一种基于域聚类的WiFi室内定位方法与流程
本发明属于室内定位技术领域,具体涉及一种新基于WIFi指纹的通过区域集群进行室内位置定位的方法。
背景技术:
近二十年来,越来越多的室内环境的个性化基于位置服务刺激着各种各样的室内定位系统(IPS)的发展。一系列不同的定位技术被部署用于进行室内位置估计,例如GNSS,超声波,超宽带(UWB)和WiFi等。WiFi室内定位技术存在两个主要的挑战:多径效应和非视距(NLOS)的影响。因此,大多数WiFi室内定位系统使用指纹技术进行位置估计,其包含两个阶段:校准阶段(线下阶段)和定位阶段(线上阶段)。校准阶段通过关联附近APs的WiFi信号和校准点的物理坐标来构建定位区域的指纹。在定位阶段,通过比较测试点接收到的附近APs的信号强度和指纹库的校准点的信息来估计测试点的位置。通常采用WKNN和朴素贝叶斯分类器来估计位置,这两者方法的结果都受到AP选取算法影响。
AP的选取通常为了实现两个目的:通过选取可用APs的AP子集减少计算负担,消除无用甚至对位置估计有害的APs。基于AP选取策略实施的阶段可以将AP选取算法区分为线下AP选取策略和线上AP选取策略。H.Zou等提出了一种基于互信息的线上AP选取策略,选取最佳集体判别能力最佳的APs用于位置近似计算。另一种基于标准差的线上AP选取算法选取标准差最小的N个APs作为最优AP子集。线上阶段的AP选取算法能够减少环境动态变化带来的影响,但是其忽略了校准点包含的大量信息,同时其建立在线上阶段测试点较长时间的持续采样的基础上。在线下阶段,位置信息增益可用于AP的选取,但是单个AP信息增益算法没有考虑AP间的相关性。本发明提出了一种基于域聚类的新的位置估计策略。
总的来说AP选取算法的性能受到不同环境的影响,并且最优AP子集的个数定义往往是模糊的且对位置估计精度存在一定的影响。因此,为了保证和提高算法的定位精度,亟需提出了一种新的WiFi室内定位估计策略。
技术实现要素:
本发明提出了一种新的WiFi室内定位估计的策略,称为域聚类定位(DCL)。该方法同时适用于两种经典的位置估计策略:WKNN方法和朴素贝叶斯分类器,同时由于其采用所有的AP分别进行位置估计因此不需要考虑AP选取问题。
本发明所采用的技术方案是:一种基于域聚类的WiFi室内定位方法,其特征在于,包括以下步骤:
步骤1:在两种不同的室内环境中选取若干校准点,采集校准点处的WiFi信号强度信息,将信号强度信息和校准点的位置信息关联起来组成位置指纹,得到位置指纹库;
步骤2:采集测试点(x,y)的WiFi信号强度信息,将测试点的WiFi信号强度信息与位置指纹库进行预匹配,利用校准点与测试点的欧氏距离找到距测试点最近的K个邻近校准点;统计K个邻近校准点的边界值并求出中心点;
步骤3:采用WKNN或朴素贝叶斯分类器对测试点进行定位;若校准点与测试点共同观测到的AP总共有m个,则可获得m个测试点可能出现的位置;
步骤4:确定测试点的最终位置
与现有技术相比,本发明具有的特点:
(1)经典的WKNN方法或者朴素贝叶斯分类器需要选取AP子集从而提高IPS的性能。当AP子集的个数不同时,WKNN方法或者朴素贝叶斯分类器的结果也会不一致。新的定位策略采用所有可用AP单独进行测试点的位置估计,并且利用域聚类技术获取最终的位置。因此,新方法的结果不会受到AP子集的影响;
