一种基于分组测试的拥塞链路定位方法与流程
本发明属于网络故障诊断技术领域,尤其涉及一种基于分组测试的拥塞链路定位方法。
背景技术:
精确地以及及时地了解大型网络的内部链路状态(如企业内部网中链路的延迟或者拥塞状态)对于许多网络应用是至关重要的,例如路由优化、网络性能评估以及探测异常或恶意行为等;因为监测大量链路以及传送数据包会产生很高的花费,所以直接测试内部链路状态一般是不可行的。为了解决这些问题,网络诊断通过端到端的路径测试来推断内部链路状态已经引起了广泛的研究。如果一条链路上的通信量速率接近它的可用带宽,在这条链路上的数据包将感到很长的延迟,以致最终丢失。因此在两个主机(边界节点)之间沿着包含至少一条拥塞链路的路径上发送探测数据包将会感到明显的端到端的延迟,预示着拥塞的开始。然而,通过这些端到端的测试,如何确定性地鉴别哪些链路是拥塞的为决定性问题。网络诊断的一个特例是通过端到端的拥塞测试去推断内部链路的拥塞状态.在这种情况下,只考虑二进制的链路状态,即“1”表示拥塞以及“0”表示非拥塞。路径测试结果也是二进制表示:“1”表示沿着这条路径至少一个链路是拥塞的以及“0”表示沿着这条路径的所有链路是非拥塞的。链路和路径的二进制特征要求网络诊断模型通过布尔代数来计算和求解。Duffield首次提出称作布尔诊断的新的网络诊断结构;提出了最小一致故障集(SCFS)推断算法去诊断拥塞链路,存在的缺陷是只适用于拥塞链路为稀疏时的拥塞链路定位,而且在网络诊断中他使用的是被动测试来监测网络中的链路状态,这需要终端的合作,另一方面,同时发送所有的探测路径来定位所有的拥塞链路会导致需要较多的探测路径数。在Duffield之后,有许多学者致力于此,提高了布尔诊断的性能;为了提高丢失率的弱可分离性引起的不精确性。Nguyen and Thiran在执行SCFS算法前,使用启发式的算法修正每条路径的状态,由于链路延迟,一个端到端的测试会引起沿着路径上的所有链路延迟的累加;Chen Jin-Biao引入乘法的度量可以通过使用方程log(·)使路径上的延迟表示为加法的形式;通过进行很多路径测试构建一个线性观测模型,求解这个模型推断出内部链路的状态。Pan Sheng-Li采用放大的状态空间模型反应不同的拥塞水平,通过解约束优化来鉴别拥塞链路,该方法存在的缺陷是根据端到端的测试估计出每条链路的拥塞概率,基于估计的拥塞概率进一步提出算法来定位拥塞链路;由于链路延迟是随着时间变化的,他提出关于链路延迟有很好先验分布的随机模型有较高的精度,但是在随机模型中过度参数化将导致很明显的计算复杂度。Bai Linda提出适应性的探测方法,根据每一次的探测结果动态地调整下一次的探测路径,精确地定位出拥塞链路的位置,降低了需要的探测路径数,其缺陷是在探测过程中需要内部节点的协作,增加了监测花费,同时具有较高的时间复杂度。
目前基于端到端的路径探测技术定位拥塞链路的方法定位准确度不够、诊断时间过长,这是因为由于目前的诊断方案大多是基于随机性模型,关于链路延迟有很好先验分布的随机模型将会有较低的方差估计,而假设的分布和真实的分布之间的差异将会导致估计偏差,不能够做到精确定位网络中的拥塞链路。虽然二进制的决定性探测方案可以精确地定位每一条拥塞链路,但Bai Linda提出适应性的决定性探测方法,根据每一次探测结果来部署下一次探测路径,动态调整每一次的探测路径具有较高的时间复杂度,导致诊断时间过长,而本发明提出的探测方案中,在构造好的路由矩阵中,通过同时发送所有的探测信号来唯一定位网络中的所有拥塞链路,精确定位所有拥塞链路的同时大大地降低了时间复杂度。
技术实现要素:
本发明的目的在于提供一种基于分组测试的拥塞链路定位方法,旨在解决目前基于端到端路径探测技术定位拥塞链路的方法定位准确度不够、诊断时间过长的问题。
