文的上下文生成器32和用于确定与给定上下文相关联的概率的概率生成器34。该示例编码器30涉及上下文建模之后的二进制化。换言之,针对输入数据序列的预二进制化符号确定上下文,且然后在MAC编码器36内对该序列进行二进制化,MAC编码器36包括二进制化器38作为其一部分。在一些实施例中,二进制化器38可以采用二叉搜索树的形式,该二叉搜索树用于在给定针对符号确定的上下文的情况下将该符号转换为二进制串。
在图4A中示出了解码器70的对应简化框图。解码器70包括具有集成的逆二进制化器74的MAC解码器72,并且从上下文生成器76和概率生成器78接收用于对输入的编码数据比特流进行解码的概率信息。
现在将参考图5,图5示出了示例系数编码树500。该示例中的树500是用于编码“令牌”的编码树,该“令牌”表示VP8和VP9中的已量化变换域系数。VP8和VP9中的令牌是指示已量化变换域系数的幅度的二进制串。如下对其进行定义:
上面的dct_cat1、...、dct_cat6各自对应于有限的值集合。为了确定集合中的精确的值,要对附加比特进行编码和解码。例如,在对dct_cat1进行解码之后,要对附加比特进行解码以确定该值是5还是6。类似地,在对dct_cat2进行解码之后,要对两个附加比特进行解码以确定{7,8,9,10}中的值。对于dct_cat3到dct_cat5,分别需要3、4和5个附加比特。对于dct_cat6,需要11个附加比特。此外,对于除DCT_0和dct_eob之外的任何令牌,要编码和解码符号比特。
为了使用树500来解码令牌,解码器从根节点(0)开始并且遵循到与令牌相对应的叶子节点的路径。每个内部节点具有相关联的二元概率分布,该相关联的二元概率分布与是采用左路径还是采用右路径相关联。假设存在11个内部节点,这意味着存在11个二元分布。
基于平面类型、扫描位置和附近系数来针对令牌确定上下文。在VP8和VP9中有96个上下文,这意味着有1056个二元概率分布(11x96),因为每个上下文都有其自己的概率分布集合。这些概率分布可以存储在数组中,该数组被定义为:
Prob coeff_probs[4][8][3][num_dct_tokens-1];
coeff_probs通常对于帧/图片或片段而言是固定的。可以由编码器将其信号通知给解码器。
图5的示例编码树500可以表达如下:
编码器和解码器中的二进制算术编码引擎将内部概率分布用于对令牌(即,二进制化串)的比特进行算术编码。将会理解,二进制化器的结构被树500所固定,并且如果需要的话,随着时间仅调整针对给定上下文的内部概率。
对熵编码方法的压缩性能的理论极限的分析揭示了:在BAC的实际实现中,非归一化压缩率(其被定义为以比特为单位的压缩数据序列的长度)关于二进制序列长度n线性增长。要注意,(归一化)压缩率被定义为非归一化压缩率与输入序列长度的比率,即针对每输入符号的平均比特数。相应地,提高压缩效率的可能方法之一是改善二进制化的质量或功效,以减小二进制序列长度n。如上所述,在现有的编码标准(如H.265/HEVC和VP8/VP9中的上下文自适应BAC(CABAC))中,二进制化器被合并(bake)到上下文建模中。具体地,针对给定的上下文,二进制化器是固定的。二进制化基于规定如何将非二进制数据(例如,已量化系数)划分为二进制串的固定的树或固定的语法定义。所发生的任何二进制化与上下文和变换系数数据本身密切相关,而不与任何可用概率信息密切相关。
本申请提议向解码器发信号通知要使用已修改二进制化器而不是缺省二进制化器。编码器可以在以下情况下确定使用已修改二进制化器:其预期与使用缺省二进制化器的情况相比,已修改二进制化器将导致更短的二进制序列。二进制化器中的这种改变不是必然是上下文的确定函数,这意味着在相同的上下文中(在不同的块或图片中),编码器/解码器可以根据编码器做出的选择使用不同的二进制化器。
在一些示例实施例中,二进制化器是预先设计的,并且编码器从两个或更多个预定义二进制化器之间选择已修改二进制化器,该两个或更多个预定义二进制化器之一是缺省二进制化器。在一些其他示例实施例中,已修改二进制化器可以在编码器上即时地构建。解码器可以在比特流中接收新构建的二进制化器的细节,或者可以使用与编码器相同的处理来自己构建已修改二进制化器。在一些情况下,作为构建已修改二进制化器的机制,编码器信号通知对缺省二进制化器的改变。
二进制化器中的改变可以基于块、块系列、切片、图片或图像/视频数据的任何其它分组(grouping)来做出,并且可以在与分组相关联的首部中作为首部信息来信号通知。
对使用已修改二进制化器的确定可以基于多个因素。例如,其可以基于数据序列的编码历史。在一些情况下,其可以基于与上下文相关联的历史概率或估计概率。在一些情况下,其可涉及确定或估计已量化变换域系数的编码分布以及构建更好地匹配所确定的编码分布的新编码树。根据对示例实施例的以下描述,本领域普通技术人员将理解其它机制。
现在将参考图1B和2B,其分别示出了使用自适应二进制化器选择的编码器110和解码器150的简化框图。
编码器110包括上下文生成器114、概率生成器116和用于从二进制化序列中生成编码比特流的BAC编码器118。在编码器110中,二进制化器选择器120构建或选择用于二进制化输入数据序列的二进制化器112(例如,可能从预定义候选二进制化器的有限集合构建或选择)。关于选择的信息(标记为选择信息)可以与用于存储或发送的编码比特流(标记为比特流)组合(例如,复用)。在一些实施例中,选择信息被编码在首部信息字段内。
二进制化器选择器120的构建/选择可以基于数据序列的编码历史。其可以取决于具体代码或序列的概率分布,无论是根据经验确定还是基于先前编码的数据估计。在一些实施例中,上下文信息可以由二进制化器选择器120接收。
解码器150包括BAC解码器152、上下文生成器154和概率生成器156。BAC解码器对编码数据的输入(解复用)比特流进行解码,以重构二进制序列。逆二进制化器158对二进制序列进行逆二进制化,以重构符号序列。逆二进制化器158由二进制化器选择器160至少部分地基于选择信息流中的信息来选择/构建。如上所述,在一些情况下,可以从编码数据的比特流的首部字段中提取选择信息。在一些实施例中,该信息可以包括标识多个预定义二进制化器中的一个预定义二进制化器的信息、指定逆二进制化器158的结构的信息、指定解码器150根据其来构建对应的逆二进制化器158的概率分布的信息、或使解码器150能够选择或构建逆二进制化器158的其他这样的信息。