(2)实验分析表明:新的位置估计策略具有更高的精度和可靠性。相比对应的经典算法WKNN-DCL和NBC-DCL的定位结果的误差均值都达到最小。基于DCL的定位策略误差在1.5m和3.5m的正确率相比经典的方法具有明显的优势;
(3)由于新策略仅仅采用一个简单的域聚类技术对WiFi IPS进行了改进,因此在将来的工作中将会提出更加合理的域聚类技术,对于域聚类技术在WiFi指纹定位中的应用起到了借鉴作用。
附图说明
图1是本发明实施例的流程图;
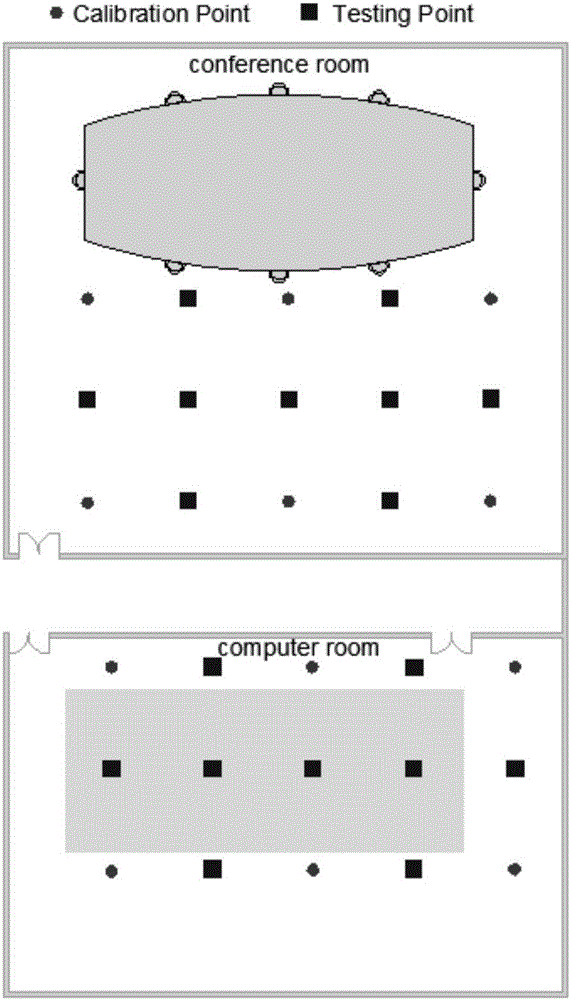
图2是本发明实施例的实验方案分布示意图;
图3是本发明实施例的WKNN定位策略的累积分布函数(CDF)示意图;
图4是本发明实施例的朴素贝叶斯定位策略的累积分布函数(CDF)示意图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种基于域聚类的WiFi室内定位方法,包括以下步骤:
步骤1:在两种不同的室内环境中选取6个校准点(请见图2),采集校准点处的WiFi信号强度信息,持续时间为2min;将信号强度信息和校准点的位置信息关联起来组成位置指纹,得到位置指纹库;
步骤2:采集测试点(x,y)的WiFi信号强度信息(9个测试点,点位详见图2),将测试点的WiFi信号强度信息与位置指纹库进行预匹配,利用校准点与测试点的欧氏距离找到距测试点最近的K个邻近校准点;统计K个邻近校准点的边界值并求出中心点;
本实施例邻近校准点个数设置为4。同时四个邻近校准点的坐标边界值记录为and
步骤3:采用WKNN或朴素贝叶斯分类器对测试点进行定位;若校准点与测试点共同观测到的AP总共有m个,则可获得m个测试点可能出现的位置;
识别测试点的近似区域,可应用简单的AP可见性原则实现该目标。一般而言,房间级别子区域可见的AP集合是存在差异的,因此和测试点可共同观测的AP数目最多的区域便是测试点最可能出现的区域,即为近似区域。近似区域所有测试点和校准点可共同观测的AP记为AP1,AP2,...,APm。
WKNN方法和朴素贝叶斯方法具体实现原理:
选取k个AP用于位置估计,因此第j个校准点的RSS向量为:
校准点和定位点之间多维信号空间的距离可以采用欧氏距离表示为:
其中,表示测试点的第i个AP的RSS观测值;
选取距离最短的K个校准点用于估计测试点的位置,WKNN和朴素贝叶斯分类器的区别就在于权重计算;
WKNN通常采用距离反比例加权:
因此测试点的位置可通过下式计算:
其中表示测试点的二维坐标估计值,表示是第j个校准点的坐标;
假定测试点的RSS观测向量为并且表示第j个校准点的位置,那么朴素贝叶斯分类器利用后验概率测度测试点出现在第j个校准点的可能性;利用贝叶斯理论,后验概率可表达成如下的形式:
其中表示RSSt的条件概率存,其在线下阶段存储在指纹库中,所有校准点的为相同的常量;
类似WKNN,将看成第j个校准点的权重,因此测试点的朴素贝叶斯分类器位置估计公式如下:
步骤4:确定测试点的最终位置其具体实现包括以下子步骤:
步骤4.1:分别对m个测试点可能出现的位置的x坐标和y坐标排序;
步骤4.2:将m个估计位置的x坐标利用分为两部分,其中表示测试点可能出现位置中最大的x坐标值;表示测试点可能出现位置中最小的x坐标值;
步骤4.3:分别计算小于和大于的x坐标的个数,个数多的部分即x坐标最可能落入的区域,成为x域;