本发明是这样实现的,一种基于分组测试和构造分离矩阵的拥塞链路定位方法,定位过程分为3步:
(1)为了定位网络中d条拥塞链路,首先需要构造d分离矩阵M;
由于d分离矩阵的d分离特性,通过分组测试的理论来构造d分离矩阵,网络中的任意d条拥塞链路都可以被定位出来。
(2)将d分离矩阵M作为路由矩阵,沿着这个路由矩阵同时发送探测信号,得到路径测试结果向量Y;
依据(1)中得到的d分离矩阵作为路由矩阵,所有的探测信号在每条探测路径上同时发送来快速定位拥塞链路。
(3)根据探测路径结果Y和d分离矩阵M,求解d分离矩阵模型Y=MX,得出每条链路的拥塞状态X。
所述基于分组测试的拥塞链路定位方法采用d分离矩阵模型作为二进制检验矩阵鉴别拥塞链路,定位网络中的拥塞链路;d分离矩阵模型为Y=MX,其中M表示路由矩阵,是一个d分离矩阵,矩阵M的每一行为一条探测路径,Y为每条探测路径的结果,已知M和Y,可求得每条链路的拥塞状态X;通过随机游走方法来构造矩阵的每一行去定位拥塞链路;一个测试为一个随机游走,即探测信号从发送方出发,随机选择路径进行随机游走,直到到达接收方后停止;任务是识别拥塞链路;在给定的网络中,使用布尔向量编码路由矩阵,编码的过程是:布尔向量相应的位置表示图中链路集合,每条探测路径经过的链路,他们相应位置记为1,否则记为0。
进一步,所述d分离矩阵的构造方法包括:n个物品为网络中的链路,当中至多d条是拥塞的,即经由链路的数据包丢失;每一列相当于G中的每条链路,每一行相当于G上的一些链路形成的一条路径;提出随机游走的算法去设计一个保证没有误差地鉴别所有拥塞链路的行数m最小的m×n的二进制检验矩阵,即d分离矩阵;m为探测路径数。
进一步,所述随机游走方法包括:
输入:图G(V,E),一个发送方u,一个接收方v,拥塞链路数d,初始拥塞链路集合为Ψ=E;
输出:拥塞链路集合Ψ,M的行数m;
初始化每条链路上的计数器ρ(e)=0;
独立地构造M的每一行的过程如下:
让u∈V为G中的任意一点,从u开始直到达到节点v,执行一个任意的随机游走;
每次随机游走结束后,对其所经过的链路上的计数器ρ(e)加1;
下一次随机游走从u开始,选择计数器数值小的链路进行游走,直到达到节点v;
让M的每行为由每条游走访问的链路的集合;
end
在每一条游走上发送数据包,如果某条游走上的时延低于阈值t,从Ψ中删除这条游走经过的链路。
本发明的另一目的在于提供一种利用所述基于分组测试的拥塞链路定位方法的网络诊断系统。
本发明提供的基于分组测试的拥塞链路定位方法,提出二进制决定性模型,基于这个模型,依据非适应性探测方法提出随机游走的拥塞链路诊断算法;非适应性型探测结合随机游走的方法可以减少时间复杂度.通过仿真环境比较了本发明算法和已有的拥塞定位算法(文献[Chen JB,Qi X,Wang Y.An efficient solution to locate sparsely congested links by network tomography.In Proc.the 2014IEEE International Conference on Communications,January 2014,pp.1278-1283]和[Bai LD,Roy S.A two-stage approach for network monitoring.J.Netw.Syst.Manage,2013.238-263])。实验结果证明,本发明算法可以使用较少的管理花费精确定位每条拥塞链路以及具有更快的诊断速度。本发明提出了d分离矩阵模型作为二进制检验矩阵来唯一地鉴别拥塞链路,提高了故障诊断精度,能够100%定位网络中的拥塞链路;通过图约束下的分组测试问题来构造d分离矩阵;在图约束下的分组测试问题中,n个物品为图中的链路,当中至多d条是拥塞的,即经由这些链路的数据包丢失;提出的检验矩阵M的限制如下:每一列相当于G中的每条链路,每一行相当于G上的一些链路形成的一条路径;提出随机游走的算法去设计一个可以保证没有误差地鉴别所有拥塞链路的行数m(探测路径数)最小的m×n的二进制检验矩阵。