现在还参考图3B和4B,其分别示出了使用自适应二进制化器选择的编码器130和解码器170的附加示例的简化框图。这些示例还包括二进制化器选择器以及将关于二进制化器的选择/构建的信息从编码器130传递给解码器170。
在下面的示例实施例中,图5中所示的缺省编码树是示例缺省二进制化器。各个实施例详细说明可如何选择或构建已修改二进制化器,以及解码器如何确定使用或构造哪个二进制化器。
VP8和VP9中缺省编码树的结构基于令牌(即,符号)的预期分布。针对给定块组的令牌的实际分布可能偏离所假定的分布。要注意,令牌的分布(有时被称为“令牌的边缘分布”)不同于在coeff_probs数组中指定的内部节点概率,其以二元分布的汇集的形式为BAC所使用。令牌的边缘分布可以由长度为12的向量指定,其中每个元素对应于不同令牌的概率,且所有令牌概率之和等于1。对应地,块组(例如,切片/图片/帧)中令牌的经验分布是如下边缘分布:其可被定义为长度为12的向量,使得每个元素对应于在该块组中出现令牌的归一化频率。具体而言,设n表示图片/帧中令牌的总数,并且设fi表示令牌i,0≤i<12出现在图片/帧中的次数。则向量中的第i个元素等于且向量是:
为了方便起见,下面我们还可以使用非归一化频率向量
(f0,f1,…,f11)
其有时被称为非归一化经验分布。
设表示用于对在VP8和VP9中定义的缺省系数编码树中的令牌i进行表示的二进制码的数量:
因此,如果使用缺省系数树,则要编码和解码的切片/图片/帧中的二进制码的总数是
设li表示通过使用所选择的不同于缺省系数编码树的二进制化器来表示令牌i所使用的二进制码的数量。整体而言,(l0,l1,…,l11)被称为二进制化器的长度函数。很容易看到,只要
则所选择的二进制化器减少了二进制码的总数,且节省通过来给出。为了找到满足上述不等式的二进制化器,可以在具有12个叶子节点的候选树的集合中执行搜索,该具有12个叶子节点的候选树是编码器和解码器都已知的,例如,定义在如Golomb码、Gallager-Voorhis码等的规范中。通过构建来确定二进制化器的备选方法是构造针对给定概率分布具有长度函数(l0,l1,…,l11)的霍夫曼编码树,并使用该霍夫曼编码树作为二进制化器。
要注意,不是必须显式地构建霍夫曼编码树。事实上,二叉码编码树满足以下条件可能就足够了:
对于任何i≠j,如果fi>fj,则li≤lj
要注意,霍夫曼编码树满足上述条件,并因此可以作为候选包括。还要注意,一旦信号通知了新的二进制化器,要使用新的二进制化器来解译概率分布,即,coeff_probs。也就是说,coeff_prob[a][b][c][i]表示新的二进制化器中内部节点i处的二元分布,其中,a、b、c是根据平面类型、coeff位置和附近系数导出的上下文。
从预定义的二进制化器选择
在一个实施例中,编码器和解码器二者都具有在存储器中定义的两个或更多个预定义二进制化器,其中之一是缺省二进制化器。例如,在使用编码树的二进制化的情况下,可存在缺省编码树和一个或多个备选编码树。在一些示例中,可以基于符号(例如,令牌)的不同边缘分布来开发备选编码树。
编码器(具体地,二进制化器选择器)可针对块组(例如,切片、帧、图片、图片组等)确定是使用缺省二进制化器还是使用备选二进制化器中的一个。例如,编码器可以确定或估计针对该块组的令牌的分布。为了实际确定分布,编码器可能需要使用二次(two-pass)编码。备选地,编码器可以估计分布,可能是基于来自一个或多个先前块组的统计来估计分布。编码器处的二进制化器选择器确定使用哪个二进制化器来对块进行编码,且然后在与该块组有关的首部信息中信号通知该选择。
在一些情况下,向解码器信号通知二进制化器可包括使用首部信息内的标记或码。在单个备选二进制化器的情况下,编码器可使用二元标记来指示是否正在使用缺省二进制化器。在多个备选二进制化器的情况下,编码器可包括用来对要使用哪个二进制化器解码块组进行指示的码。
叶子节点的重新分布
在一个实施例中,缺省二进制化器的结构保持不变,但编码器可以信号通知令牌的重新分布,即,针对将哪些符号/令牌指派给哪些叶子节点的改变。例如,参考VP8和VP9编码树,编码器可以确定指派给具体叶子节点的令牌应该被重新布置以提高具体块组的二进制化的效率。在这种情况下,可以通过在首部字段中指定令牌的顺序来向解码器信号通知该重新布置。内部系数概率的分布(coeff_prob数组)保持不变。
例如,在图5中,存储dct_eob的叶子节点和存储DCT_1的叶子节点可能被交换,即,在交换后,具有到根节点的短路径的前者存储DCT_1,且具有较长路径的后者存储dct_eob。使用现有树的优点之一是对熵编码的简单设计,其也与VP8和VP9中的现有设计后向兼容。观察到在这些情况下,BAC解码逻辑不需要改变,因为:
1.其可以使用现有设计来确定是否到达叶子节点,以及
2.存储在coeff_probs中的概率对应于系数编码树中的相同内部节点。
对树的唯一改变是改变了存储在叶子节点中的相应令牌。由此,当use_new_coeff_coding_tree_flag等于1时,我们可以通过使用数组T[num_dct_tokens]来指定新的二进制化,其中,T[i](i=0,...,num_dct_tokens-1)指定存储在第(i+1)个(在图5中从左数到右)叶子节点处的令牌。示例数组如下:
新的树结构
代替保持编码树的缺省形状,编码器可以确定更好地拟合实际或估计的边缘令牌分布的新的树结构。然后,编码器可以在块组的首部信息中向解码器信号通知该新结构。作为示例,新的系数编码树可被解析为数组T[2*(num_dct_tokens-1)],其中应用以下约定:
1.如果T[i]在{0,-1,-2,...,-num_dct_token中,则T[i]是叶子节点,且-T[i]是令牌,即0指示dct_eob,1指示DCT_0等。