步骤4.4:挑选出所有位于x域的x坐标估计值并利用下式计算测试点最终的x坐标
式中kx表示位于x域的坐标的个数,表示属于x域的坐标估计;
步骤4.5:利用步骤4.1-4.1的原理,计算测试点y坐标的最终估计值
步骤4.5:获得测试点的最终位置
测试点的真实位置(x,y)与估计位置的误差err可计算如下:
本实施例的实验结果如下,其中WKNN算法和WKNN-DCL算法精度比较结果请见表1,朴素贝叶斯算法和朴素贝叶斯-DCL算法精度比较结果请见表2,WKNN算法和WKNN-DCL算法型稳定性比较结果请见表3,朴素贝叶斯算法和朴素贝叶斯-DCL算法型稳定性比较结果请见表4:
表1 WKNN算法和WKNN-DCL算法精度比较
表2朴素贝叶斯算法和朴素贝叶斯-DCL算法精度比较
表3 WKNN算法和WKNN-DCL算法型稳定性比较
表4朴素贝叶斯算法和朴素贝叶斯-DCL算法型稳定性比较
在两个房间的区域进行了实验用来评估提出的新方法的性能。房间1为一个计算机室并且存在人员的活动,大小约为72m2(10m×7.2m)。房间2为一个会议室且没有人员的走动,大小约为110m2(10m×11m)。总共采集了12个校准点和18个测试点。相邻点之间的空间间隔为2m。校准点和测试点的物理位置如图2所示。
两种典型方法,WKNN和朴素贝叶斯分类器被选择用来与DCL进行对比分析。WKNN和朴素贝叶斯分类器的AP选取采用基于联合信息增益的智能AP选取策略,AP子集的个数分别设置为4-8个。分别实施基于WKNN的DCL方法(WKNN-DCL)和基于朴素贝叶斯分类器的DCL(NBC-DCL)。表1比较了WKNN和WKNN-DCL两种不同策略的位置估计误差的均值、标准差和最大误差。表2比较了朴素贝叶斯分类器和NBC-DCL两种不同策略的位置估计误差的均值、标准差和最大误差。从表1和表2可以看出,经典的WKNN方法和朴素贝叶斯分类器的定位结果都受到AP子集个数的影响,并且难以找出误差均值和最大误与AP子集个数的显示关系。因此,这两张方法需要谨慎的处理选取AP个数的问题。表1和表2中,WKNN-DCL的误差均值要小于不同AP个数的WKNN方法的均值,同样NBC-DCL的误差均值也要小于不同AP个数的朴素贝叶斯分类器。同时,NBC-DCL的最大误差也要远小于对应的其它朴素贝叶斯分类器计算的结果且其NBC-DCL的误差标准差也是最小的。然而,WKNN-DCL的比较存在一些异常,WKNN-DCL的误差标准差并非最小,并且其最大误差最大。
图3和图4展示了不同定位策略的累积分布函数图(CDF)。如图3所示,当误差阈值在2m~4m时,WKNN-DCL的CDF曲线要高于经典的WKNN方法,即误差小于阈值的概率更高。这一现象在图4中更加明显,NBC-DCL的CDF曲线在整个误差范围内都要高于朴素贝叶斯分类器。表3和表4显示了正确率在1.5m,2.5m和3.5m内的统计百分比。WKNN-DCL小于1.5m的误差占61%远大于经典的WKNN方法。尽管WKNN-DCL正确率在2.5m的百分比要比部分WKNN方法差,但是WKNN-DCL正确率小于3.5m的百分比为89%比WKNN方法最好时还要高约6%。NBC-DCL的1.5m限差的正确率为44%且正确率为3.5m的百分比为83%,都要远好于朴素贝叶斯分类器。
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!