附图说明
图1是本发明实施例提供的基于探测路径的拥塞链路定位示意图;
图中:(a)拓扑图;(b)路由矩阵。
图2是本发明实施例提供的简化网络管理所延伸的网络示意图。
图3是本发明实施例提供的2分离矩阵示例即M的任何2列的布尔和不包含任何其他列示意图。
图4是本发明实施例提供的不同的网络规模和链路拥塞率对应的探测路径数示意图。
图5是本发明实施例提供的不同网络规模和平均节点度对应的探测路径的平均长度示意图。
图6是本发明实施例提供的不同网络规模和平均节点度对应的探测路径数示意图。
图7是本发明实施例提供的不同网络规模下不同算法对比下的计算时间示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合具体实施例对本发明的应用原理作进一步的描述。
1决定性的测试模型
由于决定性的测试模型在得到更高效的网络监测算法方面很有潜力,所以在本发明中采用它作为模型。
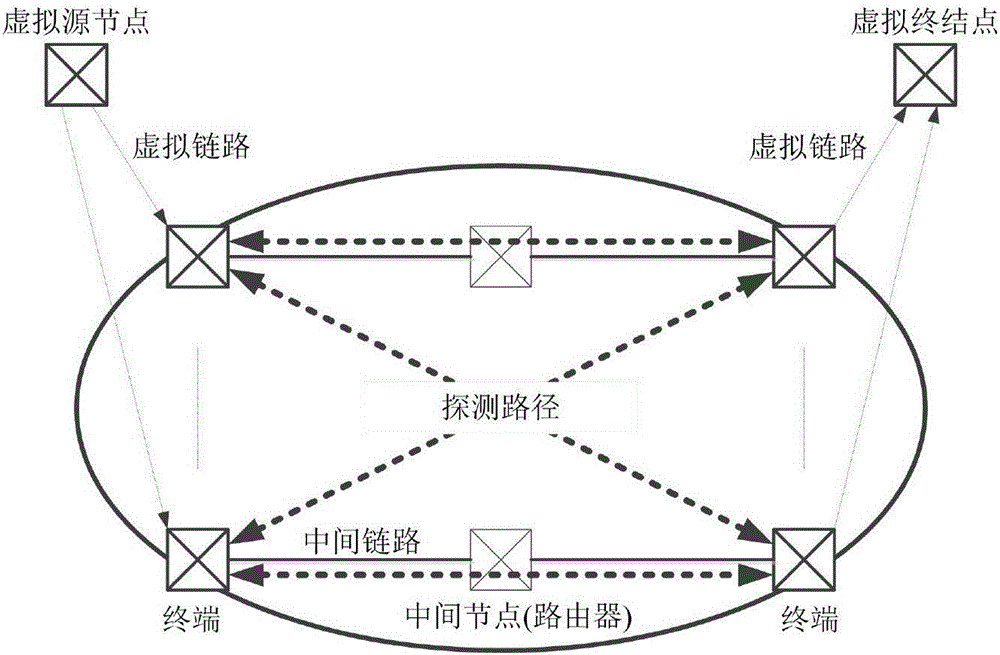
考虑一个网络,建模为一个无向图G(V,E);节点集V表示节点(终端、交换机或者路由器),边集合E表示连接这些节点的链路(边和链路在文章中交换使用)。网络中的总链路数(|E|的基数)为n;在G中假设有一组定义的边界节点(终端),边界节点一般设为可以发送和接收探测信号的节点,内部节点(路由器)只有转发功能,在边界节点对间沿着提前给定的路由发送探测信号;在边界节点对间选择总条数为m的路由(意味着得到总共m条端到端的测试)来鉴别哪些链路为拥塞链路。图1(a)给出了有4个边界节点,2个中间节点,5条内部链路的网络拓扑,(b)给出了4条探测路径相应的路由矩阵。
在多个边界节点间,两两选择进行发送探测信号来探测拥塞链路,会产生较高的管理花费;管理花费主要由发送方和接收方的数量组成。为了简化网络管理,本发明将所有的边界节点虚拟为两个节点,一个为虚拟源节点作为发送方,一个为虚拟终节点作为接收方(见图2);发送方发送探测信号,接收方接收探测信号;通过一对发送(接收)节点依据路由矩阵进行探测来诊断网络内部链路的拥塞状态;即在一对发送方和接收方之间选择m条端到端的测试;如果链路li(i=1,...,n)属于路径φj(j=1,...,m),相应的路由矩阵A中(j,i)的元素为1,否则剩下的元素都为0。
则在网络中,有一个发送方节点,一个接收方节点,假设网络G(V,E)的路由矩阵为M;网络中所有端到端的路径集合为Φ;链路li的状态表示为:
路径φj(∈Φ)的状态表示为:
当且仅当路径上的至少一条链路拥塞,则这条路径是坏的,即就是:
这引出一个二进制决定性模型:
Y=MX (4)
其中是由探测路径得到的m×1的二进制向量,M为m×n的二进制路由矩阵,为n×1的二进制向量,表示链路状态。
网络中的所有的链路都被端到端的探测来监测,即:
本发明假设链路状态是独立的并只考虑k<<n条链路是拥塞的,非拥塞的路径的时延为t,拥塞路径的时延高于阈值t,甚至数据包会丢失导致一直接收不到信号。本发明中的监测系统使用一对可以发送和接收数据包的终端;在网络中通过分配路由,一个终端发送数据包到另一个终端。