2.如果T[i]是偶数整数,则T[i]是内部节点,其左子节点在位置T[i]处,且其右子节点在位置T[i]+1处。注意,如果T[i]是偶数,则通过约定,T[i]不小于i+1,即,子节点总是出现在它们的父节点之后。
3.T[0]是根节点的左子节点,T[1]是根节点的右子节点。
参考图6,其示出了用于VP8和VP9令牌的备选编码树600的一个示例。下面是用于定义和信号通知图6所示的备选编码树600的数组T的示例:
T的长度函数可以被验证为是(2,2,3,3,4,4,5,5,6,6,6,6)。
上述数组T被构建为便于解析和树表示。为了进行编码和发送,T可以被变换到另一个数组T′以便于熵编码,其中从T到T′的变换是可逆的,即T可以从T′完全重构。例如,如果T[i]是正的,则T[i]≥2且始终是偶数。因此,代替直接对T[i]进行编码,编码器可对T′[i]=(T[i]-2)>>1进行编码。在解码器侧,在解码T′[i]之后,可以将T[i]重构为T[i]=T′[i]*2+2。
该编码器可通过首先确定或估计针对块组的边缘令牌分布(即,在对块组编码时每个令牌出现的归一化频率)确定新的树结构。根据该信息,编码器可在然后确定更好地拟合边缘分布的编码树(例如,霍夫曼编码树)。在一些实现中,编码器可以通过使用由令牌的频率计数组成的非归一化经验分布而不是归一化边缘分布来确定编码树。
在一些实施例中,编码器可以在确定拟合边缘分布的编码树之前过滤边缘令牌分布或等效地非归一化经验分布。例如,小于阈值的频率计数可被非归一化经验分布中的缺省值(例如,0、1或已知正整数)替换。不失一般性,假设非归一化经验分布由(f0,f1,…,f11)给出,其中fi表示令牌i(0≤i≤11)的频率计数。然后,对于每个i,如果fi<Th(其中Th表示阈值),则否则,然后将所得到的向量用于确定编码树。在过滤之后,我们看到频率计数小于阈值的令牌被等同地对待,并且将在确定编码树的过程中具有确定且有限的影响。因此,通过使用过滤,编码器避免了在没有足够的经验数据时在确定编码树中的过度拟合。要注意,该阈值可以是先验确定的常数或可作为令牌总数(即,所有频率计数的总和)的函数。
将会理解,在仅实现树的部分更新的情况下,在一些实施例中可以不信号通知整个树。这可被用于平衡信号通知新的二进制化器的成本和二进制码节省的益处。例如,可能希望基于5中的缺省树来信号通知新的树,其中
1.改变限于对应于{dct_eob,DCT_0,DCT_1,DCT_2,DCT_3,DCT_4}的子树;以及
2.以内部节点(12)为根节点的子树保持不变。
更新概率
如上所述,VP8和VP9缺省树的内部节点处的二元概率分布存储在coeff_probs数组中。如果使用新的树,则解码器可能需要将与现有缺省树相关联的概率分布(在coeff_probs中)映射到新的树。
设T1和T2指示表示具有N个符号的相同字母表A={a0,…aN-1}的两个二叉树。假定T1和T2都是满的,并且因此它们正好具有N-1个内部节点。设(p1,0,…p1,N-2)表示T1的N-1个内部节点处的二元概率分布:例如,p1,0表示第一内部节点(根)处的概率1(或等效地,采用右侧分支),p1,1表示第二内部节点处的概率1(或等效地,采用右侧分支),等等。要注意,对内部节点进行标记的顺序无关紧要,换言之,任何已知的顺序都将适用于本解决方案。类似地,设(p2,0,…p2,N-2)表示T2的N-1个内部节点处的二元概率分布。假设(p1,0,…p1,N-2)和(p2,0,…p2,N-2)是从A上的同一边缘分布学习得到的。因而挑战是将(p1,0,…p1,N-2)映射到(p2,0,…p2,N-2),且反之亦然。
设(q0,…qN-1)表示A上的该公共边缘分布,其中qi(0≤i<N),表示ai的概率。从而通过使用以下两阶段过程解决了该挑战:
1.在T1中,根据(p1,0,…p1,N-2)确定(q0,…qN-1)。
2.在T2中,根据(q0,…qN-1)确定(p2,0,…p2,N-2)。
上述第一级可通过使用树遍历的方法来实现(例如,深度优先或广度优先),以从上到下地填入概率(自上而下)。下面是一个深度优先迭代法的示意性示例,其中,不失去一般性,假定根节点被标记为“0”且对应于p1,0:
作为另一示例,可将第一阶段的广度优先方案描述为:
通过类似的方式,第二阶段可以通过遍历树来实现,以从下到上地填入概率(自下而上)。在以下伪代码中使用后序深度优先横向法示出了示例方法:
因此,在一些实施例中,可以对更新概率的过程进行以下改变,以减少信令开销。代替信号通知针对coeff_probs中的条目(例如,1056个)中的每个的更新标记,本解决方案可以如下推断(未在比特流中存在的)标记。假设给出二进制化器(或等效地,系数编码树)。要注意,coeff_probs中的每个条目对应于系数编码树中的内部节点。如果与在coeff_probs中的条目相关联的更新标记被信号通知为1,且该条目对应于节点a,则关联于与从根节点到节点a的路径中的节点相对应的条目的所有更新标记都被推断为1,且不需要在比特流中信号通知。例如,如果与图5中的节点(8)相关联的更新标记被信号通知为1,则与节点(6)、(4)、(2)、(0)相关联的更新标记被推断为1,且不需要在比特流中信号通知。
在另一实施例中,更新标记可以与系数编码树中的级别相关联,其中,根节点处于级别0,其子节点处于级别1,等等。如果与级别L>=0相关联的更新标记被信号通知为1,则与所有1<L的级别相关联(即更接近根级别)的更新标记被推断为1。
将会理解,上述树遍历方法是示例。可以使用其他遍历方法(例如,迭代深化深度优先搜索)(例如,以满足如存储器复杂度、调用堆栈限制等的应用需求)。还将理解,在一些实施例中,可在上述针对概率的两阶段映射过程中填入概率时使用定点运算。要注意到,可以在中间步骤中使用不同的(更高的)精度或甚至浮点运算,以在最终结果中获得更好的精度。
基于概率的解码器构造的二进制化器
在上述实施例中,编码器确定/选择二进制化器,然后将选择信号通知给解码器。在一个情况下,编码器传送其从多个预定义的二进制化器中的选择。在另一情况下,编码器指定二进制化器。例如,其可以发送对用于构建已修改二进制化器的令牌的结构和指派进行指定的数据。在另一示例中,其可以信号通知对解码器可用来创建已修改二进制化器的令牌的缺省结构或指派的改变。
在又一实施例中,编码器不指定新确定的编码树或其他二进制化器的结构或令牌,而是代之以发送已更新概率信息和对解码器应基于该已更新概率信息来构建新二进制化器的指示。
再次使用VP8和VP9编码树作为示例,编码器可传送内部节点概率分布,例如coeff_probs数组,或对该数组的改变。编码器还信号通知解码器是否应构造新的树。编码器可以基于coeff_probs概率分布与最初设计缺省编码树所针对的概率之间的差异程度来确定新的树是否有正当理由。在一个或多个内部节点概率之间超出阈值偏差可信号通知应该使用新的编码树。在另一实施例中,编码器获得令牌的边缘分布,并根据那些概率值确定是否应该构建新的树。编码器可以使用上述树遍历技术之一来根据内部节点概率获得令牌的边缘分布。在令牌的边缘分布中超出阈值改变可以确定应该构建新的树。例如,编码器可以指示解码器使用首部中的标记来构造新的树。
解码器然后可以使用上述树遍历技术来根据已更新coeff_probs概率分布确定令牌的对应边缘分布。然后,可以使用令牌的边缘分布来确定合适的编码树,该合适的编码树导致使用较少二进制码来编码数据。
在又一实施例中,编码器不指示解码器是否应该创建新的二进制化器。相反,解码器自己确定是否应该构建和使用新的树。该确定可以基于在已更新coeff_probs数组中指定的概率分布是否已经超出阈值改变。在另一实施例中,每当更新coeff_probs数组时,解码器计算令牌的边缘分布,并且根据令牌的边缘分布确定是否应该构建新的树,例如基于令牌的边缘分布是否偏离缺省树(或者,如果使用了已修改编码树,则为当前树)所基于的概率超过阈值量。
上下文自适应的二进制化器选择
在一些上述实施例中,选择单个二进制化器来对块组(例如帧/图片)的令牌进行编码。在另一实施例中,可以在块组(例如图片/帧)内使用多个可用的二进制化器,并且针对当前的非二进制符号,根据上下文信息(例如,针对该符号导出的上下文)选择该多个可用的二进制化器中的一个二进制化器。
使用VP8和VP9的元素作为示例来说明该解决方案,其中:
1.针对12个令牌定义了96个上下文。
2.在对令牌进行编码之前,从已知信息中导出上下文:平面类型、coeff位置和附近系数。
3.在解码令牌之前,从已知信息中导出上下文:平面类型、coeff位置和附近系数。
4.对于每个上下文,可以估计在图片/帧中的令牌上的经验分布。
在对令牌进行编码和解码之前,上下文对于VP8和VP9中的编码器和解码器分别是已知的。
在本实施例中,上下文被用作从候选二进制化器的有限集合中选择二进制化器的基础。在一个示例中,在图片/帧首部中,可在比特流中信号通知将96个上下文映射到二进制化器的表;以及当这样的表在比特流中不存在时,可以使用缺省表。设B={T0,T1,…,TN}(N>1)表示二进制化器的有限集合。该表可被定义为数组M[4][8][3],其中每个条目是B中的索引,即,针对由(a,b,c)给出的上下文(其中0≤a≤4,0≤b<8,且0≤c<3),B中的TM[a][b][c]是所选择的二进制化器。
一旦表M被解析,解码器可在然后根据导出的上下文来针对要解码的每个令牌选择二进制化器。此外,我们注意到,现在应该根据针对由(a,b,c)给出的上下文选择的二进制化器TM[a][b][c]来解译coeff_probs[a][b][c][]中的概率分布。
总而言之,示例解码器可以使用以下过程来解码令牌v:
D1.确定针对在VP#中定义的令牌的上下文(a,b,c)。
D2.将二进制化器T选择为TM[a][b][c]。
D3.使用coeff_probs[a][b][c]和T来解码v。
对应地,示例编码器可以使用以下处理来对令牌v进行编码:
E1.确定针对在VP#中定义的令牌的上下文(a,b,c)。
E2.将二进制化器T选择为TM[a][b][c]。
E3.使用T将v二进制化为二进制串T(v)=b0b1…bl(v),其中l(v)是二进制码的数目,并且T(v)是T中从根到对应于v的叶子的路径。
E4.使用coeff_probs[a][b][c]来编码T(v)。
现在参考图7A,其示出了用于对图像或视频编码器中的图像进行编码的示例编码过程700的流程图。使用包括算术编码器的编码架构来实现过程700,该算术编码器使用算术编码(无论是二进制算术编码还是多级算术编码)将二进制码转换为编码数据的比特流。过程700假定图像已经历图像或视频编码过程以创建符号序列。示例符号可以包括已量化变换域系数的幅度,或表示已量化变换域系数的“令牌”。
编码架构还包括缺省二进制化器。缺省二进制化器的一个示例是针对VP8/VP9中的令牌的缺省编码树。
过程700包括操作702,确定要使用已修改二进制化器而不是针对符号序列规定的缺省二进制化器。对使用已修改二进制化器的确定可以基于:例如,对符号在图像中的归一化出现频率的评估(测量出或估计出),以及对这些频率与缺省二进制化器所基于的这些符号的边缘概率之间的差的评估。
在一些实施例中,操作702可以包括基于测量或估计出的符号的归一化出现频率来构建已修改二进制化器。在一些实施例中,操作702可以包括从多个预构建/预建立的二进制化器中选择已修改二进制化器。
在操作704中,使用已修改二进制化器来对符号序列进行二进制化,以生成二进制码序列。然后,在操作706中,使用算术编码器对二进制码序列进行算术编码,以产生编码数据的比特流。
为了确保解码器可以正确地重构图像,过程700还包括将首部信息插入到比特流中的操作708。首部信息指示要使用已修改二进制化器对与符号序列相对应的二进制码序列进行逆二进制化。将会理解,首部信息可以放置在与一系列块(例如,切片、帧、图片、图片组或块的其他汇集)相对应的首部中。首部信息指示:针对该一系列的块中至少具体符号序列(例如,令牌),解码器要使用已修改二进制化器而不是缺省二进制化器。