在布尔代数中,很难找到高效的方法解决候选解中的歧义,测试长度(链路数)为l的拥塞路径有2l-1种可选择的中间链路状态;为了唯一性地决定网络中所有n条链路的拥塞状态,根据矩阵论知识,解模型(4)求X需要观测(路由)矩阵M包含m=n条线性独立的路径测试,由于一些测试是线性相关的并没有提供新的信息,这一般需要进行m(>n)次测试;通过引入分组测试来构造d分离矩阵M来说明进行m(<<n)测试就可以明确地定位所有的拥塞链路。
2d分离矩阵的构造算法
分组测试
分组测试的思想可以追溯到二战时期,在美国军队中,分析成千上万个血样去检测梅毒;为了减少测试数,有人提议把多个血样本放入一个水池(pool)中同时进行测试;从算法的观点,把多个血样本放入水池中进行检测和在图中监测拥塞链路这两个任务有两个明显的不同:(1)血样本可以任意组合放入到水池中,而探测路径上的链路必须是一组连通的链路,(2)探测在发送方同时发送,并不知道其他测试的结果(非适应性测试),非适应性的分组测试为把n个物品任意分组到不同的水池中,接着测试每一个水池,识别出有缺陷的物品,一个根本的问题为最小化鉴别至多d个有缺陷的物品所需的测试数;在非适应性的分组测试中,给出一个m×n的二进制测试矩阵M;M的第j行表示n个物品中哪些子集属于第j个水池,在图约束下的分组测试问题中,n个物品是图中的链路;n个中至多d个是有缺陷的;关于定位拥塞链路问题,物品可以看作是网络中的链路,每一个水池为一组连通的链路。
d分离矩阵的定义
定义1:一个m×n布尔矩阵M被称作d分离矩阵,当对于每一列,每选择M的d列S1,...,Sd(与S0不同),则至少有一行M[r,S0]=1,相应的M[r,Si]=0(i=1,2,...,d)。
d分离矩阵的概念起源于分组测试理论,由于它高效的解码方法,已经被广泛应用在各种大型网络中的异常定位中;图3给出了一个2分离矩阵,d分离矩阵作为路由矩阵来发送/接收探测信号,探测结果为0表示探测信号在给定的时间阈值t内成功接收信号,φj上没有拥塞链路;否则表示φj上有拥塞链路。
为了区分稀疏的布尔向量,在分组测试理论中一个经典的结果认为分离矩阵可以用在非适应性的分组测试方案中,在拥塞链路定位算法中,假设拥塞链路数的上界为d,d分离矩阵可以精确定位网络中d条拥塞链路,要定位d条拥塞链路的位置就需要构造一个d分离矩阵。更确切的说,有|E|列的d分离矩阵M可以用来做测试矩阵;M的每一行为一条探测路径,在长度为|E|两个不同的d稀疏向量得到的测试结果至少一位不同;这样就能够唯一地定位所有的拥塞链路;接下来要做的是设计一个行数m最小的m×|E|的二进制的d分离矩阵,可以保证没有误差的鉴别拥塞链路。
如何构造维数较大的d分离矩阵一直是个难题,直到提出的d分离矩阵构造方法,本发明通过随机游走来构造矩阵的每一行去定位拥塞链路。在本发明中,一个测试为一个随机游走,即探测信号从发送方出发,随机选择路径进行随机游走,直到到达接收方后停止;任务是识别拥塞链路;在给定的图中,使用布尔向量编码路由矩阵,编码的过程是:布尔向量相应的位置表示图中链路集合,每条探测路径经过的链路,他们相应位置记为1,否则记为0。
3算法
在算法中使用计数器的目的是使游走尽量走被较少探测路径经过的链路,这样可以减少总的探测路径数m.在每一条游走上发送数据包,如果某条游走上的包的时间延迟高于阈值t,则认为此路径上存在拥塞链路,否则这条游走上的所有链路都是健康链路。因此,如果一条链路是拥塞的,它总会被分类为拥塞的;换句话说,基于探测的算法的误诊率(False Detection Rate)为0;其中:ncongested为实际发生的拥塞链路,ndetected为算法诊断出的发生拥塞的链路;关于误诊率,ndetected≥ncongested,当测试矩阵是d分离矩阵时,等号成立。
下面结合仿真对本发明的应用效果作详细的描述。
1仿真