在最简单的情况下,首部信息包括对要使用已修改二进制化器进行指示的标记。然后,解码器可以使用边信息(例如,概率信息)来选择或构建二进制化器。在一些其他情况下,首部信息指定符号到缺省结构的叶子节点的分配。在又一些其他情况下,首部信息指定编码树的新结构或修改结构。在又一些情况下,可以在首部信息中指定二进制化器构建的其它细节。
现在参考图7B,其示出了示例解码过程750的流程图。过程750由用于图像或视频的示例解码器实现,示例解码器包括算术解码器,且包括缺省二进制化器(用于将二进制码逆二进制化为重构符号)。示例过程750包括从比特流中提取首部信息,如操作752所示。
首部信息指示是使用已修改二进制化器还是使用缺省二进制化器。相应地,在操作754中,解码器根据首部信息确定要使用已修改二进制化器而不是缺省二进制化器。要注意,在一些情况下,这可以是首部信息中的显式指令,例如对要使用已修改二进制化器进行指定的标记,或者对多个预定二进制化器选项中的具体已修改二进制化器进行指定的索引。在一些其他情况下,首部信息指定已修改二进制化器。例如,其可以指定对缺省二进制化器的改变,例如在编码树的叶子节点之间重新分配符号,或者其可以指定对编码树的结构的改变。在又一些其他示例中,首部信息可以指定二进制化器的全部或部分结构,例如霍夫曼树的结构以及符号在其叶子节点之间的分配。在又一些其它实施例中的任一者中,首部信息可以提供数据,如概率信息(例如,coeff_probs数组),解码器可根据其来确定要使用已修改二进制化器而不是缺省二进制化器。
在操作756中,已修改二进制化器被用于对二进制码序列(其已被从比特流中算术解码出)进行逆二进制化,以重构符号序列。
自适应二进制化器选择
在一些上述实施例中,在比特流中向解码器信号通知二进制化器选择。这可以通过以下方式来进行:发送对选择预先设计的二进制化器进行指定的选择索引或标记,发送对构建已修改二进制化器进行指定的信息,或发送与图像有关的统计数据(例如,概率分布),解码器可根据该统计数据来构造已修改二进制化器。在这些实施例的一些中,为了在最小化要处理的二进制码的数量方面实现最佳性能,使用二次编码:第一遍是收集构造最佳二进制化器所需的统计信息,且第二遍是在编码过程中使用新的二进制化器。在跳过第一遍或用一些启发式方法替代第一遍的实施例中,所得到的二进制化器可能不是最佳的。
依赖于一遍编码的备选方法是“自适应二进制化器选择”,其中,在编码和解码过程期间即时地学习和更新二进制化器。在该解决方案中,在对数据进行编码时,基于数据的不断演变的概率分布来选择(例如,构造/修改)二进制化器。在一些情况下,这可以被称为二进制化器“调谐”。
现在参考图8,其以框图形式示出了具有自适应二进制化器选择的编码器800的一个简化示例。将会注意到,在符号级的二进制化之前定义该示例实施例中的上下文模型,而在一些上述示例中,上下文建模可以发生在二进制化之前或之后。在该示例中,二进制化器和概率分布二者可逐符号改变,且前者至少部分地取决于后者。
编码器800对来自其基数大于2的字母表的符号的数据序列进行编码。编码器800包括确定输入符号的上下文的上下文生成器814以及将概率向量与所确定的上下文相关联的概率生成器816。概率向量被MAC编码器818用作编码分布。编码器800包括生成由MAC编码器818使用的二进制化器820的二进制化器生成器822,其中,二进制化器820的生成至少部分地基于概率向量
在一些实施例中,二进制化器生成器822可以基于概率向量构建新的二进制化器。在一些实施例中,二进制化器生成器822可以从候选二进制化器的有限集合中选择新的二进制化器。然后,在由MAC编码器818进行的MAC编码期间,在符号的二进制化中使用新的二进制化器820。
然后,基于编码符号更新概率分布,即概率向量
图9示出了使用自适应二进制化器选择的示例解码器900。解码器900包括上下文生成器914、概率生成器916和MAC解码器918。编码数据的输入比特流由MAC解码器918算术解码并逆二进制化,以重构符号序列。二进制化器生成器922确定要由MAC解码器918用于关于比特流中的编码符号进行逆二进制化的二进制化器920。二进制化器生成器922将对二进制化器920的确定基于概率生成器916输出的概率分布(概率向量)。一旦MAC解码器918解码了符号,更新概率分布。
将会理解,在一些示例中,符号可以是已量化变换系数、像素值、帧内预测模式、运动向量或运动向量差,或者任何的非二进制语法元素。
在一些实施例中,确定二进制化器还可以取决于是否满足某组条件,例如,从上次确定二进制化器开始,使用相同的上下文已经解码了至少T>1个符号。
在一些实施例中,可以不在每次对符号进行编码/解码之后更新与上下文相关联的概率分布。在这些情况下,一旦选择了上下文,便可例如根据编码器和解码器二者可获得的边信息确定分布。例如,边信息可以包括与分别编码和发送的上下文相关联的概率分布,或者包括可根据其来估计概率分布的编码器和解码器二者可获得的训练序列。
在将二进制化作为不可分割的一部分完全集成到算术编码中的情况下,所描述的自适应二进制化器选择解决方案可以被认为是多符号算术编码的改进设计,其中可以改变符号的排序以便于在给定的字母表A中搜索符号。要注意到,搜索可以是线性的,如在Whitten等在“Arithmetic coding for data compression”,1987,Commun.ACM 30,520-540中所描述的算术多符号编码的所谓“CACM实现”中一样,其中,CACM是“Commun.ACM”的缩写。CACM实现搜索可被定义为:
在A中找到i,使得
cum_freq[i]<=(value-low)/(high-low)<cum_freq[i-1]
在以上所述中,cum_freq是存储累积频率的数组,值是接收的比特串,且[low,high]定义用于编码的当前间隔的范围。要注意到,由于i在编码器处是已知的,搜索过程在编码器处不存在。由于该原因,CACM解码器通常比CACM编码器更复杂。在正常CACM实现中,字母表A中符号的排序是固定的。
有效的搜索策略可以使用二叉树来降低搜索复杂度,其中,树可以随着输入概率分布改变而改变。在这样的示例中,二叉树替换正常CACM实现中的cum_freq。要注意到,线性搜索可以被认为是二分搜索的特殊情况,其中,每个内部节点具有至少一个叶子节点作为其子节点。还要注意到,在一些实施例中,树形可以是固定的,但是给定字母表中的符号与叶子节点之间的映射可根据概率分布而改变。例如,本解决方案可以根据概率对符号排序,以加速线性搜索。
因此,使用自适应二进制化器选择的编码器和解码器可通过根据所确定的概率分布确定/构建二叉树来确定二进制化器。在二叉树中,每个内部节点可以存储二元分布(例如,采用左分支的概率),以便于BAC编码/解码。可以根据与上下文相关联的概率分布导出存储在内部节点处的二元分布。
虽然本文的描述集中于BAC,但是所提出的解决方案同样适用于其它熵编码方法,如二进制V2V(可变长度到可变长度)编码、二进制V2F(可变长度到固定长度)编码以及二进制F2V(固定长度到可变长度)编码。这里,二进制V2V编码将可变长度的二进制输入串映射到可变长度的二进制输出串,二进制V2F编码将可变长度的二进制输入串映射到固定长度的二进制输出串,以及二进制F2V编码将固定长度的二进制输入串映射到可变长度的二进制输出串。此外,所提出的解决方案可被扩展到三进制(基-3)、四进制(基-4)或一般的固定基数D数字系统(D≥2),其中,三进制、四进制和一般的D进制树分别可用于代替二叉树。
现在参考图10,其以流程图形式示出了用于在视频或图像编码器中对图像进行编码的一个示例过程1000。根据编码格式对图像进行处理,以产生符号序列(例如,在一些实施例中,已量化变换域系数)。编码器使用多符号算术编码并使用自适应二进制化器选择来编码该符号序列。
过程1000包括确定针对符号序列中的符号的上下文,如操作1002所指示的。基于上下文模型来确定上下文。在操作1004中,编码器使用针对符号字母表的上下文来确定概率分布。概率分布可以是与符号在字母表中的出现频率相关联的所存储的概率向量或序列。在一些情况下,概率分布特定于所确定的上下文(或在一些情况下,上下文的分组)。
在操作1006中,编码器基于概率分布确定二进制化器。在一些情况下,这可包括基于概率分布从候选二进制化器的集合中进行选择。在其他情况下,其可以包括基于概率分布构造二进制化器。在一些情况下,构造二进制化器可包括修改缺省或现有二进制化器以更好地匹配在操作1004中确定的概率分布。
然后,在操作1008中,使用在操作1006中选择或构建的二进制化器对符号进行二进制化,产生二进制码序列,然后在操作1010中对二进制码序列进行算术编码,以产生编码数据的比特流。
在操作1012中,在该示例中,在编码器返回到操作1002以确定针对下一符号的上下文之前,使用编码符号来更新概率分布。
图11以流程图形式示出了视频或图像解码器中用于对编码数据的比特流进行解码以重构图像的示例过程1100。过程1100包括确定针对比特流中的编码符号的上下文,如操作1102所示。然后,解码器在操作1104中确定(在许多情况下,与所确定的上下文相关联的)概率分布。概率分布可以作为概率的向量或数组存储在存储器中,每个分布与符号字母表中的相应符号相关联,使得操作1104涉及从存储器检索所存储的分布。
在操作1106中,解码器使用概率分布来确定用于对二进制数据进行逆二进制化以重构符号的二进制化器。一旦二进制化器已被确定(或选择),则在操作1108中,解码器对比特流的一部分进行算术解码以重构与二进制化符号相对应的二进制码序列,且在然后在操作1110中,使用所确定的二进制化器对该二进制码序列进行逆二进制化,以重构符号。在操作1112中,基于重构符号来更新概率分布。
树构建示例
如上所述,可以使用各种树遍历方法(例如,深度优先或广度优先)来将边缘分布映射到内部节点概率,反之亦然。在下面的例子中,针对字母表A,根据A上的给定边缘分布(q0,…qN-1)构建二进制化器,且获得内部节点处的概率分布(p0,…pN-2)。不失一般性,假设对(q0,…qN-1)排序,即q0≥q1≥…≥qN-1。要注意到,如果一开始未对(q0,…qN-1)排序,则可以添加排序步骤以确保针对后续过程的输入概率分布被排序。为了构建针对字母表A的具有边缘分布(q0,…qN)的二进制化器T,可使用以下示例过程:
1.将计数器k初始化为0。
2.创建N个具有标签N-1,…,2N-2的节点,使得节点(N-1+i)具有概率qi,0≤i<N,即节点包含A中与该概率相关联的符号。
3.创建具有标签(N-2-k)的内部节点,其子节点是满足下列条件的两个现有节点:
I.该两个节点是它们各自子树的根节点。换言之,该两个节点不是任何其他现有节点的子节点。
II.该两个节点在满足上述条件I的所有节点中具有最小概率。通过和分别表示这两个概率。
4.然后,节点(N-2-k)具有概率并在节点(N-2-k)处的编码概率pN-2-k由给出。要注意,有可能确保且因此pN-2-k始终低于0.5。
5.将k增加1。
6.重复步骤3-5,直到k等于N-2。
上述过程生成具有N-1个内部节点的完整二叉树,该完整二叉树针对字母表A定义了二进制化器T。内部节点处的二元概率分布由(p0,…pN-2)给出,其中,pj是内部节点j(0≤j<N-1)处的概率1(采用右分支)。
可以观察到,以上过程与针对给定分布(q0,…qN-1)构建霍夫曼编码树相同,主要区别在于步骤4,在步骤4中计算概率pN-2-k,0≤k<N-1。在BAC接受pN-2-k的有限精度表示的实际应用中,可在树构建过程中或在构建完整的树T之后量化pN-2-k。要注意到,由于该示例过程可以保证pN-2-k≤0.5,可在存储pN-2-k时节省一个比特(最高有效位):如果BAC内部使用M比特来表示(0,1)中的概率,可以使用M-1个比特来存储pN-2-k,其中M是正整数。
还将会理解,由于在上下文建模中主要使用(q0,…qN-1),且在编码中主要使用(p0,…pN-2),所提出的解决方案实际可使用以下实现:
1.存储并维护(q0,…qN-1)中的元素以作为频率计数,即非归一化,以节省计算和存储复杂度。
2.以作为到BAC的输入所需的算术精确度来存储并维护(p0,…pN-2)中的元素。对于8比特BAC,可以将pi存储为8比特无符号整数(或7比特,如果已知pi是较不可能符号的概率)。
3.上述对的计算可在整数运算中实现。此外,可以通过使用移位运算来对除法进行近似。