为了评估实验,本发明在Microsoft Visual Studio 2010环境下进行仿真,给出了在不同的网络规模、平均节点度、链路拥塞率的角度下评估算法的性能;通过稀疏幂律模型产生平均节点度为2和3的大型随机网络,在产生的网络上进行测试;除了检测所需的探测路径数,文章也检测了每一条探测结果为“0”的探测路径(即没有拥塞链路的路径)的长度,这可以帮助接收者决定等探测信号到达需要多长时间,否则的话认为有拥塞发生。因此,它反映了算法的时间复杂度。本发明为了研究算法的稳健性,通过增加链路数来增加网络规模,对于生成的每一个网络,固定两个最大度节点作为接收方和发送方。
网络规模的影响;本发明产生节点数范围为500到3000,边数范围为1000到3000的网络;拥塞比率(其中k为拥塞的链路数)为2%和3%;图4为平均节点度为3的网络中,不同的网络规模和链路拥塞率对应的探测路径数,随着网络规模的增大,定位拥塞链路所需的探测路径数也在增加。这是不可避免的,因为链路数越多,定位越困难。根据图4,可以看到探测路径数少于[Du DZ,Hwang FK.Pooling Designs:Group Testing in Molecular Biology.World Scientific,2006]中d分离矩阵的行数的理论上限d2logm,即就是小于没有图限制下定位d条拥塞链路所需的探测路径数。
探测结果为“0”的探测路径的平均长度,见图5,随着网络规模从链路数1000增加到2000,探测结果为“0”的探测路径的平均长度从30增加到80;因为只有一对发送方和接收方,它俩的直径可能会和图的直径一样大。因此,接收方可以使用最大传输时间为80跳作为数据包的最大传输时间;拓扑密度的影响;见图6,平均节点度从2增加到3,探测路径数增加,越密集的拓扑,大量的随机游走将经过大量重复的链路或环,这会减少探测路径的效率。探测时间,快速的诊断出拥塞链路是网络故障诊断的一个最重要的目标,在平均节点度为2的大型幂律网络中,链路数从1000到3000,仿真实现文献[8]和文献[3]的算法,图7给出了在不同网络规模下不同的算法的计算时间,由于随机游走算法同时发送所有的探测,可以得到,对比文献[8]使用先验概率估计拥塞链路的方法,以及对比文献[3]适应性探测的方法,本发明提出的算法有很明显的时间减少。
使用探测率(DR)来评估定位拥塞链路算法的性能,探测率为正确地探测为拥塞链路的百分比,ET为实际拥塞的链路,ES为本发明中算法探测到的拥塞链路,DR的计算公式为:考虑管理花费,即发送方和接收方的数量,要明确的知道边界节点的数量,本发明采用格状拓扑进行仿真比较。表1给出了在格状拓扑中,拥塞率为2%时,不同的网络规模下不同方法对应的管理花费、DR和FDR;随机游走算法在保证和文献[3]都具有探测率为1、误诊率为0的同时,减少了管理花费。
文献[3]Bai LD,Roy S.A two-stage approach for network monitoring.J.Netw.Syst.Manage,2013.238-263。
文献[8]Chen JB,Qi X,Wang Y.An efficient solution to locate sparsely congested links by network tomography.In Proc.the 2014IEEE International Conference on Communications,January 2014,pp.1278-1283。
表1在格状拓扑中,拥塞率为2%时,不同的网络规模下不同方法对应的管理花费、DR和FDR
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!