自适应二进制化
设xm=x1x2…xm表示来自字母A的要被压缩的序列。对于该例子,假定以下概率模型:假设以A上的未知概率分布从无记忆源发出xm。以初始边缘分布(q1,0,…q1,N-1)开始,模型在每个符号被编码或解码之后如下更新分布
1.初始化i=1。
2.利用分布(qi,0,…qi,N-1),使用算术编码来对xi进行编码/解码。
3.通过包括xi来将(qi,0,…qi,N-1)更新为(qi+1,0,…qi+1,N-1)。
4.将i增加1。
5.重复步骤2-3,直到i等于N。
在上述步骤3中,可以通过使用概率估计器来实现对概率分布进行更新,概率估计器包括例如拉普拉斯估计器、Krichevsky-Trofimov(KT)估计器、有限状态模型或它们的变体。
在上面步骤2中,可注意到,可在对每个xi进行编码或解码之后改变概率分布(qi,0,…qi,N-1),即(qi,0,…qi,N-1)和(qi+1,0,…qi+1,N-1)可能不同。如果发生这种变化,则针对xi+1可能需要新的二进制化器。设Ti表示针对xi的二进制化器。为了适配用于每个xi的二进制化器,可以根据编码分布(qi,0,…qi,N-1)(例如通过使用上述树构建方法)来针对xi生成Ti。因此,编码器侧的上述步骤2可以实现为:
3.Ea.针对字母表A,利用分布(qi,0,…qi,N-1)生成二进制化器Ti,并获得Ti的内部节点处的二元分布(pi,0,…pi,N-2)。
3.Eb.使用二进制化器Ti将xi转换成二进制串。
3.Ec.利用(pi,0,…pi,N-2),使用BAC编码二进制串。
在解码器侧,上面的步骤2可以实现如下:
3.Da.针对字母表A,利用分布(qi,0,…qi,N-1)生成二进制化器Ti,并获得Ti的内部节点处的二元分布(pi,0,…pi,N-2)。
3.Db.利用(pi,0,…pi,N-2),使用BAC来解码二进制串,使得二进制串是从根节点去往Ti中的叶子节点的路径。
3.Dc.将xi解码为A中与以上识别出的Ti中的叶子节点相关联的符号。
在上述的步骤2.Ea/2.Da中,可通过以下方式实现生成Ti:如果(qi,0,…qi,N-1)与(qi-1,0,…qi-1,N-1)之间的差是稀疏的,更新Ti-1。例如,如果Ti-1是针对(qi-1,0,…qi-1,N-1)的霍夫曼树,则可以针对(qi,0,…qi,N-1)将Ti构建为霍夫曼树。要注意,为了检查是否不需要更新Ti,可以进行检查以验证Ti-1是否针对(qi,0,…qi,N-1)满足同属(sibling)特性。如果答案是肯定的,则Ti=Ti-1;否则,可以执行更新。
最后,为了减少在生成Ti时涉及的计算复杂度,一些实施例可仅在每对L>1个符号进行了编码/解码时或者在(qi,0,…qi,N-1)与(q*,0,…q*,N-1)有足够的不同时才更新二进制化器,(q*,0,…q*,N-1)表示A上用于生成Ti-1(即,先前的二进制化器)的边缘分布。(qi,0,…qi,N-1)和(q*,0,…q*,N-1)之间的差可被测量,例如,通过使用Lp范数(p的示例包括1、2和∞)、KL散度、汉明距离、或针对(qi,0,…qi,N-1)在其处同属特性被Ti-1违反的位置的数量。
简化
在一些实施例中,针对给定的字母表A,自适应二进制化可以被应用到较粗集合S,以平衡自适应二进制化的计算成本和二进制码节省的益处,且给定S,如果有必要,使用缺省静态二进制化方案对A的符号进行二进制化。在以上所述中,较粗集合S可具有以下特性:
1.S的基数小于A的基数,且
2.S中的每个符号对应于A中的一个或多个符号。换言之,S中的符号可被视为对A中的一个或多个符号进行合并的结果。
作为例子,假设A={0,±1,±2,…,±32767}。S的较粗集合可被定义为S={s0,s1,s2,s3},其中,s0对应于A中的0,s1对应于A中的±1,s2对应于A中的±2,且s3对应于A中的所有其它符号。
在另一些情况下,针对给定字母表A={0,1,…,N-1},编码/解码过程可通过保持对二进制化器进行定义的树的形状并且根据演变中的分布(qi,0,…qi,N-1)仅改变叶子节点与字母表A中的符号之间的映射,来实现自适应二进制化。设lk表示从树中的根节点到达叶子节点k所需的二进制码的数量。整体而言,(l0,l1,…,lN-1)被称为树的长度函数。设π表示排列{0,1,…,N-1},使得π(k)表示存储A中的符号k的叶子节点的索引。设πi表示在时刻i处选择的排列。因而,给定πi-1、(qi,0,…qi,N-1)和长度函数(l0,l1,…,lN-1),我们的解决方案试图寻找映射(排列)π,使得:
如果不存在这样的πi,则πi=πi-1。如果可能,可通过将符号α与另一符号β,α≠β,交换来实现上述不等式,使得,
如果qi,α<qi,β且则πi(α)=πi-1(β)且πi(β)=πi-1(α)。
备选地,找到针对给定(qi,0,…qi,N-1)和(l0,l1,…,lN-1)最小化的πi。
上下文相关的自适应二进制化
在一些实施例中,动态二进制化器自适应可以是上下文相关的。设xm=x1x2…xm表示来自字母A的要被压缩的序列。假设具有K个上下文的自适应上下文建模方案,针对每个xi,1≤i≤m,该方案从上下文集合中导出上下文Ci,并将每个k,0≤k<K与初始分布(q0,0|k,…q0,N-1|k)相关联。在以上所述中,K是由上下文建模过程定义的正整数。使用算术编码和上述上下文建模方案对xm编码和解码的示例过程可描述如下:
1.初始化i=1,且针对所有k=0,1,…K-1,n(k)=0。
2.使用给定的上下文建模过程导出针对xi的上下文Ci。
3.利用分布使用算术编码来对xi进行编码/解码。
4.通过包括xi来将更新为
5.将i增加1,且将n(Ci)增加1。
6.重复步骤2-3,直到i等于N。
在上述步骤4中,可以通过使用概率估计器来实现对概率分布进行更新,概率估计器包括例如拉普拉斯估计器、Krichevsky-Trofimov(KT)估计器、有限状态模型或它们的变体。
在上述步骤3中,与针对第i个符号xi的上下文Ci相关联的概率分布可不同于且因此可以针对xi使用新的二进制化器。设表示针对xi的二进制化器。因而可以根据分布来针对xi生成例如,通过使用上述的树构建方法。因此,编码器侧的上述步骤3可如下实现:
3.Ea.针对字母表A,利用分布生成二进制化器并获得的内部节点处的二元分布
3.Eb.使用二进制化器将xi转换成二进制串。
3.Ec.利用使用BAC编码二进制串。
在解码器侧,上面的步骤2可以实现如下:
3.Da.针对字母表A,利用分布生成二进制化器并获得的内部节点处的二元分布
3.Db.利用使用BAC来解码二进制串,使得二进制串是从根节点去往中的叶子节点的路径。
3.Dc.将xi解码为A中与以上识别出的中的叶子节点相关联的符号。
在上述的步骤2.Ea/2.Da中,可通过以下方式实现生成:如果与之间的差是稀疏的,更新例如,如果是针对的霍夫曼树,则可以针对将构建为霍夫曼树。要注意到,为了检查是否不需要更新可以检查以验证针对是否满足同属特性。如果答案是肯定的,则否则,需要更新。
为了减少生成时涉及的计算复杂度,上述解决方案可仅在每对上下文Ci之下的L>1个符号进行了编码/解码时或者在与有足够的不同时才更新二进制化器,表示A上用于生成(即,先前的二进制化器)的边缘分布。和之间的差可被测量,例如,通过使用Lp范数(p的示例包括1、2和∞)、KL散度、汉明距离、或针对在其处同属特性被违反的位置的数量。
自适应重排序
在使用多符号算术编码的一些实施例中,动态二进制化器适配可以适于字母表重排序。假设在算术解码器中使用固定搜索策略(例如,CACM解码器中的线性搜索)来确定符号作为解码器输出。设xm=x1x2…xm表示来自字母表A={a0,…aN-1}的要压缩的序列,其中A的基数大于2。对于该例子,假定以下概率模型:假设以A上的未知概率分布从无记忆源发出xm。以初始边缘分布(q1,0,…q1,N-1)开始,模型在每个符号被如上所述地编码或解码之后更新分布,以用于自适应二进制化。
要注意到,可在对每个xi进行编码或解码之后改变概率分布(qi,0,…qi,N-1),即(qi,0,…qi,N-1)和(qi+1,0,…qi+1,N-1)可能不同。如果这样的改变发生,可能需要将A的新排序用于xi+1,以提高搜索性能。设πi表示针对xi确定的排序,其中,πi(j)确定A中的第j个符号aj的索引,j=0,…,N-1。为了适应针对每个xi使用的排序,可根据编码分布(qi,0,…qi,N-1)来针对xi确定πi,例如,如果qi,j>qi,l,通过在解码器使用的固定搜索策略中将aj置于al之前,j≠l。因此,编码器侧的上述步骤2可以实现为:
3.Ea.根据分布(qi,0,…qi,N-1)确定针对字母表A的排列πi。
3.Eb.使用重排序字母表(即,使用πi来排列的A)来编码xi。
在解码器侧,上面的步骤2可以实现如下:
3.Da.根据分布(qi,0,…qi,N-1)确定针对字母表A的排列πi。
3.Db.使用重排序字母表(即,使用πi来排列的A)和分布(qi,0,…qi,N-1)(或等效地,其使用πi的排列)来解码xi。
在上述的步骤2.Ea/2.Da中,可通过以下方式实现确定πi:如果(qi,0,…qi,N-1)与(qi-1,0,…qi-1,N-1)之间的差是稀疏的,更新πi-1。例如,假设根据(qi-1,0,…qi-1,N-1)获得πi-1,通过检查符号xi以及πi-1中在其前面的符号是否需要根据(qi,0,…qi,N-1)来交换,可以获得πi。
为了减少在确定Ai时涉及的计算复杂度,一些实施例可仅在每对L>1个符号进行了编码/解码时或者在(qi,0,…qi,N-1)与(q*,0,…q*,N-1)有足够的不同时才更新字母表排序,(q*,0,…q*,N-1)表示A上用于确定Ai-1的边缘分布。
最后,在一些实施例中,动态字母表重排序可以是上下文相关的,其中扩展类似于针对动态二进制化器适配所描述的扩展。
现在参考图12,其中示出了编码器1200的示例性实施例的简化框图。编码器1200包括处理器1202、存储器1204、和编码应用1206。编码应用1206可以包括存储在存储器1204中并包含指令的计算机程序或应用,所述指令在执行时使处理器1202执行诸如本文描述的操作等的操作。例如,编码应用1206可以编码并输出根据本文描述的过程所编码的比特流。可以理解,编码应用1206可以存储在非瞬时计算机可读介质上,如致密光盘、闪存设备、随机存取存储器、硬盘等等。当执行指令时,结果是将1202处理器配置为使得可创建实现所描述的过程的专用处理器。在一些示例中,这样的处理器可以被称为“处理器线路”或“处理器电路”。
现在还参考图13,其示出了解码器1300的示例实施例的简化框图。解码器1300包括处理器1302、存储器1304、以及解码应用1306。解码应用1306可以包括存储在存储器1304中并包含指令的计算机程序或应用,所述指令在执行时使处理器1302执行诸如本文描述的操作等的操作。可以理解,解码应用1306可以存储在计算机可读介质上,如致密光盘、闪存设备、随机存取存储器、硬盘等等。当执行指令时,结果是将处理器1302配置为使得可创建实现所描述的过程的专用处理器。在一些示例中,这样的处理器可以被称为“处理器线路”或“处理器电路”。
可以认识到,根据本申请的解码器和/或编码器可以在多个计算设备中实现,包括但不限于服务器、合适编程的通用计算机、音频/视频编码和回放设备、电视机顶盒、电视广播设备和移动设备。解码器或编码器可以通过软件来实现,该软件包含用于将处理器配置为执行本文所述功能的指令。软件指令可以存储在任何合适的非瞬时计算机可读存储器上,包括CD、RAM、ROM、闪存等。
将理解的是,可以使用标准计算机编程技术和语言来实现本文描述的解码器和/或编码器以及实现所描述的用于配置编码器的方法/过程的模块、例程、进程、线程或其他软件组件。本申请不限于特定处理器、计算机语言、计算机编程惯例、数据结构、其他这种实现细节。本领域技术人员将认识到,可以将所描述的处理实现为存储在易失性或非易失性存储器中的计算机可执行代码的一部分、专用集成芯片(ASIC)的一部分等。
可以对所述实施例进行某种调整和修改。因此,上文讨论的实施例应被认识是说明性而非限制性的。
- 还没有人留言评论。精彩留言会获得点赞!